Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Используйте сведения, приведенные в этой статье, чтобы устранить неполадки с развертыванием Локальные дисковые пространства.
Как правило, начните с следующих действий:
- Убедитесь, что модель SSD сертифицирована для Windows Server 2016 и Windows Server 2019 с помощью каталога Windows Server. Убедитесь, что диски поддерживаются для Локальные дисковые пространства.
- Проверьте хранилище для всех неисправных дисков. Используйте программное обеспечение для управления хранилищем, чтобы проверить состояние дисков. Если любой из дисков неисправен, обратитесь к поставщику.
- При необходимости обновите встроенное ПО хранилища и диска. Убедитесь, что на всех узлах установлены последние Обновл. Windows. Последние обновления для Windows Server 2016 можно получить из журнала обновлений Windows 10 и Windows Server 2016. Получите последние обновления для Windows Server 2019 из журнала обновлений Windows 10 и Windows Server 2019.
- Обновите драйверы и встроенное ПО сетевого адаптера.
- Запустите проверку кластера и просмотрите раздел "Локальный дисковые пространства". Убедитесь, что диски, используемые для кэша, сообщаются правильно и не имеют ошибок.
Если у вас по-прежнему возникли проблемы, просмотрите сведения об устранении неполадок для каждой из конкретных проблем в этой статье.
Ресурсы виртуального диска находятся в состоянии "Без избыточности"
Узлы Локальные дисковые пространства системы неожиданно перезапускается из-за сбоя или сбоя питания. Затем один или несколько виртуальных дисков могут не подключаться, и вы увидите описание недостаточная информация об избыточности.
| Понятное имя | ОтказоустойчивостьSettingName | ОперативныйСтатус | Состояние здоровья | Ручное присоединение | Размер | PSComputerName |
|---|---|---|---|---|---|---|
| Диск 4 | Зеркальное отображение | ОК | Работоспособно | Истина | 10 ТБ | Node-01.conto... |
| Диск 3 | Зеркальное отображение | ОК | Работоспособно | Истина | 10 ТБ | Узел-01.contoso. |
| Диск 2 | Зеркальное отображение | Отсутствие избыточности | Нездоровый | Истина | 10 ТБ | Узел-01.contoso. |
| Диск 1 | Зеркальное отображение | {Нет избыточности, InService} | Нездоровый | Истина | 10 ТБ | Узел-01.contoso. |
Кроме того, после попытки подключить виртуальный диск к сети, следующие сведения записываются в журнал кластера.DiskRecoveryAction
[Verbose] 00002904.00001040::YYYY/MM/DD-12:03:44.891 INFO [RES] Physical Disk <DiskName>: OnlineThread: SuGetSpace returned 0.
[Verbose] 00002904.00001040:: YYYY/MM/DD -12:03:44.891 WARN [RES] Physical Disk < DiskName>: Underlying virtual disk is in 'no redundancy' state; its volume(s) may fail to mount.
[Verbose] 00002904.00001040:: YYYY/MM/DD -12:03:44.891 ERR [RES] Physical Disk <DiskName>: Failing online due to virtual disk in 'no redundancy' state. If you would like to attempt to online the disk anyway, first set this resource's private property 'DiskRecoveryAction' to 1. We will try to bring the disk online for recovery, but even if successful, its volume(s) or CSV may be unavailable.
Состояние эксплуатации без избыточности возникает, если диск вышел из строя или если система не может получить доступ к данным на виртуальном диске. Эта проблема может возникнуть, если перезагрузка происходит на узле во время обслуживания на узлах.
Чтобы устранить проблему, выполните указанные ниже действия.
Удалите затронутые виртуальные диски из CSV-файла. Это позволяет поместить их в доступную группу хранения в кластере и начинает отображаться как ResourceType
Physical Disk.Remove-ClusterSharedVolume -Name "CSV Name"На узле, владеющего группой доступных хранилищ, выполните следующую команду на каждом диске, который находится в состоянии избыточности. Чтобы определить, на каком узле находится группа доступных хранилищ, можно выполнить следующую команду:
Get-ClusterGroupЗадайте действие восстановления диска и запустите диски.
Get-ClusterResource "Physical Disk Resource Name" | Set-ClusterParameter -Name DiskRecoveryAction -Value 1 Start-ClusterResource -Name "Physical Disk Resource Name"Восстановление должно начинаться автоматически. Дождитесь завершения ремонта. Он может перейти в приостановленное состояние и начать снова. Чтобы отслеживать ход выполнения, выполните следующие действия.
- Запустите
Get-StorageJob, чтобы отслеживать состояние восстановления и узнать, когда оно завершено. - Запустите
Get-VirtualDiskи убедитесь, что пробел возвращает значение HealthStatus для работоспособности.
- Запустите
После завершения восстановления и работоспособности виртуальных дисков измените параметры виртуального диска обратно.
Get-ClusterResource "Physical Disk Resource Name" | Set-ClusterParameter -Name DiskRecoveryAction -Value 0Перейдите в автономный режим, а затем снова в сети, чтобы войти в
DiskRecoveryActionсилу:Stop-ClusterResource "Physical Disk Resource Name" Start-ClusterResource "Physical Disk Resource Name"Добавьте затронутые виртуальные диски обратно в CSV-файл.
Add-ClusterSharedVolume -Name "Physical Disk Resource Name"
DiskRecoveryAction — это переопределяющий параметр, позволяющий подключить том пробела в режиме чтения и записи без каких-либо проверок. Свойство позволяет диагностировать, почему том не поступает в интернет. Он похож на режим обслуживания, но его можно вызвать в ресурсе в состоянии сбоя. Кроме того, он позволяет получить доступ к данным, чтобы скопировать их. Этот доступ полезен в ситуациях без избыточности. Свойство DiskRecoveryAction было добавлено 22 февраля 2018 г. в обновлении базы знаний 4077525.
Состояние отсоединения в кластере
При запуске командлета Get-VirtualDiskOperationalStatus один или несколько виртуальных дисков Локальные дисковые пространства отсоединяются. Тем не менее, HealthStatus, сообщаемый Get-PhysicalDisk командлетом, указывает, что все физические диски находятся в работоспособном состоянии.
В этом примере показаны выходные данные командлета Get-VirtualDisk .
| Понятное имя | ОтказоустойчивостьSettingName | ОперативныйСтатус | Состояние здоровья | Ручное присоединение | Размер | PSComputerName |
|---|---|---|---|---|---|---|
| Диск 4 | Зеркальное отображение | ОК | Работоспособно | Истина | 10 ТБ | Узел-01.contoso. |
| Диск 3 | Зеркальное отображение | ОК | Работоспособно | Истина | 10 ТБ | Узел-01.contoso. |
| Диск 2 | Зеркальное отображение | Отсоединен | Неизвестно | Истина | 10 ТБ | Узел-01.contoso. |
| Диск 1 | Зеркальное отображение | Отсоединен | Неизвестно | Истина | 10 ТБ | Узел-01.contoso. |
Кроме того, на узлах могут быть зарегистрированы следующие события:
Log Name: Microsoft-Windows-StorageSpaces-Driver/Operational
Source: Microsoft-Windows-StorageSpaces-Driver
Event ID: 311
Level: Error
User: SYSTEM
Computer: Node#.contoso.local
Description: Virtual disk {GUID} requires a data integrity scan.
Data on the disk is out-of-sync and a data integrity scan is required.
To start the scan, run this command:
Get-ScheduledTask -TaskName "Data Integrity Scan for Crash Recovery" | Start-ScheduledTask
Once you have resolved that condition, you can online the disk by using these commands in PowerShell:
Get-VirtualDisk | ?{ $_.ObjectId -Match "{GUID}" } | Get-Disk | Set-Disk -IsReadOnly $false
Get-VirtualDisk | ?{ $_.ObjectId -Match "{GUID}" } | Get-Disk | Set-Disk -IsOffline $false
------------------------------------------------------------
Log Name: System
Source: Microsoft-Windows-ReFS
Event ID: 134
Level: Error
User: SYSTEM
Computer: Node#.contoso.local
Description: The file system was unable to write metadata to the media backing volume <VolumeId>. A write failed with status "A device which does not exist was specified." ReFS will take the volume offline. It might be mounted again automatically.
------------------------------------------------------------
Log Name: Microsoft-Windows-ReFS/Operational
Source: Microsoft-Windows-ReFS
Event ID: 5
Level: Error
User: SYSTEM
Computer: Node#.contoso.local
Description: ReFS failed to mount the volume.
Context: 0xffffbb89f53f4180
Error: A device which does not exist was specified.
Volume GUID:{00000000-0000-0000-0000-000000000000}
DeviceName:
Volume Name:
Происходит, Detached Operational Status если журнал отслеживания грязных регионов (DRT) заполнен. дисковые пространства использует отслеживание грязных регионов (DRT) для зеркальных пространств, чтобы гарантировать, что при сбое питания регистрируются все обновления в тестовом режиме для метаданных. Зарегистрированные обновления гарантируют, что дисковое пространство может повторно выполнять или отменять операции. Они возвращают дисковое пространство гибкому и согласованному состоянию после восстановления питания, а система выполняет резервное копирование. Если журнал DRT заполнен, виртуальный диск не может быть подключен к сети, пока метаданные DRT не синхронизированы и удалены. Для этого процесса требуется выполнить полную проверку, которая может занять несколько часов.
Чтобы устранить проблему, выполните указанные ниже действия.
Удалите затронутые виртуальные диски из CSV-файла.
Remove-ClusterSharedVolume -Name "CSV Name"Выполните эти команды на каждом диске, который не подключен к сети.
Get-ClusterResource -Name "Physical Disk Resource Name" | Set-ClusterParameter DiskRunChkDsk 7 Start-ClusterResource -Name "Physical Disk Resource Name"Выполните следующую команду на каждом узле, в котором отключенный том находится в сети.
Get-ScheduledTask -TaskName "Data Integrity Scan for Crash Recovery" | Start-ScheduledTaskИнициируйте эту задачу на всех узлах, на которых отключенный том находится в сети. Восстановление должно начинаться автоматически. Дождитесь завершения ремонта. Он может перейти в приостановленное состояние и начать снова. Чтобы отслеживать ход выполнения, выполните следующие действия.
- Запустите
Get-StorageJob, чтобы отслеживать состояние восстановления и узнать, когда оно завершено. - Запустите
Get-VirtualDiskи проверьте, что пробел возвращает значение HealthStatus для работоспособности.Проверка целостности данных для аварийного восстановления — это задача, которая не отображается как задание хранилища, и индикатор хода выполнения отсутствует. Если задача отображается как запущенная, она выполняется. По завершении отображается завершено.
Кроме того, можно просмотреть состояние выполняемой задачи расписания с помощью этого командлета:
Get-ScheduledTask | ? State -eq running
- Запустите
После завершения проверки целостности данных для аварийного восстановления восстановление завершится, а виртуальные диски работоспособны. Измените параметры виртуального диска обратно.
Get-ClusterResource -Name "Physical Disk Resource Name" | Set-ClusterParameter DiskRunChkDsk 0Перейдите в автономный режим, а затем снова в сети, чтобы войти в
DiskRecoveryActionсилу:Stop-ClusterResource "Physical Disk Resource Name" Start-ClusterResource "Physical Disk Resource Name"Добавьте затронутые виртуальные диски обратно в CSV-файл.
Add-ClusterSharedVolume -Name "Physical Disk Resource Name"Используется
DiskRunChkdsk value 7для подключения тома пробела и задания секции в режиме только для чтения. Это действие позволяет Пробелам самостоятельно обнаруживать и самовосстановляться путем активации восстановления. Восстановление выполняется автоматически после подключения. Он также позволяет получить доступ к данным для копирования. Для некоторых условий сбоя, таких как полный журнал DRT, необходимо запустить задачу проверки целостности данных для запланированной задачи аварийного восстановления.
Используйте задачу проверки целостности данных для аварийного восстановления, чтобы синхронизировать и очистить полный журнал отслеживания грязных регионов (DRT). Эта задача может занять несколько часов. Проверка целостности данных для аварийного восстановления — это задача, которая не отображается как задание хранилища, и индикатор хода выполнения отсутствует. Если задача отображается как запущенная, она выполняется. По завершении он отображается как завершенное. Если вы отменяете задачу или перезапускаете узел во время выполнения этой задачи, задача должна начинаться с самого начала.
Для получения дополнительной информации см. раздел «Устранение неполадок с состоянием работоспособности и операционными состояниями Storage Spaces Direct».
Событие 5120 с STATUS_IO_TIMEOUT c00000b5
Внимание
Для Windows Server 2016. Чтобы уменьшить вероятность возникновения этих симптомов при применении обновления с исправлением, рекомендуется использовать процедуру обслуживания хранилища для установки накопительного обновления Windows Server 2016 18 октября 2018 г. или более поздней версии, когда узлы в настоящее время установили накопительное обновление Windows Server 2016, выпущенное с 8 мая, 2018 – 9 октября 2018 г.
Вы можете получить событие 5120 с STATUS_IO_TIMEOUT c00000b5 после перезапуска узла на Windows Server 2016 с установленным накопительным обновлением, выпущенным с 8 мая 2018 г. KB4103723 до 9 октября 2018 г. KB4462917.
При перезапуске узла событие 5120 регистрируется в журнале системных событий и включает один из следующих кодов ошибок:
Event Source: Microsoft-Windows-FailoverClustering
Event ID: 5120
Description: Cluster Shared Volume 'CSVName' ('Cluster Virtual Disk (CSVName)') has entered a paused state because of 'STATUS_IO_TIMEOUT(c00000b5)'. All I/O will temporarily be queued until a path to the volume is reestablished.
Cluster Shared Volume 'CSVName' ('Cluster Virtual Disk (CSVName)') has entered a paused state because of 'STATUS_CONNECTION_DISCONNECTED(c000020c)'. All I/O will temporarily be queued until a path to the volume is reestablished.
При регистрации события 5120 динамический дамп создает для сбора сведений об отладке, которые могут вызвать другие симптомы или повлиять на производительность. При создании динамического дампа это приводит к краткой паузе. Пауза позволяет моментальному снимку памяти записывать файл дампа. Системы с большим объемом памяти и при стрессе могут привести к удалению узлов из членства в кластере и вызвать запись следующего события 1135.
Event source: Microsoft-Windows-FailoverClustering
Event ID: 1135
Description: Cluster node 'NODENAME'was removed from the active failover cluster membership. The Cluster service on this node might have stopped. This could also be due to the node having lost communication with other active nodes in the failover cluster. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapters on this node. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Изменение, введенное 8 мая 2018 г. на Windows Server 2016, было накопительным обновлением для добавления устойчивых дескрипторов SMB для Локальные дисковые пространства сетевых сеансов SMB внутри кластера. Это обновление было сделано, чтобы повысить устойчивость временных сбоев сети и улучшить способ обработки перегрузки сети RoCE. Эти улучшения также непреднамеренно увеличили время ожидания при попытке повторного подключения SMB и ожидания ожидания при перезапуске узла. Эти проблемы могут повлиять на систему, которая находится под стрессом. Во время незапланированного простоя операции ввода-вывода приостанавливаются до 60 секунд, в то время как система ожидает истечения времени ожидания подключений. Чтобы устранить эту проблему, установите накопительное обновление для Windows Server 2016 или более поздней версии 18 октября 2018 г.
Примечание.
Это обновление выравнивает время ожидания CSV с временем ожидания подключения SMB, чтобы устранить эту проблему. Он не реализует изменения, чтобы отключить создание динамического дампа, упомянутое в разделе обходного решения.
Поток процесса завершения работы
Запустите командлет Get-VirtualDisk и убедитесь, что значение HealthStatus работоспособно.
Слив узел, выполнив этот командлет:
Suspend-ClusterNode -DrainПоместите диски на этот узел в режим обслуживания хранилища, выполнив следующий командлет:
Get-StorageFaultDomain -Type StorageScaleUnit | Where-Object {$_.FriendlyName -eq "<NodeName>"} | Enable-StorageMaintenanceModeGet-PhysicalDiskЗапустите командлет и убедитесь, чтоOperationalStatusзначение являетсяIn Maintenanceрежимом.Restart-ComputerЗапустите командлет, чтобы перезапустить узел.После перезапуска узла удалите диски на этом узле из режима обслуживания хранилища, выполнив следующий командлет:
Get-StorageFaultDomain -Type StorageScaleUnit | Where-Object {$_.FriendlyName -eq "<NodeName>"} | Disable-StorageMaintenanceModeВозобновите узел, выполнив этот командлет:
Resume-ClusterNodeПроверьте состояние заданий повторной синхронизации, выполнив этот командлет:
Get-StorageJob
Отключение динамических дампов
Чтобы снизить влияние создания динамического дампа на системы с большим объемом памяти и при стрессе, вы можете отключить создание динамического дампа. Предоставляются следующие три варианта:
Внимание
Эта процедура может предотвратить сбор диагностических сведений, которые служба поддержки Майкрософт, возможно, потребуется изучить эту проблему. Агент поддержки может попросить повторно включить создание динамического дампа на основе конкретных сценариев устранения неполадок.
Отключение всех дампов
Чтобы полностью отключить все дампы, включая динамические дампы на уровне системы, выполните следующие действия. Используйте эту процедуру для этого сценария:
- Создайте следующий раздел реестра: HKLM\System\CurrentControlSet\Control\CrashControl\ForceDumpsDisabled
- В разделе нового ключа ForceDumpsDisabled создайте свойство REG_DWORD как GuardedHost, а затем задайте для нее значение 0x10000000.
- Примените новый раздел реестра к каждому узлу кластера.
Примечание.
Чтобы изменения nregistry вступили в силу, необходимо перезапустить компьютер.
После установки этого ключа реестра создание снимка дампа завершится сбоем и вызовет ошибку STATUS_NOT_SUPPORTED.
Разрешить только один LiveDump
По умолчанию отчеты об ошибках Windows разрешает только один liveDump для каждого типа отчета в семь дней и только один LiveDump на компьютер в течение пяти дней. Вы можете изменить это, задав следующие разделы реестра, чтобы разрешить только один LiveDump на компьютере навсегда.
reg add "HKLM\Software\Microsoft\Windows\Windows Error Reporting\FullLiveKernelReports" /v SystemThrottleThreshold /t REG_DWORD /d 0xFFFFFFFF /f
reg add "HKLM\Software\Microsoft\Windows\Windows Error Reporting\FullLiveKernelReports" /v ComponentThrottleThreshold /t REG_DWORD /d 0xFFFFFFFF /f
Примечание.
Чтобы изменения вступили в силу, необходимо перезапустить компьютер.
Отключение создания кластера
Чтобы отключить создание динамических дампов кластера (например, при регистрации события 5120), выполните следующий командлет:
(Get-Cluster).DumpPolicy = ((Get-Cluster).DumpPolicy -Band 0xFFFFFFFFFFFFFFFE)
Этот командлет немедленно влияет на все узлы кластера без перезагрузки компьютера.
Низкая производительность операций ввода-вывода
Если вы видите низкую производительность ввода-вывода, проверьте, включен ли кэш в конфигурации Локальные дисковые пространства.
Существует два способа проверить:
Используйте журнал кластера. Откройте журнал кластера с помощью текстового редактора и выполните поиск по запросу "[=== диски SBL ===]". Вы увидите список дисков на узле, в который был создан журнал.
Пример дисков с поддержкой кэша: обратите внимание на то, что состояние есть
CacheDiskStateInitializedAndBoundи есть GUID, представленный здесь.[=== SBL Disks ===] {26e2e40f-a243-1196-49e3-8522f987df76},3,false,true,1,48,{1ff348f1-d10d-7a1a-d781-4734f4440481},CacheDiskStateInitializedAndBound,1,8087,54,false,false,HGST,HUH721010AL4200,7PG3N2ER,A21D,{d5e27a3b-42fb-410a-81c6-9d8cc12da20c},[R/M 0 R/U 0 R/T 0 W/M 0 W/U 0 W/T 0],Кэш не включен: здесь можно увидеть, что нет GUID и состояние
CacheDiskStateNonHybrid.[=== SBL Disks ===] {426f7f04-e975-fc9d-28fd-72a32f811b7d},12,false,true,1,24,{00000000-0000-0000-0000-000000000000},CacheDiskStateNonHybrid,0,0,0,false,false,HGST,HUH721010AL4200,7PGXXG6C,A21D,{d5e27a3b-42fb-410a-81c6-9d8cc12da20c},[R/M 0 R/U 0 R/T 0 W/M 0 W/U 0 W/T 0],Кэш не включен. Если все диски имеют одинаковый тип, по умолчанию регистр не включен. Здесь вы увидите, что отсутствует GUID, и состояние отсутствует
CacheDiskStateIneligibleDataPartition.{d543f90c-798b-d2fe-7f0a-cb226c77eeed},10,false,false,1,20,{00000000-0000-0000-0000-000000000000},CacheDiskStateIneligibleDataPartition,0,0,0,false,false,NVMe,INTEL SSDPE7KX02,PHLF7330004V2P0LGN,0170,{79b4d631-976f-4c94-a783-df950389fd38},[R/M 0 R/U 0 R/T 0 W/M 0 W/U 0 W/T 0],Используйте Get-PhysicalDisk.xml из SDDCDiagnosticInfo.
- Откройте XML-файл с помощью команды "$d = Import-Clixml GetPhysicalDisk.XML".
- Выполните
ipmo storage. - Выполните
$d. Обратите внимание, что использование используется автоматически, а не журнал.
Выходные данные должны иметь следующий вид:
Понятное имя Серийный номер Тип мультимедиа Канпул ОперативныйСтатус Состояние здоровья Использование Размер NVMe INTEL SSDPE7KX02 PHLF733000372P0LGN твердотельный накопитель (SSD) Неправда ОК Работоспособно Автоматическое выбор 1,82 ТБ NVMe INTEL SSDPE7KX02 PHLF7504008J2P0LGN твердотельный накопитель (SSD) Неправда ОК Работоспособно Автоматическое выбор 1,82 ТБ NVMe INTEL SSDPE7KX02 PHLF7504005F2P0LGN твердотельный накопитель (SSD) Неправда ОК Работоспособно Автоматическое выбор 1,82 ТБ NVMe INTEL SSDPE7KX02 PHLF7504002A2P0LGN твердотельный накопитель (SSD) Неправда ОК Работоспособно Автоматическое выбор 1,82 ТБ NVMe INTEL SSDPE7KX02 PHLF7504004T2P0LGN твердотельный накопитель (SSD) Неправда ОК Работоспособно Автоматическое выбор 1,82 ТБ NVMe INTEL SSDPE7KX02 PHLF7504002E2P0LGN твердотельный накопитель (SSD) Неправда ОК Работоспособно Автоматическое выбор 1,82 ТБ NVMe INTEL SSDPE7KX02 PHLF7330002Z2P0LGN твердотельный накопитель (SSD) Неправда ОК Работоспособно Автоматическое выбор 1,82 ТБ NVMe INTEL SSDPE7KX02 PHLF733000272P0LGN твердотельный накопитель (SSD) Неправда ОК Работоспособно Автоматическое выбор 1,82 ТБ NVMe INTEL SSDPE7KX02 PHLF7330001J2P0LGN твердотельный накопитель (SSD) Неправда ОК Работоспособно Автоматическое выбор 1,82 ТБ NVMe INTEL SSDPE7KX02 PHLF733000302P0LGN твердотельный накопитель (SSD) Неправда ОК Работоспособно Автоматическое выбор 1,82 ТБ NVMe INTEL SSDPE7KX02 PHLF7330004D2P0LGN твердотельный накопитель (SSD) Неправда ОК Работоспособно Автоматическое выбор 1,82 ТБ
Как уничтожить существующий кластер, чтобы снова использовать те же диски
В кластере Storage Spaces Direct отключите Storage Spaces Direct и используйте процесс очистки, описанный в разделе "Очистка дисков". Кластеризованный пул носителей по-прежнему остается в автономном состоянии, а служба работоспособности удаляется из кластера.
Следующим шагом является удаление пула фантомных носителей:
Get-ClusterResource -Name "Cluster Pool 1" | Remove-ClusterResource
Теперь, если запустить Get-PhysicalDisk на любом из узлов, вы увидите все диски, которые находились в пуле. Например, в лаборатории с 4-узлом кластера с 4 дисками SAS каждый из них содержит 100 ГБ, представленных каждому узлу. В этом случае, после отключения Storage Spaces Direct, который удаляет SBL (уровень шины хранения), но оставляет фильтр, если вы выполните Get-PhysicalDisk, он должен сообщить о 4 дисках, за исключением локального диска ОС. Вместо этого он сообщил 16. Это поведение одинаково для всех узлов в кластере. При выполнении команды Get-Disk вы увидите локальные подключенные диски, нумеруемые как 0, 1, 2 и т. д., как показано в этом примере выходных данных:
| Число | Понятное имя | Серийный номер | Состояние здоровья | ОперативныйСтатус | Общий размер | Стиль секционирования |
|---|---|---|---|---|---|---|
| 0 | Майкрософт Виртуальный | Работоспособно | Миграция по сети | 127 ГБ | GPT | |
| Майкрософт Виртуальный | Работоспособно | Не в сети | 100 ГБ | НЕОБРАБОТАННЫЕ | ||
| Майкрософт Виртуальный | Работоспособно | Не в сети | 100 ГБ | НЕОБРАБОТАННЫЕ | ||
| Майкрософт Виртуальный | Работоспособно | Не в сети | 100 ГБ | НЕОБРАБОТАННЫЕ | ||
| Майкрософт Виртуальный | Работоспособно | Не в сети | 100 ГБ | НЕОБРАБОТАННЫЕ | ||
| 1 | Майкрософт Виртуальный | Работоспособно | Не в сети | 100 ГБ | НЕОБРАБОТАННЫЕ | |
| Майкрософт Виртуальный | Работоспособно | Не в сети | 100 ГБ | НЕОБРАБОТАННЫЕ | ||
| 2 | Майкрософт Виртуальный | Работоспособно | Не в сети | 100 ГБ | НЕОБРАБОТАННЫЕ | |
| Майкрософт Виртуальный | Работоспособно | Не в сети | 100 ГБ | НЕОБРАБОТАННЫЕ | ||
| Майкрософт Виртуальный | Работоспособно | Не в сети | 100 ГБ | НЕОБРАБОТАННЫЕ | ||
| Майкрософт Виртуальный | Работоспособно | Не в сети | 100 ГБ | НЕОБРАБОТАННЫЕ | ||
| Майкрософт Виртуальный | Работоспособно | Не в сети | 100 ГБ | НЕОБРАБОТАННЫЕ | ||
| 4 | Майкрософт Виртуальный | Работоспособно | Не в сети | 100 ГБ | НЕОБРАБОТАННЫЕ | |
| 3 | Майкрософт Виртуальный | Работоспособно | Не в сети | 100 ГБ | НЕОБРАБОТАННЫЕ | |
| Майкрософт Виртуальный | Работоспособно | Не в сети | 100 ГБ | НЕОБРАБОТАННЫЕ | ||
| Майкрософт Виртуальный | Работоспособно | Не в сети | 100 ГБ | НЕОБРАБОТАННЫЕ | ||
| Майкрософт Виртуальный | Работоспособно | Не в сети | 100 ГБ | НЕОБРАБОТАННЫЕ |
Сообщение об ошибке "неподдерживаемый тип носителя" при создании кластера Локальные дисковые пространства с помощью Enable-ClusterS2D
Вы можете столкнуться с аналогичными ошибками при запуске командлета Enable-ClusterS2D.
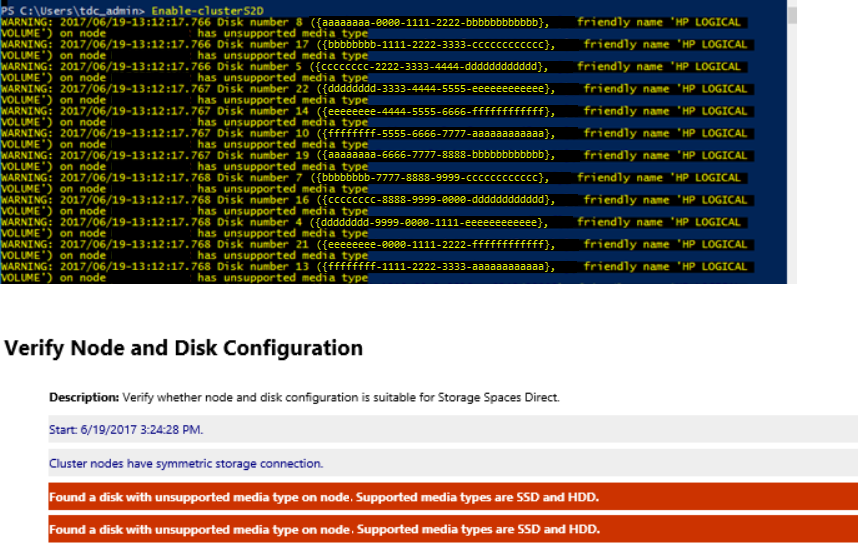
Чтобы устранить эту проблему, убедитесь, что адаптер HBA настроен в режиме HBA. В режиме RAID не следует настраивать HBA.
Enable-ClusterStorageSpacesDirect зависает на "Ожидание, пока диски SBL не будут отображаться" или на 27 %
В отчете проверки отображаются следующие сведения:
Диск <identifier> , подключенный к узлу <nodename> , вернул связь портов SCSI и не удалось найти соответствующее устройство корпуса. Оборудование несовместимо с Локальные дисковые пространства (S2D). Обратитесь к поставщику оборудования, чтобы проверить поддержку служб корпуса SCSI (SES).
Проблема связана с картой расширения HPE SAS, которая находится между дисками и картой HBA. Средство расширения SAS создает повторяющийся идентификатор между первым диском, подключенным к расширительу, и самим расширением. Эта проблема устранена в прошивке HPE Smart Array Controllers SAS Expander: 4.02.
Серия INTEL SSD DC P4600 имеет неуниковый NGUID
Возможно, возникла проблема, из-за которой устройство СЕРИИ DC P4600 intel SSD p4600 сообщает аналогичное 16-байтовое NGUID для нескольких пространств имен, таких как 0100000001000000E4D25C000014E214 или 0100000001000000E4D25C0000EEE214 в этом примере.
| Уникальный идентификатор | DeviceId (Идентификатор устройства) | Тип мультимедиа | Тип шины | Серийный номер | Размер | Канпул | Понятное имя | ОперативныйСтатус |
|---|---|---|---|---|---|---|---|---|
| 5000ККА251Д12Э30 | 0 | HDD (жёсткий диск) | САС | 7ПКР197Г | 10000831348736 | Неправда | HGST | HUH721010AL4200 |
| eui.010000000000000E4D25C000014E214 | 4 | твердотельный накопитель (SSD) | NVMe | 0100_0000_0100_0000_E4D2_5C00_0014_E214. | 1600321314816 | Истина | ИНТЕЛ | SSDPE2KE016T7 |
| eui.010000000000000E4D25C000014E214 | 5 | твердотельный накопитель (SSD) | NVMe | 0100_0000_0100_0000_E4D2_5C00_0014_E214. | 1600321314816 | Истина | ИНТЕЛ | SSDPE2KE016T7 |
| eui.0100000000100000E4D25C0000EEE214 | 6 | твердотельный накопитель (SSD) | NVMe | 0100_0000_0100_0000_E4D2_5C00_00EE_E214. | 1600321314816 | Истина | ИНТЕЛ | SSDPE2KE016T7 |
| eui.0100000000100000E4D25C0000EEE214 | 7 | твердотельный накопитель (SSD) | NVMe | 0100_0000_0100_0000_E4D2_5C00_00EE_E214. | 1600321314816 | Истина | ИНТЕЛ | SSDPE2KE016T7 |
Чтобы устранить эту проблему, обновите встроенное ПО на дисках Intel до последней версии. Версия встроенного ПО QDV101B1 с мая 2018 г. известна для устранения этой проблемы.
Выпуск Intel SSD Data Center Tool от мая 2018 г. включает обновление микропрограммы, QDV101B1, для серии Intel SSD DC P4600.
HealthStatus для физического диска и OperationsStatus
В кластере Локальных дисковых пространств Windows Server 2016 может появиться значение HealthStatus для одного или нескольких физических дисков как работоспособных, в то время как OperationsStatus удаляется из пула, ОК.
Удаление из состояния пула — это набор намерений, когда Remove-PhysicalDisk вызывается, но сохраняется в работоспособности для поддержания состояния и разрешает восстановление, если операция удаления завершается ошибкой. Вы можете вручную изменить OperationsStatus на "Работоспособный" с помощью одного из следующих методов:
- Удалите физический диск из пула и добавьте его обратно.
- Import-Module Clear-PhysicalDiskHealthData.ps1.
- Запустите скриптClear-PhysicalDiskHealthData.ps1 , чтобы очистить намерение. Этот скрипт доступен для скачивания в виде файла .txt. Прежде чем его можно запустить, необходимо сохранить в виде ps1-файла .
Ниже приведены некоторые примеры, показывающие, как запустить скрипт:
SerialNumberИспользуйте параметр, чтобы указать диск, который необходимо задать для работоспособности. Серийный номер можно получить изWMI MSFT_PhysicalDiskилиGet-PhysicalDisk. В этом примере используются нули для стоять для серийного номера.Clear-PhysicalDiskHealthData -Intent -Policy -SerialNumber 000000000000000 -Verbose -ForceUniqueIdИспользуйте параметр, чтобы указать диск, снова изWMI MSFT_PhysicalDiskилиGet-PhysicalDisk.Clear-PhysicalDiskHealthData -Intent -Policy -UniqueId 00000000000000000 -Verbose -Force
Копирование файлов медленно
Возможно, копирование файла занимает больше времени, чем ожидалось, если вы используете проводник для копирования большого виртуального жесткого диска на виртуальный диск.
Мы не рекомендуем использовать проводник, Robocopy или Xcopy для копирования большого виртуального жесткого диска на виртуальный диск. Это приводит к замедлению, чем ожидалось, производительности. Процесс копирования не проходит через стек Локальные дисковые пространства, который находится ниже в стеке хранилища и вместо этого действует как локальный процесс копирования.
Если вы хотите проверить производительность Локальные дисковые пространства, рекомендуется использовать VMFleet и Diskspd для загрузки и стресс-тестирования серверов, чтобы получить базовую строку и задать ожидания Локальные дисковые пространства производительности.
Ожидаемые события, которые будут отображаться на остальных узлах во время перезагрузки узла
Это безопасно, чтобы игнорировать следующие события:
Event ID 205: Windows lost communication with physical disk {XXXXXXXXXXXXXXXXXXXX}. This can occur if a cable failed or was disconnected, or if the disk itself failed.
Event ID 203: Windows lost communication with physical disk {XXXXXXXXXXXXXXXXXXXX}. This can occur if a cable failed or was disconnected, or if the disk itself failed.
Если вы используете виртуальные машины Azure, можно игнорировать это событие: идентификатор события 32. Драйвер обнаружил, что устройство \Device\Harddisk5\DR5 имеет свой кэш записи. Может возникнуть повреждение данных.
Низкая производительность или "Потерянная связь", "Ошибка ввода-вывода", "Отсоединенная" или "Без избыточности" для развертываний, использующих устройства Intel P3x00 NVMe
Мы определили критически важные проблемы, которые влияют на некоторые Локальные дисковые пространства пользователей, использующих оборудование на основе семейства устройств NVM Express (NVM) Intel P3x00 до выпуска 8.
Примечание.
Отдельные изготовители оборудования могут иметь устройства, основанные на семействе устройств NVMe Intel P3x00 с уникальными строками версии встроенного ПО. Обратитесь к изготовителю оборудования для получения дополнительных сведений о последней версии встроенного ПО.
Если вы используете оборудование в развертывании на основе семейства устройств NVMe Intel P3x00, рекомендуется немедленно применить последнее доступное встроенное ПО (по крайней мере выпуск обслуживания 8).