Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu makalede, Azure HDInsight'ta en iyi performans için Apache Spark kümenizin bellek yönetimini iyileştirme adımları anlatılmaktadır.
Genel Bakış
Spark, verileri belleğe yerleştirerek çalışır. Bu nedenle bellek kaynaklarını yönetmek, Spark işlerinin yürütülmesini iyileştirmenin önemli bir yönüdür. Kümenizin belleğini verimli bir şekilde kullanmak için uygulayabileceğiniz çeşitli teknikler vardır.
- Daha küçük veri bölümlerini tercih edin ve bölümleme stratejinizde veri boyutu, türleri ve dağıtımı için hesap oluşturun.
- Varsayılan Java serileştirmesi yerine daha yeni, daha verimli
Kryo data serializationdüşünün. -
spark-submit'ı gruplar halinde ayırdığı için YARN kullanmayı tercih edin. - Spark yapılandırma ayarlarını izleyin ve ayarlayın.
Başvurunuz için Spark bellek yapısı ve bazı anahtar yürütücü bellek parametreleri sonraki görüntüde gösterilir.
Spark bellekle ilgili dikkat edilmesi gerekenler
Apache Hadoop YARN kullanıyorsanız YARN, her Spark düğümündeki tüm kapsayıcılar tarafından kullanılan belleği denetler. Aşağıdaki diyagramda anahtar nesneler ve bunların ilişkileri gösterilmektedir.
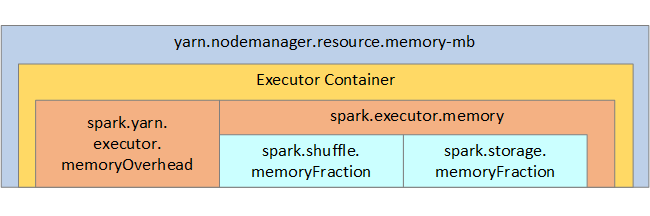
'Bellek yetersiz' iletilerini ele almak için şunları deneyin:
- DAG Yönetim Değişikliklerini gözden geçirin. Harita tarafındaki azaltma ile, kaynak verileri önceden bölümleyerek (veya demetleyerek), tek bir karıştırmayı en üst düzeye çıkararak ve gönderilen veri miktarını azaltarak.
-
ReduceByKey'ı, toplamalar, pencereleme ve diğer işlevleri sağlayan ancak sınırsız bellek sınırına sahip olanGroupByKey'e tercih edin, çünküReduceByKeysabit bellek sınırına sahiptir. - Tercih edin
TreeReduce, bu daha fazla işlem yürütücüler veya bölümler üzerinde yapar,Reduceyerine, bu tüm işlemi sürücü üzerinde yapar. - Alt düzey RDD nesneleri yerine DataFrames kullanın.
- "İlk N", çeşitli toplamalar veya pencereleme işlemleri gibi eylemleri kapsülleyen ComplexType'lar oluşturun.
Ek sorun giderme adımları hakkında bilgi için Azure HDInsight'ta Apache Spark için OutOfMemoryError özel durumlarınabakın.
Sonraki adımlar
- Apache Spark için veri işlemeyi iyileştirme
- Apache Spark için veri depolamayı iyileştirme
- Apache Spark için küme yapılandırmasını iyileştirme