Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Havuz düzeyi paketlere ek olarak, bir notebook oturumu başında oturuma özel kitaplıklar da belirtebilirsiniz. Oturum kapsamlı kitaplıklar, not defteri oturumunda Python, jar ve R paketlerini belirtmenize ve kullanmanıza olanak sağlar.
Oturum kapsamlı kitaplıkları kullanırken aşağıdaki noktaları göz önünde bulundurmak önemlidir:
- Oturum kapsamlı kitaplıkları yüklediğinizde, yalnızca geçerli not defterinin belirtilen kitaplıklara erişimi olur.
- Bu kitaplıkların aynı Spark havuzunu kullanan diğer oturumlar veya işler üzerinde hiçbir etkisi yoktur.
- Bu kitaplıklar temel çalışma zamanı ve havuz düzeyi kitaplıklarının üzerine yüklenir ve en yüksek önceliği alır.
- Oturum kapsamlı kitaplıklar oturumlar arasında kalıcı olmaz.
Oturum kapsamlı Python paketleri
Environment.yml dosyası aracılığıyla, oturum kapsamlı Python paketlerini yönetme
Oturum kapsamlı Python paketlerini belirtmek için:
- Seçili Spark havuzuna gidin ve oturum düzeyinde kitaplıkları etkinleştirdiğinizden emin olun. Apache Spark havuzu>giderek bu ayarı etkinleştirebilirsiniz.
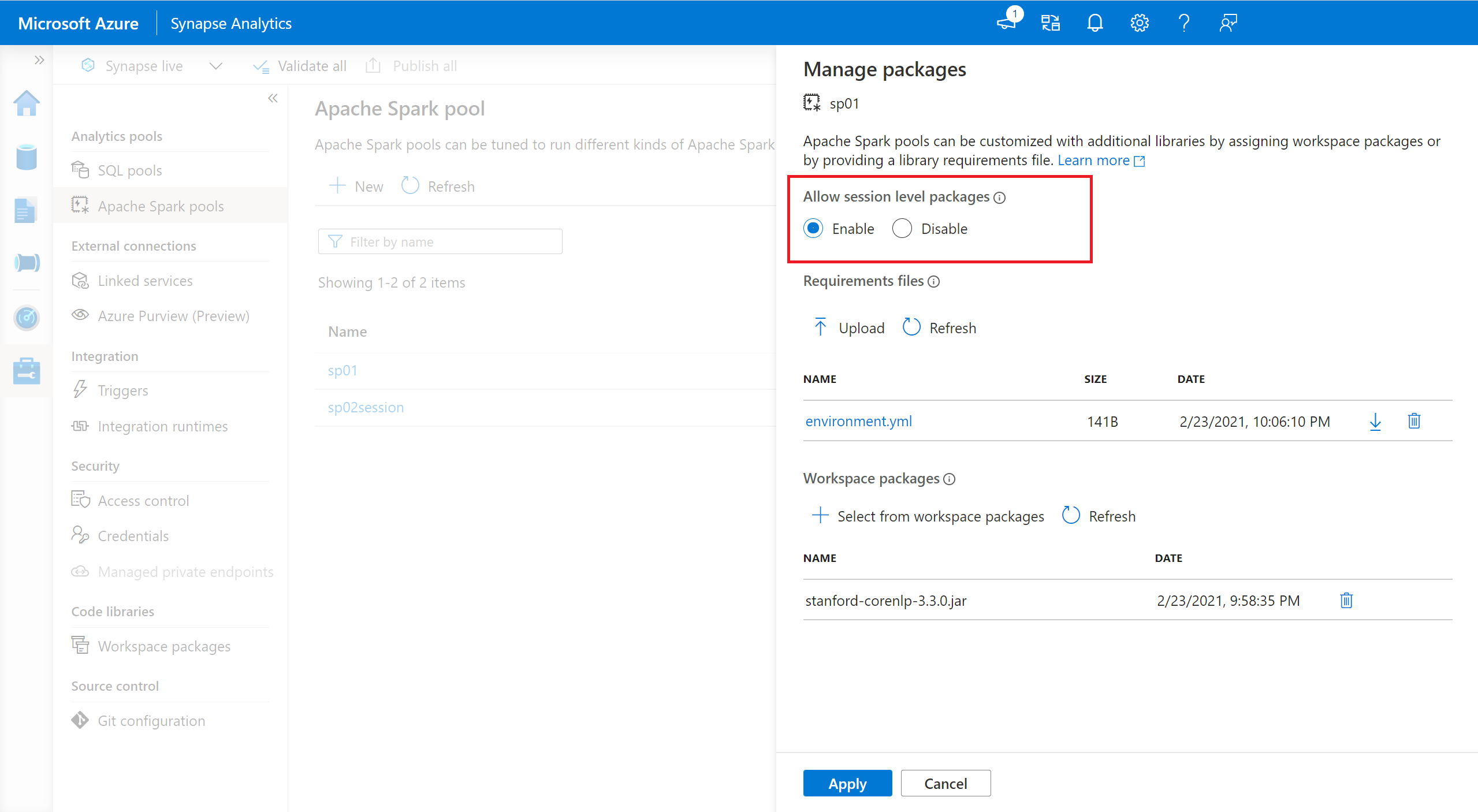
- Ayar uygulandıktan sonra bir not defteri açıp Oturum Yapılandır>Paketler'i seçebilirsiniz.

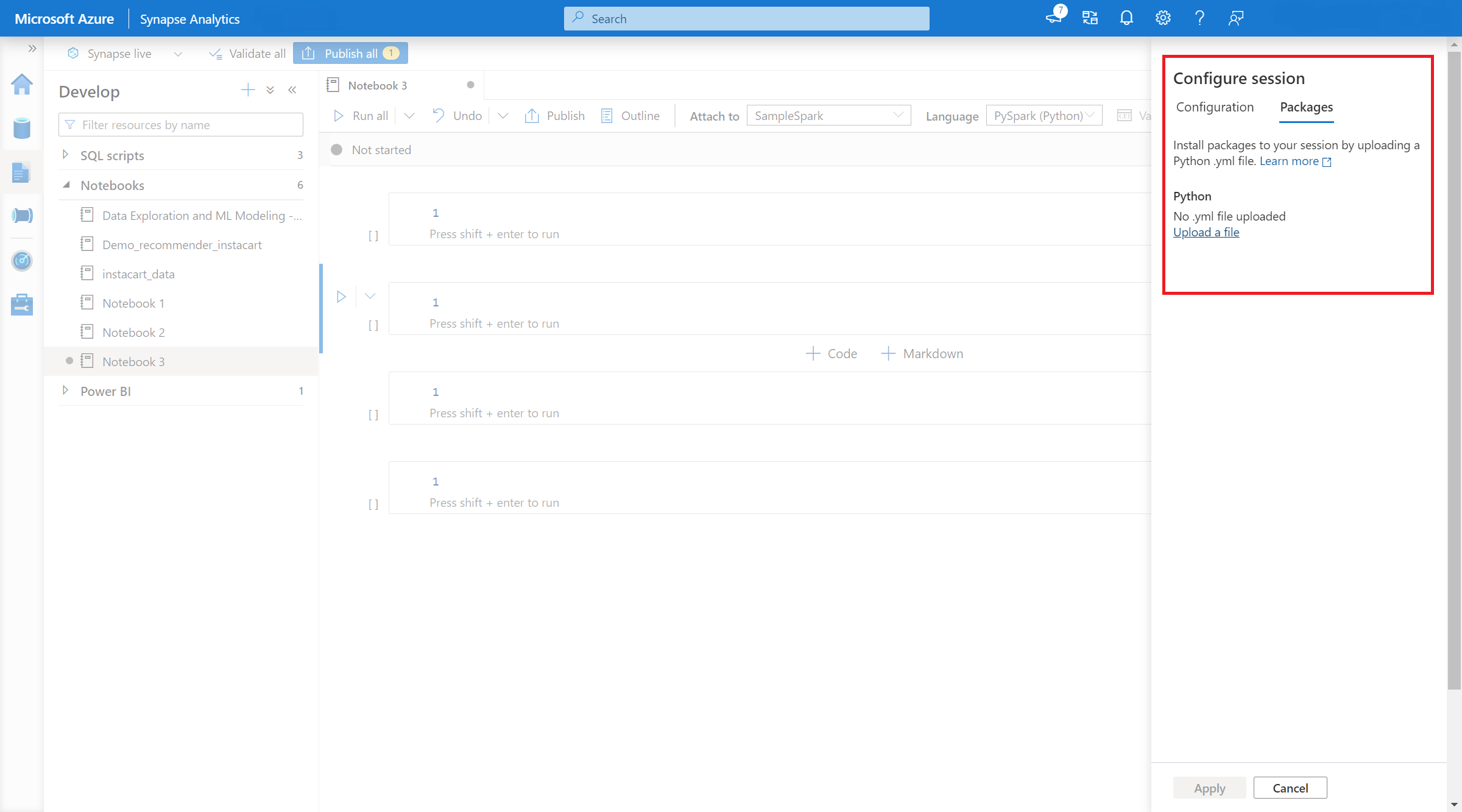
- Burada, bir conda environment.yml dosyasını yükleyerek bir oturum içinde paketleri yükleyebilir veya yükseltebilirsiniz. Oturum başladıktan sonra belirtilen kitaplıklar bulunur. Oturum sona erdikten sonra bu kitaplıklar artık kullanılamaz.

Oturum kapsamlı Python paketlerini %pip ve %conda komutları aracılığıyla yönet
Apache Spark not defteri oturumunuz sırasında ek üçüncü taraf kitaplıkları veya özel kitaplıklarınızı yüklemek için popüler %pip ve %conda komutlarını kullanabilirsiniz. Bu bölümde, bazı yaygın senaryoları göstermek için %pip komutlarını kullanacağız.
Not
- Yeni kitaplıklar yüklemek istiyorsanız not defterinizin ilk hücresine %pip ve %conda komutlarını yerleştirmenizi öneririz. Python yorumlayıcısı, oturum düzeyi kitaplığı değişiklikleri etkili olacak şekilde yönetildikten sonra yeniden başlatılır.
- İşlem hattı işleri çalıştırılırken Python kitaplıklarını yönetmeye yönelik bu komutlar devre dışı bırakılır. İşlem hattı içinde bir paket yüklemek istiyorsanız, havuz düzeyinde kitaplık yönetimi özelliklerinden yararlanmanız gerekir.
- Oturum kapsamındaki Python kitaplıkları, hem sürücü hem de çalışan düğümlerine otomatik olarak yüklenir.
- Aşağıdaki %conda komutları desteklenmez: oluşturma, temizleme, karşılaştırma, etkinleştirme, devre dışı bırakma, çalıştırma, paket.
- Komutların tam listesi için %pip komutlarına ve %conda komutlarına başvurabilirsiniz.
Üçüncü taraf paketi yükleme
PyPI'dan kolayca python kitaplığı yükleyebilirsiniz.
# Install vega_datasets
%pip install altair vega_datasets
Yükleme sonucunu doğrulamak için aşağıdaki kodu çalıştırarak vega_datasets görselleştirebilirsiniz
# Create a scatter plot
# Plot Miles per gallon against the horsepower across different region
import altair as alt
from vega_datasets import data
cars = data.cars()
alt.Chart(cars).mark_point().encode(
x='Horsepower',
y='Miles_per_Gallon',
color='Origin',
).interactive()
Depolama hesabından tekerlek paketi yükleme
Depolama alanından kitaplık yüklemek için aşağıdaki komutları çalıştırarak depolama hesabınıza bağlamanız gerekir.
from notebookutils import mssparkutils
mssparkutils.fs.mount(
"abfss://<<file system>>@<<storage account>.dfs.core.windows.net",
"/<<path to wheel file>>",
{"linkedService":"<<storage name>>"}
)
Ardından gerekli tekerlek paketini yüklemek için %pip install komutunu kullanabilirsiniz
%pip install /<<path to wheel file>>/<<wheel package name>>.whl
Yerleşik kitaplığın başka bir sürümünü yükleme
Belirli bir paketin yerleşik sürümünü görmek için aşağıdaki komutu kullanabilirsiniz. Örnek olarak pandas kullanıyoruz
%pip show pandas
Sonuç şu günlük gibidir:
Name: pandas
Version: **1.2.3**
Summary: Powerful data structures for data analysis, time series, and statistics
Home-page: https://pandas.pydata.org
... ...
Pandas'ı başka bir sürüme (diyelim ki 1.2.4) değiştirmek için aşağıdaki komutu kullanabilirsiniz
%pip install pandas==1.2.4
Oturum kapsamlı kitaplığı kaldır
Bu not defteri oturumunda yüklü olan bir paketi kaldırmak istiyorsanız aşağıdaki komutlara başvurabilirsiniz. Ancak, yerleşik paketleri kaldıramazsınız.
%pip uninstall altair vega_datasets --yes
%pip komutunu kullanarak requirement.txt dosyasından kitaplıkları yükleme
%pip install -r /<<path to requirement file>>/requirements.txt
Oturum kapsamlı Java veya Scala paketleri
Oturum kapsamlı Java veya Scala paketlerini belirtmek için şu %%configure seçeneği kullanabilirsiniz:
%%configure -f
{
"conf": {
"spark.jars": "abfss://<<file system>>@<<storage account>.dfs.core.windows.net/<<path to JAR file>>",
}
}
Not
- %%configure komutunu not defterinizin başında çalıştırmanızı öneririz. Geçerli parametrelerin tam listesi için bu belgeye başvurabilirsiniz.
Oturum kapsamı R paketleri (Önizleme)
Azure Synapse Analytics havuzları, kullanıma hazır birçok popüler R kitaplığı içerir. Apache Spark not defteri oturumunuz sırasında fazladan üçüncü taraf kitaplıkları da yükleyebilirsiniz.
Not
- İşlem hattı işleri çalıştırılırken R kitaplıklarını yönetmeye yönelik bu komutlar devre dışı bırakılır. İşlem hattı içinde bir paket yüklemek istiyorsanız, havuz düzeyinde kitaplık yönetimi özelliklerinden yararlanmanız gerekir.
- Oturum kapsamlı R kitaplıkları hem sürücü düğümlerine hem de çalışan düğümlerine otomatik olarak yüklenir.
Paketi yükleme
CRAN'dan kolayca R kitaplığı yükleyebilirsiniz.
# Install a package from CRAN
install.packages(c("nycflights13", "Lahman"))
CraN anlık görüntülerini depo olarak da kullanarak her seferinde aynı paket sürümünün indirilmesini sağlayabilirsiniz.
install.packages("highcharter", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
Paketleri yüklemek için geliştirici araçlarını kullanma
Kitaplık, devtools ortak görevleri hızlandırmak için paket geliştirmeyi basitleştirir. Bu kitaplık varsayılan Azure Synapse Analytics çalışma zamanına yüklenir.
Kitaplığın yüklenecek belirli bir sürümünü belirtmek için kullanabilirsiniz devtools . Bu kitaplıklar küme içindeki tüm düğümlere yüklenir.
# Install a specific version.
install_version("caesar", version = "1.0.0")
Benzer şekilde, doğrudan GitHub'dan bir kitaplık yükleyebilirsiniz.
# Install a GitHub library.
install_github("jtilly/matchingR")
Şu anda Azure Synapse Analytics'de aşağıdaki devtools işlevler desteklenmektedir:
| Komut | Açıklama |
|---|---|
| install_github() | GitHub'dan R paketi yükler |
| install_gitlab() | GitLab'den R paketi yükler |
| install_bitbucket() | Bitbucket'ten R paketi yükler |
| install_url() | Rastgele bir URL'den R paketi yükler |
| install_git() | Rastgele git deposundan yükler |
| install_local() | Disk üzerindeki yerel bir dosyadan yükler |
| install_version() | CRAN'da belirli bir sürümden yükler |
Yüklü kitaplıkları görüntüleme
komutunu kullanarak library oturumunuzun içinde yüklü olan tüm kitaplıkları sorgulayabilirsiniz.
library()
kitaplığının packageVersion sürümünü denetlemek için işlevini kullanabilirsiniz:
packageVersion("caesar")
R paketini oturumdan kaldırma
ad alanından bir kitaplığı kaldırmak için işlevini kullanabilirsiniz detach . Bu kitaplıklar yeniden yüklenene kadar diskte kalır.
# detach a library
detach("package: caesar")
Oturum kapsamlı bir paketi not defterinden kaldırmak için remove.packages() komutunu kullanın. Bu kitaplık değişikliği aynı kümedeki diğer oturumları etkilemez. Kullanıcılar varsayılan Azure Synapse Analytics çalışma zamanının önceden yüklenmiş kitaplıklarını kaldıramaz veya silemez.
remove.packages("caesar")
Not
SparkR, SparklyR veya R gibi temel paketleri kaldıramazsınız.
Oturum kapsamlı R kitaplıkları ve SparkR
Not defteri kapsamlı kitaplıklar SparkR çalışanlarında kullanılabilir.
install.packages("stringr")
library(SparkR)
str_length_function <- function(x) {
library(stringr)
str_length(x)
}
docs <- c("Wow, I really like the new light sabers!",
"That book was excellent.",
"R is a fantastic language.",
"The service in this restaurant was miserable.",
"This is neither positive or negative.")
spark.lapply(docs, str_length_function)
Oturum kapsamı R kütüphaneleri ve SparklyR
SparklyR'de spark_apply() ile Spark içindeki herhangi bir R paketini kullanabilirsiniz. Varsayılan olarak sparklyr::spark_apply() içinde packages bağımsız değişkeni YANLIŞ olarak ayarlanır. Bu, geçerli libPath'lerdeki kitaplıkları çalışanlara kopyalayarak bunları içeri aktarmanıza ve çalışanlarda kullanmanıza olanak sağlar. Örneğin, sparklyr::spark_apply() ile sezar şifreli bir ileti oluşturmak için aşağıdakileri çalıştırabilirsiniz:
install.packages("caesar", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
spark_version <- "3.2"
config <- spark_config()
sc <- spark_connect(master = "yarn", version = spark_version, spark_home = "/opt/spark", config = config)
apply_cases <- function(x) {
library(caesar)
caesar("hello world")
}
sdf_len(sc, 5) %>%
spark_apply(apply_cases, packages=FALSE)
Sonraki adımlar
- Varsayılan kitaplıkları görüntüleme: Apache Spark sürüm desteği
- Synapse Studio portalı dışındaki paketleri yönetme: Az komutları ve REST API'leri aracılığıyla paketleri yönetme