Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Şunlar için geçerlidir: SQL Server Analysis Services Azure Analysis Services Fabric/Power BI Premium
SQL Server Analysis Services Azure Analysis Services Fabric/Power BI Premium
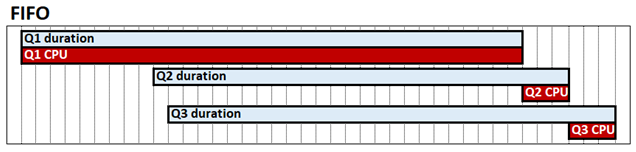
Sorgu birleştirme, yüksek eşzamanlılık senaryolarında sorgu performansını geliştirebilen bir tablo modu sistem yapılandırmasıdır. Varsayılan olarak, Analysis Services tablo motoru, CPU ile ilgili olarak ilk gelen, ilk çıkan (FIFO) şeklinde çalışır. FIFO ile, örneğin kaynak açısından pahalı ve büyük olasılıkla yavaş bir depolama altyapısı sorgusu alınırsa ve ardından iki hızlı sorgu gelirse, hızlı sorgular, pahalı sorgunun tamamlanmasını beklerken engellenebilir. Bu davranış, ilgili sorgular, süreleri ve CPU süresi olarak Q1, Q2 ve Q3'ü gösteren aşağıdaki diyagramda gösterilmiştir.
Kısa sorgu yanlılığı ile sorgu aralaması, eşzamanlı sorguların CPU kaynaklarını paylaşmasına olanak tanır; bu da hızlı sorguların yavaş sorguların arkasında engellenmemesi anlamına gelir. Üç sorgunun da tamamlanması için geçen süre hala aynıdır, ancak örneğimizde Q2 ve Q3 sonuna kadar engellenmez. Kısa sorgu sapması, her sorgunun belirli bir noktada zaten ne kadar CPU kullandığıyla tanımlanan hızlı sorguların uzun süre çalışan sorgulardan daha yüksek kaynak oranına atanabileceği anlamına gelir. Aşağıdaki diyagramda, Q2 ve Q3 sorguları hızlı kabul edilir ve Q1'den daha fazla CPU ayrılır.
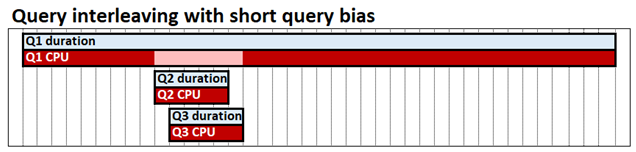
Sorgu araya eklemenin, yalıtımlı çalışan sorgular üzerinde çok az performans etkisine sahip olması veya hiç olmaması amaçlanmıştır; tek bir sorgu, FIFO modeliyle olduğu kadar CPU kullanmaya devam edebilir.
Dikkat edilmesi gereken önemli hususlar
Sorgu araya eklemenin senaryonuz için uygun olup olmadığını belirlemeden önce aşağıdakileri göz önünde bulundurun:
- Sorgu araya ekleme yalnızca içeri aktarma modelleri için geçerlidir. DirectQuery modellerini etkilemez.
- Sorgu birleştirme yalnızca VertiPaq depolama altyapısı sorguları tarafından kullanılan CPU'yu dikkate alır. Formül motoru işlemleri için geçerli değildir.
- Tek bir DAX sorgusu birden çok VertiPaq depolama altyapısı sorgusuna neden olabilir. Bir DAX sorgusu, depolama altyapısı sorguları tarafından tüketilen CPU'ya göre hızlı veya yavaş kabul edilir. DAX sorgusu ölçü birimidir.
- Yenileme işlemleri varsayılan olarak sorgu araya eklemeye karşı korunur. Uzun süre çalışan yenileme işlemleri, uzun süre çalışan sorgulara göre farklı kategorilere ayrılmıştır.
Yapılandırma
Sorgu araya işlem eklemeyi yapılandırmak için Threadpool\SchedulingBehavior özelliğini ayarlayın. Bu özellik aşağıdaki değerlerle belirtilebilir:
| Değer | Description |
|---|---|
| -1 | Otomatik. Motor kuyruk türünü seçecek. |
| 0 (SSAS 2019 için varsayılan) | İlk gelen, ilk çıkan (FIFO). |
| 1 | Kısa sorgu sapması. Motor, hızlı sorguları tercih ederek baskı altında olduğunda uzun süre çalışan sorgular üzerinde kademeli olarak yavaşlatma yapar. |
| 3 (Azure AS, Power BI, SSAS 2022 ve üzeri için varsayılan) | Hızlı iptal ile kısa sorgu sapması. Yüksek eşzamanlılık senaryolarında kullanıcı sorgusu yanıt sürelerini geliştirir. Yalnızca Azure AS, Power BI, SSAS 2022 ve üzeri için geçerlidir. |
Şu anda SchedulingBehavior özelliği yalnızca XMLA kullanılarak ayarlanabilir. SQL Server Management Studio'da, aşağıdaki XMLA kod parçacığı SchedulingBehavior özelliğini 1 olarak ayarlar, kısa sorgu yanlılıkları.
<Alter AllowCreate="true" ObjectExpansion="ObjectProperties" xmlns="http://schemas.microsoft.com/analysisservices/2003/engine">
<Object />
<ObjectDefinition>
<Server xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:ddl2="http://schemas.microsoft.com/analysisservices/2003/engine/2" xmlns:ddl2_2="http://schemas.microsoft.com/analysisservices/2003/engine/2/2" xmlns:ddl100_100="http://schemas.microsoft.com/analysisservices/2008/engine/100/100" xmlns:ddl200="http://schemas.microsoft.com/analysisservices/2010/engine/200" xmlns:ddl200_200="http://schemas.microsoft.com/analysisservices/2010/engine/200/200" xmlns:ddl300="http://schemas.microsoft.com/analysisservices/2011/engine/300" xmlns:ddl300_300="http://schemas.microsoft.com/analysisservices/2011/engine/300/300" xmlns:ddl400="http://schemas.microsoft.com/analysisservices/2012/engine/400" xmlns:ddl400_400="http://schemas.microsoft.com/analysisservices/2012/engine/400/400" xmlns:ddl500="http://schemas.microsoft.com/analysisservices/2013/engine/500" xmlns:ddl500_500="http://schemas.microsoft.com/analysisservices/2013/engine/500/500">
<ID>myserver</ID>
<Name>myserver</Name>
<ServerProperties>
<ServerProperty>
<Name>ThreadPool\SchedulingBehavior</Name>
<Value>1</Value>
</ServerProperty>
</ServerProperties>
</Server>
</ObjectDefinition>
</Alter>
Önemli
Sunucu örneğinin yeniden başlatılması gerekir. Azure Analysis Services'te sunucuyu durdurup yeniden başlatarak etkili bir şekilde çalıştırmanız gerekir.
Ek özellikler
Çoğu durumda, SchedulingBehavior ayarlamanız gereken tek özelliktir. Aşağıdaki ek özellikler, kısa sorgu sapmalı çoğu senaryoda çalışması gereken varsayılan değerlere sahiptir, ancak gerekirse değiştirilebilir. SchedulingBehavior özelliği ayarlanarak sorgu araya ekleme etkinleştirilmediği sürece aşağıdaki özelliklerin hiçbir etkisi yoktur .
ReservedComputeForFastQueries - Hızlı sorgular için ayrılmış mantıksal çekirdek sayısını ayarlar. Tüm sorgular, belirli bir CPU miktarı kullandıkları için yavaşlayana kadar hızlı kabul edilir. ReservedComputeForFastQueries, 0 ile 100 arasında bir tamsayıdır. Varsayılan değer 75'tir.
ReservedComputeForFastQueries için ölçü birimi çekirdek yüzdesidir. Örneğin, 20 çekirdeği olan bir sunucudaki 80 değeri, hızlı sorgular için 16 çekirdek ayırmayı dener (yenileme işlemi yapılmazken). ReservedComputeForFastQueries, en yakın tam çekirdek sayısına yukarı yuvarlar. Bu özellik değerini 50'nin altına ayarlamamanızı öneririz. Bunun nedeni hızlı sorguların yok sayılabilmesi ve özelliğin genel tasarımına karşı olmasıdır.
DecayIntervalCPUTime - Sorgunun bozulmadan önce harcadığı CPU süresini milisaniye cinsinden temsil eden tamsayı. Sistem CPU baskısı altındaysa, bozulan sorgular hızlı sorgular için ayrılmamış kalan çekirdeklerle sınırlıdır. Varsayılan değer 60.000'dir. Bu, geçen takvim süresini değil 1 dakikalık CPU süresini temsil eder.
ReservedComputeForProcessing - Her işleme (veri yenileme) işlemi için ayrılmış mantıksal çekirdek sayısını ayarlar. Özellik değeri, varsayılan değeri 75 olan 0 ile 100 arasında bir tamsayıdır. değeri ReservedComputeForFastQueries özelliği tarafından belirlenen çekirdeklerin yüzdesini temsil eder. 0 (sıfır) değeri, işleme işlemlerinin sorgular ile aynı sorgu birleştirme mantığına tabi olduğu anlamına gelir, bu nedenle bozulabilir.
İşleme işlemleri gerçekleştirilmezken ReservedComputeForProcessing'in herhangi bir etkisi yoktur. Örneğin, değeri 80 olan ReservedComputeForFastQueries, 20 çekirdekli bir sunucuda hızlı sorgular için 16 çekirdek ayırır. 75 değeriyle ReservedComputeForProcessing, yenileme işlemleri için 16 çekirdeğin 12'sini ayırır ve işlem işlemleri çalışırken ve CPU tüketirken hızlı sorgular için 4'lerini bırakır. Aşağıdaki Çürümüş sorgular bölümünde açıklandığı gibi, hızlı sorgular veya işleme işlemleri için özel olarak ayrılmamış olan kalan 4 çekirdek, boşta kalmaları durumunda hızlı sorgular ve işleme için kullanılmaya devam edecektir.
Bu ek özellikler ResourceGovernance özellikleri düğümü altında bulunur. SQL Server Management Studio'da aşağıdaki örnek XMLA kod parçacığı, DecayIntervalCPUTime özelliğini varsayılan değerden daha düşük bir değere ayarlar:
<Alter AllowCreate="true" ObjectExpansion="ObjectProperties" xmlns="http://schemas.microsoft.com/analysisservices/2003/engine">
<Object />
<ObjectDefinition>
<Server xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:ddl2="http://schemas.microsoft.com/analysisservices/2003/engine/2" xmlns:ddl2_2="http://schemas.microsoft.com/analysisservices/2003/engine/2/2" xmlns:ddl100_100="http://schemas.microsoft.com/analysisservices/2008/engine/100/100" xmlns:ddl200="http://schemas.microsoft.com/analysisservices/2010/engine/200" xmlns:ddl200_200="http://schemas.microsoft.com/analysisservices/2010/engine/200/200" xmlns:ddl300="http://schemas.microsoft.com/analysisservices/2011/engine/300" xmlns:ddl300_300="http://schemas.microsoft.com/analysisservices/2011/engine/300/300" xmlns:ddl400="http://schemas.microsoft.com/analysisservices/2012/engine/400" xmlns:ddl400_400="http://schemas.microsoft.com/analysisservices/2012/engine/400/400" xmlns:ddl500="http://schemas.microsoft.com/analysisservices/2013/engine/500" xmlns:ddl500_500="http://schemas.microsoft.com/analysisservices/2013/engine/500/500">
<ID>myserver</ID>
<Name>myserver</Name>
<ServerProperties>
<ServerProperty>
<Name>ResourceGovernance\DecayIntervalCPUTime</Name>
<Value>15000</Value>
</ServerProperty>
</ServerProperties>
</Server>
</ObjectDefinition>
</Alter>
Eskimiş sorgular
Bu bölümde açıklanan kısıtlamalar yalnızca sistem CPU baskısı altındaysa geçerlidir. Örneğin tek bir sorgu, sistemde belirli bir zamanda çalışan tek sorguysa, bozulup bozulmadığına bakılmaksızın tüm kullanılabilir çekirdekleri kullanabilir.
Her sorgu birçok depolama altyapısı işi gerektirebilir. Bozulan sorgular için havuzdaki bir çekirdek kullanılabilir olduğunda, zamanlayıcı geçen takvim süresine göre çalışan en eski sorguyu denetleyecek ve Maksimum Çekirdek Yetkilendirmesini (MCE) kullanıp kullanmadığını kontrol edecektir. Eğer hayır ise, sonraki işi yürütülür. Evet ise, bir sonraki en eski sorgu değerlendirilir. MCE sorgusu, daha önce kaç bozunma aralığı kullandığına göre belirlenir. Kullanılan her bozulma aralığı için MCE, aşağıdaki tabloda gösterilen algoritmaya göre azaltılır. Bu, sorgu tamamlanana, zaman aşımına uğrayana veya MCE (örneğin, Çok Çekirdekli Motor) tek bir çekirdeğe indirgenene kadar devam eder.
Aşağıdaki örnekte, sistemin 32 çekirdeği vardır ve sistemin CPU'su baskı altındadır.
Hızlı Sorgular için Ayrılan Hesaplama (ReservedComputeForFastQueries) %60 (60%).
- 20 çekirdek (19,2 yukarı yuvarlanmış) hızlı sorgular için ayrılmıştır.
- Kalan 12 çekirdek, bozulan sorgular için ayrılır.
DecayIntervalCPUTime 60.000 'dir (1 dakikalık CPU süresi).
Zaman aşımına veya tamamlanmadığı sürece sorgunun yaşam döngüsü aşağıdaki gibi olabilir:
| Aşama | Statü | Yürütme/zamanlama | MCE |
|---|---|---|---|
| 0 | Hızlı | MCE 20 çekirdektir (hızlı sorgular için ayrılmıştır). Sorgu, 20 ayrılmış çekirdek genelindeki diğer hızlı sorgulara göre FIFO biçiminde yürütülür. 1 dakikalık CPU zamanı bozulma süresi doldu. |
20 = MIN(32/2˄0, 20) |
| 1 | Çürümüş | MCE, 12 çekirdek olarak ayarlanır (hızlı sorgular için ayrılmayan 12 çekirdek). İşler, MCE'ye kadar kullanılabilirlik temelinde yürütülür. 1 dakikalık CPU zamanı bozulma süresi doldu. |
12 = MIN(32/2˄1, 12) |
| 2 | Çürümüş | MCE 8 çekirdeğe (toplam 32 çekirdeğin çeyreği) ayarlanır. İşler, MCE'ye kadar kullanılabilirlik temelinde yürütülür. 1 dakikalık CPU zamanı bozulma süresi doldu. |
8 = MIN(32/2˄2, 12) |
| 3 | Çürümüş | MCE 4 çekirdeğe ayarlanır. İşler, MCE'ye kadar kullanılabilirlik temelinde yürütülür. 1 dakikalık CPU zamanı bozulma süresi doldu. |
4 = MIN(32/2˄3, 12) |
| 4 | Çürümüş | MCE 2 çekirdek olarak ayarlanır. İşler, MCE'ye kadar olan kullanılabilirlik durumuna göre yürütülür. 1 dakikalık CPU zamanı bozulma süresi doldu. |
2 = MIN(32/2˄4, 12) |
| 5 | Çürümüş | MCE 1 çekirdek olarak ayarlanır. İşler, MCE'ye kadar kullanılabilirlik temelinde yürütülür. Sorgu en düşük seviyeye ulaştığından bozulma aralığı uygulanmaz. En az 1 çekirdeğe ulaşılana kadar başka bozulma olmaz. |
1 = Mİn(32/2˄5, 12) |
Sistem CPU baskısı altındaysa, her sorguya MCE'den daha fazla çekirdek atanmayacak. Tüm çekirdekler şu anda ilgili MCE'leri içindeki sorgular tarafından kullanılıyorsa, diğer sorgular çekirdekler kullanılabilir duruma gelene kadar bekler. Çekirdekler kullanılabilir hale geldikçe, geçen takvim süresine göre en eski yetkili veya uygun sorgu seçilir. MCE, baskı altındaki bir ölçüdür; herhangi bir zamanda CPU çekirdek sayısını garanti etmez.