Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
API InkAnalysis предоставляют разработчикам планшетных пк мощные средства для программного анализа входных данных рукописного ввода. API классифицирует чернила в значимые категории, такие как слова, строки, абзацы и рисунки.
Вы можете использовать каждую классификацию различными способами, включая улучшение результатов распознавания для рукописного ввода.
Основы анализа чернил
В этом разделе представлена технология анализа рукописного ввода Платформы Планшетного ПК и объясняется, когда и как ее использовать.
API InkAnalysis эффективно объединяет две различные, но взаимодополняющие технологии: распознавание рукописного ввода и классификацию макетов. Объединение этих двух технологий дает окончательно больше результатов, чем части, взятые в одиночку.
Распознавание рукописного текста — это вычислительный анализ рукописного ввода для получения интерпретации на основе символов на заданном языке. То есть распознавание рукописного ввода — это то, как компьютер "считывает" рукописный текст человека.
Анализ чернил можно разделить на классификацию чернил и анализ макета. Классификация чернил — это вычислительное деление чернил на семантически значимые единицы, такие как абзацы, строки, слова и рисунки. Анализ макета — это вычислительный осмотр ввода чернил, чтобы определить положение чернил на поверхности, на которую нанесены чернила, и как штрихи связаны друг с другом пространственно и даже семантически. Например, анализ макета может сказать вам, что определенный фрагмент чернильного штриха является заметкой или выноской.
Распознавание
Один из примеров того, как сочетание распознавания с анализом рукописного ввода в API InkAnalysis помогает разработчику улучшить результаты распознавания. Обработчики распознавания рукописного ввода планшетного пк были в основном предназначены для распознавания одной горизонтальной линии рукописного ввода. Тем не менее, люди, как правило, пишут несколько строк, когда делают заметки, и эти строки не всегда будут горизонтальными относительно страницы. С помощью API InkAnalysis рукописный ввод предварительно обрабатывается анализатором рукописного ввода перед отправкой распознавателю. Проанализированные чернила преобразуются в горизонтальное положение до распознавания, что улучшает результаты распознавания.
Другие преимущества для распознавания заключаются в том, что анализатор рукописного ввода исправляет неправильные сведения о порядке штриха перед отправкой его распознавателю. Кроме того, результаты распознавания теперь доступны выборочно. То есть разработчик может быстро получить результаты распознавания для одного слова, строки или абзаца в одном вызове.
Классификация чернил
Существует, конечно, множество сценариев, в которых можно сохранить данные рукописного ввода без изменений, а не преобразовывать его сразу в текст. Анализ чернил также приносит преимущества. В частности, API-интерфейсы InkAnalysis предоставляют возможность разделения росчерков рукописного ввода на рукописный текст и рисунки. Рукописные росчерки, которые классифицируются как написание, являются теми, которые составляют слово или символы. Все остальные росчерки являются рисунками. Это обеспечивает новый способ доступа к данным рукописного ввода, что позволяет создавать новые пользовательские сценарии. Например, вы можете реализовать выбор, чтобы он был различным в зависимости от типа штриха, по которому пользователь нажимает; Если пользователь касается штриха письма, приложение выбирает весь набор штрихов, составляющих слово, если пользователь нажимает на рисовальный штрих, приложение выбирает только этот штрих.
Анализ макета
Полезный анализ макета на самом деле выходит за рамки относительно простой разделения чернил на составляющие письменных и рисовальных элементов.
Анализ чернил также включает более детальную разбивку штрихов письма и рисования. В качестве очень простого примера возьмите кляксу чернил, как показано на следующем рисунке.

После анализа этих штрихов платформа возвращает дерево представления этих штрихов, как показано на следующем рисунке. В этом простом случае дерево содержит только абзац, строку и информацию о слове, но богатство этого дерева увеличивается по мере увеличения сложности рукописного документа.
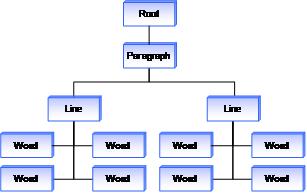
Так как эта информация теперь разделена на управляемые единицы, теперь вы можете создавать более мощные функции. Например, приложение может расширить функцию, позволяющую пользователю нажимать для выбора слова, в функцию, где он нажимает один раз, чтобы выбрать слово, дважды – чтобы выбрать всю строку, и три раза – чтобы выбрать весь абзац. Используя структуру дерева, возвращаемую операцией анализа, приложение может связывать область, на которую нажали, с отдельным штрихом в структуре дерева. После того как приложение находит штрих, оно может перемещаться по дереву, чтобы определить, как и какие соседние штрихи выбрать.
Выбор всей строки является упрощённым примером преимуществ анализа рукописного ввода, но возможности значительно расширяются, когда принимаются во внимание различные типы иерархических структур, которые анализатор рукописного ввода способен обнаруживать.
- Упорядоченные и неупорядоченные списки
- Формы
- Аннотированные комментарии, встроенные в текст
Типы функций зависят от приложения к приложению и зависят от требований и доступных обработчиков анализа рукописного ввода и распознавания.
Основные функции анализа чернил
Основные возможности API InkAnalysis включают следующие функции:
- Пошаговый анализ
- Упорство
- Прокси-сервер данных
- Примирение
- Расширяемость
Пошаговый анализ
Когда конечные пользователи работают с чернилами, они обычно обрабатывают его как рукописный ввод. Чернила постоянно подвергаются операциям редактирования, таким как добавление новых чернил, удаление существующих чернил и изменение их свойств, и все это делается так же, как постоянно редактируется рукопись. Эти операции редактирования влияют на результаты анализа. При возникновении изменений они обычно могут быть выделены в разделы документа в определенные моменты времени. Например, предположим, что пользователь пишет пять строк чернил. Стандартный способ анализа рукописного ввода приложений — ждать, пока пользователь не завершит запись всех пяти строк рукописного ввода ( например, абзаца), а затем анализирует результаты синхронно или асинхронно.
Вы можете оптимизировать общее время, затрачиваемое на анализ этих пяти строк, изолируя области, которые анализируются по мере их написания, а затем повторно анализируя только те части результатов, которые изменились. После анализа первой строки он никогда не будет распознаться снова, если он не изменяется конечным пользователем. Распознавание второй строки рассматривается как независимая операция распознавания.
Этот поэтапный подход эффективен на уровне строки для задачи распознавания, но должен работать на более высоком уровне для анализа рукописи. Так как анализатор рукописного ввода может обнаруживать различные классификации более высокого уровня для этих пяти строк рукописного ввода (например, это может быть стандартный абзац или пять элементов в списке), добавочный подход для анализатора рукописного ввода заключается в том, что он должен анализировать эти более высокие структуры. То есть после того, как анализатор рукописного ввода классифицирует первую строку рукописного ввода в виде строки, он дважды проверяет, что он по-прежнему является линией при классификации второй строки. Однако анализатор рукописного ввода изолирует этот двойный анализ абзаца и игнорирует первый абзац при анализе второго абзаца, рассматривая второй абзац как независимую операцию анализатора рукописного ввода. Этот постепенный подход к анализу значительно экономит время обработки, когда в приложении уже существует большое количество чернил.
Упорство
Инкрементный анализ хорошо функционирует в определённом сеансе или экземпляре объекта InkAnalyzer. Однако api-интерфейсы платформы планшетного пк первого поколения не могут выполнять добавочный анализ после сохранения рукописного ввода на диске. API InkAnalysis позволяет сохранять рукопись на диск вместе с устойчивой формой результатов анализа. Результаты анализа могут быть загружены при загрузке чернил и введены в новый экземпляр InkAnalyzer. Новый экземпляр объекта InkAnalyzer затем имеет то же состояние результатов, что и ранее, и теперь может принимать любые изменения в виде добавочных изменений в существующем состоянии, а не анализировать все снова.
Прокси-сервер данных
Многие приложения уже имеют существующую структуру документов в своих приложениях; например, граф или база данных. InkAnalyzer также предоставляет результаты в структурированной форме, в виде дерева объектов ContextNode. Структура InkAnalyzer и существующая структура приложения должны взаимодействовать в двух направлениях: результаты извлекаются из InkAnalyzer в приложение, а состояние отправляется из приложения в InkAnalyzer.
Если бы извлечение результатов из InkAnalyzer в структуру приложения было всем, что необходимо, это было бы относительно просто. Приложения будут выполнять итерацию по дереву результатов и копировать (интегрировать) все результаты, необходимые им в существующую структуру данных. Однако, поскольку многие горизонтальные приложения требуют добавочного анализа и сохраняемости на диске, проблема становится двухнаправленной. Состояние (прошлые результаты) необходимо извлечь из структуры приложения и передать в InkAnalyzer.
В соответствии с этим требованием InkAnalyzer содержит ряд событий, которые он вызывает в соответствующее время во время операции анализа, чтобы позволить приложениям направлять запросы на доступ к данным обратно в существующие структуры. Эти события создаются только для тех объектов ContextNode, необходимых для инкрементальной операции.
Примирение
Большинство приложений будет анализировать рукописный ввод в фоновом режиме, чтобы минимизировать прерывания работы пользовательского интерфейса. При анализе рукописного ввода в фоновом режиме возникают проблемы, если пользователь изменяет рукописный ввод (или соседний рукописный ввод), который анализируется. Например, если пользователь удаляет рукописный ввод во время фоновой операции, результирующая структура будет отражать состояние документа при начале фоновой операции, а не когда она завершилась.
Чтобы помочь приложениям, InkAnalyzer сопоставляет различия в состоянии документа между началом и окончанием операции анализа. Изменения, внесенные пользователем или приложением во время выполнения анализа в фоновом режиме, всегда переопределяют результаты, вычисляемые в фоновом режиме. После выверки сообщаются только части структуры результатов, которые не конфликтуют с изменениями документа, и конфликтующие штрихи помечены для дальнейшего анализа. При следующем выполнении фоновой операции анализа результаты пересчитываются на основе нового состояния.
На следующей схеме показан этот процесс. Время выражается линейно от верхней до нижней части диаграммы.
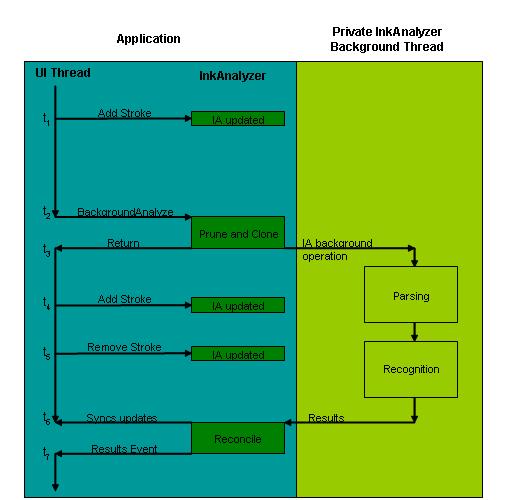
- Во время 1 (t1) приложение собирает чернила от конечного пользователя, включая любые изменения чернил, такие как добавление, удаление или изменение.
- В момент t2 приложение запускает операцию фонового анализа. InkAnalyzer определяет, какие рукописные фрагменты не имеют результатов и какие рукописные фрагменты необходимо перепроверить. Он копирует необходимые данные рукописного ввода, чтобы разрешить фоновому потоку выполняться независимо.
- На t3 InkAnalyzer передает выполнение потока пользовательского интерфейса обратно приложению. InkAnalyzer создает второй поток — поток фонового анализа, а двигатели анализа и распознавания рукописных данных анализируют скопированные рукописные данные.
- Пока операция анализа выполняется во втором фоновом потоке, конечный пользователь продолжает редактировать документ, добавляя и удаляя данные о штрихах, на этапах t4 и t5. Эти изменения могут конфликтуть с работой, которая выполняется в фоновом режиме.
- В t6 фоновый поток завершил операцию анализа и результаты готовы. Прежде чем InkAnalyzer сообщает результаты приложению, он запускает алгоритм согласования, чтобы определить, противоречит ли правка пользователя, сделанная во время вычисления операции анализа (t4 и t5), результатам. При обнаружении каких-либо столкновений штрихи помечаются для повторного анализа, который происходит при следующем запуске фонового анализа приложения.
- Наконец, на этапе t7, после обнаружения всех столкновений, InkAnalyzer представляет результаты приложению.
Расширяемость
API InkAnalysis позволяют использовать новые типы обработчиков анализа приложениями таким образом, чтобы предотвратить необходимость переопределения всех преимуществ API InkAnalysis, включая выверку, прокси-сервер данных, сохраняемость и добавочный анализ.
Связанные разделы