Знакомство с Apache Spark
Apache Spark — это платформа распределенной обработки данных, которая обеспечивает аналитику данных в большом масштабе, координируя работу нескольких узлов обработки в кластере.
Принципы работы Spark
Приложения Apache Spark выполняются как независимые наборы процессов в кластере, координируемые объектом SparkContext в основной программе (называемой программой драйвера). SparkContext подключается к диспетчеру кластеров, который распределяет ресурсы между приложениями с помощью реализации Apache Hadoop YARN. После подключения Spark получает исполнителей на узлах кластера для выполнения кода приложения.
SparkContext выполняет основную функцию и параллельные операции на узлах кластера, а затем собирает результаты операций. Узлы считывают и записывают данные из файловой системы и обратно, а также кэшируют преобразованные данные в памяти как отказоустойчивые распределенные наборы данных (RDD).
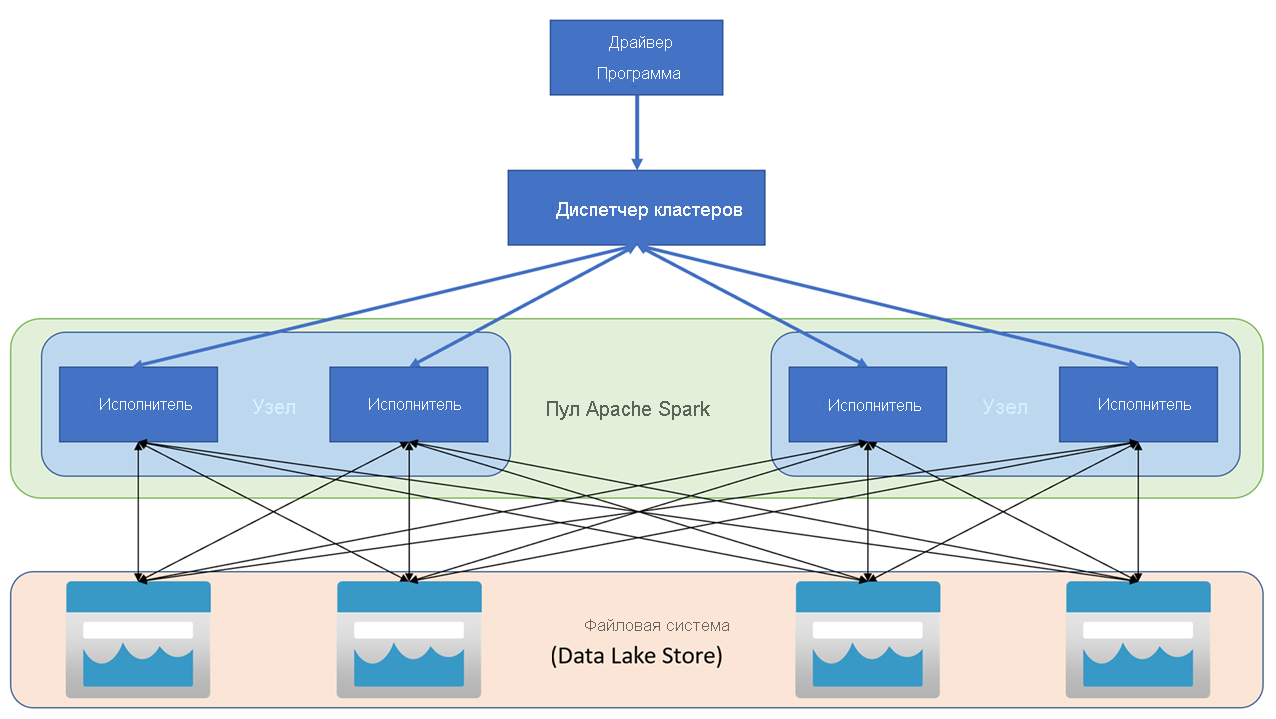
SparkContext отвечает за преобразование приложения в направленный ациклический граф (DAG). Граф состоит из отдельных задач, которые выполняются в рамках процесса исполнителя в узлах. Каждое приложение получает отдельные процессы исполнителя, которые остаются активными во время выполнения приложения и обрабатывают задачи в нескольких потоках.
Пулы Spark в Azure Synapse Analytics
В Azure Synapse Analytics кластер реализуется как пул Spark, который предоставляет среду выполнения для операций Spark. Вы можете создать один или несколько пулов Spark в рабочей области Azure Synapse Analytics с помощью портала Azure или в Azure Synapse Studio. При определении пула Spark можно указать параметры конфигурации для пула, в том числе:
- имя пула Spark;
- размер виртуальной машины, используемой для узлов в пуле, включая возможность использования узлов с поддержкой GPU с аппаратным ускорением;
- количество узлов в пуле, а также является ли размер пула фиксированным или же можно динамически подключать отдельные узлы для автоматического масштабирования кластера; в этом случае можно указать минимальное и максимальное количество активных узлов;
- версию среды выполнения Spark, которая будет использоваться в пуле; она определяет версии отдельных устанавливаемых компонентов, таких как Python, Java и др.
Совет
Дополнительные сведения о параметрах конфигурации пула Spark см. в разделе Конфигурации пула Apache Spark в Azure Synapse Analytics в документации по Azure Synapse Analytics.
Пулы Spark в рабочей области Azure Synapse Analytics являются бессерверными. Они запускаются по запросу и останавливаются в случае простоя.