Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Показывает, как управлять жизненным циклом данных ресурсов путем отслеживания хода выполнения GPU с помощью заборов. Память можно эффективно повторно использовать с заборами, тщательно управляя доступностью свободного места в памяти, например в реализации буфера кольца для кучи отправки.
- Сценарий буфера кольца
- Пример буфера кольца
- связанные разделы
Сценарий кольцевого буфера
Ниже приведен пример, в котором приложение испытывает редкий спрос на память кучи отправки.
Кольцевой буфер — это один из способов управления кучей отправки. Буфер кольца содержит данные, необходимые для следующих нескольких кадров. Приложение поддерживает текущий указатель ввода данных и очередь смещения кадров для записи каждого кадра и начального смещения данных ресурсов для этого кадра.
Приложение создает кольцевой буфер на основе буфера для передачи данных в GPU для каждого кадра. В настоящее время кадр 2 отрисовывается, кольцевой буфер обтекает данные кадра 4, все данные, необходимые для кадра 5, и большой буфер константы, необходимый для кадра 6, должен быть выделен вложен.
рис. 1: приложение пытается выделить вложенный буфер констант, но находит недостаточно свободного памяти.
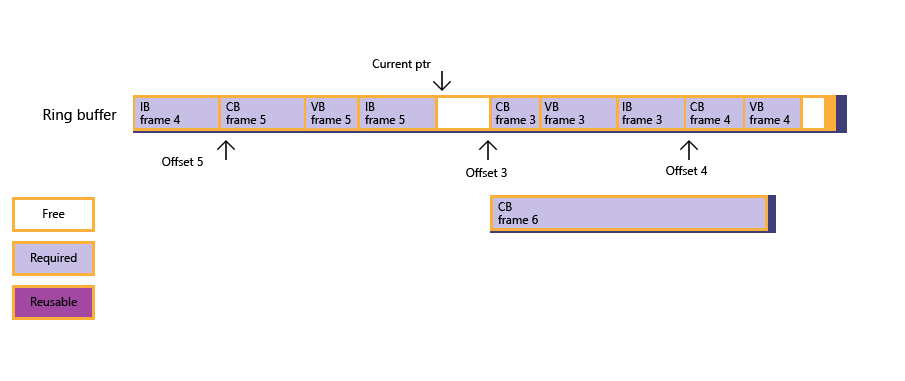
рис. 2: через опрос забора приложение обнаруживает, что кадр 3 был отрисован, очередь смещения кадра обновляется, а текущее состояние буфера кольца следует. Однако свободное память по-прежнему недостаточно большая, чтобы разместить буфер констант.
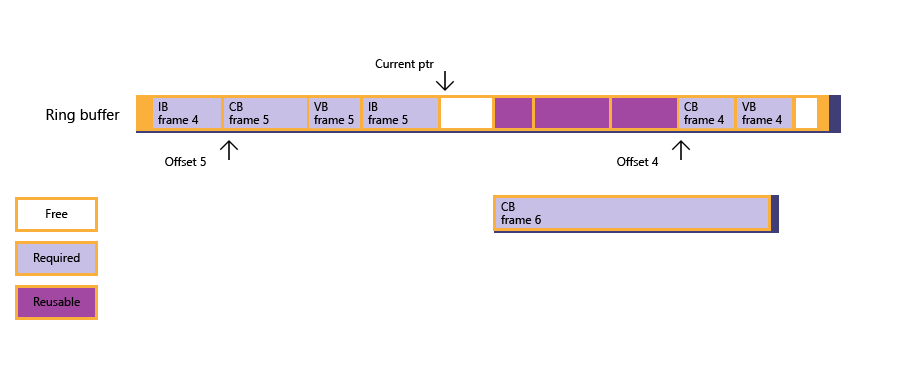
рис. 3: учитывая ситуацию, ЦП блокирует себя (через ограждение ожидания) до отрисовки кадра 4, который освобождает подсеть памяти, выделенную для кадра 4.
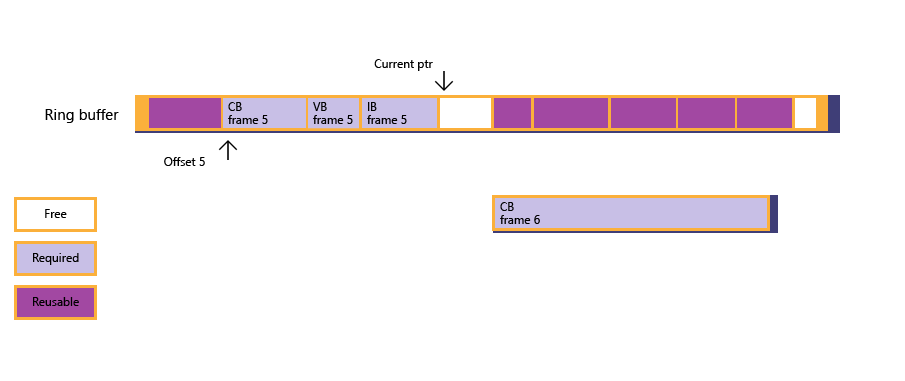
рис. 4: теперь объем свободной памяти достаточно велик для буфера констант, и выделение вложенного распределения успешно; Приложение копирует данные буфера больших констант в память, ранее используемые данными ресурсов для обоих кадров 3 и 4. Текущий указатель ввода, наконец, обновляется.
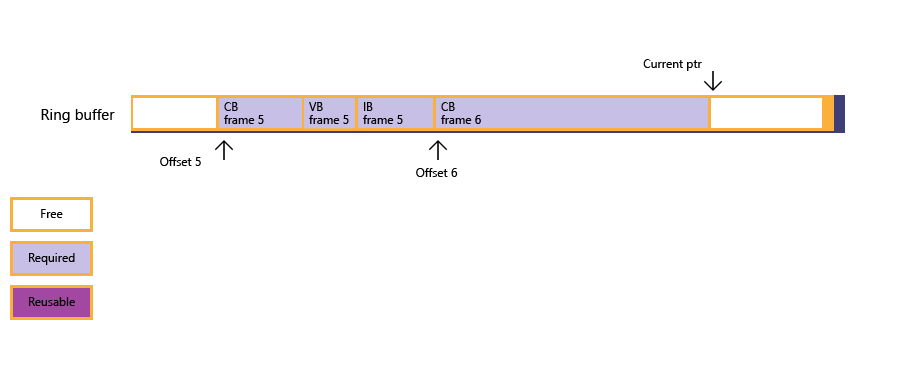
Если приложение реализует кольцевой буфер, кольцевой буфер должен быть достаточно большим, чтобы справиться с худшим сценарием размеров данных ресурсов.
Пример кольцевого буфера
В следующем примере кода показано, как управлять кольцевым буфером, обращая внимание на подпрограмму подраспределения, которая обрабатывает опросы и ожидание забора. Для простоты в примере используется NOT_SUFFICIENT_MEMORY для скрытия сведений о "недостаточной свободной памяти, найденной в куче", так как эта логика (на основе m_pDataCur и смещения внутри FrameOffsetQueue) не тесно связана с кучами или заборами. Пример упрощен для того, чтобы пожертвовать скоростью кадров вместо использования памяти.
Обратите внимание, что поддержка кольцевого буфера, как ожидается, является популярным сценарием; Однако конструкция кучи не исключает другое использование, например параметризацию списка команд и повторное использование.
struct FrameResourceOffset
{
UINT frameIndex;
UINT8* pResourceOffset;
};
std::queue<FrameResourceOffset> frameOffsetQueue;
void DrawFrame()
{
float vertices[] = ...;
UINT verticesOffset = 0;
ThrowIfFailed(
SetDataToUploadHeap(
vertices, sizeof(float), sizeof(vertices) / sizeof(float),
4, // Max alignment requirement for vertex data is 4 bytes.
verticesOffset
));
float constants[] = ...;
UINT constantsOffset = 0;
ThrowIfFailed(
SetDataToUploadHeap(
constants, sizeof(float), sizeof(constants) / sizeof(float),
D3D12_CONSTANT_BUFFER_DATA_PLACEMENT_ALIGNMENT,
constantsOffset
));
// Create vertex buffer views for the new binding model.
// Create constant buffer views for the new binding model.
// ...
commandQueue->Execute(commandList);
commandQueue->AdvanceFence();
}
HRESULT SuballocateFromHeap(SIZE_T uSize, UINT uAlign)
{
if (NOT_SUFFICIENT_MEMORY(uSize, uAlign))
{
// Free up resources for frames processed by GPU; see Figure 2.
UINT lastCompletedFrame = commandQueue->GetLastCompletedFence();
FreeUpMemoryUntilFrame( lastCompletedFrame );
while ( NOT_SUFFICIENT_MEMORY(uSize, uAlign)
&& !frameOffsetQueue.empty() )
{
// Block until a new frame is processed by GPU, then free up more memory; see Figure 3.
UINT nextGPUFrame = frameOffsetQueue.front().frameIndex;
commandQueue->SetEventOnFenceCompletion(nextGPUFrame, hEvent);
WaitForSingleObject(hEvent, INFINITE);
FreeUpMemoryUntilFrame( nextGPUFrame );
}
}
if (NOT_SUFFICIENT_MEMORY(uSize, uAlign))
{
// Apps need to create a new Heap that is large enough for this resource.
return E_HEAPNOTLARGEENOUGH;
}
else
{
// Update current data pointer for the new resource.
m_pDataCur = reinterpret_cast<UINT8*>(
Align(reinterpret_cast<SIZE_T>(m_pHDataCur), uAlign)
);
// Update frame offset queue if this is the first resource for a new frame; see Figure 4.
UINT currentFrame = commandQueue->GetCurrentFence();
if ( frameOffsetQueue.empty()
|| frameOffsetQueue.back().frameIndex < currentFrame )
{
FrameResourceOffset offset = {currentFrame, m_pDataCur};
frameOffsetQueue.push(offset);
}
return S_OK;
}
}
void FreeUpMemoryUntilFrame(UINT lastCompletedFrame)
{
while ( !frameOffsetQueue.empty()
&& frameOffsetQueue.first().frameIndex <= lastCompletedFrame )
{
frameOffsetQueue.pop();
}
}
Связанные разделы