Нормализация и стандартизация
масштабирование компонентов — это метод, который изменяет диапазон значений, которые имеет функция. Это помогает моделям быстрее и надежнее учиться.
Нормализация и стандартизация
нормализация означает масштабирование значений, чтобы все они соответствовали определенному диапазону, как правило, 0–1. Например, если у вас есть список возрастов людей, которые были 0, 50 и 100 лет, можно нормализовать, разделив возраст на 100, чтобы ваши значения были 0, 0,5 и 1.
стандартизация аналогична, но вместо этого мы вычитаем среднее значение (также известное как среднее) значений и делим на стандартное отклонение. Если вы не знакомы со стандартным отклонением, не беспокоиться; это означает, что после стандартизации среднее значение равно нулю, а около 95% значений падают между -2 и 2.
Существуют и другие способы масштабирования данных, но нюансы этих возможностей выходят за рамки того, что нам нужно знать прямо сейчас. Давайте рассмотрим, почему мы применяем нормализацию или стандартизацию.
Почему нам нужно масштабировать?
Существует множество причин, по которым мы нормализуем или стандартизируем данные перед обучением. Эти вещи проще понять с помощью примера. Предположим, мы хотим обучить модель, чтобы предсказать, будет ли собака успешно работать в снеге. Наши данные отображаются на следующем графике как точки, и линия тренда, которую мы пытаемся найти, отображается как сплошная линия:
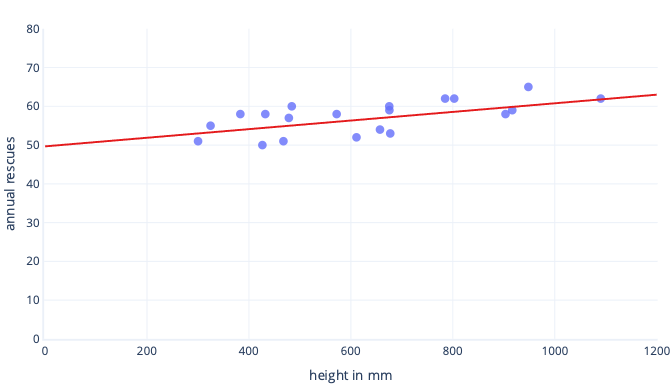
Масштабирование предоставляет обучению более удачную стартовую точку.
Оптимальная линия на предыдущем графике имеет два параметра: перехват, который равен 50, линия на x=0 и наклон, которая составляет 0,01; каждый 1000 миллиметров увеличивает спасения на 10. Предположим, мы начнем обучение с первоначальными оценками 0 для обоих этих параметров.
Если наши учебные итерации изменяют параметры примерно на 0,01 за итерацию в среднем, требуется по крайней мере 5000 итераций перед нахождением перехвата: 50 / 0,01 = 5000 итераций. Стандартизация позволяет сдвинуть оптимальное пересечение ближе к нулю, что означает, что мы можем найти его гораздо быстрее. Например, если вычитать среднее значение из нашей метки (ежегодные спасения) и наша функция (высота) перехват составляет -0,5, а не 50, что мы можем найти около 100 раз быстрее.
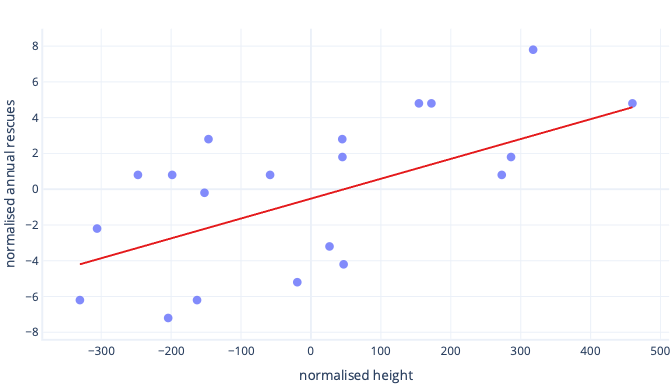
Существуют и другие причины, по которым сложные модели могут быть очень медленными для обучения, когда первоначальное предположение далеко от правильного решения, но решение по-прежнему одинаково: сдвинуть характеристики ближе к первоначальному предположению.
Стандартизация позволяет параметрам обучаться с той же скоростью
В новых данных смещения мы имеем идеальное смещение –0,5 и идеальный наклон 0,01. Хотя смещение помогает ускорить процесс, но обучение смещению все равно гораздо медленнее, чем обучение наклону. Это может замедлить работу и сделать обучение нестабильным.
Например, наши первоначальные предположения для смещения и наклона равны нулю. Если мы изменим наши параметры примерно на 0,1 на каждой итерации, мы быстро найдем смещение, но это будет очень трудно найти правильный наклон, потому что увеличение склона будет слишком большим (0 +0,1 > 0,01) и может перезахватить идеальное значение. Мы можем сделать корректировки меньшими, но это замедлит время, необходимое для поиска точки пересечения.
Что произойдет, если мы масштабируем нашу функцию высоты?
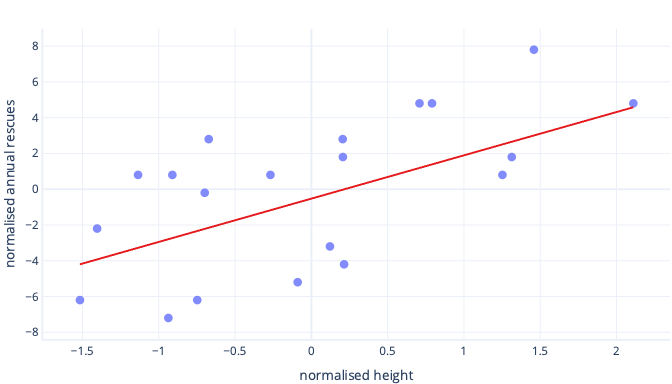
Наклон линии теперь составляет 0,5. Обратите внимание на ось x. Наш оптимальный пересечение -0,5 и наклон 0,5 находятся в одинаковом масштабе. Теперь легко выбрать разумный размер шага, что определяет скорость обновления параметров градиентного спуска.
Масштабирование помогает использовать несколько функций
При работе с несколькими функциями, наличие этих функций в другом масштабе может привести к проблемам в настройке, аналогично тому, как мы только что видели с примерами перехвата и наклона. Например, если мы обучаем модель, которая принимает как высоту в мм, так и вес в метрических тоннах, многим моделям будет сложно оценить важность признака веса, просто потому, что он выглядит таким незначительным по сравнению с признаками высоты.
Всегда ли мне нужно масштабироваться?
Мы не всегда должны масштабироваться. Некоторые виды моделей, в том числе предыдущие модели с прямыми линиями, могут быть подходят без итеративной процедуры, такой как градиентный спуск, чтобы они не думали о том, что функции неправильного размера. Другие модели нуждаются в масштабировании для хорошого обучения, но их библиотеки часто выполняют автоматическое масштабирование функций.
Как правило, единственными реальными недостатками нормализации или стандартизации является то, что это может сделать его труднее интерпретировать наши модели и что мы должны писать немного больше кода. По этой причине масштабирование функций является стандартной частью создания моделей машинного обучения.