Семантические языковые модели
Замечание
Дополнительные сведения см. на вкладке "Текст и изображения ".
Поскольку состояние дел в области NLP совершило шаг вперёд, возможность обучения моделей, которые инкапсулируют семантические отношения между токенами, привела к появлению мощных языковых моделей глубокого обучения. В основе этих моделей лежит кодировка маркеров языка в виде векторов (многозначных массивов чисел), известных как внедрение.
Этот векторный подход к моделированию текста стал общим с такими методами, как Word2Vec и GloVe, в которых текстовые маркеры представлены как плотные векторы с несколькими измерениями. Во время обучения модели значения измерения назначаются для отражения семантических характеристик каждого маркера на основе их использования в обучаемом тексте. Затем математические связи между векторами можно использовать для выполнения общих задач анализа текста более эффективно, чем более старые статистические методы. Более последнее достижение в этом подходе заключается в использовании техники, называемой внимание, для рассмотрения каждого токена в контексте и вычисления влияния токенов вокруг него. Результируемые контекстуализированные внедрения, такие как те, которые находятся в семействе моделей GPT, предоставляют основу современного генерирующего ИИ.
Представление текста в виде векторов
Векторы представляют точки в многомерном пространстве, определяемые координатами вдоль нескольких осей. Каждый вектор описывает направление и расстояние от источника. Семантически аналогичные маркеры должны привести к векторам, имеющим аналогичную ориентацию, другими словами, они указывают на аналогичные направления.
Например, рассмотрим следующие трехмерные встраивания для некоторых распространенных слов.
| Слово | Vector |
|---|---|
dog |
[0.8, 0.6, 0.1] |
puppy |
[0.9, 0.7, 0.4] |
cat |
[0.7, 0.5, 0.2] |
kitten |
[0.8, 0.6, 0.5] |
young |
[0.1, 0.1, 0.3] |
ball |
[0.3, 0.9, 0.1] |
tree |
[0.2, 0.1, 0.9] |
Эти векторы можно визуализировать в трехмерном пространстве, как показано ниже:

Векторы для "dog" и "cat" похожи (оба домашние животные), как и "puppy" и "kitten" (оба молодых животного). Слова "tree", "young"и ball" имеют четко разные векторные ориентации, отражая их различные семантические значения.
Семантическая характеристика, закодированная в векторах, позволяет использовать операции на основе векторов, которые сравнивают слова и обеспечивают аналитические сравнения.
Поиск связанных терминов
Так как ориентация векторов определяется их значениями измерения, слова с аналогичными семантическими значениями, как правило, имеют аналогичные ориентации. Это означает, что вы можете использовать вычисления, такие как сходство косинуса между векторами, чтобы сделать значимые сравнения.
Например, чтобы определить "нечетное" между , "dog"и "cat", можно вычислить сходство косинуса между "tree"парами векторов. Подобие косинуса вычисляется следующим образом:
cosine_similarity(A, B) = (A · B) / (||A|| * ||B||)
Где A · B — скалярное произведение и ||A|| — величина вектора A.
Вычисление сходства между тремя словами:
dog[0.8, 0.6, 0.1] иcat[0.7, 0.5, 0.2]:- Скалярное произведение: (0,8 × 0,7) + (0,6 × 0,5) + (0,1 × 0,2) = 0,56 + 0,30 + 0,02 = 0,88
- Величина
dog: √(0,8² + 0,6² + 0,1²) = √(0,64 + 0,36 + 0,01) = √1,01 ≈ 1,005 - Величина
cat: √(0,7² + 0,5² + 0,2²) = √(0,49 + 0,25 + 0,04) = √0,78 ≈ 0,883 - Сходство косинуса: 0,88 / (1.005 × 0,883) ≈ 0,992 (высокая сходство)
dog[0.8, 0.6, 0.1] иtree[0.2, 0.1, 0.9]:- Скалярное произведение: (0.8 × 0.2) + (0,6 × 0.1) + (0.1 × 0.9) = 0,16 + 0,06 + 0,09 = 0,31
- Величина
tree: √(0,2² + 0,1² + 0,9²) = √(0,04 + 0,01 + 0,81) = √0,86 ≈ 0,927 - Косинусное сходство: 0,31 / (1,005 × 0,927) ≈ 0,333 (низкое сходство)
cat[0.7, 0.5, 0.2] иtree[0.2, 0.1, 0.9]:- Скалярное произведение: (0,7 × 0,2) + (0,5 × 0,1) + (0,2 × 0,9) = 0,14 + 0,05 + 0,18 = 0,37
- Сходство косинуса: 0,37 / (0,883 × 0,927) ≈ 0,452 (низкая сходство)
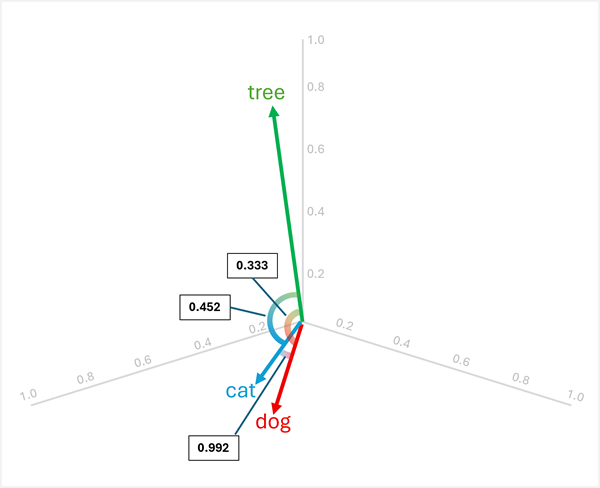
Результаты показывают, что "dog" и "cat" очень похожи (0,992), в то время как "tree" имеет меньшее сходство с "dog" (0,333) и "cat" (0,452). Поэтому tree явно отличается от остальных.
Преобразование векторов путем добавления и вычитания
Вы можете складывать или вычитать векторы, чтобы создавать новые векторные результаты, которые затем можно использовать для поиска токенов с соответствующими векторами. Этот метод позволяет интуитивно понятной арифметической логике определять соответствующие термины на основе лингвистических связей.
Например, используя векторы из предыдущих версий:
-
dog+young= [0.8, 0.6, 0.1] + [0.1, 0.1, 0.3] = [0.9, 0.7, 0.4] =puppy -
cat+young= [0.7, 0.5, 0.2] + [0.1, 0.1, 0.3] = [0.8, 0.6, 0.5] =kitten
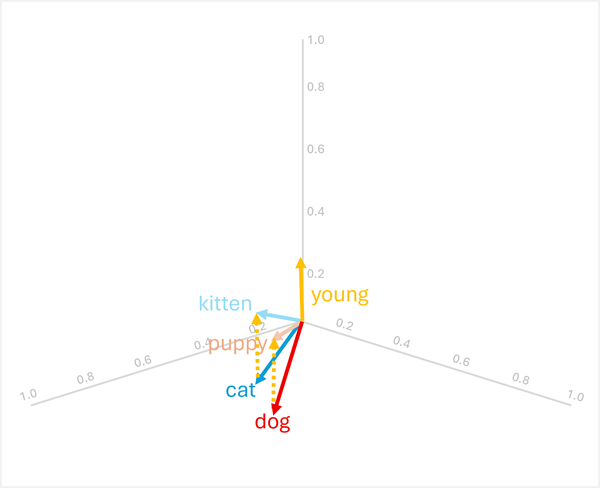
Эти операции работают, поскольку вектор для "young" кодирует семантическое преобразование от взрослого животного к его молодому аналогу.
Замечание
На практике арифметический вектор редко выдает точные совпадения; вместо этого вы будете искать слово, вектор которого является ближайшим (наиболее похожим) на результат.
Арифметические операции работают в обратном направлении также.
-
puppy-young= [0.9, 0.7, 0.4] - [0.1, 0.1, 0.3] = [0.8, 0.6, 0.1] =dog -
kitten-young= [0.8, 0.6, 0.5] - [0.1, 0.1, 0.3] = [0.7, 0.5, 0.2] =cat
Аналоговое обоснование
Арифметика векторов также может отвечать на вопросы-аналоги, такие как "
Чтобы решить эту проблему, вычислите следующее: kitten - puppy + dog
- [0.8, 0.6, 0.5] - [0.9, 0.7, 0.4] + [0.8, 0.6, 0.1]
- = [-0.1, -0.1, 0.1] + [0.8, 0.6, 0.1]
- = [0.7, 0.5, 0.2]
- =
cat
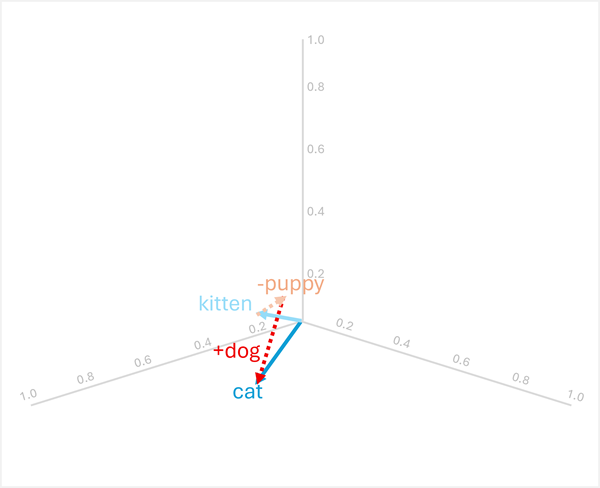
В этих примерах показано, как векторные операции могут фиксировать лингвистические связи и обеспечивать рассуждение о семантических шаблонах.
Использование семантических моделей для анализа текста
Семантические модели на основе векторов предоставляют мощные возможности для многих распространенных задач анализа текста.
Суммаризация текста
Семантические эмбеддинги позволяют экстрактивное суммирование, определяя предложения с векторами, наиболее репрезентативными для всего документа. Закодируя каждое предложение в виде вектора (часто путем усреднения или объединения внедренных слов), можно вычислить, какие предложения наиболее важны для смысла документа. Эти центральные предложения можно извлечь, чтобы сформировать сводку, которая захватывает ключевые темы.
Извлечение ключевых слов
Сходство векторов может определить наиболее важные термины в документе, сравнивая внедрение каждого слова в общее семантичное представление документа. Слова, векторы которых наиболее похожи на вектор документа, или наиболее центральные при рассмотрении всех векторов слов в документе, скорее всего, будут ключевыми терминами, представляющими основные темы.
Распознавание именованных сущностей
Семантические модели можно настраивать для точного распознавания именованных сущностей (людей, организаций, местоположений и т. д.) путем обучения векторным представлениям, которые группируют похожие типы сущностей вместе. Во время вывода модель проверяет внедрение каждого маркера и его контекст, чтобы определить, представляет ли она именованную сущность и, если да, какой тип.
Классификация текстов
Для таких задач, как анализ тональности или классификация тем, документы могут быть представлены в виде агрегатных векторов (например, средних значений всех встраиваемых слов в документе). Затем эти векторы документов можно использовать в качестве функций для классификаторов машинного обучения или сравнивать их непосредственно с векторами прототипов классов для назначения категорий. Так как семантически похожие документы имеют аналогичные векторные ориентации, этот подход эффективно группирует связанное содержимое и различает различные категории.