Визуализация данных с помощью Spark
Одним из самых интуитивно понятных способов анализа результатов запросов к данным является их визуализация в виде диаграмм. Записные книжки в Azure Synapse Analytics предоставляют некоторые базовые возможности диаграмм в пользовательском интерфейсе, и когда эта функция не предоставляет необходимые функции, вы можете использовать одну из многих графических библиотек Python для создания и отображения визуализаций данных в записной книжке.
Использование встроенных диаграмм блокнота
При отображении кадра данных или запуске SQL-запроса в записной книжке Spark в Azure Synapse Analytics результаты отображаются в ячейке кода. По умолчанию результаты отображаются в виде таблицы, однако вы также можете изменить представление результатов на диаграмму и воспользоваться ее свойствами для настройки визуализации данных, как показано ниже:
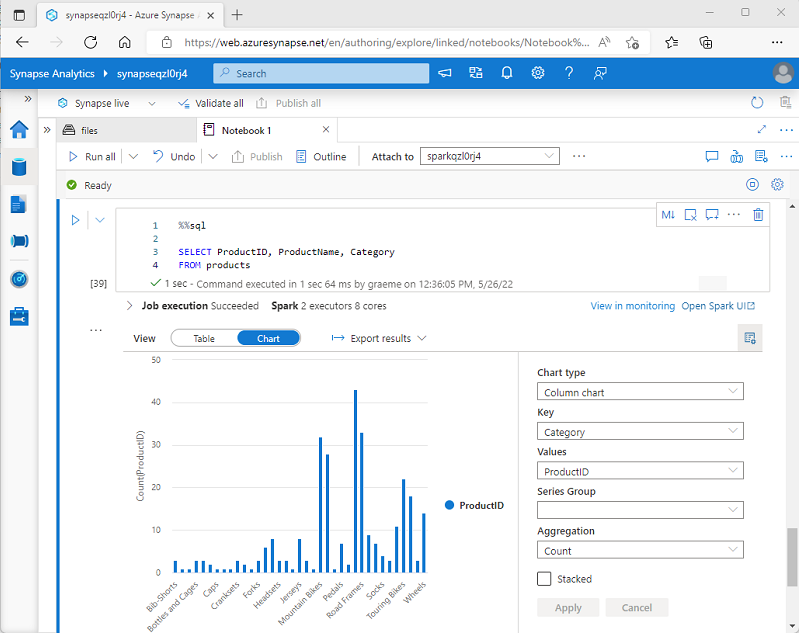
Встроенная функция построения диаграмм в записных книжках полезна, когда вы работаете с результатами запроса, не содержащего существующих группировок или агрегатов, и хотите быстро создать визуальное резюме данных. Если требуется больше контроля над форматированием данных или отображением значений, которые вы уже агрегировали в запросе, следует использовать графический пакет для создания собственных визуализаций.
Использование графических пакетов в коде
Для создания визуализаций данных в коде можно использовать множество графических пакетов. В частности, Python поддерживает целый ряд пакетов. В основе большинства из них лежит базовая библиотека Matplotlib. Вывод из графической библиотеки может быть отображен в записной книжке, упрощая процесс объединения кода для сбора и обработки данных с инлайн визуализациями данных и ячейками Markdown для комментариев.
Например, можно использовать следующий код PySpark для агрегирования данных из гипотетических данных продуктов, изученных ранее в этом модуле, и Matplotlib для создания диаграммы на основе агрегированных данных.
from matplotlib import pyplot as plt
# Get the data as a Pandas dataframe
data = spark.sql("SELECT Category, COUNT(ProductID) AS ProductCount \
FROM products \
GROUP BY Category \
ORDER BY Category").toPandas()
# Clear the plot area
plt.clf()
# Create a Figure
fig = plt.figure(figsize=(12,8))
# Create a bar plot of product counts by category
plt.bar(x=data['Category'], height=data['ProductCount'], color='orange')
# Customize the chart
plt.title('Product Counts by Category')
plt.xlabel('Category')
plt.ylabel('Products')
plt.grid(color='#95a5a6', linestyle='--', linewidth=2, axis='y', alpha=0.7)
plt.xticks(rotation=70)
# Show the plot area
plt.show()
Библиотека Matplotlib требует, чтобы данные находились в кадре данных Pandas, а не в кадре данных Spark, поэтому для их преобразования применяется метод toPandas. Затем код создает фигуру указанного размера и строит линейчатую диаграмму с некоторой настраиваемой конфигурацией свойств, и только после этого отображается итоговая диаграмма.
Диаграмма, созданная кодом, будет выглядеть примерно так:
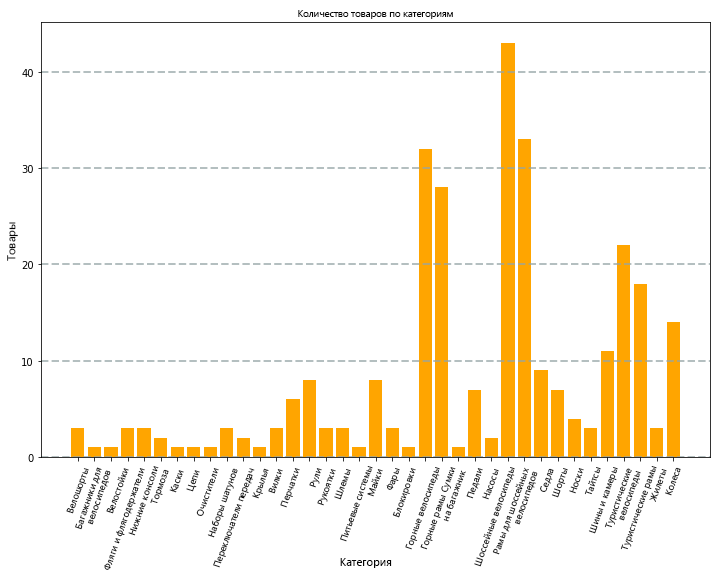
С помощью библиотеки Matplotlib можно создавать самые разные диаграммы; однако для создания диаграмм с высоким уровнем настройки можно использовать и другие библиотеки, такие как Seaborn.