Azure Databricks kullanarak Cassandra'dan Apache Cassandra için Azure Cosmos DB hesabına veri geçirme
ŞUNLAR IÇIN GEÇERLIDIR: ![]() Cassandra
Cassandra
Azure Cosmos DB'de Cassandra api'si, Apache Cassandra üzerinde çalışan kurumsal iş yükleri için çeşitli nedenlerle harika bir seçim haline gelmiştir:
Yönetim ve izleme yükü yoktur: İşletim sistemi, JVM ve YAML dosyaları ve bunların etkileşimleri arasında ayarları yönetme ve izleme yükünü ortadan kaldırır.
Önemli maliyet tasarrufu: VM'lerin maliyetini, bant genişliğini ve geçerli lisansları içeren Azure Cosmos DB ile maliyet tasarrufu yapabilirsiniz. Veri merkezlerini, sunucuları, SSD depolamayı, ağı ve elektrik maliyetlerini yönetmeniz gerekmez.
Mevcut kodu ve araçları kullanma olanağı: Azure Cosmos DB, mevcut Cassandra SDK'ları ve araçlarıyla kablo protokolü düzeyinde uyumluluk sağlar. Bu uyumluluk, apache Cassandra için Azure Cosmos DB ile mevcut kod tabanınızı önemsiz değişikliklerle kullanabilmenizi sağlar.
Veritabanı iş yüklerini bir platformdan diğerine geçirmenin birçok yolu vardır. Azure Databricks, Apache Spark için büyük ölçekte çevrimdışı geçişler gerçekleştirmenin bir yolunu sunan bir hizmet olarak platform (PaaS) teklifidir. Bu makalede, Azure Databricks kullanarak yerel Apache Cassandra anahtar boşluklarından ve tablolarından Apache Cassandra için Azure Cosmos DB'ye veri geçirmek için gereken adımlar açıklanmaktadır.
Önkoşullar
Apache Cassandra için Azure Cosmos DB'ye bağlanmanın temellerini gözden geçirin.
Uyumluluğu sağlamak için Apache Cassandra için Azure Cosmos DB'de desteklenen özellikleri gözden geçirin.
Apache Cassandra için hedef Azure Cosmos DB hesabınızda boş anahtar alanları ve tablolar oluşturduğunuzdan emin olun.
Doğrulama için cqlsh kullanın.
Azure Databricks kümesi sağlama
Azure Databricks kümesi sağlamak için yönergeleri izleyebilirsiniz. Spark 3.0'ı destekleyen Databricks çalışma zamanı sürüm 7.5'i seçmenizi öneririz.
Bağımlılık ekleme
Hem yerel hem de Azure Cosmos DB Cassandra uç noktalarına bağlanmak için kümenize Apache Spark Cassandra Bağlayıcı kitaplığını eklemeniz gerekir. Kümenizde Kitaplıklar>Yeni>Maven Yükle'yi seçin ve ardından Maven koordinatlarını ekleyin.com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0
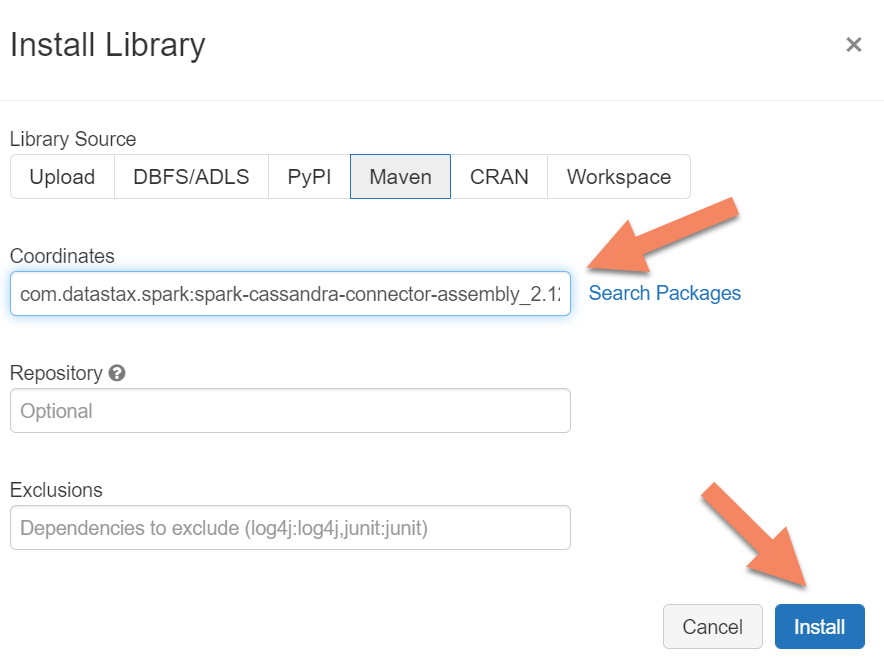
Yükle'yi seçin ve yükleme tamamlandığında kümeyi yeniden başlatın.
Not
Cassandra Bağlayıcı kitaplığı yüklendikten sonra Databricks kümesini yeniden başlattığınızdan emin olun.
Uyarı
Bu makalede gösterilen örnekler Spark sürüm 3.0.1 ve buna karşılık gelen Cassandra Spark Bağlayıcısı com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0 ile test edilmiştir. Spark ve/veya Cassandra bağlayıcısının sonraki sürümleri beklendiği gibi çalışmayabilir.
Geçiş için Scala Not Defteri oluşturma
Databricks'te Scala Not Defteri oluşturun. Kaynak ve hedef Cassandra yapılandırmalarınızı ilgili kimlik bilgileriyle, kaynak ve hedef anahtar alanlarıyla tablolarla değiştirin. Ardından aşağıdaki kodu çalıştırın:
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql._
import org.apache.spark.SparkContext
// source cassandra configs
val nativeCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "false",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>"
)
//target cassandra configs
val cosmosCassandra = Map(
"spark.cassandra.connection.host" -> "<USERNAME>.cassandra.cosmos.azure.com",
"spark.cassandra.connection.port" -> "10350",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>",
//throughput related settings below - tweak these depending on data volumes.
"spark.cassandra.output.batch.size.rows"-> "1",
"spark.cassandra.output.concurrent.writes" -> "1000",
//"spark.cassandra.connection.remoteConnectionsPerExecutor" -> "1", // Spark 3.x
"spark.cassandra.connection.connections_per_executor_max"-> "1", // Spark 2.x
"spark.cassandra.concurrent.reads" -> "512",
"spark.cassandra.output.batch.grouping.buffer.size" -> "1000",
"spark.cassandra.connection.keep_alive_ms" -> "600000000"
)
//Read from native Cassandra
val DFfromNativeCassandra = sqlContext
.read
.format("org.apache.spark.sql.cassandra")
.options(nativeCassandra)
.load
//Write to CosmosCassandra
DFfromNativeCassandra
.write
.format("org.apache.spark.sql.cassandra")
.options(cosmosCassandra)
.mode(SaveMode.Append) // only required for Spark 3.x
.save
Not
spark.cassandra.output.batch.size.rows Spark kümenizdeki ve spark.cassandra.output.concurrent.writes değerleri ve çalışan sayısı, hız sınırlamasını önlemek için ayarlanması gereken önemli yapılandırmalardır. Hız sınırlama, Azure Cosmos DB'ye yapılan istekler sağlanan aktarım hızını veya istek birimlerini (RU) aştığında gerçekleşir. Spark kümesindeki yürütücü sayısına ve hedef tablolara yazılan her kaydın boyutuna (ve dolayısıyla RU maliyetine) bağlı olarak bu ayarları değiştirmeniz gerekebilir.
Sorun giderme
Hız sınırlama (429 hatası)
Ayarları en düşük değerlerine indirgeseniz bile 429 hata kodu veya "istek oranı büyük" hata metni görebilirsiniz. Aşağıdaki senaryolar hız sınırlamasına neden olabilir:
Tabloya ayrılan aktarım hızı 6.000'den az istek birimidir. Spark, en düşük ayarlarda bile yaklaşık 6.000 istek birimi veya daha fazla hızda yazabilir. Paylaşılan aktarım hızına sahip bir anahtar alanında tablo sağladıysanız, bu tablonun çalışma zamanında kullanılabilir 6.000'den az RU'ya sahip olması mümkündür.
Geçiş yaptığınız tabloda, geçişi çalıştırdığınızda en az 6.000 RU olduğundan emin olun. Gerekirse, bu tabloya ayrılmış istek birimleri ayırın.
Büyük veri hacmine sahip aşırı veri dengesizliği. Belirli bir tabloya geçirilmesi gereken büyük miktarda veriniz varsa ancak verilerde önemli bir dengesizlik varsa (yani, aynı bölüm anahtarı değeri için çok sayıda kayıt yazılıyorsa), tablonuzda sağlanan birkaç istek birimi olsa bile hız sınırlaması yaşayabilirsiniz. İstek birimleri fiziksel bölümler arasında eşit olarak bölünür ve ağır veri dengesizliği tek bir bölüme yönelik isteklerde performans sorununa neden olabilir.
Bu senaryoda Spark'ta en düşük aktarım hızı ayarlarına düşürün ve geçişi yavaş çalışmaya zorlar. Bu senaryo, başvuru veya denetim tablolarını geçirirken daha yaygın olabilir; burada erişim daha az sıktır ve dengesizlik yüksek olabilir. Ancak, başka bir tablo türünde önemli bir dengesizlik varsa, sabit durum işlemleri sırasında iş yükünüz için sık erişimli bölümleme sorunlarını önlemek için veri modelinizi gözden geçirmek isteyebilirsiniz.
Sonraki adımlar
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin