Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
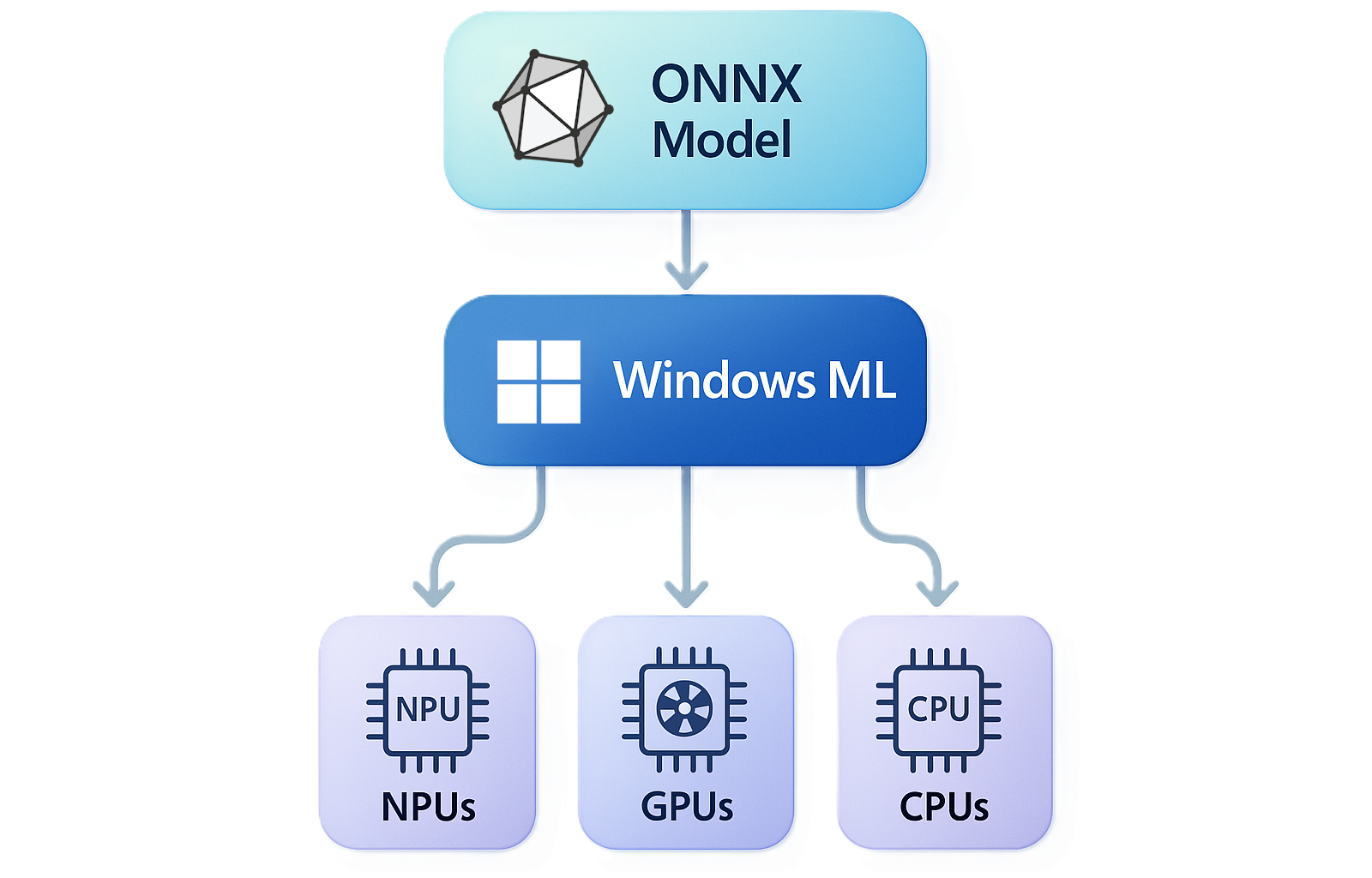
Машинное обучение Windows помогает разработчикам приложений Windows на C#, C++и Python запускать модели ONNX локально во всех различных аппаратных модулях Windows, включая ЦП, GPU и NPUs. Windows ML абстрагирует поставщиков оборудования и выполнения, чтобы сосредоточиться на написании кода. Кроме того, Windows ML автоматически обновляется для поддержки последних NPUs, GPU и ЦП по мере их выпуска.
Это важно
Api машинного обучения Windows в настоящее время экспериментальны и не поддерживаются для использования в рабочих средах. Приложения, пытающиеся использовать эти API, не должны публиковаться в Microsoft Store.
Поддерживаемые версии Windows
Windows ML работает на всех компьютерах с Windows 11 под управлением версии 24H2 (сборка 26100) или более поздней.
Поддерживаемое оборудование
Windows ML работает на всех компьютерах x64 и ARM64, даже на компьютерах, которые не имеют NPUs или GPU, что означает, что вы можете достичь сотен миллионов устройств Windows на рынке. Это может означать поддержание рабочих нагрузок лёгкими, но существуют iGPU, которые достаточно мощны для обработки тяжёлых рабочих нагрузок.
Преобразование моделей в ONNX
Модели можно преобразовать из других форматов в ONNX, чтобы использовать их с Windows ML. Чтобы узнать больше, ознакомьтесь с документацией Visual Studio Code AI Toolkit по преобразованию моделей в формат ONNX.
Какие проблемы решает Windows ML?
Разнообразие оборудования
Как разработчик ИИ, создающий приложения на Windows, первая задача, которую Windows ML решает для вас, заключается в разнообразии аппаратного обеспечения. Да, это преимущество экосистемы Windows, что пользователи могут выбрать любое оборудование, которое им лучше всего подходит. Но без Windows ML это затруднило бы вас, как разработчика, создающего интерфейсы искусственного интеллекта, для поддержки всего этого аппаратного разнообразия. Многие из современных ведущих приложений, работающих под управлением Windows, предпочитают выпускаться на продуктах только одного поставщика оборудования одновременно. Просто intel; просто Qualcomm; просто AMD; просто дискретные GPU на данный момент. И это значительно ограничивает количество устройств, на которых эти приложения могут работать.
Развертывание зависимостей
Далее стоит проблема развертывания всех необходимых зависимостей. Для отправки возможностей искусственного интеллекта в приложении приложение должно отправлять и развертывать три элемента.
- Модели ИИ, которые требуется запустить.
- Среда выполнения, позволяющая выполнять вывод на этих моделях.
- Средства и драйверы, разработанные поставщиком, которые помогают выбранной среде выполнения взаимодействовать с кремнием.
Ваше приложение нуждается в этих вещах, и оно также должно поддерживаться и обновляться. Когда выпускается новая версия среды выполнения или в ней исправлена критическая ошибка, вам потребуется соответствующим образом обновить свое приложение. Без Windows ML в качестве разработчика приложений вам потребуется взять на себя ответственность за все эти зависимости. Они стали частью вашего приложения, и бремя поддержания всего будет падать к вам.
Использование локального оборудования
Затем встает вопрос об использовании локального оборудования, на котором работает ваше приложение. Должны ли рабочие нагрузки ИИ выполняться на ЦП или GPU или NPU? Если вы используете разные модели ИИ, то какие из них лучше всего работают на каких процессорах? Эта проблема быстро становится очень сложной. И без Windows ML вам придется написать и поддерживать сложную логику, которая сначала определяет, что доступно на текущем устройстве, а затем пытается извлечь из него максимальную производительность.
Windows ML, доступный через пакет SDK для приложений Windows, решает все эти проблемы.
- Среда выполнения не должна находиться в приложении.
- Поставщик выполнения (EP) выбирается для пользователей автоматически на основе оборудования, доступного для них. Переопределения для разработчиков доступны для выбора.
- Windows ML управляет зависимостями среды выполнения, перекладывая эту нагрузку из вашего приложения на саму Windows ML и поставщиков выполнения (EPs).
- Windows ML помогает сбалансировать нагрузку на клиентское устройство и выбрать подходящее оборудование для выполнения рабочей нагрузки ИИ.
Подробный обзор
Windows ML Microsoft.Windows.AI.MachineLearning служит центральным элементом вычислений искусственного интеллекта в Windows AI Foundry. Таким образом, используете ли вы API Windows для доступа к моделям, встроенным в Windows, или вы используете растущий список готовых моделей Foundry с Foundry Local (см. статью "Начало работы с Foundry Local"), вы будете работать с рабочими нагрузками ИИ в Windows ML, вероятно, даже не зная его.
И если вы создаете собственные модели или требуется высокий уровень точного контроля над тем, как выполняется вывод модели, вы можете использовать Windows ML напрямую, вызвав свои API. См. API Машинного обучения Windows (Microsoft.Windows.AI.MachineLearning).
На основе среды выполнения ONNX
Машинное обучение Windows основано на специализированном ответвлении версии среды выполнения ONNX. Это позволяет некоторым улучшениям, специфическим для Windows, повысить производительность. Мы также оптимизировали его с учетом стандартных моделей ONNX QDQ, что позволяет сосредоточиться на достижении оптимальной производительности инференса на локальном устройстве без необходимости излишне увеличивать модели.
Среда выполнения ONNX взаимодействует с аппаратными средствами через исполнительных провайдеров (EPs), которые служат уровнем перевода между средой выполнения и драйверами аппаратного обеспечения. Мы использовали провайдеров выполнения с Windows Click to Do и NPU, совместили их с новыми провайдерами выполнения для GPU и объединили все это в одну платформу Windows ML, которая теперь полностью реализует обещание обеспечить возможность выполнения рабочих нагрузок ИИ на любом оборудовании, в том числе на ЦП, GPU и NPU. Каждый тип процессора является полноправным участником, который полностью поддерживается последними драйверами и провайдерами выполнения ONNX Runtime от четырех основных поставщиков ИИ процессоров (AMD, Intel, NVIDIA и Qualcomm). Типы этих процессоров равноправны — вам нужно лишь использовать Windows ML с моделями QDQ ONNX, чтобы уверенно масштабировать рабочие нагрузки ИИ на всех типах оборудования.
Упаковка и развертывание
Windows ML распространяется в составе пакета SDK для приложений Windows. После добавления ссылки на пакет SDK для приложений Windows в проекте и установки приложения на компьютере клиента:
- Загрузчик пакета SDK для приложений Windows гарантирует правильное инициализацию среды выполнения Машинного обучения Windows в приложении.
- Затем Windows ML обнаруживает оборудование для конкретного компьютера, на котором установлено приложение, и загружает соответствующие поставщики выполнения, необходимые для этого компьютера.
Поэтому вам не нужно включать собственных исполнителей в пакет приложения. На самом деле, вам не нужно беспокоиться о поставщиках выполнения вообще или о доставке пользовательских сборок среды выполнения ИИ, которые специально предназначены для AMD или Intel или NVIDIA или Qualcomm или любого другого конкретного семейства оборудования. Вы просто вызываете API Машинного обучения Windows, а затем передаете правильно отформатированную модель, и мы берем на себя все остальное — автоматически подготавливая все необходимое для целевой аппаратуры и поддерживая все в актуальном состоянии.
Результат заключается в том, что это значительно упрощает управление зависимостями и снимает беспокойство о них. И это стало возможным благодаря уровню взаимодействия, которое мы получили от таких аппаратных партнеров, как AMD, Intel, NVIDIA и Qualcomm. Эти партнеры будут продолжать предоставлять поставщиков услуг исполнения для Windows ML и отправлять их в Корпорацию Майкрософт, когда у них есть обновления или новые чипы, которые они внедряют на рынок.
Корпорация Майкрософт сертифицирует любые новые поставщики выполнения, чтобы гарантировать отсутствие регрессии в точности выводов. А затем мы возьмем на себя ответственность за развертывание этих EP для целевых компьютеров от имени поставщиков оборудования и будем способствовать тому, чтобы экосистема Windows ML в целом оставалась современной и обновленной.
Это другой подход, отличный от подхода, принятого такими технологиями, как DirectML и DirectX, где Майкрософт абстрагирует API над изменениями в экосистеме оборудования. Вместо этого, с Windows ML, мы меняем обстановку, чтобы предоставить производителям оборудования возможность быстро и напрямую внедрять инновационные технологии, с немедленной поддержкой провайдера выполнения с первого дня по мере их появления на рынке.
Производительность
Производительность больше, чем чистая скорость часов на стенах. Да, многие задачи, связанные с искусственным интеллектом, требуют больших вычислительных ресурсов. Но по мере того как ИИ становится вездесущим в интерфейсе приложений, существует потребность в среде выполнения, которая может оптимизировать вывод таким образом, чтобы сохранить жизнь батареи при сохранении высокой степени точности. Таким образом, что ИИ выдает хорошие, точные результаты.
Рабочие нагрузки искусственного интеллекта обычно попадают в один из двух сегментов:
- Повсеместный ИИ. ИИ происходит незаметно в фоновом режиме, пока пользователи взаимодействуют с вашим приложением.
- Публичный ИИ. Пользователи знают, что они запустили задачу ИИ, которая обычно представляет собой сценарий создания искусственного интеллекта (genAI).
Нагрузки на искусственный интеллект для окружающей среды можно разгрузить на выделенный процессор NPU, обладающий вычислительной мощностью более 40 TOPS и потребляющий обычно в пределах нескольких ватт. Таким образом, Windows ML идеально подходит для внешних рабочих нагрузок ИИ. В большинстве случаев пользователи ваших приложений будут ощущать магию ИИ без необходимости ждать и не беспокоясь о заряде батареи своего компьютера.
Многие вычислительно тяжелые задачи ИИ могут лучше всего выполняться выделенным графическим процессором. Версия Windows ML 2018 использует EP DirectML для обработки рабочих нагрузок GPU; и это увеличивает количество слоев между моделью и силиконом. Windows ML в Microsoft.Windows.AI.MachineLearning не имеет уровня DirectML. Вместо этого он работает напрямую с специализированными исполнителями для GPU, обеспечивая производительность, сравнимую с низкоуровневыми SDK прошлого, такими как TensorRT для RTX, AI Engine Direct и расширение Intel для PyTorch. Мы разработали Windows ML для обеспечения передовой производительности GPU, сохраняя преимущества принципа «один раз разработай — запускай где угодно», которые предлагало прошлое решение на основе DirectML.
В обоих из этих двух случаев все аспекты производительности имеют значение. Чистая скорость стенных часов, время работы батареи и точность. Таким образом, пользователь получает фактически хорошие результаты.
Все это открывает вам ряд возможностей и сценариев с помощью ИИ. Вы можете запускать рабочие нагрузки и агентов, использующих окружной искусственный интеллект, на выделенных NPU; или запускать рабочие нагрузки на интегрированных GPU, чтобы при необходимости освободить дискретный GPU. И если вы хотите использовать необработанную мощность, то вы можете нацелиться на современные современные дискретные GPU (DGP) для выполнения более тяжелых рабочих нагрузок на максимально быстрых возможных скоростях.
Что такое поставщик выполнения?
Поставщик выполнения (EP) — это компонент, реализующий оптимизацию оборудования для операций машинного обучения (ML). EP может реализовать одну или несколько аппаратных абстракций. Рассмотрим пример.
- Поставщики ЦП оптимизируют для процессоров общего назначения.
- Поставщики выполнения GPU оптимизируют графические процессоры.
- Поставщики услуг NPU оптимизируют работу нейронных процессоров.
- Другие поставщики, специфичные для отдельных вендоров.
Среда выполнения Машинного обучения Windows обрабатывает сложность управления этими поставщиками выполнения, предоставляя API для выполнения следующих действий:
- Скачайте соответствующие пакеты для текущего оборудования.
- Динамически регистрируйте ЭП во время выполнения.
- Настройка поведения EP.
Использование поставщиков выполнения с Windows ML
Среда выполнения Машинного обучения Windows предоставляет гибкий способ доступа к поставщикам выполнения машинного обучения (EPS), которые могут оптимизировать вывод модели машинного обучения на различных аппаратных конфигурациях. Эти EPs предоставляются как отдельные пакеты, которые можно обновлять независимо от операционной системы.
Предоставление отзывов о Windows ML
Мы хотели бы услышать ваши отзывы об использовании Windows ML! Если у вас возникли проблемы или есть предложения, выполните поиск в GitHub репозитории Windows App SDK, чтобы узнать, было ли об этом уже сообщено, и если это не так, создайте новую проблему.