Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
На предыдущем этапе этого руководства мы приобрели набор данных, который мы будем использовать для обучения модели анализа данных с помощью PyTorch. Сейчас время использовать эти данные.
Чтобы обучить модель анализа данных с помощью PyTorch, необходимо выполнить следующие действия:
- Загрузите данные. Если вы выполнили предыдущий шаг этого руководства, вы уже справились с этим.
- Определите нейронную сеть.
- Определите функцию потери.
- Обучить модель на обучающих данных.
- Проведите тестирование сети на тестовых данных.
Определение нейронной сети
В этом руководстве вы создадите базовую модель нейронной сети с тремя линейными слоями. Структура модели выглядит следующим образом:
Linear -> ReLU -> Linear -> ReLU -> Linear
Линейный слой применяет линейное преобразование к входящим данным. Необходимо указать количество входных функций и количество выходных функций, которые должны соответствовать количеству классов.
Уровень ReLU — это функция активации, определяющая все входящие функции, которые должны иметь значение 0 или больше. Таким образом, при применении слоя ReLU любое число меньше 0 изменяется на ноль, а другие сохраняются одинаково. Мы применим уровень активации к двум скрытым слоям и не будем применять активацию на последнем линейном слое.
Параметры модели
Параметры модели зависят от нашей цели и обучающих данных. Размер входных данных зависит от количества признаков, которые мы подаём модели — четыре в нашем примере. Размер выходных данных составляет три, так как существует три возможных типа ирисов.
Имея три линейных слоя, (4,24) -> (24,24) -> (24,3) сеть будет иметь 744 весов (96+576+72).
Скорость обучения (lr) задает контроль того, сколько вы корректируете вес нашей сети в отношении градиента потери. Чем ниже, тем медленнее будет обучение. В этом руководстве вы установите значение lr на 0.01.
Как работает сеть?
Здесь мы строим прямую нейронную сеть. Во время обучения сеть будет обрабатывать входные данные через все слои, вычислять потерю, чтобы понять, насколько далеко прогнозируемая метка изображения падает от правильной, и распространяет градиенты обратно в сеть, чтобы обновить весы слоев. Проводя итерации по огромному набору входных данных, сеть "научится" настраивать свои веса для достижения наилучших результатов.
Функция прямого распространения вычисляет значение функции потерь, а функция обратного распространения вычисляет градиенты обучаемых параметров. При создании нейронной сети с помощью PyTorch необходимо определить только функцию пересылки. Обратная функция будет автоматически определена.
- Скопируйте следующий код в
DataClassifier.pyфайл в Visual Studio, чтобы определить параметры модели и нейронную сеть.
# Define model parameters
input_size = list(input.shape)[1] # = 4. The input depends on how many features we initially feed the model. In our case, there are 4 features for every predict value
learning_rate = 0.01
output_size = len(labels) # The output is prediction results for three types of Irises.
# Define neural network
class Network(nn.Module):
def __init__(self, input_size, output_size):
super(Network, self).__init__()
self.layer1 = nn.Linear(input_size, 24)
self.layer2 = nn.Linear(24, 24)
self.layer3 = nn.Linear(24, output_size)
def forward(self, x):
x1 = F.relu(self.layer1(x))
x2 = F.relu(self.layer2(x1))
x3 = self.layer3(x2)
return x3
# Instantiate the model
model = Network(input_size, output_size)
Кроме того, необходимо определить устройство выполнения на основе доступного на вашем компьютере. PyTorch не имеет выделенной библиотеки для GPU, но вы можете вручную определить устройство выполнения. Устройство будет графической картой Nvidia, если она установлена на вашем компьютере, или центральным процессором, если графической карты нет.
- Скопируйте следующий код, чтобы определить устройство выполнения:
# Define your execution device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("The model will be running on", device, "device\n")
model.to(device) # Convert model parameters and buffers to CPU or Cuda
- На последнем шаге определите функцию для сохранения модели:
# Function to save the model
def saveModel():
path = "./NetModel.pth"
torch.save(model.state_dict(), path)
Замечание
Хотите узнать больше о нейронной сети с Помощью PyTorch? Ознакомьтесь с документацией по PyTorch.
Определение функции потери
Функция потери вычисляет значение, которое оценивает, насколько далеко выходные данные от целевого объекта. Основная цель — уменьшить значение функции потери, изменив значения вектора веса путем обратного распространения в нейронных сетях.
Значение потери отличается от точности модели. Функция потерь показывает, насколько хорошо работает наша модель после каждой итерации оптимизации на обучающем наборе. Точность модели вычисляется на тестовых данных и показывает процент правильных прогнозов.
В PyTorch пакет нейронной сети содержит различные функции потери, которые образуют стандартные блоки глубоких нейронных сетей. Если вы хотите узнать больше об этих особенностях, ознакомьтесь с приведенным выше примечанием. Здесь мы будем использовать существующие функции, оптимизированные для такой классификации, а также функцию потерь перекрестной энтропии для классификации и оптимизатор Адама. В оптимизаторе скорость обучения (lr) задает контроль того, сколько вы корректируете весы нашей сети в отношении градиента потери. Вы установите его как 0,001 здесь - чем ниже значение, тем медленнее будет обучение.
- Скопируйте следующий код в
DataClassifier.pyфайл в Visual Studio, чтобы определить функцию потери и оптимизатор.
# Define the loss function with Classification Cross-Entropy loss and an optimizer with Adam optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=0.001, weight_decay=0.0001)
Обучить модель на обучающих данных.
Чтобы обучить модель, необходимо выполнить цикл по итератору данных, передать входные данные в сеть и оптимизировать модель. Чтобы проверить результаты, вы просто сравниваете прогнозируемые метки с фактическими метками в наборе данных проверки после каждой эпохи обучения.
Программа будет отображать потери обучения, потерю проверки и точность модели для каждой эпохи или для каждой полной итерации по набору обучения. Она сохранит модель с максимальной точностью, а после 10 эпох программа будет отображать окончательную точность.
- Добавьте следующий код в
DataClassifier.pyфайл
# Training Function
def train(num_epochs):
best_accuracy = 0.0
print("Begin training...")
for epoch in range(1, num_epochs+1):
running_train_loss = 0.0
running_accuracy = 0.0
running_vall_loss = 0.0
total = 0
# Training Loop
for data in train_loader:
#for data in enumerate(train_loader, 0):
inputs, outputs = data # get the input and real species as outputs; data is a list of [inputs, outputs]
optimizer.zero_grad() # zero the parameter gradients
predicted_outputs = model(inputs) # predict output from the model
train_loss = loss_fn(predicted_outputs, outputs) # calculate loss for the predicted output
train_loss.backward() # backpropagate the loss
optimizer.step() # adjust parameters based on the calculated gradients
running_train_loss +=train_loss.item() # track the loss value
# Calculate training loss value
train_loss_value = running_train_loss/len(train_loader)
# Validation Loop
with torch.no_grad():
model.eval()
for data in validate_loader:
inputs, outputs = data
predicted_outputs = model(inputs)
val_loss = loss_fn(predicted_outputs, outputs)
# The label with the highest value will be our prediction
_, predicted = torch.max(predicted_outputs, 1)
running_vall_loss += val_loss.item()
total += outputs.size(0)
running_accuracy += (predicted == outputs).sum().item()
# Calculate validation loss value
val_loss_value = running_vall_loss/len(validate_loader)
# Calculate accuracy as the number of correct predictions in the validation batch divided by the total number of predictions done.
accuracy = (100 * running_accuracy / total)
# Save the model if the accuracy is the best
if accuracy > best_accuracy:
saveModel()
best_accuracy = accuracy
# Print the statistics of the epoch
print('Completed training batch', epoch, 'Training Loss is: %.4f' %train_loss_value, 'Validation Loss is: %.4f' %val_loss_value, 'Accuracy is %d %%' % (accuracy))
Проверьте модель на тестовых данных.
Теперь, когда мы обучили модель, мы можем протестировать модель с помощью тестового набора данных.
Мы добавим две тестовые функции. Первый тест проверяет модель, сохраненную в предыдущем разделе. Он будет тестировать модель с помощью тестового набора данных из 45 элементов и выведет точность модели. Во-вторых, является необязательной функцией для проверки уверенности модели в прогнозировании каждого из трех видов ириса, представленной вероятностью успешной классификации каждого вида.
- Добавьте в файл
DataClassifier.pyуказанный ниже код.
# Function to test the model
def test():
# Load the model that we saved at the end of the training loop
model = Network(input_size, output_size)
path = "NetModel.pth"
model.load_state_dict(torch.load(path))
running_accuracy = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, outputs = data
outputs = outputs.to(torch.float32)
predicted_outputs = model(inputs)
_, predicted = torch.max(predicted_outputs, 1)
total += outputs.size(0)
running_accuracy += (predicted == outputs).sum().item()
print('Accuracy of the model based on the test set of', test_split ,'inputs is: %d %%' % (100 * running_accuracy / total))
# Optional: Function to test which species were easier to predict
def test_species():
# Load the model that we saved at the end of the training loop
model = Network(input_size, output_size)
path = "NetModel.pth"
model.load_state_dict(torch.load(path))
labels_length = len(labels) # how many labels of Irises we have. = 3 in our database.
labels_correct = list(0. for i in range(labels_length)) # list to calculate correct labels [how many correct setosa, how many correct versicolor, how many correct virginica]
labels_total = list(0. for i in range(labels_length)) # list to keep the total # of labels per type [total setosa, total versicolor, total virginica]
with torch.no_grad():
for data in test_loader:
inputs, outputs = data
predicted_outputs = model(inputs)
_, predicted = torch.max(predicted_outputs, 1)
label_correct_running = (predicted == outputs).squeeze()
label = outputs[0]
if label_correct_running.item():
labels_correct[label] += 1
labels_total[label] += 1
label_list = list(labels.keys())
for i in range(output_size):
print('Accuracy to predict %5s : %2d %%' % (label_list[i], 100 * labels_correct[i] / labels_total[i]))
Наконец, добавим основной код. Будет инициировано обучение моделей, сохранение модели и отображение результатов на экране. Мы будем выполнять только две итерации [num_epochs = 25] по набору обучения, поэтому процесс обучения не займет слишком много времени.
- Добавьте в файл
DataClassifier.pyуказанный ниже код.
if __name__ == "__main__":
num_epochs = 10
train(num_epochs)
print('Finished Training\n')
test()
test_species()
Давайте запустите тест! Убедитесь, что в раскрывающемся меню на верхней панели инструментов задано значение Debug. Измените Solution Platform на x64, чтобы запустить проект на локальном компьютере, если ваше устройство 64-битное, или x86, если оно 32-битное.
- Чтобы запустить проект, нажмите
Start Debuggingкнопку на панели инструментов или нажмите клавишуF5.
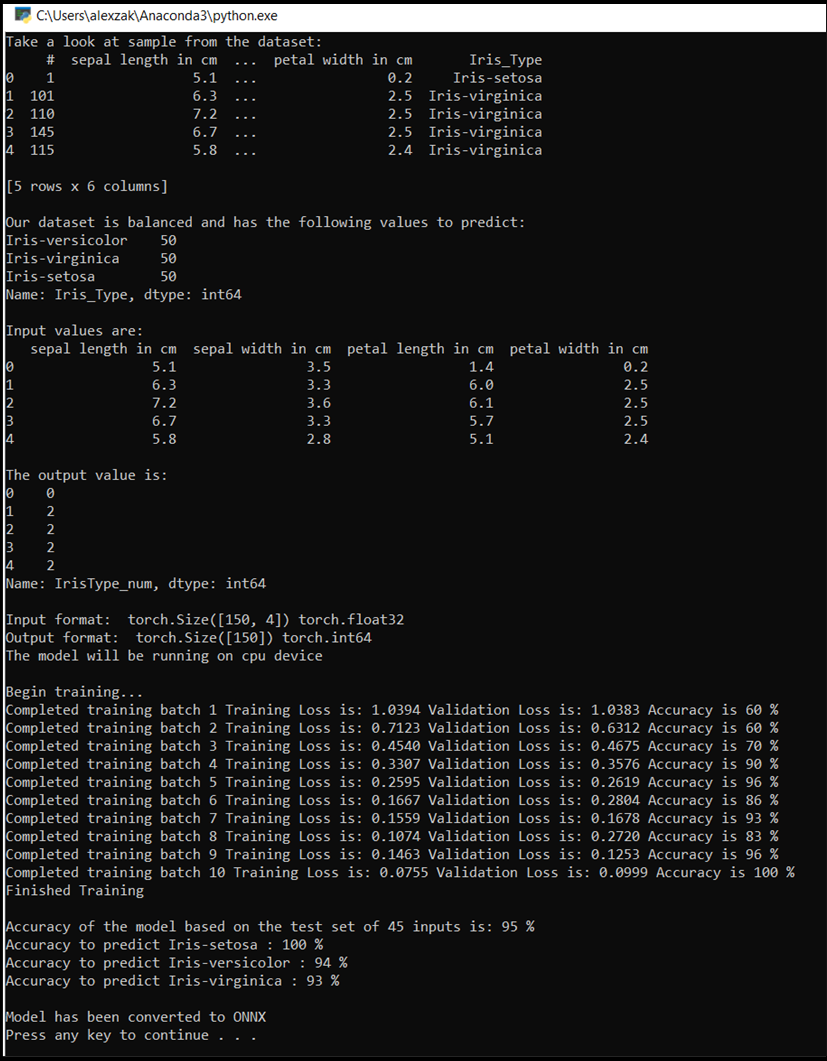
Откроется окно консоли, и вы увидите процесс обучения. Согласно вашим настройкам, значение потери будет выводиться каждую эпоху. Ожидается, что значение потери уменьшается с каждым циклом.
После завершения обучения вы должны увидеть выходные данные, аналогичные приведенным ниже. Ваши цифры не будут полностью одинаковыми. Обучение зависит от многих факторов и не всегда приносит идентичные результаты, но они должны выглядеть похоже.
Дальнейшие шаги
Теперь, когда у нас есть модель классификации, следующим шагом является преобразование модели в формат ONNX.