Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
İpucu
Microsoft Fabric Data Warehouse geleceğe hazır mimariye, yerleşik yapay zekaya ve yeni özelliklere sahip data lake foundation üzerinde kurumsal ölçekli ilişkisel bir ambardır. Veri ambarı konusunda yeniyseniz Fabric Data Warehouse ile başlayın. Mevcut özel SQL havuzu iş yükleri, veri bilimi, gerçek zamanlı analiz ve raporlama genelinde yeni özelliklere erişmek için Fabric yükseltilebilir.
işlevi, OPENROWSET(BULK...) Azure Depolama'daki dosyalara erişmenizi sağlar.
OPENROWSET işlevi, uzak veri kaynağının (örneğin dosya) içeriğini okur ve içeriği bir satır kümesi olarak döndürür. Sunucusuz SQL havuzu kaynağında OPENROWSET toplu satır kümesi sağlayıcısına OPENROWSET işlevi çağrılarak ve BULK seçeneği belirtilerek erişilir.
Sorgunun OPENROWSET yan tümcesinde FROM işlevine, tablo adı OPENROWSET gibi başvurulabilir. Bir dosyadaki verilerin okunmasını ve satır kümesi olarak döndürülmasını sağlayan yerleşik bir BULK sağlayıcısı aracılığıyla toplu işlemleri destekler.
Not
OPENROWSET işlevi ayrılmış SQL havuzunda desteklenmez.
Veri kaynağı
Synapse SQL'deki OPENROWSET işlevi, bir veri kaynağından dosyaların içeriğini okur. Veri kaynağı bir Azure depolama hesabıdır ve OPENROWSET işlevinde açıkça referans alınabilir veya okumak istediğiniz dosyaların URL'sinden dinamik olarak çıkarılabilir.
İşlev, isteğe bağlı olarak dosyaları içeren veri kaynağını belirtmek amacıyla bir OPENROWSET parametresi içerebilir.
OPENROWSETolmadanDATA_SOURCE, seçenek olarakBULKbelirtilen URL konumundan dosyaların içeriğini doğrudan okumak için kullanılabilir:SELECT * FROM OPENROWSET(BULK 'http://<storage account>.dfs.core.windows.net/container/folder/*.parquet', FORMAT = 'PARQUET') AS [file]
Bu, dosyaların içeriğini önceden yapılandırmadan okumanın hızlı ve kolay bir yoludur. Bu seçenek, depolama alanına erişmek için temel kimlik doğrulama seçeneğini kullanmanıza olanak tanır (Microsoft Entra oturum açma işlemleri için Microsoft Entra geçişi ve SQL oturum açma işlemleri için SAS belirteci).
OPENROWSETileDATA_SOURCEbelirtilen depolama hesabındaki dosyalara erişmek için kullanılabilir:SELECT * FROM OPENROWSET(BULK '/folder/*.parquet', DATA_SOURCE='storage', --> Root URL is in LOCATION of DATA SOURCE FORMAT = 'PARQUET') AS [file]Bu seçenek, veri kaynağındaki depolama hesabının konumunu yapılandırmanızı ve depolamaya erişmek için kullanılacak kimlik doğrulama yöntemini belirtmenizi sağlar.
Önemli
OPENROWSETolmadanDATA_SOURCE, depolama dosyalarına erişmek için hızlı ve kolay bir yol sağlar, ancak sınırlı kimlik doğrulama seçenekleri sunar. Örneğin, Microsoft Entra sorumluları dosyalara yalnızca Microsoft Entra kimliklerini veya genel kullanıma açık dosyalarını kullanarak erişebilir. Daha güçlü kimlik doğrulama seçeneklerine ihtiyacınız varsa seçeneğini kullanınDATA_SOURCEve depolamaya erişmek için kullanmak istediğiniz kimlik bilgilerini tanımlayın.
Güvenlik
Veritabanı kullanıcısı, ADMINISTER BULK OPERATIONS işlevini kullanabilmek için OPENROWSET iznine sahip olmalıdır.
Depolama yöneticisi, geçerli SAS belirteci sağlayarak veya Microsoft Entra sorumlusunun depolama dosyalarına erişmesini sağlayarak kullanıcının dosyalara erişmesini de etkinleştirmelidir. Bu makalede depolama erişim denetimi hakkında daha fazla bilgi edinin.
OPENROWSET depolamada kimlik doğrulamasının nasıl yapılacağını belirlemek için aşağıdaki kuralları kullanın:
- Kimlik doğrulama mekanizması olmadan
OPENROWSETiçindeDATA_SOURCEçağıran türüne bağlıdır.- Herhangi bir kullanıcı,
OPENROWSETkullanmadanDATA_SOURCE'yi Azure depolamada genel kullanıma açık dosyaları okumak için kullanabilir. - Azure depolama, Microsoft Entra kullanıcısının temel dosyalara erişmesine izin veriyorsa (örneğin, çağıranın Azure depolama izni varsa) Microsoft Entra oturum açma bilgileri kendi
Storage Readerkullanarak korumalı dosyalara erişebilir. - SQL oturum açma bilgileri,
OPENROWSETilk kullanmadanDATA_SOURCE, genel kullanıma açık dosyalara, SAS belirteci kullanılarak korunan dosyalara veya Synapse çalışma alanının Yönetilen Kimliğine erişmek için de kullanılabilir. Depolama dosyalarına erişime izin vermek için sunucu kapsamlı kimlik bilgileri oluşturmanız gerekir.
- Herhangi bir kullanıcı,
-
OPENROWSETileDATA_SOURCEkimlik doğrulama mekanizması, başvuruda bulunan veri kaynağına atanan veritabanı kapsamlı kimlik bilgileri içinde tanımlanır. Bu seçenek, genel kullanıma açık depolamaya erişebilmenizi ya da SAS belirteci, çalışma alanının Yönetilen Kimliği veya çağıranın Microsoft Entra kimliği (eğer çağıran Microsoft Entra sorumlusuyse) kullanarak depolamaya erişebilmenizi sağlar. Genel olmayan bir Azure depolamasınaDATA_SOURCEbaşvuruyorsanız, depolama dosyalarına erişime izin vermek için veritabanı kapsamlı kimlik bilgileri oluşturmanız ve bu bilgileriDATA SOURCEiçinde referans vermeniz gerekir.
Çağıranın, depolamada kimlik doğrulaması yapmak için kimlik bilgileri üzerinde izni olmalıdır REFERENCES .
Söz dizimi
--OPENROWSET syntax for reading Parquet or Delta Lake files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT= ['PARQUET' | 'DELTA'] }
)
[WITH ( {'column_name' 'column_type' }) ]
[AS] table_alias(column_alias,...n)
--OPENROWSET syntax for reading delimited text files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT = 'CSV'
[ <bulk_options> ]
[ , <reject_options> ] }
)
WITH ( {'column_name' 'column_type' [ 'column_ordinal' | 'json_path'] })
[AS] table_alias(column_alias,...n)
<bulk_options> ::=
[ , FIELDTERMINATOR = 'char' ]
[ , ROWTERMINATOR = 'char' ]
[ , ESCAPECHAR = 'char' ]
[ , FIRSTROW = 'first_row' ]
[ , FIELDQUOTE = 'quote_characters' ]
[ , DATA_COMPRESSION = 'data_compression_method' ]
[ , PARSER_VERSION = 'parser_version' ]
[ , HEADER_ROW = { TRUE | FALSE } ]
[ , DATAFILETYPE = { 'char' | 'widechar' } ]
[ , CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' } ]
[ , ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}' ]
<reject_options> ::=
{
| MAXERRORS = reject_value,
| ERRORFILE_DATA_SOURCE = <data source name>,
| ERRORFILE_LOCATION = '/REJECT_Directory'
}
Tartışmalar
Sorgulama için hedef verileri içeren giriş dosyaları için üç seçeneğiniz vardır. Geçerli değerler:
'CSV' - Satır/sütun ayırıcıları olan sınırlandırılmış metin dosyalarını içerir. Herhangi bir karakter, TSV'de olduğu gibi FIELDTERMINATOR = tab şeklinde, alan ayırıcı olarak kullanılabilir.
'PARQUET' - Parquet biçiminde ikili dosya.
'DELTA' - Delta Lake biçiminde önizleme için düzenlenmiş bir Parquet dosyaları kümesi.
Boş alan içeren değerler geçerli değil. Örneğin, 'CSV' geçerli bir değer değildir.
'unstructured_veri_yolu'
Verilerin yolunu oluşturan unstructured_data_path mutlak veya göreli bir yol olabilir:
- Biçimindeki
\<prefix>://\<storage_account_path>/\<storage_path>mutlak yol, kullanıcının dosyaları doğrudan okumasına olanak tanır. -
<storage_path>parametresi ile kullanılması gerekenDATA_SOURCEbiçimindeki göreli yol, <storage_account_path> konumunda tanımlanan dosya deseniniEXTERNAL DATA SOURCEaçıklar.
Aşağıda, belirli bir dış veri kaynağınıza bağlanacak ilgili <depolama hesabı yol> değerlerini bulabilirsiniz.
| Dış Veri Kaynağı | Önek | Depolama hesabı yolu |
|---|---|---|
| Azure Blob Depolama | http[s] | < >storage_account.blob.core.windows.net/path/file |
| Azure Blob Depolama | wasb[s] | <container>@<storage_account.blob.core.windows.net/path/file> |
| Azure Veri Gölü Deposu 1. Nesil | http[s] | < >storage_account.azuredatalakestore.net/webhdfs/v1 |
| Azure Data Lake Storage Nesil 2 | http[s] | < >storage_account.dfs.core.windows.net/path/file |
| Azure Data Lake Storage Nesil 2 | abfs[s] | < >file_system@<account_name.dfs.core.windows.net/path/file> |
'<depolama_yolu>'
Depolama alanınızda okumak istediğiniz klasöre veya dosyaya işaret eden bir yol belirtir. Yol bir kapsayıcıyı veya klasörü işaret ederse, tüm dosyalar söz konusu kapsayıcıdan veya klasörden okunur. Alt klasörlerdeki dosyalar dahil edilmeyecektir.
Birden çok dosya veya klasörü hedeflemek için joker karakterler kullanabilirsiniz. Birbirinden bağımsız birden çok joker karakter kullanılabilir.
Aşağıda, /csv/population ile başlayan tüm klasörlerdeki popülasyon ile başlayan tüm csv dosyalarını okuyan bir örnek verilmiştir:
https://sqlondemandstorage.blob.core.windows.net/csv/population*/population*.csv
Klasör olarak unstructured_data_path belirtirseniz sunucusuz sql havuzu sorgusu bu klasörden dosya alır.
Sunucusuz SQL havuzuna yol sonunda /* belirterek klasörlerde geçiş yapma talimatı vererek, örneğin: https://sqlondemandstorage.blob.core.windows.net/csv/population/**
Not
Hadoop ve PolyBase'in aksine sunucusuz SQL havuzu, yolun sonunda /** belirtmediğiniz sürece alt klasörler döndürmez. Hadoop ve PolyBase gibi, dosya adının altı çizili (_) veya nokta (.) ile başladığı dosyaları döndürmez.
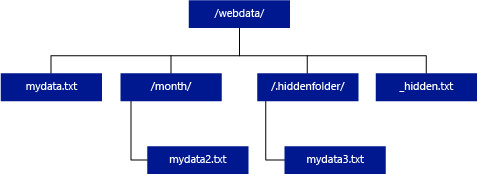
Aşağıdaki örnekte, unstructured_data_path=https://mystorageaccount.dfs.core.windows.net/webdata/ ise sunucusuz bir SQL havuzu sorgusu mydata.txt satırları döndürür. Bir alt klasörde bulunduğundan mydata2.txt ve mydata3.txt döndürmez.
[WITH ( {'column_name' 'column_type' [ 'column_ordinal'] }) ]
WITH yan tümcesi, dosyalardan okumak istediğiniz sütunları belirtmenize olanak tanır.
CSV veri dosyalarında tüm sütunları okumak için sütun adlarını ve bunların veri türlerini sağlayın. Sütunların bir alt kümesini istiyorsanız, sıralı sayıları kullanarak kaynak veri dosyalarındaki sütunları sıralı olarak seçin. Sütunlar sıra numaralandırması ile bağlanacaktır. HEADER_ROW = DOĞRU kullanılırsa, sütun bağlama sıralı konum yerine sütun adıyla yapılır.
İpucu
CSV dosyaları için WITH yan tümcesini de atlayabilirsiniz. Veri türleri dosya içeriğinden otomatik olarak çıkarılır. HEADER_ROW bağımsız değişkenini kullanarak üst bilgi satırının varlığını ve bu durumda sütun adlarının üst bilgi satırından okunacağını belirtebilirsiniz. Ayrıntılar için otomatik şema bulmayı denetleyin.
Parquet veya Delta Lake dosyaları için, kaynak veri dosyalarındaki sütun adlarla eşleşen sütun adları sağlayın. Sütunlar isimlerine göre eşleştirilir ve büyük/küçük harfe duyarlıdır. WITH ifadesi atlanırsa, Parquet dosyalarındaki tüm sütunlar döndürülür.
Önemli
Parquet ve Delta Lake dosyalarındaki sütun adları büyük/küçük harfe duyarlıdır. Eğer dosyalardaki sütun adıyla farklı bir büyük/küçük harf biçimde sütun adı belirtirseniz, bu sütun için
NULLdeğerleri döndürülür.
column_name = Çıkış sütunu için ad. Sağlanırsa, bu ad kaynak dosyadaki sütun adını ve varsa JSON yolunda sağlanan sütun adını geçersiz kılar. json_path sağlanmazsa otomatik olarak '$.column_name' olarak eklenir. json_path bağımsız değişkeninin davranışını denetleyin.
column_type = Çıkış sütunu için veri türü. Örtük veri türü dönüştürme işlemi burada gerçekleşir.
column_ordinal = Kaynak dosyalarda sütunun sıra numarası. Bağlama ada göre yapıldığından parquet dosyaları için bu bağımsız değişken yoksayılır. Aşağıdaki örnek yalnızca CSV dosyasından ikinci bir sütun döndürür:
WITH (
--[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2 2
--[year] smallint,
--[population] bigint
)
json_path = JSON yol ifadesi sütuna veya iç içe geçmiş özelliğe. Varsayılan yol modu gevşektir.
Not
Katı modda sorgu, belirtilen yol mevcut değilse hata verir. Lax modunda sorgu başarılı olur ve JSON yol ifadesi NULL olarak değerlendirilir.
<toplu_seçenekler>
FIELDTERMINATOR ='field_terminator'
Kullanılacak alan sonlandırıcısını belirtir. Varsayılan alan sonlandırıcısı virgüldür (",").
ROWTERMINATOR ='row_terminator'
Kullanılacak satır sonlandırıcısını belirtir. Satır sonlandırıcı belirtilmezse, varsayılan sonlandırıcılardan biri kullanılır. PARSER_VERSION = '1.0' için varsayılan sonlandırıcılar \r\n, \n ve \r'dır. PARSER_VERSION = '2.0' için varsayılan sonlandırıcılar \r\n ve \n'tir.
Not
PARSER_VERSION='1.0' kullanıp satır sonlandırıcısı olarak \n (yeni satır) belirttiğinizde, otomatik olarak bir \r (satır başı) karakteri eklenir ve bu da \r\n satır sonlandırıcısıyla sonuçlanır.
ESCAPE_CHAR = 'char'
Dosyada, kendisinden ve dosyadaki tüm sınırlayıcı değerlerden kaçmak için kullanılan karakteri belirtir. Kaçış karakterinin ardından kendi dışında bir değer veya sınırlayıcı değerlerden biri gelirse, değer okunurken kaçış karakteri bırakılır.
ESCAPECHAR parametresi, FIELDQUOTE'nin etkin olup olmamasına bakılmaksızın uygulanır. Alıntı karakterinden kaçmak için kullanılmaz. Alıntı karakteri, başka bir alıntı karakteriyle kaçırılmalıdır. Alıntı karakteri, sütun değeri içinde yalnızca değer, alıntı karakterleriyle kapsüllenmişse görünebilir.
FIRSTROW = 'first_row'
Yüklenecek ilk satırın sayısını belirtir. Varsayılan değer 1'dir ve belirtilen veri dosyasındaki ilk satırı gösterir. Satır numaraları, satır sonlandırıcıları sayılarak belirlenir. FIRSTROW 1 tabanlıdır.
FIELDQUOTE = 'field_quote'
CSV dosyasında tırnak karakteri olarak kullanılacak bir karakter belirtir. Belirtilmezse, tırnak karakteri (") kullanılır.
DATA_COMPRESSION = 'veri_sıkıştırma_yöntemi'
Sıkıştırma yöntemini belirtir. Yalnızca PARSER_VERSION='1.0' içinde desteklenir. Aşağıdaki sıkıştırma yöntemi desteklenir:
- GZIP
PARSER_VERSION = 'parser_version'
Dosyaları okurken kullanılacak ayrıştırıcı sürümünü belirtir. Şu anda desteklenen CSV ayrıştırıcı sürümleri 1.0 ve 2.0'dır:
- PARSER_VERSION = '1.0'
- PARSER_VERSION = '2.0'
CSV ayrıştırıcısı sürüm 1.0 varsayılandır ve zengin özelliklere sahiptir. Sürüm 2.0 performans için oluşturulmuş olup tüm seçenekleri ve kodlamaları desteklemez.
CSV ayrıştırıcı sürüm 1.0 özellikleri:
- Aşağıdaki seçenekler desteklenmez: HEADER_ROW.
- Varsayılan sonlandırıcılar \r\n, \n ve \r'dır.
- Satır sonlandırıcısı olarak \n (yeni satır) belirtirseniz, buna otomatik olarak bir \r (satır başı) karakteri eklenir ve bu da \r\n satır sonlandırıcısıyla sonuçlanır.
CSV ayrıştırıcı sürüm 2.0 özellikleri:
- Tüm veri türleri desteklenmez.
- Karakter sütun uzunluğu üst sınırı 8000'dir.
- Satır boyutu üst sınırı 8 MB'tır.
- Aşağıdaki seçenekler desteklenmez: DATA_COMPRESSION.
- Alıntılanan boş dize ("") boş dize olarak yorumlanır.
- DATEFORMAT SET seçeneği kabul edilmez.
- DATE veri türü için desteklenen biçim: YYYY-AA-GG
- TIME veri türü için desteklenen biçim: HH:MM:SS[.fractional seconds]
- DATETIME2 veri türü için desteklenen biçim: YYYY-AA-GG SS:DD:SS[.kesirli saniye]
- Varsayılan sonlandırıcılar \r\n ve \n'tir.
HEADER_ROW = { DOĞRU | YANLIŞ }
CSV dosyasının üst bilgi satırı içerip içermediğini belirtir. Varsayılan değer PARSER_VERSION FALSE. ='2.0' içinde desteklenir. TRUE ise, sütun adları FIRSTROW bağımsız değişkenine göre ilk satırdan okunur. TRUE ve şema WITH kullanılarak belirtilirse, sütun adlarının bağlaması sıralı konumlarla değil sütun adıyla yapılır.
DATAFILETYPE = { 'char' | 'widechar' }
Kodlamayı belirtir: char UTF8 için kullanılır, widechar UTF16 dosyaları için kullanılır.
CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' }
Veri dosyasındaki verilerin kod sayfasını belirtir. Varsayılan değer 65001'dir (UTF-8 kodlaması). Bu seçenek hakkında daha fazla ayrıntı için buraya bakın.
ROWSET_OPTIONS = '{"READ_OPTIONS":["TUTARSIZ_OKUMALARA_İZİN_VER"]}'
Bu seçenek, sorgu yürütme sırasında dosya değişikliği denetimini devre dışı bırakır ve sorgu çalışırken güncelleştirilen dosyaları okur. Bu seçenek, sorgu çalışırken eklenen yalnızca ekleme dosyalarını okumanız gerektiğinde kullanışlıdır. Eklenebilir dosyalara mevcut içerik güncelleştirilmez ve yalnızca yeni satırlar eklenir. Bu nedenle, güncelleştirilebilir dosyalara kıyasla yanlış sonuç olasılığı en aza indirilir. Bu seçenek, hataları işlemeden sık eklenen dosyaları okumanızı sağlayabilir. Eklenebilir CSV dosyalarını sorgulama bölümünde daha fazla bilgi bulabilirsiniz.
Reddetme Seçenekleri
Not
Reddedilen satırlar özelliği Genel Önizleme'dedir. Reddedilen satırlar özelliğinin sınırlandırılmış metin dosyaları ve PARSER_VERSION 1.0 için çalıştığını lütfen unutmayın.
Hizmetin dış veri kaynağından alan kirli kayıtları nasıl işleyeceklerini belirleyen reddetme parametreleri belirtebilirsiniz. Gerçek veri türleri dış tablonun sütun tanımlarıyla eşleşmiyorsa veri kaydı 'kirli' olarak kabul edilir.
Reddetme seçeneklerini belirtmediğinizde veya değiştirmediğinizde, hizmet varsayılan değerleri kullanır. Hizmet, gerçek sorgu başarısız olmadan önce reddedilebilen satır sayısını belirlemek için reddetme seçeneklerini kullanır. Reddetme eşiği aşılana kadar sorgu kısmi sonuçlar döndürür. Ardından uygun hata iletisiyle başarısız olur.
MAXERRORS = reject_value
Sorgu başarısız olmadan önce reddedilebilen satır sayısını belirtir. MAXERRORS, 0 ile 2.147.483.647 arasında bir tamsayı olmalıdır.
ERRORFILE_DATA_SOURCE = veri kaynağı
Reddedilen satırların ve ilgili hata dosyasının yazılacağı veri kaynağını belirtir.
ERRORFILE_LOCATION = Dizin Konumu
reddedilen satırların ve ilgili hata dosyasının yazılması gerektiğini DATA_SOURCE içindeki dizini veya belirtilirse ERROR_FILE_DATASOURCE belirtir. Belirtilen yol yoksa, hizmet sizin adınıza bir yol oluşturur. "rejectedrows" adında bir alt dizin oluşturulur. "" karakteri, konum parametresinde açıkça belirtilmediği sürece dizinin diğer veri işleme süreçlerinden hariç tutulmasını sağlar." Bu dizinde, YearMonthDay_HourMinuteSecond_StatementID biçiminde yük gönderme süresine göre oluşturulmuş bir klasör vardır (Ör. 20180330-173205-559EE7D2-196D-400A-806D-3BF5D007F891). Sorguyu oluşturduğu klasör ile ilişkilendirmek için ifade kimliğini kullanabilirsiniz. Bu klasörde iki dosya yazılır: error.json dosyası ve veri dosyası.
error.json dosyası, reddedilen satırlarla ilgili hatalarla karşılaşılan json dizisini içerir. Hatayı temsil eden her öğe aşağıdaki öznitelikleri içerir:
| Öznitelik | Açıklama |
|---|---|
| Hata | Satırın reddedilme nedeni. |
| Satır | Dosyadaki reddedilen satır sıra numarası. |
| Sütun | Reddedilen sütunun sıra numarası. |
| Değer | Reddedilen sütun değeri. Değer 100 karakterden büyükse yalnızca ilk 100 karakter görüntülenir. |
| Dosya | Bu satırın ait olduğu dosyanın yolu. |
Hızlı sınırlandırılmış metin ayrıştırma
Kullanabileceğiniz iki sınırlandırılmış metin ayrıştırıcı sürümü vardır. CSV ayrıştırıcı sürüm 1.0, varsayılan ve zengin özelliklere sahipken; ayrıştırıcı sürüm 2.0, performans için oluşturulmuştur. Ayrıştırıcı 2.0'daki performans iyileştirmesi, gelişmiş ayrıştırma tekniklerinden ve çoklu iş parçacığından kaynaklanır. Dosya boyutu büyüdükçe hız farkı daha büyük olacaktır.
Otomatik şema bulma
WITH yan tümcesini atlayarak şemayı bilmeden veya belirtmeden hem CSV hem de Parquet dosyalarını kolayca sorgulayabilirsiniz. Sütun adları ve veri türleri dosyalardan çıkarılır.
Parquet dosyaları okunacak olan sütun meta verilerini içerir. Parquet için tür eşlemelerinde tür eşlemeleri bulunabilir. Örnekler için şemayı belirtmeden Parquet dosyalarını okuma örneklerini kontrol edin.
CSV dosyaları için sütun adları üst bilgi satırından okunabilir. HEADER_ROW bağımsız değişkeni kullanarak üst bilgi satırının var olup olmadığını belirtebilirsiniz. HEADER_ROW = YANLIŞ ise genel sütun adları kullanılır: C1, C2, ... Cn burada n, dosyadaki sütun sayısıdır. Veri türleri ilk 100 veri satırı arasından çıkarılır. Örnekler için şema belirtmeden CSV dosyalarını okumayı denetleyin.
Dosya sayısını aynı anda okuyorsanız, şemanın depolama hizmetinin depodan aldığı ilk dosyadan belirleneceğini unutmayın. Bu, beklenen bazı sütunların atlanacağı anlamına gelebilir, çünkü şemayı tanımlamak için hizmet tarafından kullanılan dosya bu sütunları içermiyordu. Bu durumda OPENROWSET WITH ifadesini kullanın.
Önemli
Bilgi eksikliği nedeniyle uygun veri türünün çıkarılamadığı ve bunun yerine daha büyük veri türünün kullanılacağı durumlar vardır. Performans üzerinde ek yük oluşturur ve varchar(8000) olarak varsayılacak karakter sütunları için özellikle önemlidir. En iyi performans için, çıkarsanan veri türlerini denetleyin ve uygun veri türlerini kullanın.
Parquet için tür eşlemesi
Parquet ve Delta Lake dosyaları her sütun için tür açıklamaları içerir. Aşağıdaki tabloda Parquet türlerinin SQL yerel türlerine nasıl eşlendiği açıklanmaktadır.
| Parquet türü | Parquet mantıksal türü (ek açıklama) | SQL veri türü |
|---|---|---|
| boolean | bir parça | |
| İKİLİ / BYTE_ARRAY | varbinary | |
| ÇİFT | kayan noktalı sayı | |
| yüzen nesne | gerçek | |
| INT32 | int | |
| INT64 | bigint | |
| INT96 | datetime2 | |
| sabit uzunlukta bayt dizisi | ikili | |
| İKİLİ | UTF8 | varchar *(UTF8 harmanlama) |
| İKİLİ | DİZGİ | varchar *(UTF8 harmanlama) |
| İKİLİ | ENUM | varchar *(UTF8 harmanlama) |
| sabit uzunlukta bayt dizisi | UUID | benzersiz tanımlayıcı |
| İKİLİ | ONDALIK | ondalık |
| İKİLİ | JSON | varchar(8000) *(UTF8 harmanlama) |
| İKİLİ | BSON | Desteklenmez |
| sabit uzunlukta bayt dizisi | ONDALIK | ondalık |
| BYTE_DİZİSİ | ARALIK | Desteklenmez |
| INT32 | INT(8, true) (8 bitlik tam sayı, doğru) | smallint |
| INT32 | INT(16, doğru) | smallint |
| INT32 | INT(32, true) | int |
| INT32 | INT(8, yanlış) | tinyint |
| INT32 | INT(16, yanlış) | int |
| INT32 | INT(32, false) | bigint |
| INT32 | TARİH | tarih |
| INT32 | ONDALIK | ondalık |
| INT32 | ZAMAN (Milisaniye) | zaman |
| INT64 | INT(64, doğru) | bigint |
| INT64 | INT(64, yanlış) | ondalık(20,0) |
| INT64 | ONDALIK | ondalık |
| INT64 | ZAMAN (MICROS) | zaman |
| INT64 | ZAMAN (NANOS) | Desteklenmez |
| INT64 | TIMESTAMP (utc olarak normalleştirilmiş) (MILLIS / MICROS) | datetime2 |
| INT64 | TIMESTAMP (utc'ye normalleştirilmemiş) (MILLIS / MICROS) | bigint - bir tarih saat değerine dönüştürmeden önce bigint değerini saat dilimi farkıyla açıkça ayarladığınızdan emin olun. |
| INT64 | ZAMAN DAMGASI (NANO SANİYE) | Desteklenmez |
| Karmaşık tür | LİSTE | varchar(8000), JSON olarak serileştirilmiş |
| Karmaşık tür | HARİTA | varchar(8000), JSON olarak serileştirilmiş |
Örnekler
Şema belirtmeden CSV dosyalarını okuma
Aşağıdaki örnek, sütun adlarını ve veri türlerini belirtmeden üst bilgi satırı içeren CSV dosyasını okur:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
HEADER_ROW = TRUE) as [r]
Aşağıdaki örnek, sütun adlarını ve veri türlerini belirtmeden üst bilgi satırı içermeyen CSV dosyasını okur:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0') as [r]
Şema belirtmeden Parquet dosyalarını okuma
Aşağıdaki örnek, sayım veri kümesindeki ilk satırın tüm sütunlarını Parquet biçiminde ve sütun adları ve veri türleri belirtmeden döndürür:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
) AS [r]
Şema belirtmeden Delta Lake dosyalarını okuma
Aşağıdaki örnek, delta lake biçiminde ve sütun adlarını ve veri türlerini belirtmeden sayım veri kümesindeki ilk satırın tüm sütunlarını döndürür:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='DELTA'
) AS [r]
CSV dosyasından belirli sütunları okuma
Aşağıdaki örnek, population*.csv dosyalarından yalnızca 1 ve 4 sıralı sayılar içeren iki sütun döndürür. Dosyalarda üst bilgi satırı olmadığından ilk satırdan okumaya başlar:
SELECT
*
FROM OPENROWSET(
BULK 'https://sqlondemandstorage.blob.core.windows.net/csv/population/population*.csv',
FORMAT = 'CSV',
FIRSTROW = 1
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2 1,
[population] bigint 4
) AS [r]
Parquet dosyasından belirli sütunları okuma
Aşağıdaki örnek, sayım veri kümesindeki ilk satırın yalnızca iki sütununu Parquet biçiminde döndürür:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
[stateName] VARCHAR (50),
[population] bigint
) AS [r]
JSON yollarını kullanarak sütunları belirtme
Aşağıdaki örnek, WITH yan tümcesinde JSON yol ifadelerini nasıl kullanabileceğinizi gösterir ve katı ve lax yol modları arasındaki farkı gösterir:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
--lax path mode samples
[stateName] VARCHAR (50), -- this one works as column name casing is valid - it targets the same column as the next one
[stateName_explicit_path] VARCHAR (50) '$.stateName', -- this one works as column name casing is valid
[COUNTYNAME] VARCHAR (50), -- STATEname column will contain NULLs only because of wrong casing - it targets the same column as the next one
[countyName_explicit_path] VARCHAR (50) '$.COUNTYNAME', -- STATEname column will contain NULLS only because of wrong casing and default path mode being lax
--strict path mode samples
[population] bigint 'strict $.population' -- this one works as column name casing is valid
--,[population2] bigint 'strict $.POPULATION' -- this one fails because of wrong casing and strict path mode
)
AS [r]
BULK yolunda birden çok dosya/klasör belirtme
Aşağıdaki örnekte BULK parametresinde birden çok dosya/klasör yolunu nasıl kullanabileceğiniz gösterilmektedir:
SELECT
TOP 10 *
FROM
OPENROWSET(
BULK (
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2000/*.parquet',
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2010/*.parquet'
),
FORMAT='PARQUET'
)
AS [r]
Sonraki adımlar
Daha fazla örnek için, sorgu veri depolama hızlı başlangıç belgesine bakın ve OPENROWSET'i kullanarak CSV, PARQUET, DELTA LAKE ve JSON dosya biçimlerini nasıl okuyacağınızı öğrenin. En iyi performansı elde etmek için en iyi yöntemleri denetleyin. Ayrıca CETAS kullanarak sorgunuzun sonuçlarını Azure Depolama'ya kaydetmeyi de öğrenebilirsiniz.