Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Интеграция распознавания речи и преобразования текста в речь (также известного как TTS или синтез речи) непосредственно в взаимодействие с пользователем вашего приложения.
Распознавание речи Распознавание речи преобразует слова, произнесенные пользователем, в текст для ввода формы, для диктовки текста, для указания действия или команды и выполнения задач. Она поддерживает предопределенные грамматики для свободного текста диктовки и веб-поиска, а также пользовательские грамматики, созданные с помощью спецификации грамматики распознавания речи (SRGS) версии 1.0.
Синтез речи/Text to Speech (TTS) TTS использует движок синтеза речи (голос) для преобразования текстовой строки в речь. Входная строка может быть простой, незавершенный текст или более сложный язык разметки синтеза речи (SSML). SSML предоставляет стандартный способ управления характеристиками речи на выходе, такими как произношение, громкость, темп или скорость, а также акцент.
Проектирование речевого взаимодействия
При разработке и реализации речи вдумчиво это может быть эффективный, доступный и естественный способ взаимодействия с приложениями Windows, дополняя или даже заменяя традиционные возможности взаимодействия на основе мыши, клавиатуры, контроллера или сенсорного ввода.
Эти рекомендации и советы описывают, как лучше интегрировать распознавание речи и технологии синтеза речи (TTS) во взаимодействие с приложением.
Если вы рассматриваете возможность поддержки взаимодействия с речью в приложении, задайте следующие вопросы:
- Какие действия пользователи могут выполнять через речь? Могут ли они перемещаться между страницами, вызывать команды или вводить данные в виде текстовых полей, кратких заметок или длинных сообщений?
- Подходит ли входная речь для выполнения задачи?
- Как пользователь знает, когда доступны входные данные речи?
- Всегда ли приложение прослушивает или требуется ли пользователю выполнить действие, чтобы приложение ввело режим прослушивания?
- Какие фразы инициируют действие или поведение? Нужно ли перечислять фразы и действия на экране?
- Требуются ли экраны запроса, подтверждения и дизамбигуации или синтез речи (TTS)?
- Что такое диалоговое окно взаимодействия между приложением и пользователем?
- Требуется ли пользовательский или ограниченный словарь (например, медицина, наука или языковой стандарт) для контекста приложения?
- Требуется ли сетевое подключение?
Ввод текста
Ввод текста может варьироваться от коротких входных данных формы, таких как одно слово или фраза, до длинного ввода формы, например нескольких фраз, абзацев или непрерывного диктовки. Короткие входные данные обычно меньше 10 секунд, а длинные сеансы ввода могут длиться до двух минут. Длинный ввод может автоматически перезапуститься без участия пользователя, создавая впечатление непрерывной диктовки.
Предоставьте визуальный сигнал, чтобы указать, что распознавание речи поддерживается и доступно пользователю, и нужно ли включить его пользователю. Например, используйте кнопку панели команд с глифом микрофона (см. панели команд) для отображения доступности и состояния.
Предоставляйте постоянную обратную связь о процессе распознавания, чтобы минимизировать задержки в ответах во время выполнения распознавания.
Пусть пользователи редактируют текст распознавания с помощью ввода клавиатуры, запросов дезамбигуации, предложений или дополнительного распознавания речи.
Остановите распознавание, если входные данные обнаружены на устройстве, отличном от распознавания речи, например сенсорного ввода или клавиатуры. Этот вход, вероятно, указывает, что пользователь перешел на другую задачу, например исправление текста распознавания или взаимодействие с другими полями формы.
Укажите продолжительность времени, в течение которого входные данные речи не указывают на то, что распознавание закончено. Не перезагрузите распознавание автоматически после этого периода времени, так как обычно это означает, что пользователь перестал взаимодействовать с приложением.
В некоторых случаях сетевое подключение может потребоваться для поддержки распознавания речи. Если он недоступен, отключите весь пользовательский интерфейс непрерывного распознавания и завершите сеанс распознавания.
Командование
Входные данные речи могут инициировать действия, вызывать команды и выполнять задачи.
Если пространство разрешено, рассмотрите возможность отображения поддерживаемых ответов для текущего контекста приложения с примерами допустимых входных данных. Этот подход снижает количество потенциальных ответов, которые необходимо обработать приложению, а также устраняет путаницу для пользователя.
Попробуйте задать свои вопросы, чтобы вывести как можно более конкретный ответ. Например, фраза "Что вы хотите сделать сегодня?" является очень открытой и требует обширного определения грамматики из-за разнообразия возможных ответов. Кроме того, "Вы хотите играть в игру или слушать музыку?" ограничивает ответ на один из двух допустимых ответов с соответствующим небольшим определением грамматики. Создавать небольшую грамматику гораздо проще и приводит к более точным результатам распознавания.
Запрос подтверждения от пользователя при низкой достоверности распознавания речи. Если намерение пользователя неясно, лучше получить уточнение, чем инициировать непреднамеренное действие.
Предоставьте визуальный сигнал, чтобы указать, что распознавание речи поддерживается и доступно пользователю, и нужно ли включить его пользователю. Например, используйте кнопку панели команд с глифом микрофона (см. рекомендации по панели команд) для отображения доступности и состояния.
Если переключатель распознавания речи обычно не отображается, рассмотрите возможность отображения индикатора состояния в области содержимого приложения.
Если пользователь инициирует распознавание, рассмотрите возможность использования встроенного интерфейса распознавания для согласованности. Встроенный интерфейс включает настраиваемые экраны с запросами, примерами, диспамбигациями, подтверждениями и ошибками.
Виды экранов зависят от указанных ограничений.
Предопределенная грамматика (диктовка или веб-поиск)
- Экран прослушивания .
- Экран мышления .
- Экран "Услышано" или экран ошибки.
Список слов или фраз или файла грамматики SRGS
- Экран прослушивания .
- Экран Вы сказали, если сказанное пользователем может быть интерпретировано как более одного потенциального результата.
- Экран "Услышано" или экран ошибки.
На экране прослушивания можно:
- Настройте текст заголовка.
- Введите пример текста того, что может сказать пользователь.
- Укажите, отображается ли экран "Слышали, вы сказали".
- Считывайте распознанную строку обратно пользователю на экране Как вы сказали.
На следующих изображениях показан пример встроенного потока распознавания речи для распознавателя речи, использующего ограничение SRGS. В этом примере распознавание речи успешно выполнено.
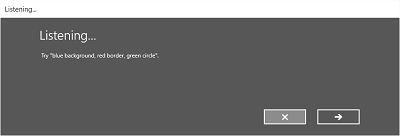
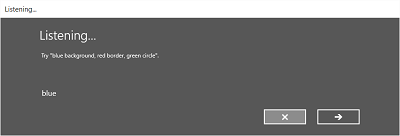
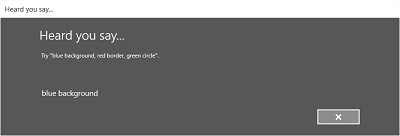
Всегда на прослушивании
Приложение может прослушивать и распознавать входные данные речи сразу после запуска приложения без вмешательства пользователя.
Настройте ограничения грамматики на основе контекста приложения. Этот подход делает работу по распознаванию речи более целенаправленной и актуальной для текущей задачи, а также сводит к минимуму ошибки.
"Что я могу сказать?"
Если включить входные данные речи, пользователи могут узнать, что приложение может понять и какие действия он может выполнить.
Если пользователи поддерживают распознавание речи, попробуйте использовать панель команд или команду меню, чтобы отобразить все слова и фразы, поддерживаемые в текущем контексте.
Если распознавание речи всегда включено, попробуйте добавить фразу "Что я могу сказать?" на каждую страницу. Когда пользователь говорит эту фразу, отображаются все слова и фразы, поддерживаемые в текущем контексте. Эта фраза обеспечивает согласованный способ обнаружения возможностей речи пользователей в системе.
Сбои распознавания
Распознавание речи может завершиться ошибкой. Сбои происходят, когда качество звука плохое, когда распознаватель обнаруживает только часть фразы или когда распознаватель не обнаруживает входных данных вообще.
Обработайте ошибку корректно, помогите пользователю понять, почему распознавание не удалось, и восстановитесь.
Приложение должно сообщить пользователю, что распознаватель не понял их и что им нужно повторить попытку.
Рассмотрим примеры одной или нескольких поддерживаемых фраз. Пользователь, скорее всего, повторяет предложенную фразу, что повышает успех распознавания.
Отобразите список возможных совпадений, из которых пользователь может сделать выбор. Этот подход может быть гораздо эффективнее, чем снова пройти процесс распознавания.
Всегда поддерживает альтернативные типы входных данных, которые особенно полезны для обработки повторяющихся сбоев распознавания. Например, можно предположить, что пользователь пытается использовать клавиатуру, или использовать сенсорный ввод или мышь для выбора из списка потенциальных совпадений.
Используйте встроенный интерфейс распознавания речи, так как он включает экраны, которые сообщают пользователю, что распознавание не было успешным и позволяет пользователю выполнить другую попытку распознавания.
Прослушивайте и пытайтесь исправить проблемы во входе звука. Распознаватель речи может обнаруживать проблемы с качеством звука, которые могут негативно повлиять на точность распознавания речи. Вы можете использовать информацию, предоставленную распознавательом речи, чтобы сообщить пользователю о проблеме и разрешить им принять корректирующие действия, если это возможно. Например, если параметр громкости на микрофоне слишком низкий, вы можете предложить пользователю говорить громче или включить громкость.
Constraints
Ограничения или грамматики определяют слова и фразы, которые распознаватель речи может распознать. Вы можете указать одну из предопределенных грамматик веб-служб или создать настраиваемую грамматику, установленную с приложением.
Предопределенные грамматики
Предопределенные диктовки и грамматики веб-поиска обеспечивают распознавание речи для приложения, не требуя создания грамматики. При использовании этих грамматик удаленная веб-служба выполняет распознавание речи и возвращает результаты устройству.
- Грамматика диктовки по умолчанию распознает большинство слов и фраз, которые пользователь может говорить на определенном языке. Он оптимизирован для распознавания коротких фраз. Используйте диктовку свободного текста, если вы не хотите ограничивать типы вещей, которые может сказать пользователь. Типичные варианты использования включают создание заметок или диктовку содержимого сообщения.
- Грамматика веб-поиска, например грамматика диктовки, содержит большое количество слов и фраз, которые может сказать пользователь. Тем не менее, он оптимизирован для распознавания терминов, которые обычно используются при поиске в Интернете.
Замечание
Так как предопределенные диктовки и грамматики веб-поиска могут быть большими и находятся в сети (не на устройстве), производительность может быть не такой быстрой, как у пользовательской грамматики, установленной на устройстве.
Эти предопределенные грамматики могут распознавать до 10 секунд ввода речи и не требуют усилий по разработке. Однако для них требуется подключение к сети.
Пользовательские грамматики
Создайте пользовательскую грамматику и установите её в ваше приложение. Устройство выполняет распознавание речи с помощью настраиваемого ограничения.
Ограничения программного списка обеспечивают упрощенный подход к созданию простых грамматик с помощью списка слов или фраз. Ограничение списка хорошо подходит для распознавания коротких, уникальных фраз. Явное указание всех слов в грамматике также повышает точность распознавания, так как подсистема распознавания речи должна обрабатывать только речь, чтобы подтвердить соответствие. Вы также можете программно обновить список.
Грамматика SRGS — это статический документ, который, в отличие от ограничения программного списка, использует формат XML, определенный SRGS версии 1.0. Грамматика SRGS обеспечивает наибольший контроль над интерфейсом распознавания речи, позволяя записывать несколько семантических значений в одном распознавании.
Ниже приведены некоторые советы по созданию грамматик SRGS:
- Делайте каждый синтаксис небольшим. Грамматики, содержащие меньше фраз, обычно обеспечивают более точное распознавание, чем более крупные грамматики, содержащие много фраз. Лучше иметь несколько небольших грамматик для конкретных сценариев, чем иметь одну грамматику для всего приложения.
- Сообщайте пользователям, что нужно сказать для каждого контекста приложения, а также включайте и отключайте грамматики по мере необходимости.
- Создайте каждую грамматику, чтобы пользователи могли говорить команду различными способами. Например, используйте правило МУСОР для сопоставления входных данных речи, которые не определены вашей грамматикой. Это правило позволяет пользователям говорить дополнительные слова, которые не имеют смысла для приложения. Например, "дай мне", "и", "э-э", "может быть", и т. д.
- Используйте элемент sapi:subset для сопоставления входных данных речи. Этот элемент представляет собой расширение Microsoft для спецификации SRGS, которое помогает в сопоставлении частичных фраз.
- Старайтесь избежать определения фраз в грамматике, содержащей только один слог. Распознавание, как правило, более точно для фраз, содержащих два или более слогов.
- Избегайте использования фраз, которые звучат аналогично. Например, такие фразы, как "hello", "bellow" и "fellow", могут вызывать проблемы для механизма распознавания и привести к низкой точности распознавания.
Замечание
Какой тип ограничения вы используете, зависит от сложности создаваемого интерфейса распознавания. Любой тип может быть лучшим выбором для конкретной задачи распознавания, и вы можете найти использование для всех типов ограничений в приложении.
Пользовательские произношения
Если ваше приложение содержит специализированный словарь с необычными или вымышленными словами или словами с необычными произношениями, вы можете улучшить производительность распознавания этих слов, определив пользовательские произношения.
Для небольшого списка слов и фраз или списка редко используемых слов и фраз создайте пользовательские произношения в грамматике SRGS. Подробности смотрите в элементе token.
Для более крупных списков слов и фраз или часто используемых слов и фраз создайте отдельные документы лексикона произношения. Дополнительные сведения см. в разделе о Lexicons и Фонетических алфавитах .
Тестирование
Проверьте точность распознавания речи и любой вспомогательный пользовательский интерфейс с целевой аудиторией вашего приложения. Этот подход помогает определить эффективность взаимодействия с речью в приложении. Например, пользователи получают плохие результаты распознавания, так как ваше приложение не прослушивает общую фразу?
Измените грамматику для поддержки этой фразы или предоставьте пользователям список поддерживаемых фраз. Если вы уже предоставляете список поддерживаемых фраз, убедитесь, что пользователи могут легко найти его.
Преобразование текста в речь (TTS)
TTS создает выходные данные речи из обычного текста или SSML.
Попробуйте разработать подсказки, которые вежливые и обнадеживающие.
Рассмотрим, следует ли читать длинные строки текста. Это одна вещь, чтобы слушать текстовое сообщение, но совсем другое, чтобы слушать длинный список результатов поиска, которые трудно помнить.
Предоставьте элементы управления мультимедиа, чтобы разрешить пользователям приостановить или остановить TTS.
Прослушивайте все строки TTS, чтобы убедиться, что они понятны и звучат естественно.
- Связывание воедино необычной последовательности слов, произнесения номеров деталей или знаков препинания может привести к тому, что фраза становится неразборчивой.
- Речь может звучать неестественно, когда просодия или каденция отличается от того, как носитель языка сказал бы фразу.
Обе проблемы можно решить с помощью SSML вместо обычного текста в качестве входных данных синтезатора речи. Дополнительные сведения о SSML см. в разделах Использование SSML для управления синтезированной речью и Справочник по языку разметки синтеза речи.