Общие сведения о регулярных выражениях
В этом уроке вы ознакомитесь с регулярными выражениями. Регулярные выражения удобно использовать для сопоставления текстовых шаблонов. Они также используются разработчиками и специалистами по обработке и анализу данных.
Регулярные выражения (regex) невероятно полезны, и, скорее всего, вы уже сталкивались с ними. Этот эзотерический мини-язык помогает в сложном сопоставлении шаблонов и поначалу может выглядеть непонятным. Однако регулярные выражения можно найти в большинстве текстовых редакторов, языков и инструментов, например в Python, SQL, Go, Scala и многих других. Их определенно стоит изучить.
Полезное онлайн-средство, которое стоит сохранить в закладках, — это Регулярные выражения 101, позволяющее тестировать регулярные выражения с использованием тестовых входных данных.
Литералы и специальные символы
Вкратце, регулярное выражение представляет собой доступный способ определения шаблона символов и в основном используется для идентификации шаблона, интеллектуального анализа текста или проверки входных данных. Указанный шаблон может быть широким или конкретным и строго считывается слева направо. Входные данные регулярного выражения всегда являются текстовой строкой.
Большинство символов (буквенные и числовые) не имеют специальных функций и буквально соответствуют этому символу. Регулярное выражение SSH совпадает только со строкой "SSH". Если входная строка содержит текст "ZSH", шаблон регулярного выражения не найдет совпадения.
Если вы завершили предыдущий урок, у вас уже есть образец открытого набора данных НАСА. Мы будем использовать этот набор данных, чтобы выполнить сопоставление шаблонов с регулярным выражением в песочнице Azure Cloud Shell.
codeИспользуйте команду, чтобы открыть файлNASA-software-API.txt в редакторе Cloud Shell:code NASA-software-API.txtФайл откроется во встроенном редакторе над запросом Cloud Shell.
Откройте поле поиска для встроенного редактора:
Щелкните мышью в любом месте в окне редактора.
Нажмите клавиши CTRL+F (в Windows или Linux) или Cmd+F (в macOS).
Во встроенном редакторе откроется поле поиска.
Выберите значок regex (
.*), чтобы включить сопоставление шаблонов regex для поиска файла в редакторе: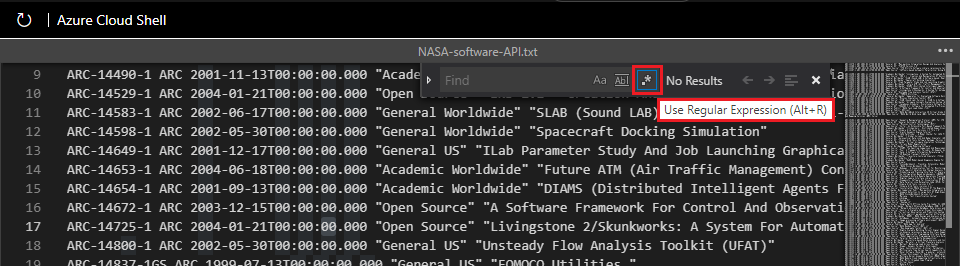
В поле поиска введите строку
Open Source.С включенным параметром regex Cloud Shell выделяет все экземпляры содержимого, соответствующего входной строке. Число совпадений отображается в поле поиска.
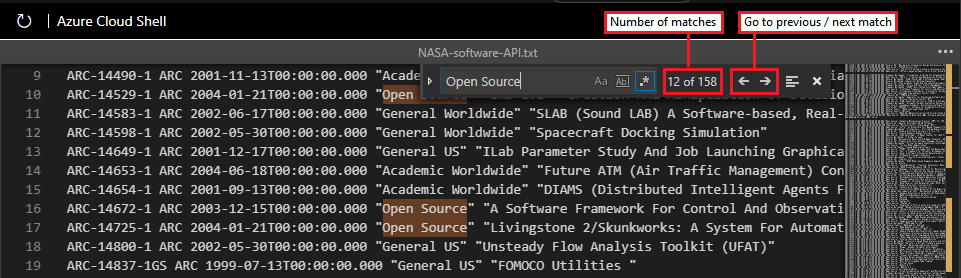
Вы можете использовать значки стрелки влево (предыдущее) и справа (далее) в поле поиска, чтобы увидеть каждый соответствующий экземпляр в файле.


Может показаться, что этот метод не отличается от любых других вариантов использования поля поиска. Преимущества регулярных выражений проявятся при поиске с использованием специальных символов, диапазонов и привязок.
Сопоставление символов и диапазоны
Итак, вы узнали, что регулярное выражение можно использовать для буквального сопоставления символов. Предположим, вам нужно найти версии программного обеспечения, указанные в файле. Вы хотите найти версии в формате типа "v1."
Вы знаете, что все версии должны начинаться с буквы "v". Оставшуюся часть строки поиска можно заключить в квадратные скобки: []. Квадратные скобки означают "любой символ в этом списке". Чтобы найти версии, начинающиеся с цифры от 1 до 5, можно выполнить поиск по регулярному выражению v[12345].
Давайте попробуем использовать этот тип шаблона регулярного выражения в файле NASA-software-API.txt file.
В поле поиска введите
ARC-14[456], чтобы найти текст, содержащий слово "ARC-14", за которым следует цифра 4, 5 или 6.Вы должны получить 12 результатов.
Используйте значки со стрелками влево и вправо в поле поиска, чтобы просмотреть каждое совпадение в файле.
Использовать такое регулярное выражение, как в этом примере, просто, поскольку в содержимом есть только три цифры для поиска (4, 5, 6). Но как выполнить сопоставление по всему алфавиту или многим цифрам, не вводя каждый символ отдельно?
Можно определить последовательный диапазон букв или цифр. Для всех цифр можно создать диапазон: [0-9]. Для строчных букв можно использовать диапазон [a-z].
Давайте найдем все вхождения слова "ARC-14", за которым следует любая цифра.
В поле поиска введите
ARC-14[0-9], чтобы найти текст, содержащий слово "ARC-14", за которым следует любая цифра.Вы должны получить 22 результата.
Вот некоторые строки в файле, которые соответствуют этому шаблону:
ARC-14293-1 ARC 2005-09-19T00:00:00.000 "Open Source" "Genetic Graphs (JavaGenes)" ... ARC-14400-1 ARC 2001-01-29T00:00:00.000 "General US" "PLOT3D Version 4.0" ... ARC-14837-1GS ARC 1999-07-13T00:00:00.000 "General US" "FOMOCO Utilities " ... ARC-14932-1 ARC 2005-01-12T00:00:00.000 "Open Source" "Mission Simulation Toolkit (MST)"
Подстановочные знаки
Символ (.) — это специальный тип символа, называемый подстановочным знаком. Он может использоваться для обозначения любого символа, например букв, цифр, пробелов, символов новой строки, знаков препинания и знаков. Например, чтобы найти все сочетания трех символов, которые начинаются с буквы "g" и заканчиваются буквой "t", нужно использовать регулярное выражение g.t.
Распространенный шаблон, используемый в регулярных выражениях, — точка, за которой следует звездочка (.*). Этот синтаксис регулярного выражения позволяет сопоставить любой символ ноль или более раз.
Давайте попробуем использовать этот шаблон регулярного выражения с подстановочными знаками, чтобы найти текст, содержащий слово "NASA", за которым следует любой другой символ.
В поле поиска введите
NASA.*, чтобы найти соответствующий текст.Вы должны получить 26 результатов.
Вот некоторые строки в файле, которые соответствуют этому шаблону:
NASA Root Cause Analysis Tool ... NASA's Moderate Resolution Imaging Spectrometer (MODIS)-Combined Ocean Color ... NASA, Average-Passage Multistage Turbomachinery Flow Field Analysis Code ... NASA - Average Passage Flow Solver) ... NASA/NESSUS 6.2c Probabilistic Structural Analysis Software
Привязки
При сопоставлении последовательностей, которые встречаются в определенной части строки или слова, это называется привязкой. Существует два типа привязок:
-
Начало строки: используйте символ (
^), если шаблон поиска должен рассматривать последовательность как совпадение, только если совпадающая часть находится в начале строки. -
Конец строки: используйте символ доллара (
$) в том случае, если шаблон поиска должен считать последовательность символов совпадением только в том случае, если соответствующая часть отображается в конце строки.
Теперь можно написать регулярное выражение, которое будет сопоставлять числа в начале строки (^[0-9]) или в конце строки ([0-9]$).
Давайте попробуем использовать шаблоны привязки регулярного выражения для поиска совпадений, где "A" является первым или последним символом во введенной строке.
В поле поиска введите
^[A-G], чтобы найти текст, начинающийся с букв A–G.Вы должны получить 258 результатов.
Введите
[A-G]$, чтобы найти текст, заканчивающийся буквами A–G.Вы получите три результата:
LAR-16939-GS LaRC 2000-11-07T00:00:00.000 "General Public" DeMAID1m.sea ... GSC-16207-1 GSFC 2011-04-12T00:00:00.000 "Open Source" "Goddard Mission Services Evolution Center Architecture Application Programming Interface (GMSEC ... LEW-16018-1 GRC 2003-01-05T00:00:00.000 "General US" CARES/LIFE
Экранирование символов
Предположим, нам нужно найти строки, в которых точка (.) является последним символом. Мы знаем, что знак доллара ($) является привязкой конца строки, поэтому в поле поиска можно ввести .$. Но это регулярное выражение не вернет совпадения, которые мы ищем. Как описано ранее, период (.) соответствует любому одному символу. Поскольку каждая строка заканчивается символом, в результатах возвращается каждая строка.
Как запретить специальному символу выполнять функцию в регулярном выражении, если мы хотим найти этот конкретный символ? Обратная косая черта (\) используется для экранирования символа, который требуется найти. Чтобы найти строки, в которых точка (.) является последним символом, мы используем выражение \.$.
Давайте попробуем использовать escape-символ в поисковом запросе с использованием регулярного выражения в файле НАСА.
В поле поиска введите
\.$, чтобы найти текст, заканчивающийся точкой (.).Вы получите ноль результатов. Ни одна строка в этом файле не заканчивается точкой.
В поле поиска введите
\*\*, чтобы найти вхождения двойной звездочки (**) в файле.Шаблону поиска соответствует одна строка в файле:
LLEW-17324-1 GRC 2001-01-05T00:00:00.000 "General US" "CANCELLED ** Same As LEW-16855-1 (APNASA - Average Passage Flow Solver)"
Памятка по регулярным выражениям
В этом уроке вы кратко познакомились с регулярными выражениями и вариантами их использования. С помощью регулярных выражений можно создать множество других сложных шаблонов. Вам поможет памятка по регулярным выражениям.
| Регулярное выражение | Определение |
|---|---|
| ^ | Соответствует началу строки. |
| $ | Соответствует концу строки. |
| . | Соответствует любому символу. |
| \s | Соответствует пробелу. |
| \S | Соответствует любому символу, не являющемуся пробелом. |
| * | Повторяет символ ноль или более раз. |
| *? | Повторяет символ ноль или более раз (нежадное сопоставление). |
| + | Повторяет символ один или более раз. |
| +? | Повторяет символ один или более раз (нежадное сопоставление). |
| [aeiou] | Соответствует одному символу из указанного набора. |
| [^XYZ] | Соответствует одному символу, не входящему в указанный набор. |
| [a-z0-9] | Набор символов может включать диапазон. |
| ( | Указывает, откуда следует начинать извлечение строк. |
| ) | Указывает, где следует закончить извлечение строк. |
Дополнительные сведения о Visual Studio Code и регулярных выражениях см. в документации по Visual Studio Code.