Описание структурированной потоковой передачи Spark
Структурированная потоковая передача Spark — это популярная платформа для обработки в памяти. В ней применяется комплексная парадигма для пакетной и потоковой передачи. Все, что вы знаете и используете в отношении пакетной передачи, применимо и для потоковой передачи, поэтому можно с легкостью переходить от пакетной передачи данных к потоковой. Потоковая передача Spark — это просто подсистема, которая выполняется поверх Apache Spark.
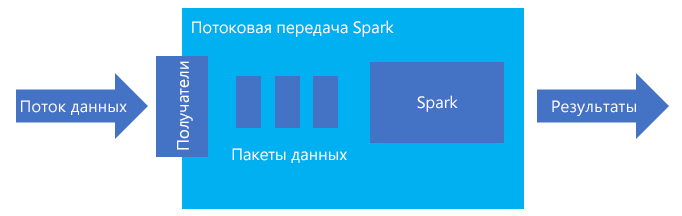
При структурированной потоковой передаче создается долго выполняющийся запрос, в рамках которого ко входным данным применяются такие операции, как выбор, проецирование, агрегация, разграничение по временным окнам и объединение потокового кадра данных с запрашиваемыми кадрами данных. Затем результаты выводятся в хранилище файлов (Azure Storage Blob или Data Lake Storage) или в любое хранилище данных с использованием специального кода (например, базы данных SQL или Power BI). Кроме того, при структурированной потоковой передаче данные выводятся на консоль для отладки в локальной среде и в таблицу в памяти, чтобы вы могли видеть данные, созданные для отладки в HDInsight.
Потоки как таблицы
Структурированная потоковая передача Spark представляет поток данных в виде таблицы, которая является не ограниченной по глубине, то есть таблица продолжает увеличиваться по мере поступления новых данных. Эта таблица входных данных непрерывно обрабатывается с помощью долго выполняющегося запроса, а результаты обработки записываются в выходную таблицу:

В структурированной потоковой передаче данные передаются в систему и сразу же поступают во входную таблицу. Вы можете написать запросы с помощью API кадров и наборов данных для выполнения операций в этой входной таблице. Выходные данные запроса поступают в другую таблицу — таблицу результатов. В таблице результатов содержатся результаты запроса, из которых извлекаются данные для отправки во внешнее хранилище, например реляционную базу данных. С помощью интервала триггера задается расписание для обработки данных во входной таблице. По умолчанию интервал триггера равен нулю, поэтому структурированная потоковая передача пытается обрабатывать данные по мере их поступления. На практике это означает, что как только структурированная потоковая передача завершает обработку выполнения предыдущего запроса, она запускает следующую обработку новых полученных данных. Можно настроить запуск триггера с интервалом, что позволит обрабатывать данные потоковой передачи в пакетах на основе времени.
Данные в таблице результатов можно обновлять каждый раз, когда поступают новые данные, благодаря чему таблица будет включать все выходные данные с момента отправки запроса потоковой передачи (полный режим), или же таблица может содержать только новые данные, поступившие после последней обработки запроса (режим добавления).
Режим добавления
В режиме добавления в таблице результатов содержатся только записи, добавленные после последнего выполнения запроса, и только они записываются во внешнее хранилище. Например, самый простой запрос просто копирует все данные из таблицы входных данных в таблицу результатов без изменений. Каждый раз, когда интервал триггера истекает, новые данные обрабатываются, а строки, представляющие эти новые данные, отображаются в таблице результатов.
Рассмотрим сценарий, когда вы обрабатываете данные о курсах акций. Предположим, что первый триггер обработал одно событие в 00:01, когда стоимость акции MSFT составляла 95 долларов США. При первом триггере запроса в таблице результатов появляется только строка со временем 00:01. В 00:02, когда поступает другое событие, единственной новой строкой является строка со временем 00:02, поэтому таблица результатов будет содержать только эту одну строку.
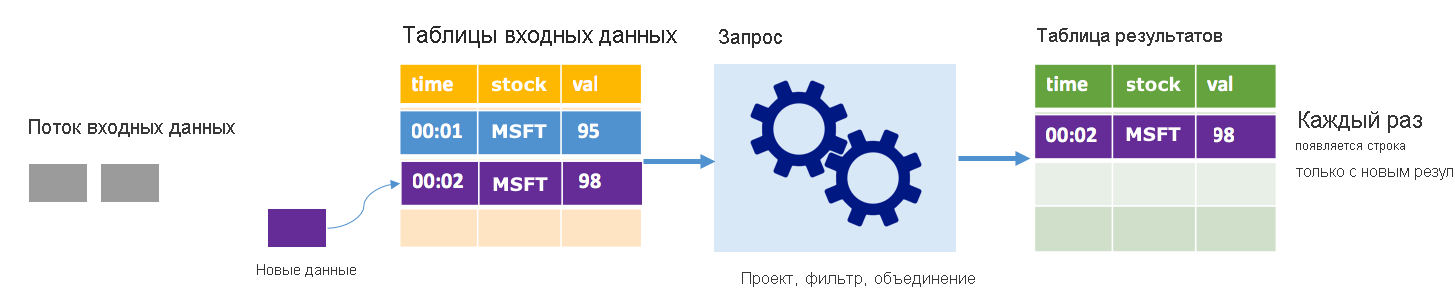
При использовании режима добавления в запросе будут применяться проекции (выбор нужных столбцов), фильтрация (выбор только строк, соответствующих определенным условиям) или объединение (дополнение данных данными из статической таблицы поиска). Режим добавления позволяет отправлять только нужные новые точки данных во внешнее хранилище.
Полный режим
Рассмотрим тот же сценарий с применением полного режима. В полном режиме вся таблица выходных данных обновляется при каждом триггере, поэтому она включает данные не только из последнего выполнения триггера, а из всех выполнений. Полный режим можно использовать для копирования данных из таблицы входных данных без изменений в таблицу результатов. При каждом запущенном выполнении новые строки результатов отображаются вместе со всеми предыдущими строками. В таблице выходных результатов будут храниться все данные, собранные с момента начала запроса, что в конечном итоге закончится нехваткой памяти. Полный режим предназначен для использования со статистическими запросами, которые обобщают входящие данные определенным образом, поэтому при каждом триггере таблица результатов обновляется с учетом новой сводки.
Предположим, что данные за пять секунд уже обработаны, теперь необходимо обработать данные за шестую секунду. В таблице входных данных есть события для времени 00:01 и времени 00:03. Рассматриваемый пример запроса предоставляет среднюю стоимость акции каждые пять секунд. В реализации этого запроса применяется статистическое выражение, которое принимает все значения, которые попадают в каждое 5-секундное окно, усредняет цену акции и создает строку для средней цены акции за этот интервал. По завершении первых 5 секунд есть два кортежа: (00:01, 1, 95) и (00:03, 1, 98). Итак, для окна 00:00–00:05 статистическая функция создает кортеж со средней ценой акций в 96,50 доллара США. В следующем 5-секундном окне в 00:06 имеется только одна точка данных, поэтому средняя цена акции составляет 98 долларов США. При использовании полного режима в 00:10 таблица результатов имеет строки для обоих окон (00: 00–00: 05 и 00:05–00:10), потому что запрос выводит все объединенные строки, а не только новые. Поэтому таблица результатов продолжает увеличиваться по мере добавления данных новых окон.
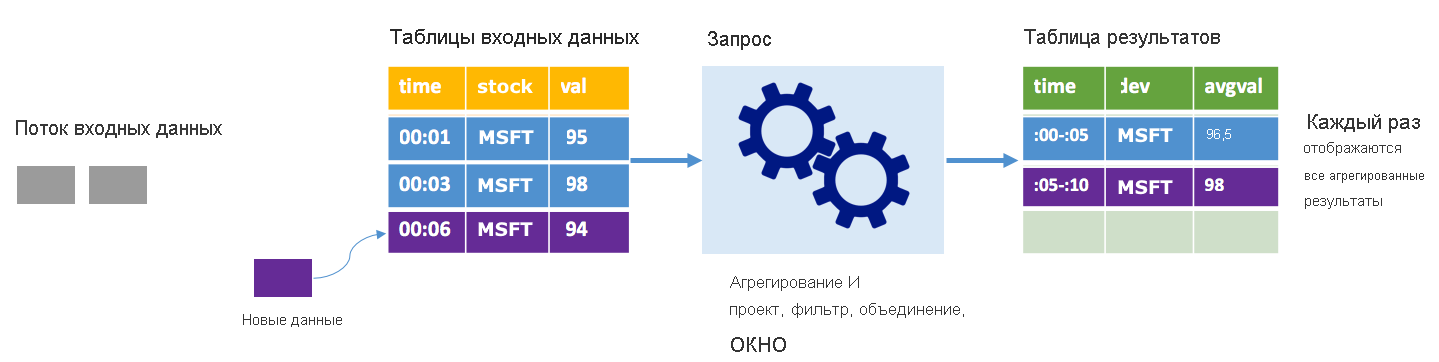
Не все запросы при использовании полного режима приведут к тому, что таблица будет расти без ограничений. Предположим, что в предыдущем примере вместо усреднения цены акции по временному окну выполняется усреднение по акции. Таблица результатов содержит фиксированное количество строк (по одной на акцию) со средней ценой для акций по всем полученным точкам данных. По мере получения новых цен таблица результатов обновляется таким образом, чтобы средние значения в таблице всегда были актуальными.
Каковы преимущества структурированной потоковой передачи Spark?
В финансовой сфере время транзакций имеет очень важное значение. Например, на фондовой бирже важно все: разница между тем, когда происходит торговля акциями на фондовой бирже, или когда получена транзакция, или когда данные считываются. Работа финансовых учреждений зависит от этих важных данных и времени, связанного с ними.
Время события, последние данные и пределы
Структурированная потоковая передача Spark знает разницу между временем события и временем обработки события системой. Каждое событие является строкой в таблице, а время события — значением столбца в строке. Это позволяет представлять статистические вычисления на основе окон (например, количество событий в каждую минуту) как группу и агрегат по столбцу времени события — каждое окно является группой, а каждая строка может принадлежать нескольким окнам или группам. Таким образом, такие статистические запросы на основе окна времени события могут быть определены одинаково как в статическом наборе данных, так и в потоке данных, что значительно упрощает работу инженера данных.
Более того, эта модель естественным образом обрабатывает данные, которые были получены позже, чем ожидалось, в зависимости от времени события. Spark полностью контролирует обновление старых агрегатов при наличии данных, поступивших с задержкой, а также очистку старых агрегатов для ограничения размера данных в промежуточном состоянии. Кроме того, начиная со Spark 2.1, Spark поддерживает пределы, что позволяет указать пороговое значение для данных, поступивших с опозданием, в результате чего подсистема соответствующим образом очищает старое состояние.
Гибкость при передаче последних данных или всех данных
Как обсуждалось выше, при работе со структурированной потоковой передачей Spark можно выбрать режим добавления или полный режим, чтобы таблица результатов включала только самые последние данные или все данные.
Поддержка перехода от микропакетов к непрерывной обработке
Изменив тип триггера запроса Spark, можно перейти от обработки микропакетов к непрерывной обработке без внесения других изменений в платформу. Ниже приведены различные виды триггеров, поддерживаемых Spark.
- Не указано — используется по умолчанию. Если нет явно заданных триггеров, запрос выполняется в микропакетах и будет обрабатываться непрерывно.
- Микропакеты через заданный интервал времени. Запрос отправляется через повторяющиеся интервалы времени, заданные пользователем. Если новые данные не получены, процесс микропакетной обработки не выполняется.
- Одноразовый микропакет. Запрос выполняет один микропакет, а затем останавливается. Это полезно, если необходимо обработать все данные, начиная с предыдущего микропакета, и сэкономить ресурсы для заданий, которые не нужно выполнять непрерывно.
- Непрерывно с фиксированным контрольным интервалом. Запрос выполняется в новом режиме низкой задержки, в режиме непрерывной обработки, который обеспечивает низкую задержку (~ 1 мс) с гарантиями отказоустойчивости по крайней мере один раз. Это похоже на триггер по умолчанию, который может обеспечить гарантию строго одного выполнения, но задержка при котором в лучшем случае составляет ~ 100 мс.
Объединение заданий пакетной и потоковой передачи
Помимо упрощения перехода от пакетной передачи к заданиям потоковой передачи, можно также сочетать задания пакетной и потоковой передачи. Это особенно полезно, если необходимо использовать данные за длительный период времени для прогнозирования будущих тенденций при обработке информации в режиме реального времени. В случае с акциями, помимо текущей цены акции, может потребоваться обратиться к их стоимости за последние 5 лет, чтобы спрогнозировать изменения относительно анонсов годовых или квартальных доходов.
Окна времени событий
Может потребоваться получить данные в окнах, например высокая стоимость акций и низкая стоимость акций в течение одного дня, одной минуты — любого определенного интервала — структурированная потоковая передача Spark поддерживает и это. Накладывающиеся окна также поддерживаются.
Создание контрольных точек для восстановления после сбоя
В случае сбоя или намеренного завершения работы можно восстановить предыдущий ход выполнения и состояние предыдущего запроса и продолжить с того места, где вы остановились. Для этого применяется создание контрольных точек и журналов с упреждающим протоколированием. Можно настроить запрос с указанием расположения контрольной точки, и запрос сохранит все сведения о ходе своего выполнения (т. е. диапазон смещений, обработанных в каждом триггере) и выполняющиеся статистические вычисления в расположении контрольной точки. Это расположение контрольной точки должно быть путем в файловой системе, совместимой с HDFS, и может быть задано в качестве параметра в DataStreamWriter при запуске запроса.