Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu makalede, HDInsight kümelerinde çalışan Apache Spark işlerini izlemeyi ve hatalarını ayıklamayı öğreneceksiniz. Apache Hadoop YARN kullanıcı arabirimini, Spark kullanıcı arabirimini ve Spark Geçmiş Sunucusu'nu kullanarak hata ayıklama. Makine öğrenmesi: MLLib kullanarak gıda denetleme verileri üzerinde tahmine dayalı analiz adlı Spark kümesiyle kullanılabilen bir not defteri kullanarak bir Spark işi başlatırsınız. Spark-submit gibi başka bir yaklaşım kullanarak gönderdiğiniz bir uygulamayı izlemek için aşağıdaki adımları kullanın.
Azure aboneliğiniz yoksa başlamadan önce ücretsiz bir hesap oluşturun.
Önkoşullar
HDInsight üzerinde bir Apache Spark kümesi. Yönergeler için bkz. Azure HDInsight'ta Apache Spark kümeleri oluşturma.
Makine öğrenmesi: MLLib kullanarak gıda denetleme verileri üzerinde tahmine dayalı analiz not defterini çalıştırmaya başlamış olmanız gerekir. Bu not defterini çalıştırma yönergeleri için bağlantıyı izleyin.
YARN kullanıcı arabiriminde bir uygulamayı izleme
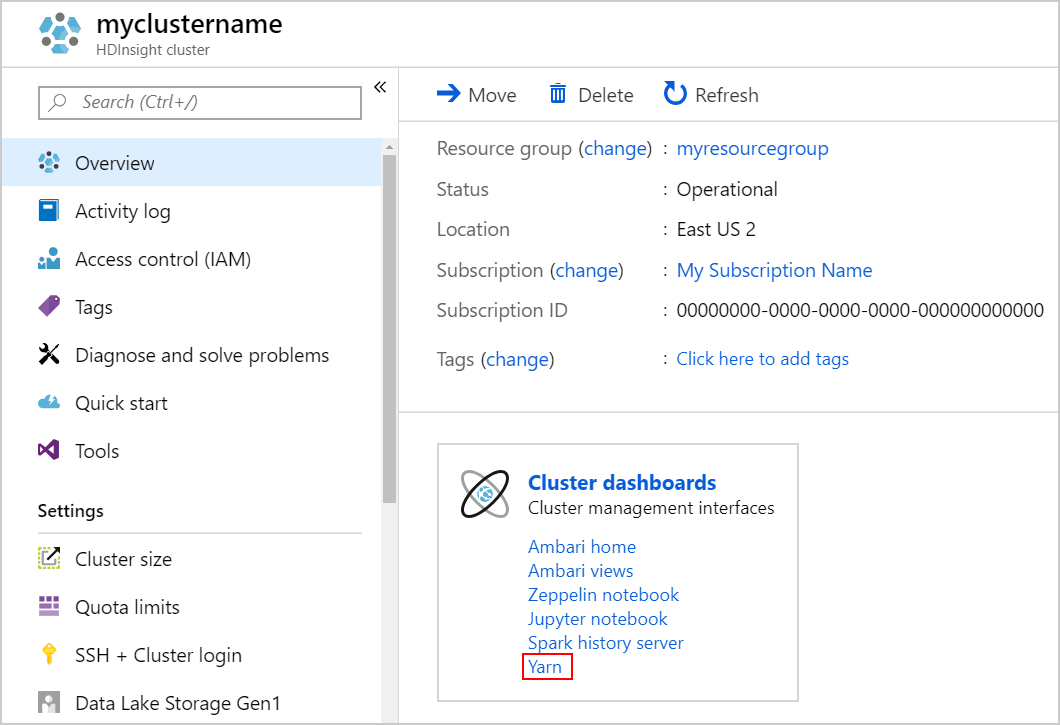
YARN kullanıcı arabirimini başlatın. Küme panoları altında Yarn'ı seçin.
Tavsiye
Alternatif olarak, Yarn kullanıcı arabirimini Ambari kullanıcı arabiriminden de başlatabilirsiniz. Ambari kullanıcı arabirimini başlatmak için Küme panoları altında Ambari giriş'i seçin. Ambari kullanıcı arabiriminden, YARN>Hızlı Bağlantılar> bölümünde etkin Resource Manager >Resource Manager kullanıcı arabirimi'ne gidin.
Spark işini Jupyter Notebooks kullanarak başlattığınız için, uygulama remotesparkmagics (not defterlerinden başlatılan tüm uygulamaların adı) adına sahiptir. İş hakkında daha fazla bilgi edinmek için uygulama adına karşılık gelen uygulama kimliğini seçin. Bu eylem uygulama görünümünü başlatır.
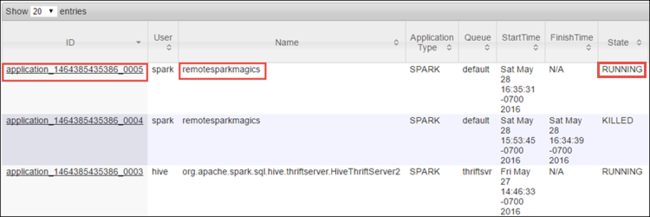
Jupyter Not Defterlerinden başlatılan bu tür uygulamalar için, siz not defterinden çıkana kadar durum her zaman ÇALıŞıR DURUMDA olur .
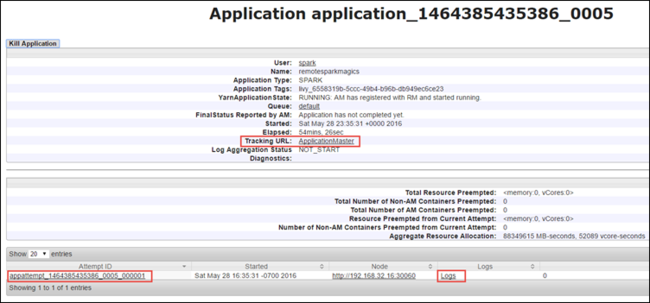
Uygulama görünümünden, uygulamayla ilişkili kapsayıcıları ve günlükleri (stdout/stderr) bulmak için detaya gidebilirsiniz. Aşağıda gösterildiği gibi İzleme URL'sine karşılık gelen bağlamaya tıklayarak da Spark kullanıcı arabirimini başlatabilirsiniz.
Spark kullanıcı arabiriminde bir uygulamayı izleme
Spark kullanıcı arabiriminde, daha önce başlattığınız uygulama tarafından oluşturulan Spark işlerinde detaya gidebilirsiniz.
Spark kullanıcı arabirimini başlatmak için, yukarıdaki ekran görüntüsünde gösterildiği gibi uygulama görünümünden İzleme URL'sinin yanındaki bağlantıyı seçin. Jupyter Notebook'ta çalıştırılan uygulama tarafından başlatılan tüm Spark işlerini görebilirsiniz.
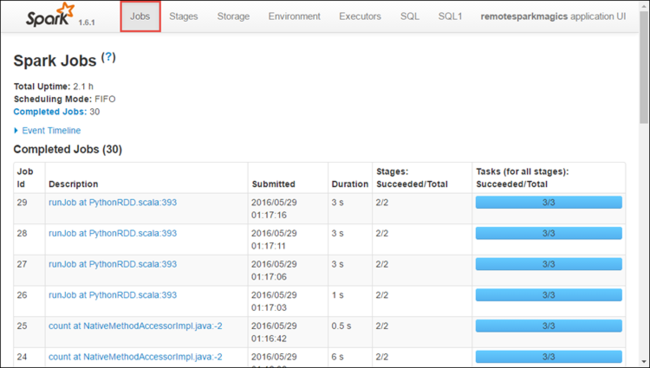
Her yürütücü için işleme ve depolama bilgilerini görmek için Yürütücüler sekmesini seçin. İş Parçacığı Dökümü bağlantısını seçerek de çağrı dizisine erişebilirsiniz.
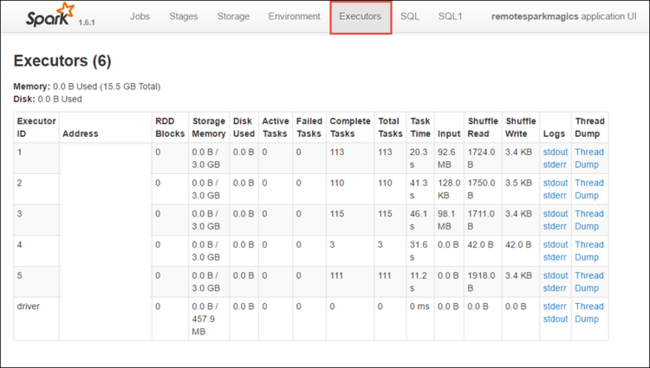
Uygulamayla ilişkili aşamaları görmek için Aşamalar sekmesini seçin.
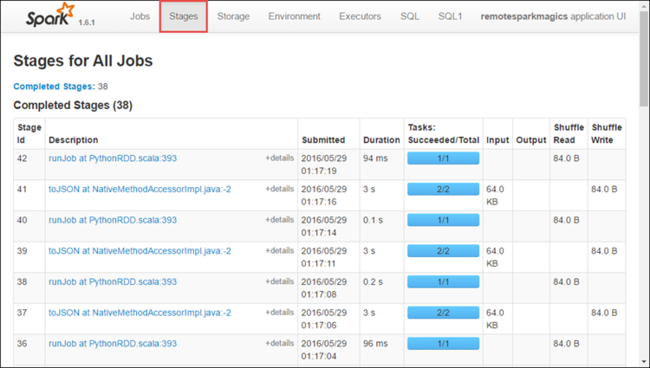
Her aşamada, aşağıda gösterildiği gibi yürütme istatistiklerini görüntüleyebileceğiniz birden çok görev olabilir.
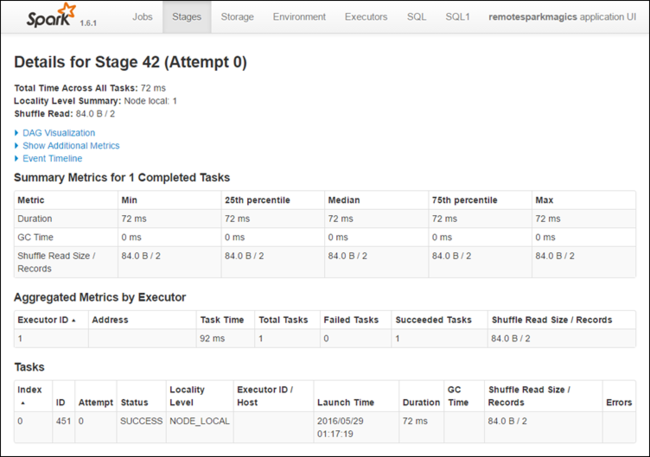
Aşama ayrıntıları sayfasından DAG Görselleştirme'yi başlatabilirsiniz. Sayfanın üst kısmındaki DAG Görselleştirme bağlantısını aşağıda gösterildiği gibi genişletin.
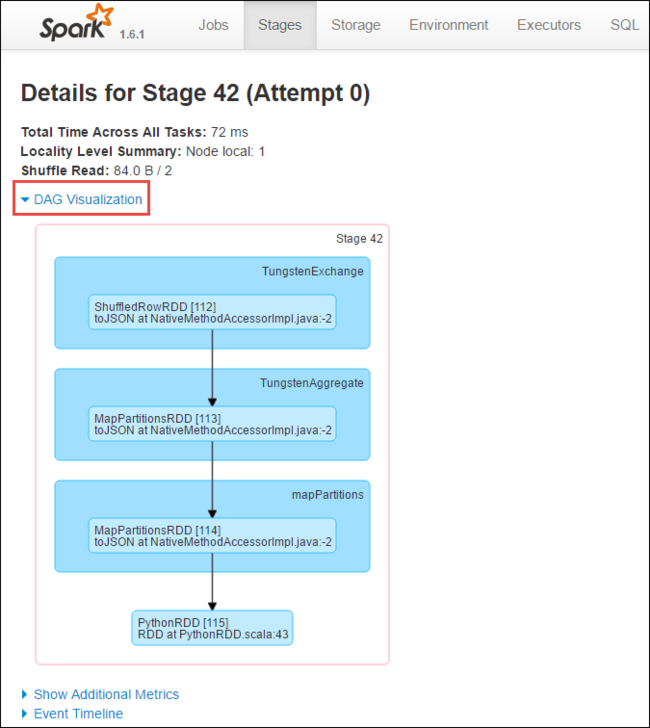
DAG veya Doğrudan Aclyic Graph, uygulamadaki farklı aşamaları temsil eder. Grafikteki her mavi kutu, uygulamadan çağrılan bir Spark işlemini temsil eder.
Aşama ayrıntıları sayfasından uygulama zaman çizelgesi görünümünü de başlatabilirsiniz. Aşağıda gösterildiği gibi sayfanın üst kısmındaki Olay Zaman Çizelgesi bağlantısını genişletin.
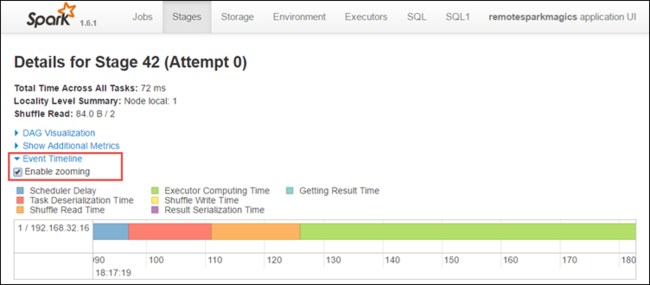
Bu görüntüde Spark olayları zaman çizelgesi biçiminde görüntülenir. Zaman çizelgesi görünümü üç düzeyde, işler arasında, bir işin içinde ve bir aşamada kullanılabilir. Yukarıdaki görüntü, belirli bir aşama için zaman çizelgesi görünümünü yakalar.
Tavsiye
Yakınlaştırmayı etkinleştir onay kutusunu seçerseniz zaman çizelgesi görünümünde sola ve sağa kaydırabilirsiniz.
Spark kullanıcı arabirimindeki diğer sekmeler, Spark örneği hakkında da yararlı bilgiler sağlar.
- Depolama sekmesi - Uygulamanız bir RDD oluşturuyorsa, depolama sekmesindeki bilgileri bulabilirsiniz.
- Ortam sekmesi - Bu sekme Spark örneğiniz hakkında aşağıdakiler gibi yararlı bilgiler sağlar:
- Scala sürümü
- Kümeyle ilişkilendirilmiş olay günlüğü dizini
- Uygulama için yürütücü çekirdeği sayısı
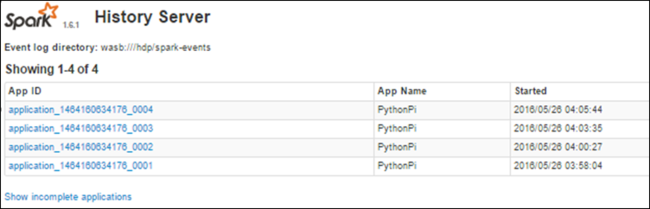
Spark Geçmiş Sunucusu'nu kullanarak tamamlanmış işler hakkında bilgi bulma
bir iş tamamlandıktan sonra, iş hakkındaki bilgiler Spark Geçmiş Sunucusu'nda kalıcı hale gönderilir.
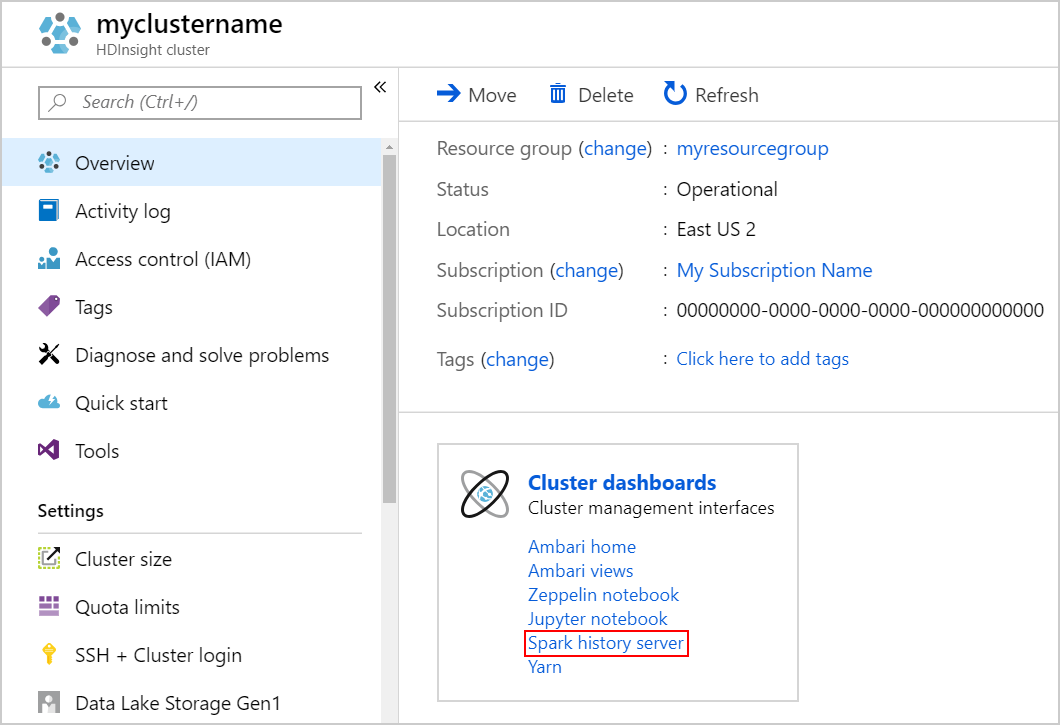
Spark Geçmiş Sunucusu'nu başlatmak için Genel Bakış sayfasında Küme panoları altında Spark geçmiş sunucusu'nu seçin.
Tavsiye
Alternatif olarak, Spark Geçmiş Sunucusu kullanıcı arabirimini Ambari kullanıcı arabiriminden de başlatabilirsiniz. Ambari kullanıcı arabirimini başlatmak için Genel Bakış panelinde Küme panoları altında Ambari ana sayfayı seçin. Ambari kullanıcı arabiriminden Spark2Hızlı Bağlantılar>Spark2>Geçmiş Sunucusu kullanıcı arabirimine gidin.
Tamamlanmış uygulamaların tümünün listelendiğini görürsünüz. Daha fazla bilgi için uygulamada detaya gitmek için bir uygulama kimliği seçin.