Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
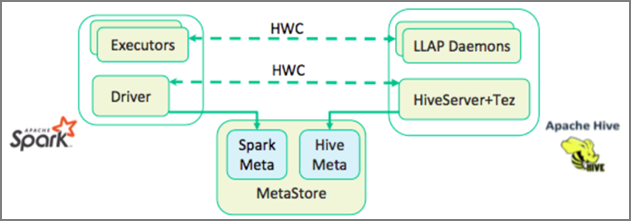
Apache Hive Ambar Bağlayıcısı (HWC), Apache Spark ve Apache Hive ile daha kolay çalışmanızı sağlayan bir kitaplıktır. Spark DataFrame'ler ile Hive tabloları arasında veri taşıma gibi görevleri destekler. Ayrıca Spark akış verilerini Hive tablolarına yönlendirerek. Hive Ambarı Bağlayıcısı, Spark ile Hive arasında bir köprü gibi çalışır. Geliştirme için programlama dilleri olarak Scala, Java ve Python'ı da destekler.
Hive Ambarı Bağlayıcısı, güçlü büyük veri uygulamaları oluşturmak için Hive ve Spark'ın benzersiz özelliklerinden yararlanmanızı sağlar.
Apache Hive, Atomik, Tutarlı, Yalıtılmış ve Dayanıklı (ACID) veritabanı işlemleri için destek sunar. ACID ve Hive'daki işlemler hakkında daha fazla bilgi için bkz . Hive İşlemleri. Hive ayrıca Apache Ranger aracılığıyla ayrıntılı güvenlik denetimleri ve Apache Spark'ta kullanılamayan Düşük Gecikmeli Analitik İşleme (LLAP) sunar.
Apache Spark, Apache Hive'da kullanılamayan akış özellikleri sağlayan yapılandırılmış bir Akış API'sini içerir. HDInsight 4.0 sürümünden başlayarak Apache Spark 2.3.1 ve üzeri ile Apache Hive 3.1.0'ın birlikte çalışabilirliği zorlaştıran ayrı meta veri deposu katalogları vardır.
Hive Ambarı Bağlayıcısı (HWC), Spark ve Hive'ın birlikte kullanılmasını kolaylaştırır. HWC kitaplığı, LLAP daemon'larından Spark yürütücülerine paralel olarak veri yükler. Bu işlem, Spark'tan Hive'a standart bir JDBC bağlantısından daha verimli ve uyarlanabilir hale getirir. Bu, HWC için iki farklı yürütme modu sunar:
- HiveServer2 aracılığıyla Hive JDBC modu
- LLAP daemon'larını kullanan Hive LLAP modu [Önerilen]
Varsayılan olarak HWC, Hive LLAP daemon'larını kullanacak şekilde yapılandırılır. Yukarıdaki modları ve ilgili API'lerini kullanarak Hive sorgularını (hem okuma hem de yazma) yürütmek için bkz . HWC API'leri.
Hive Ambarı Bağlayıcısı tarafından desteklenen işlemlerden bazıları şunlardır:
- Tabloyu açıklama
- ORC biçimli veriler için tablo oluşturma
- Hive verilerini seçme ve DataFrame alma
- Toplu olarak Hive'a DataFrame yazma
- Hive güncelleştirme deyimi yürütme
- Tablo verilerini Hive'dan okuma, Spark'ta dönüştürme ve yeni bir Hive tablosuna yazma
- HiveStreaming kullanarak Hive'a DataFrame veya Spark akışı yazma
Hive Ambarı Bağlayıcısı kurulumu
Önemli
- Hive Ambarı Bağlayıcısı (HWC) Kitaplığı, İş Yükü Yönetimi (WLM) özelliğinin etkinleştirildiği Etkileşimli Sorgu Kümeleri ile kullanılmak üzere desteklenmez.
Yalnızca Spark iş yükleriniz olduğu ve HWC Kitaplığı kullanmak istediğiniz bir senaryoda, Etkileşimli Sorgu kümesinde İş Yükü Yönetimi özelliğinin etkin olmadığından emin olun (hive.server2.tez.interactive.queueHive yapılandırmalarında yapılandırma ayarlanmaz).
Hem Spark iş yüklerinin (HWC) hem de LLAP yerel iş yüklerinin mevcut olduğu bir senaryo için, paylaşılan meta veri deposu veritabanıyla iki ayrı Etkileşimli Sorgu Kümesi oluşturmanız gerekir. WLM özelliğinin ihtiyaç temelinde etkinleştirilebildiği yerel LLAP iş yükleri için bir küme ve yalnızca WLM özelliğinin yapılandırılmaması gereken HWC iş yükü için diğer küme. Yalnızca bir kümede etkinleştirilmiş olsa bile her iki kümeden de WLM kaynak planlarını görüntüleyebileceğinizi unutmayın. Diğer kümedeki WLM işlevselliğini etkileyebileceğinden WLM özelliğinin devre dışı bırakıldığı kümedeki kaynak planlarında herhangi bir değişiklik yapmayın. - Spark, veri analizini basitleştirmek için R bilgi işlem dilini desteklese de, Hive Warehouse Connector (HWC) Kitaplığı'nın R ile kullanılması desteklenmez. HWC iş yüklerini yürütmek için yalnızca Scala, Java ve Python'ı destekleyen JDBC stili HiveWarehouseSession API'sini kullanarak Spark'tan Hive'a sorgu yürütebilirsiniz.
- HiveServer2 aracılığıyla JDBC modu aracılığıyla sorguların (hem okuma hem de yazma) yürütülmesi, Diziler/Yapı/Eşleme türleri gibi karmaşık veri türleri için desteklenmez.
- HWC yalnızca ORC dosya biçimlerinde yazmayı destekler. ORC olmayan yazma işlemleri (örn. parquet ve metin dosyası biçimleri) HWC aracılığıyla desteklenmez.
Hive Warehouse Bağlayıcısı Spark ve Etkileşimli Sorgu iş yükleri için ayrı kümelere ihtiyaç duyar. Bu kümeleri Azure HDInsight'ta ayarlamak için bu adımları izleyin.
Desteklenen Küme türleri ve sürümleri
| HWC Sürümü | Spark Sürümü | InteractiveQuery Sürümü |
|---|---|---|
| v2.1 | Spark 3.3.0 | HDI 5.1 | Etkileşimli Sorgu 3.1 | HDI 5.1 |
Küme oluşturma
Depolama hesabı ve özel bir Azure sanal ağı ile HDInsight Spark 5.1 kümesi oluşturun. Azure sanal ağında küme oluşturma hakkında bilgi için bkz . Var olan bir sanal ağa HDInsight ekleme.
Spark kümesiyle aynı depolama hesabına ve Azure sanal ağına sahip bir HDInsight Etkileşimli Sorgu (LLAP) 5.1 kümesi oluşturun.
HWC ayarlarını yapılandırma
Ön bilgileri toplama
Bir web tarayıcısından LLAPCLUSTERNAME'in Etkileşimli Sorgu kümenizin adı olduğu yere gidin
https://LLAPCLUSTERNAME.azurehdinsight.net/#/main/services/HIVE.Özet>gidin ve değeri not edin. Değer şuna benzer olabilir:
jdbc:hive2://<zookeepername1>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2ce.bx.internal.cloudapp.net:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2-interactive.Configs>Advanced>hive.zookeeper.quorum adresine gidin ve değeri not edin. Değer şuna benzer olabilir:
<zookeepername1>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181.> hive.metastore.uris adresine gidin ve değeri not edin. Değer şuna benzer olabilir:
thrift://iqgiro.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083,thrift://hn*.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083.Configs>Advanced Advanced>hive.llap.daemon.service.hosts adresine gidin ve değeri not edin. Değer şuna benzer olabilir:
@llap0.
Spark kümesi ayarlarını yapılandırma
Web tarayıcısından CLUSTERNAME'in Apache Spark kümenizin adı olduğu yere gidin
https://CLUSTERNAME.azurehdinsight.net/#/main/services/SPARK2/configs.Özel spark2-defaults seçeneğini genişletin.
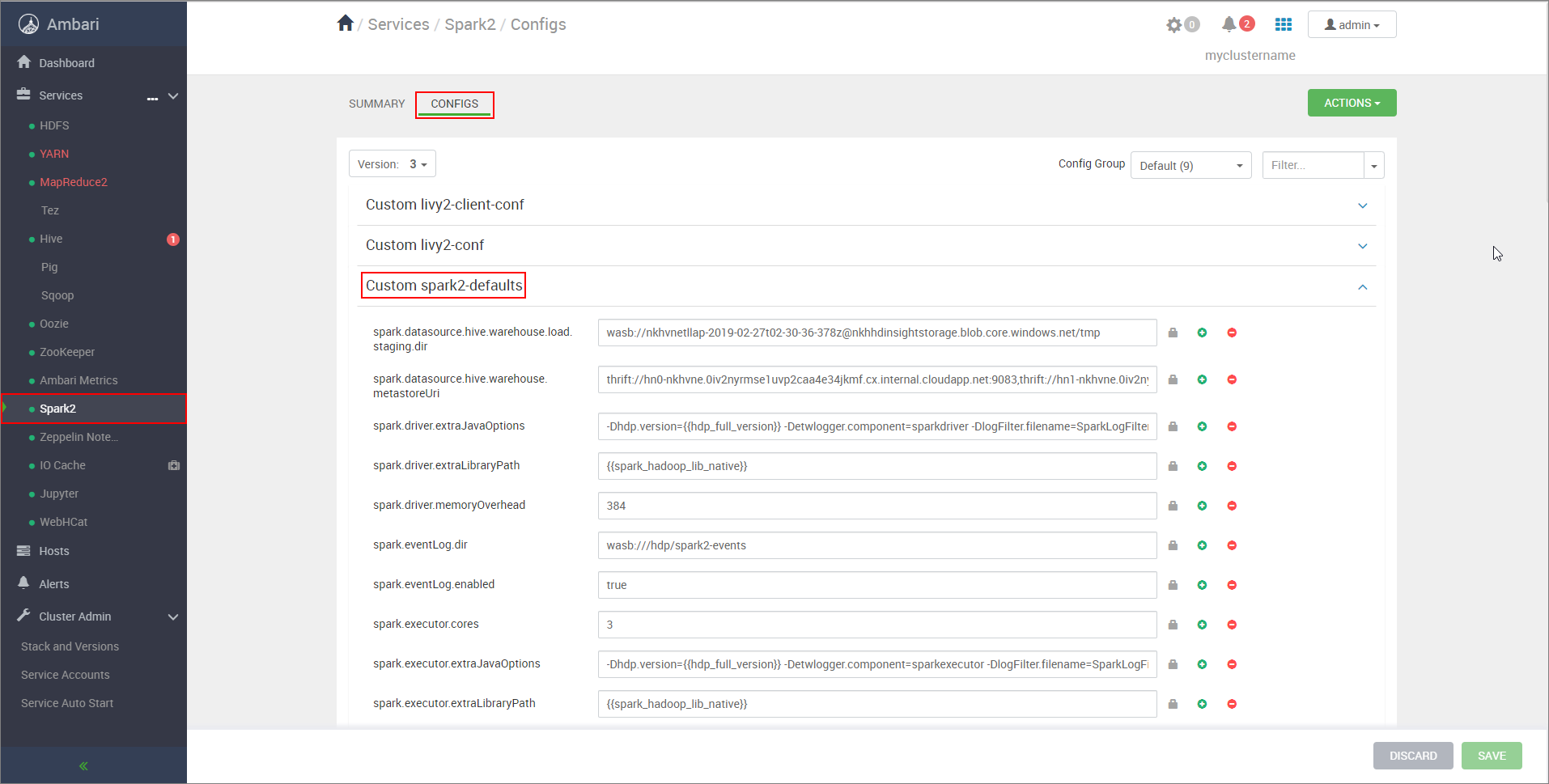
Aşağıdaki yapılandırmaları eklemek için Özellik Ekle... öğesini seçin:
Yapılandırma Değer spark.datasource.hive.warehouse.load.staging.dirADLS 2. Nesil Depolama Hesabı kullanıyorsanız abfss://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.dfs.core.windows.net/tmp
Azure Blob Depolama Hesabı kullanıyorsanız kullanınwasbs://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.blob.core.windows.net/tmp.
Uygun bir HDFS uyumlu hazırlama dizinine ayarlayın. İki farklı kümeniz varsa, hazırlama dizini LLAP kümesinin depolama hesabının hazırlama dizininde bir klasör olmalıdır, böylece HiveServer2 buna erişebilir. değerini küme tarafından kullanılan depolama hesabının adıyla veSTORAGE_ACCOUNT_NAMEdepolama kapsayıcısının adıyla değiştirinSTORAGE_CONTAINER_NAME.spark.sql.hive.hiveserver2.jdbc.urlHiveServer2 Etkileşimli JDBC URL'sinden daha önce aldığınız değer spark.datasource.hive.warehouse.metastoreUriHive.metastore.uris'ten daha önce aldığınız değer. spark.security.credentials.hiveserver2.enabledtrueyarn küme modu vefalseYARN istemci modu için.spark.hadoop.hive.zookeeper.quorumHive.zookeeper.quorum'dan daha önce aldığınız değer. spark.hadoop.hive.llap.daemon.service.hostsHive.llap.daemon.service.hosts'tan daha önce aldığınız değer. Değişiklikleri kaydedin ve etkilenen tüm bileşenleri yeniden başlatın.
Spark ve Hive için ek yapılandırmalar
Spark ve Hive kümelerinizin tüm baş ve çalışan düğümleri için aşağıdaki yapılandırmanın yapılması gerekir.
Apache Spark ve Apache Hive düğümlerinize bağlanmak için ssh komutunu kullanın. CLUSTERNAME değerini kümenizin adıyla değiştirerek aşağıdaki komutu düzenleyin ve komutunu girin:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netSpark kümesinin /etc/hosts dosyasına hive kümesinin /etc/hosts dosyasının içeriğini ekleyin (tam tersi).
Tüm düğümler güncelleştirildikten sonra her iki kümeyi de yeniden başlatın.
Kurumsal Güvenlik Paketi (ESP) kümeleri için HWC'yi yapılandırma
Kurumsal Güvenlik Paketi (ESP), Azure HDInsight'taki Apache Hadoop kümeleri için Active Directory tabanlı kimlik doğrulaması, çok kullanıcılı destek ve rol tabanlı erişim denetimi gibi kurumsal düzeyde özellikler sağlar. ESP hakkında daha fazla bilgi için bkz . HDInsight'ta Kurumsal Güvenlik Paketi kullanma.
Önceki bölümde bahsedilen yapılandırmaların dışında, ESP kümelerinde HWC kullanmak için aşağıdaki yapılandırmayı ekleyin.
Spark kümesinin Ambari web kullanıcı arabiriminde Spark2 CONFIGS>gidin.
Aşağıdaki özelliği güncelleştirin.
Yapılandırma Değer spark.sql.hive.hiveserver2.jdbc.url.principalhive/<llap-headnode>@<AAD-Domain>Web tarayıcısından CLUSTERNAME'in Etkileşimli Sorgu kümenizin adı olduğu yere gidin
https://CLUSTERNAME.azurehdinsight.net/#/main/services/HIVE/summary. HiveServer2 Interactive'e tıklayın. Ekran görüntüsünde gösterildiği gibi LLAP'nin üzerinde çalıştığı baş düğümün Tam Etki Alanı Adı'nı (FQDN) görürsünüz. değerini bu değerle değiştirin<llap-headnode>.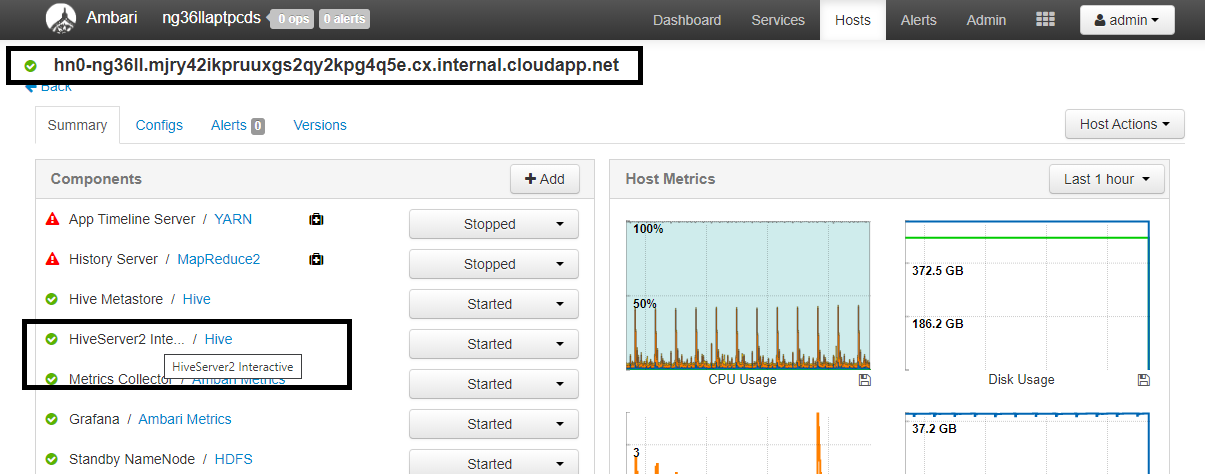
Etkileşimli Sorgu kümenize bağlanmak için ssh komutunu kullanın. Dosyasında parametresini
default_realmarayın/etc/krb5.conf. değerini büyük harf dize olarak bu değerle değiştirin<AAD-DOMAIN>; aksi takdirde kimlik bilgisi bulunmaz.
Örneğin,
hive/hn*.mjry42ikpruuxgs2qy2kpg4q5e.cx.internal.cloudapp.net@PKRSRVUQVMAE6J85.D2.INTERNAL.CLOUDAPP.NET.
Spark ve Hive kümelerinizin tüm baş ve çalışan düğümleri için aşağıdaki yapılandırmanın yapılması gerekir.
Apache Spark ve Apache Hive düğümlerinize bağlanmak için ssh komutunu kullanın. CLUSTERNAME değerini kümenizin adıyla değiştirerek aşağıdaki komutu düzenleyin ve komutunu girin:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netSpark ve Hive kümelerinizin baş ve çalışan düğümlerinde /etc/resolv.conf dosyasının son satırına kiracı etki alanı adını (örn. "fabrikam.onmicrosoft.com") ekleyin.
Değişiklikleri kaydedin ve bileşenleri gerektiği gibi yeniden başlatın.
Hive Ambarı Bağlayıcısı kullanımı
Etkileşimli Sorgu kümenize bağlanmak ve Hive Ambar Bağlayıcısı'nı kullanarak sorgu yürütmek için birkaç farklı yöntem arasından seçim yapabilirsiniz. Desteklenen yöntemler aşağıdaki araçları içerir:
Aşağıda Spark'tan HWC'ye bağlanmak için bazı örnekler verilmiştir.
Spark kabuğu
Bu, Scala kabuğunun değiştirilmiş bir sürümü aracılığıyla Spark'ı etkileşimli olarak çalıştırmanın bir yoludur.
Apache Spark kümenize bağlanmak için ssh komutunu kullanın. CLUSTERNAME değerini kümenizin adıyla değiştirerek aşağıdaki komutu düzenleyin ve komutunu girin:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netSsh oturumunuzda aşağıdaki komutu yürüterek sürümü not alın
hive-warehouse-connector-assembly:ls /usr/hdp/current/hive_warehouse_connectorAşağıdaki kodu yukarıda tanımlanan sürümle
hive-warehouse-connector-assemblydüzenleyin. Ardından spark kabuğunu başlatmak için komutunu yürütür:spark-shell --master yarn \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=falseSpark kabuğunu başlattıktan sonra, aşağıdaki komutlar kullanılarak bir Hive Ambarı Bağlayıcısı örneği başlatılabilir:
import com.hortonworks.hwc.HiveWarehouseSession val hive = HiveWarehouseSession.session(spark).build()
Spark-submit
Spark-submit , Spark kümelerine herhangi bir Spark programı (veya işi) göndermeye yönelik bir yardımcı programdır.
İş spark-submit , yönergelerimize göre Spark ve Hive Ambarı Bağlayıcısı'nı ayarlayıp yapılandıracak, bu bağlayıcıya geçirdiğimiz programı yürütecek ve ardından kullanılmakta olan kaynakları temiz bir şekilde serbest bırakacaktır.
Scala/java kodunu ve bağımlılıkları bir derleme jar'ıyla derledikten sonra bir Spark uygulaması başlatmak için aşağıdaki komutu kullanın. ve <VERSION> değerlerini gerçek değerlerle değiştirin<APP_JAR_PATH>.
YARN İstemci modu
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode client \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=false /<APP_JAR_PATH>/myHwcAppProject.jarYARN Kümesi modu
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode cluster \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=true /<APP_JAR_PATH>/myHwcAppProject.jar
Bu yardımcı program, uygulamanın tamamını pySpark'ta yazıp dosyalara .py (Python) paketlediğimizde de kullanılır, böylece kodun tamamını yürütme için Spark kümesine gönderebiliriz.
Python uygulamaları için yerine bir .py dosyası /<APP_JAR_PATH>/myHwcAppProject.jargeçirin ve ile --py-filesarama yoluna aşağıdaki yapılandırma (Python .zip) dosyasını ekleyin.
--py-files /usr/hdp/current/hive_warehouse_connector/pyspark_hwc-<VERSION>.zip
Kurumsal Güvenlik Paketi (ESP) kümelerinde sorgu çalıştırma
spark-shell'i veya spark-submit'i başlatmadan önce kullanın kinit . USERNAME değerini, kümeye erişim izinleri olan bir etki alanı hesabının adıyla değiştirin ve aşağıdaki komutu yürütür:
kinit USERNAME
Spark ESP kümelerindeki verilerin güvenliğini sağlama
Aşağıdaki komutları girerek bazı örnek verilerle bir tablo
demooluşturun:create table demo (name string); INSERT INTO demo VALUES ('HDinsight'); INSERT INTO demo VALUES ('Microsoft'); INSERT INTO demo VALUES ('InteractiveQuery');Aşağıdaki komutla tablonun içeriğini görüntüleyin. İlkeyi
demouygulamadan önce tabloda sütunun tamamı gösterilir.hive.executeQuery("SELECT * FROM demo").show()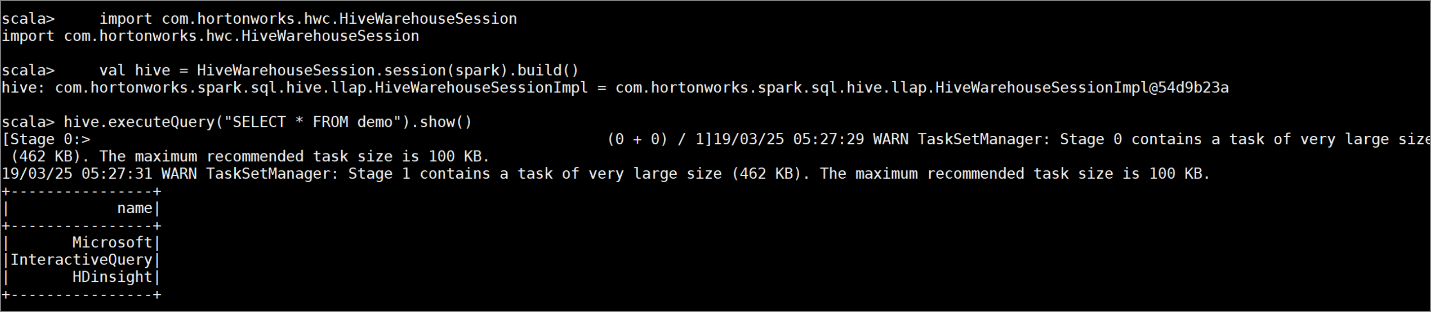
Sütunun yalnızca son dört karakterini gösteren bir sütun maskeleme ilkesi uygulayın.
konumunda ranger yönetici kullanıcı arabirimine
https://LLAPCLUSTERNAME.azurehdinsight.net/ranger/gidin.Hive altında kümenizin Hive hizmetine tıklayın.
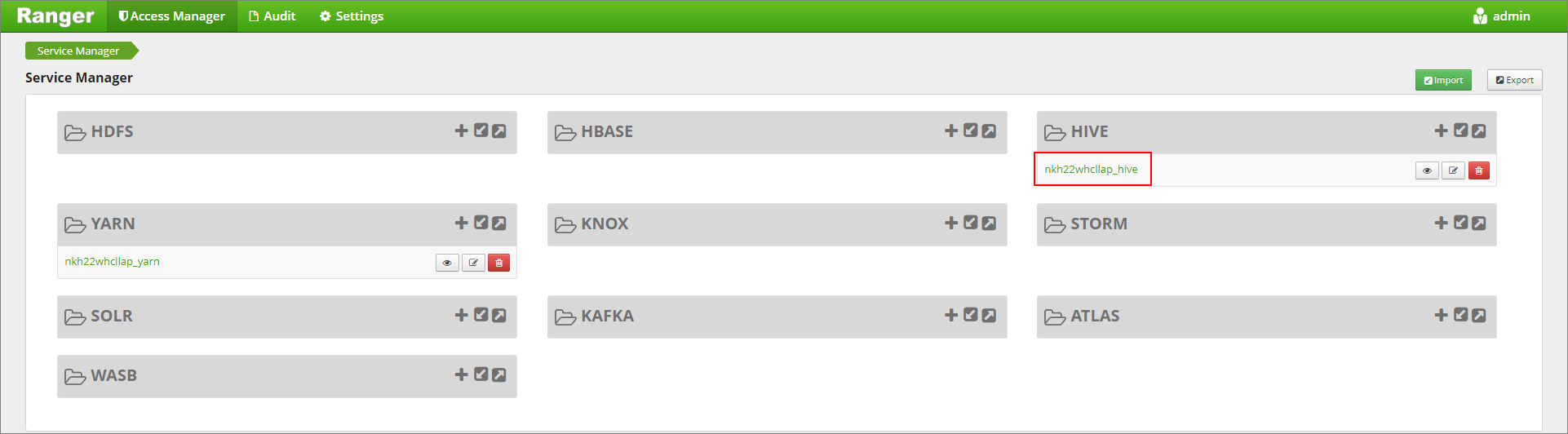
Maskeleme sekmesine ve ardından Yeni İlke Ekle'ye tıklayın
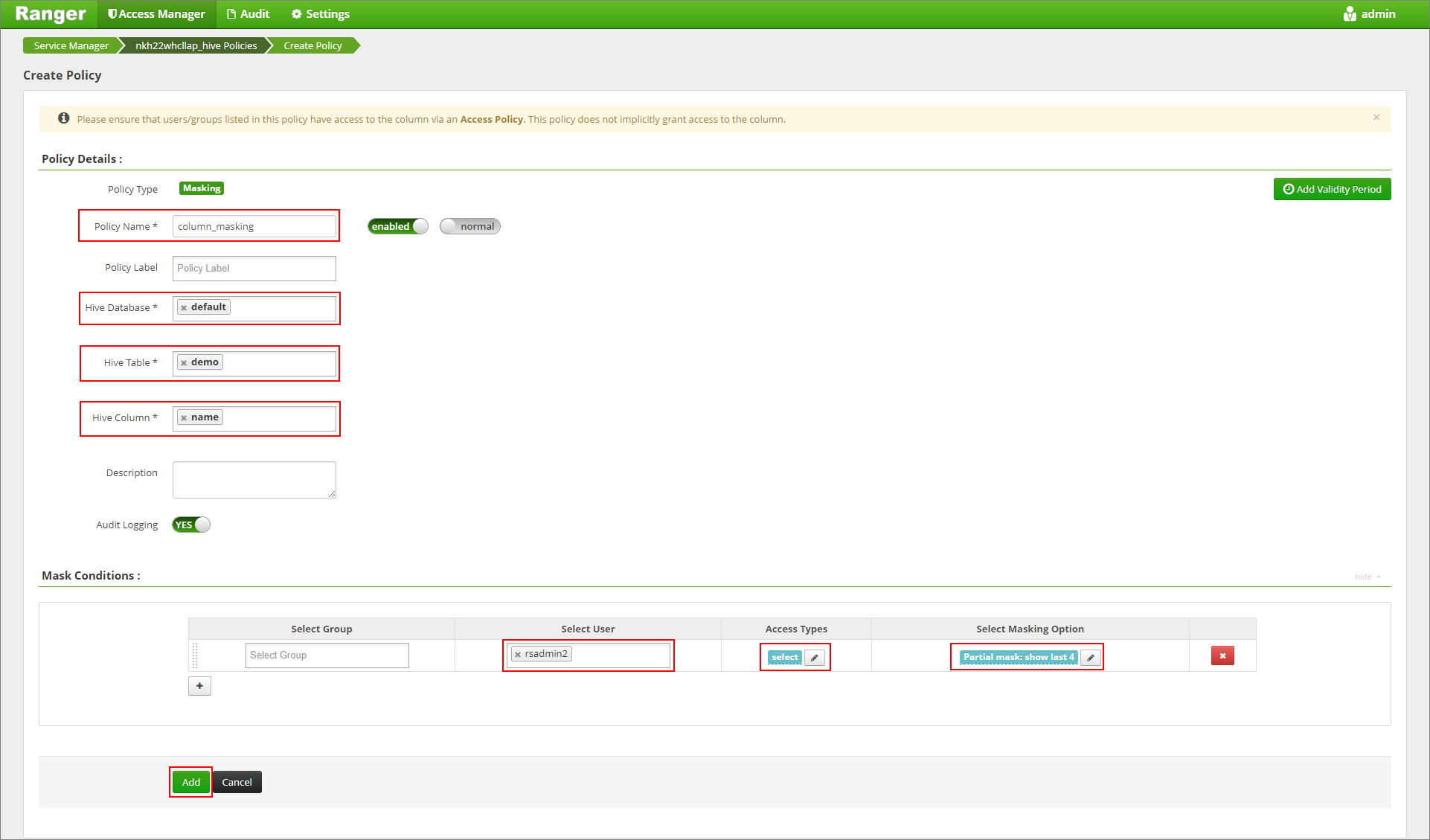
İstenen ilke adını belirtin. Veritabanı seçin: Varsayılan, Hive tablosu: demo, Hive sütunu: name, User: rsadmin2, Access Types: select ve Partial mask: show last 4 from The Masking Option menu. Ekle'yi tıklatın.
Tablonun içeriğini yeniden görüntüleyin. Ranger ilkesini uyguladıktan sonra sütunun yalnızca son dört karakterini görebiliriz.
