Azure HDInsight ile küme performansını izleyin
HdInsight kümesinin sistem durumunu ve performansını izlemek, en iyi performansı ve kaynak kullanımını korumak için gereklidir. İzleme, küme yapılandırma hatalarını ve kullanıcı kodu sorunlarını algılamanıza ve gidermenize de yardımcı olabilir.
Aşağıdaki bölümlerde kümelerinizdeki yükü izleme ve iyileştirme, Apache Hadoop YARN kuyrukları ve depolama azaltma sorunlarını algılama açıklanmaktadır.
Küme yükünü izleme
Hadoop kümeleri, küme üzerindeki yük tüm düğümler arasında eşit olarak dağıtıldığında en uygun performansı sunabilir. Bu, işleme görevlerinin tek düğümlerde RAM, CPU veya disk kaynakları tarafından kısıtlanmadan çalışmasını sağlar.
Kümenizin düğümlerine ve yüklemelerine üst düzey bir bakış elde etmek için Ambari Web kullanıcı arabiriminde oturum açın ve Konaklar sekmesini seçin. Konaklarınız, tam etki alanı adlarına göre listelenir. Her konağın çalışma durumu renkli bir sistem durumu göstergesiyle gösterilir:
| Color | Açıklama |
|---|---|
| Kırmızı | Konakta en az bir ana bileşen çalışmıyor. Etkilenen bileşenleri listeleyen bir araç ipucu görmek için üzerine gelin. |
| Orange | Konakta en az bir ikincil bileşen çalışmıyor. Etkilenen bileşenleri listeleyen bir araç ipucu görmek için üzerine gelin. |
| Sarı | Ambari Server 3 dakikadan uzun süredir konaktan sinyal almadı. |
| Yeşil | Normal çalışma durumu. |
Ayrıca her konak için çekirdek sayısını ve RAM miktarını, disk kullanımını ve yük ortalamasını gösteren sütunlar görürsünüz.
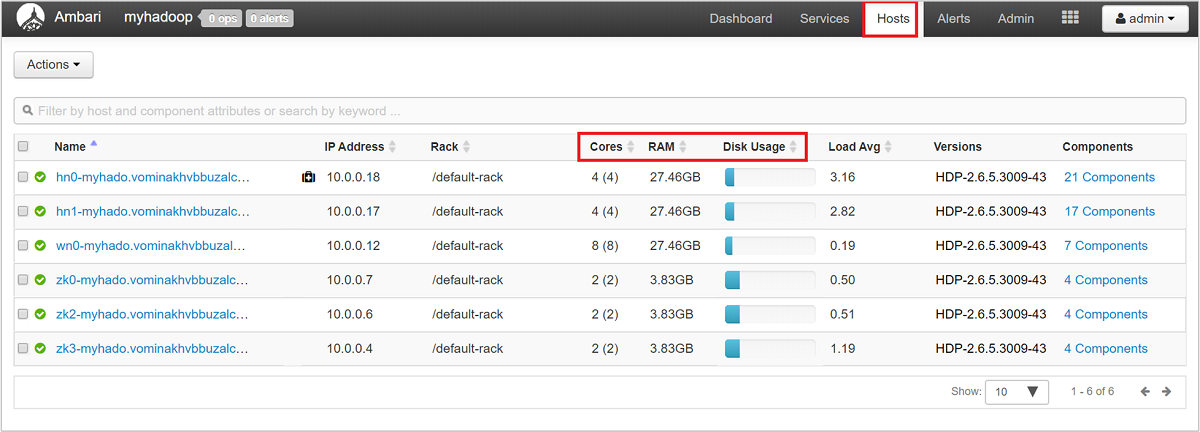
Bu konakta çalışan bileşenlere ve bunların ölçümlerine ayrıntılı bir bakış için konak adlarından herhangi birini seçin. Ölçümler CPU kullanımı, yük, disk kullanımı, bellek kullanımı, ağ kullanımı ve işlem sayılarının seçilebilir bir zaman çizelgesi olarak gösterilir.
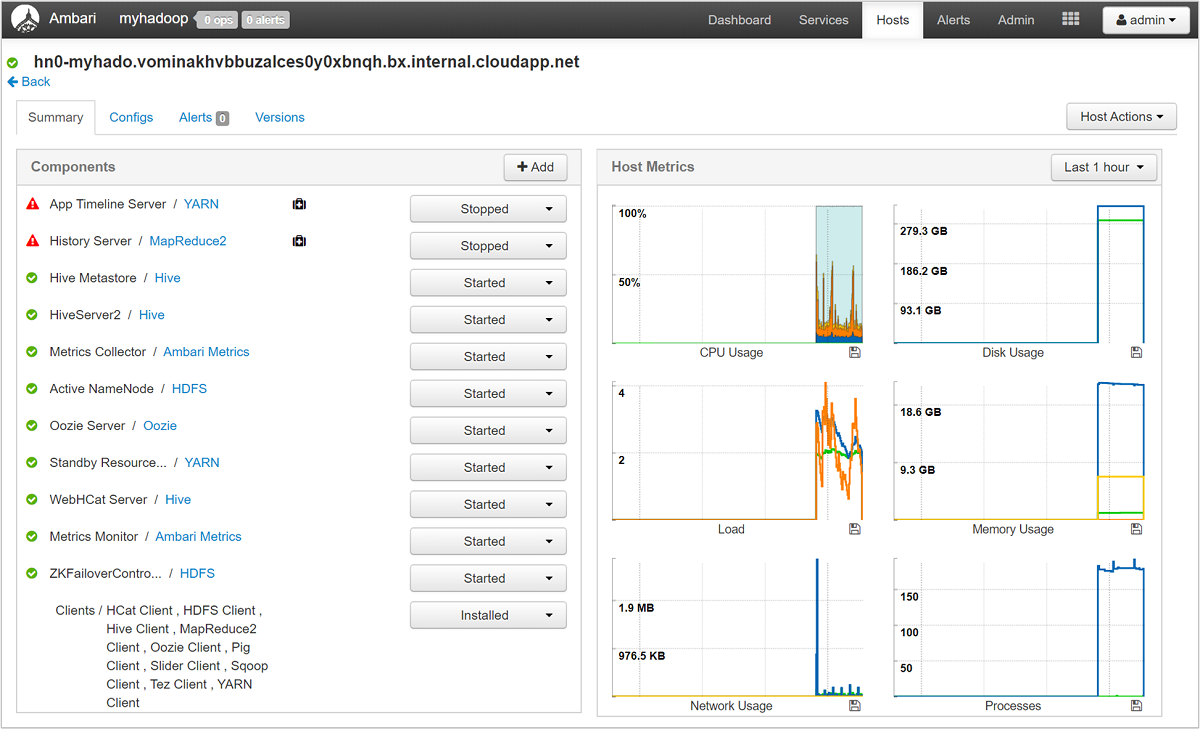
Uyarıları ayarlama ve ölçümleri görüntüleme hakkında ayrıntılı bilgi için bkz . Apache Ambari Web kullanıcı arabirimini kullanarak HDInsight kümelerini yönetme.
YARN kuyruğu yapılandırması
Hadoop'un dağıtılmış platformunda çalışan çeşitli hizmetleri vardır. YARN (Ancak Başka Bir Kaynak Anlaşmacisi) bu hizmetleri koordine eder ve tüm yüklerin kümeye eşit bir şekilde dağıtılmasını sağlamak için küme kaynaklarını ayırır.
YARN, JobTracker'ın kaynak yönetimi ve iş zamanlama/izleme olmak üzere iki sorumluluğunu iki daemon'a ayırır: genel Resource Manager ve uygulama başına ApplicationMaster (AM).
Resource Manager saf bir zamanlayıcıdır ve yalnızca tüm rakip uygulamalar arasındaki kullanılabilir kaynakları rastgele kullanır. Resource Manager, tüm kaynakların her zaman kullanımda olmasını sağlayarak SLA'lar, kapasite garantileri vb. gibi çeşitli sabitler için iyileştirme sağlar. ApplicationMaster, Resource Manager'dan kaynak anlaşması yapıp NodeManager(lar) ile birlikte çalışarak kapsayıcıları ve bunların kaynak tüketimini yürütür ve izler.
Birden çok kiracı büyük bir kümeyi paylaştığında, kümenin kaynakları için rekabet olur. CapacityScheduler, istekleri kuyruğa alarak kaynak paylaşımına yardımcı olan eklenebilir bir zamanlayıcıdır. CapacityScheduler, diğer uygulamaların kuyruklarının ücretsiz kaynakları kullanmasına izin verilmeden önce kaynakların bir kuruluşun alt sıraları arasında paylaşılmasını sağlamak için hiyerarşik kuyrukları da destekler.
YARN bu kuyruklara kaynak ayırmamıza olanak tanır ve tüm kullanılabilir kaynaklarınızın atanıp atanmadığını gösterir. Kuyruklarınızla ilgili bilgileri görüntülemek için Ambari Web Kullanıcı Arabirimi'nde oturum açın ve üstteki menüden YARN Kuyruk Yöneticisi'ni seçin.
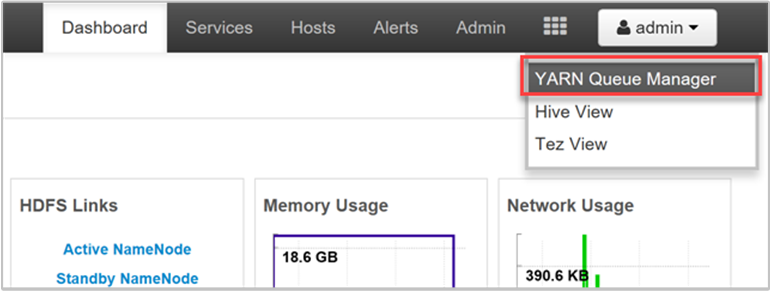
YARN Kuyruk Yöneticisi sayfasında, soldaki kuyruklarınızın listesi ve her birine atanan kapasite yüzdesi gösterilir.
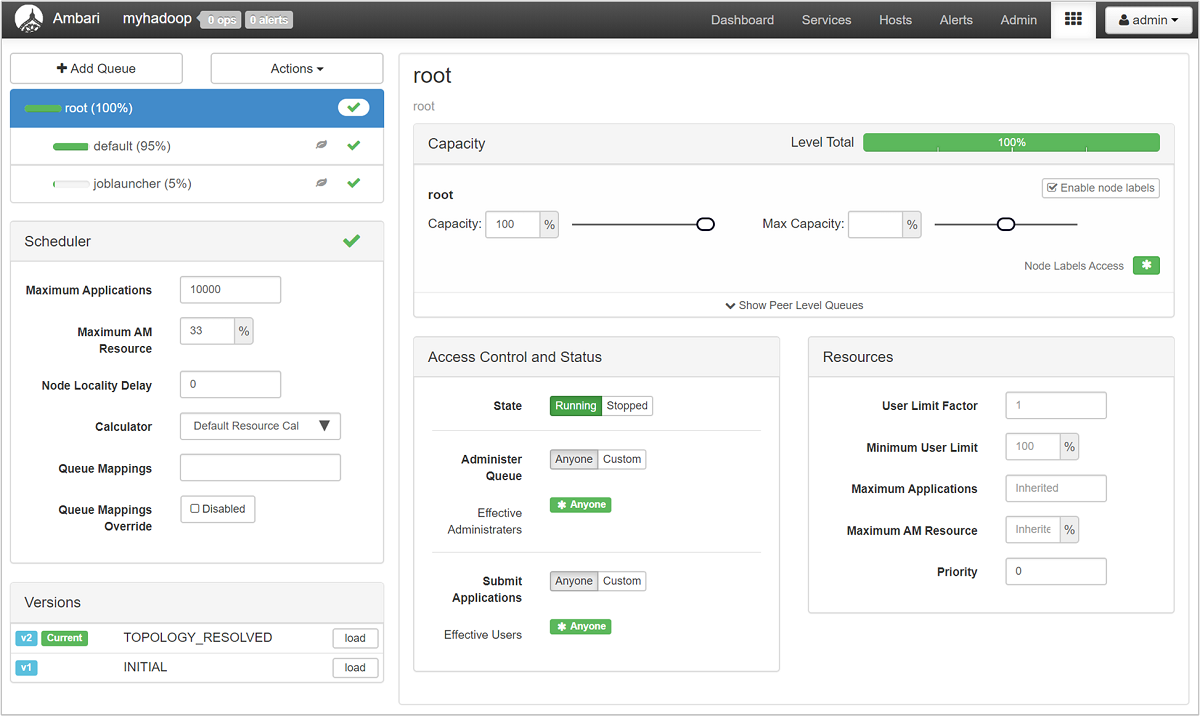
Kuyruklarınıza daha ayrıntılı bir bakış için Ambari panosundan soldaki listeden YARN hizmetini seçin. Ardından Hızlı Bağlantılar açılan menüsünün altında etkin düğümünüzün altındaki Resource Manager kullanıcı arabirimi'ni seçin.
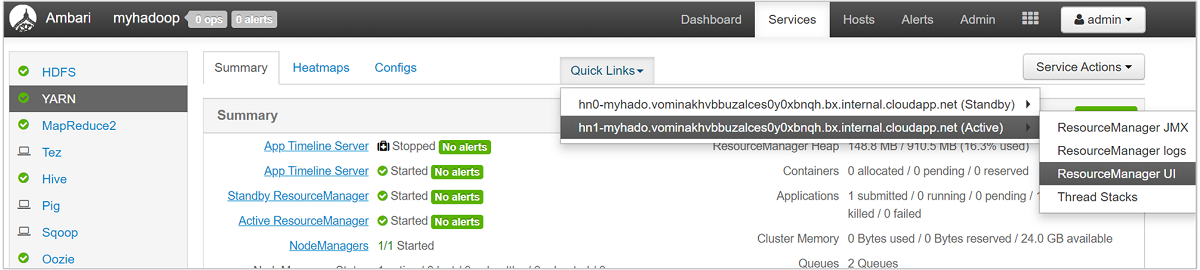
Resource Manager kullanıcı arabiriminde sol taraftaki menüden Zamanlayıcı'yı seçin. Uygulama Kuyrukları altında kuyruklarınızın listesini görürsünüz. Burada kuyruklarınızın her biri için kullanılan kapasiteyi, işlerin aralarında ne kadar iyi dağıtıldığını ve herhangi bir işin kaynak kısıtlaması olup olmadığını görebilirsiniz.
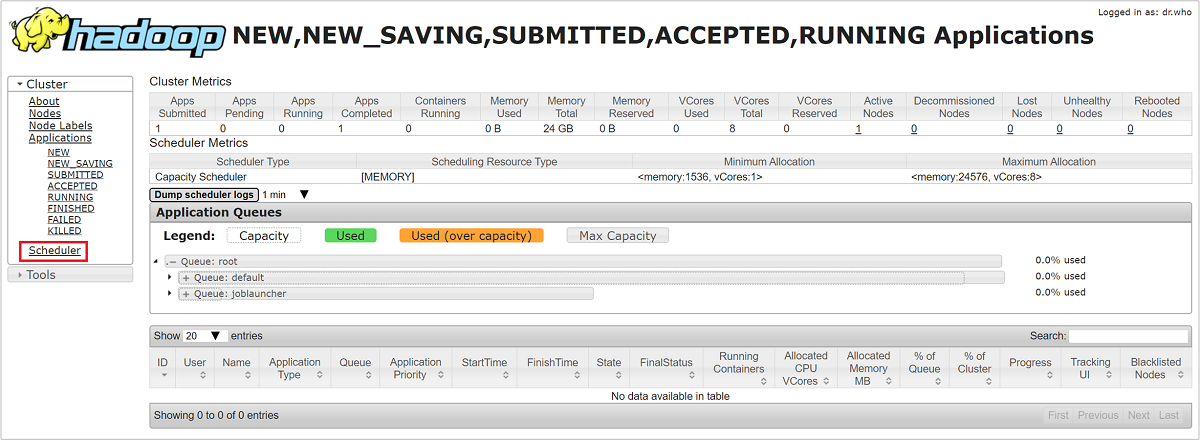
Depolama alanı azaltma
Bir kümenin performans sorunu depolama düzeyinde gerçekleşebilir. Bu tür bir performans sorunu genellikle çalışan görevleriniz depolama hizmetinin işleyebileceğinden daha fazla GÇ gönderdiğinde gerçekleşen giriş/çıkış (GÇ) işlemlerinin engellenmesinden kaynaklanır. Bu engelleme, geçerli GÇ'ler işleninceye kadar işlenmeyi bekleyen GÇ istekleri kuyruğu oluşturur. Bloklar, fiziksel bir sınır değil, bir hizmet düzeyi sözleşmesi (SLA) tarafından depolama hizmeti tarafından uygulanan bir sınır olan depolama alanı azaltmadan kaynaklanmıştır. Bu sınır, tek bir istemcinin veya kiracının hizmeti tekeline almamasını sağlar. SLA, Azure Depolama için saniye başına G/Ç (IOPS) sayısını sınırlar. Ayrıntılar için bkz. Standart depolama hesapları için ölçeklenebilirlik ve performans hedefleri.
Azure Depolama kullanıyorsanız, azaltma da dahil olmak üzere depolamayla ilgili sorunları izleme hakkında bilgi için bkz. Microsoft Azure Depolama izleme, tanılama ve sorun giderme.
Kümenizin yedekleme deposu Azure Data Lake Depolama (ADLS) ise büyük olasılıkla bant genişliği sınırları nedeniyle azaltmanız mümkündür. Bu durumda azaltma, görev günlüklerindeki azaltma hataları gözlemlenerek belirlenebilir. ADLS için, şu makalelerde uygun hizmetin azaltma bölümüne bakın:
- HDInsight ve Azure Data Lake Depolama üzerinde Apache Hive için performans ayarlama kılavuzu
- HDInsight'ta MapReduce ve Azure Data Lake Depolama için performans ayarlama kılavuzu
Yavaş düğüm performansı sorunlarını giderme
Bazı durumlarda, kümede yetersiz disk alanı olması yavaş performansa neden olabilir. Şu adımlarla araştırın:
Düğümlerin her birine bağlanmak için ssh komutunu kullanın.
Aşağıdaki komutlardan birini çalıştırarak disk kullanımını denetleyin:
df -h du -h --max-depth=1 / | sort -hÇıktıyı gözden geçirin ve klasördeki veya diğer klasörlerdeki
mntbüyük dosyaların olup olmadığını denetleyin. Genellikle,usercacheveappcache(mnt/resource/hadoop/yarn/local/usercache/hive/appcache/) klasörleri büyük dosyalar içerir.Büyük dosyalar varsa, dosya büyümesine geçerli bir iş neden oluyor veya önceki bir işin başarısız olması bu soruna katkıda bulunmuş olabilir. Bu davranışa geçerli bir işin neden olup olmadığını denetlemek için şu komutu çalıştırın:
sudo du -h --max-depth=1 /mnt/resource/hadoop/yarn/local/usercache/hive/appcache/Bu komut belirli bir işi gösteriyorsa, şuna benzer bir komut kullanarak işi sonlandırmayı tercih edebilirsiniz:
yarn application -kill -applicationId <application_id>değerini uygulama kimliğiyle değiştirin
application_id. Belirli bir iş gösterilmediyse sonraki adıma gidin.Yukarıdaki komut tamamlandıktan sonra veya belirli bir iş belirtilmemişse, aşağıdakine benzer bir komut çalıştırarak tanımladığınız büyük dosyaları silin:
rm -rf filecache usercache
Disk alanı sorunları hakkında daha fazla bilgi için bkz . Disk alanı yetersiz.
Not
Saklamak istediğiniz ancak yetersiz disk alanı sorununa katkıda bulunan büyük dosyalarınız varsa HDInsight kümenizin ölçeğini artırmanız ve hizmetlerinizi yeniden başlatmanız gerekir. Bu yordamı tamamladıktan ve birkaç dakika bekledikten sonra depolama alanının boşaltıldığını ve düğümün normal performansının geri yüklendiğini fark edeceksiniz.
Sonraki adımlar
Kümelerinizin sorunlarını giderme ve izleme hakkında daha fazla bilgi için aşağıdaki bağlantıları ziyaret edin:
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin