Использование Azure Data Lake Storage 2-го поколения в рабочих нагрузках аналитики данных
Azure Data Lake Store 2-го поколения — это технология включения нескольких вариантов использования аналитики данных. Давайте рассмотрим несколько распространенных типов аналитической рабочей нагрузки и определим, как Azure Data Lake Storage 2-го поколения работает с другими службами Azure для их поддержки.
Обработка больших данных и аналитика
Сценарии больших данных обычно относятся к аналитическим рабочим нагрузкам, которые включают в себя большие объемы данных в различных форматах, которые необходимо обрабатывать с быстрой скоростью — так называемые "три v". Azure Data Lake Storage 2-го поколения предоставляет масштабируемое и безопасное распределенное хранилище данных, в котором службы больших данных, такие как Azure Synapse Analytics, Azure Databricks и Azure HDInsight, могут применять такие платформы обработки данных, как Apache Spark, Hive и Hadoop. Распределенный характер хранилища и вычислений обработки позволяет выполнять задачи параллельно, что приводит к высокой производительности и масштабируемости даже при обработке огромных объемов данных.
Хранение данных
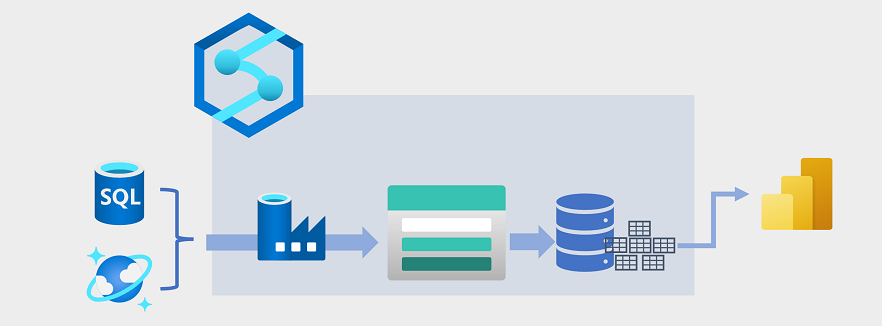
Хранение данных развивалось в последние годы для интеграции больших объемов данных, хранящихся в виде файлов в озере данных с реляционными таблицами в хранилище данных. В типичном примере решения для хранения данных данные извлекаются из операционных хранилищ данных, таких как база данных SQL Azure или Azure Cosmos DB, и преобразуется в структуры, более подходящие для аналитических рабочих нагрузок. Часто данные выполняются в озере данных, чтобы упростить распределенную обработку перед загрузкой в реляционное хранилище данных. В некоторых случаях хранилище данных использует внешние таблицы для определения уровня реляционных метаданных по файлам в озере данных и создания гибридной архитектуры data lakehouse или "lake database". Затем хранилище данных может поддерживать аналитические запросы для создания отчетов и визуализации.
Существует несколько способов реализации такой архитектуры хранения данных. На схеме показано решение, в котором конвейеры Azure Synapse Analytics размещаются для выполнения процессов извлечения, преобразования и загрузки (ETL) с помощью технологии Фабрика данных Azure. Эти процессы извлекают данные из операционных источников данных и загружают их в озеро данных, размещенное в контейнере Azure Data Lake Storage 2-го поколения. Затем данные обрабатываются и загружаются в реляционное хранилище данных в выделенном пуле SQL Azure Synapse Analytics, откуда он может поддерживать визуализацию данных и отчеты с помощью Microsoft Power BI.
Аналитика данных в режиме реального времени
Все чаще предприятия и другие организации должны записывать и анализировать бессрочные потоки данных и анализировать их в режиме реального времени (или как можно ближе к реальному времени). Эти потоки данных можно создавать на подключенных устройствах (часто называемых интернетом или устройствами Интернета вещей ) или из данных, созданных пользователями на платформах социальных сетей или других приложениях. В отличие от традиционных рабочих нагрузок пакетной обработки потоковая передача данных требует решения, которое может записывать и обрабатывать безграничный поток событий данных по мере их возникновения.
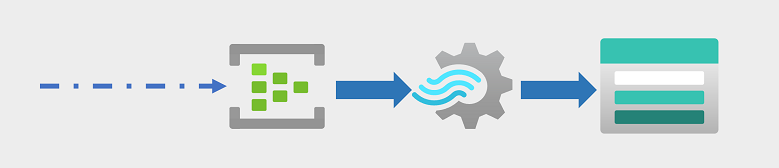
Потоковая передача событий часто фиксируется в очереди для обработки. Для выполнения этой задачи можно использовать несколько технологий, включая Центры событий Azure, как показано на изображении. Отсюда данные обрабатываются часто для агрегирования данных по темпоральным окнам (например, для подсчета количества сообщений социальных сетей с заданным тегом каждые пять минут или для вычисления среднего чтения подключенного к Интернету датчика в минуту). Azure Stream Analytics позволяет создавать задания, которые запрашивают и агрегируют данные событий по мере поступления, а также записывать результаты в приемник выходных данных. Одним из таких приемников является Azure Data Lake Storage 2-го поколения; откуда можно анализировать и визуализировать захваченные данные в режиме реального времени.
Обработка и анализ данных и машинное обучение

Анализ данных включает статистический анализ больших объемов данных, часто используя такие инструменты, как Apache Spark и языки сценариев, такие как Python. Azure Data Lake Storage 2-го поколения предоставляет высокомасштабируемое облачное хранилище данных для объемов данных, необходимых для рабочих нагрузок обработки и анализа данных.
Машинное обучение — это подзадача обработки и анализа данных, которая занимается обучением прогнозных моделей. Для обучения модели требуются огромные объемы данных и возможность эффективно обрабатывать эти данные. Машинное обучение Azure — это облачная служба, в которой специалисты по обработке и анализу данных могут запускать код Python в записных книжках с помощью динамически выделенных распределенных вычислительных ресурсов. Вычислительные процессы данных в Azure Data Lake Storage 2-го поколения контейнерах для обучения моделей, которые затем можно развернуть как рабочие веб-службы для поддержки прогнозных аналитических рабочих нагрузок.