Hatalara Karşı Dayanıklı Tasarım (Azure ile Real-World Cloud Apps Oluşturma)
Tarafından Rick Anderson, Tom Dykstra
Fix It Project'i indirin veya E-kitap indirin
Azure ile Gerçek Dünya Bulut Uygulamaları Oluşturma e-kitabı, Scott Guthrie tarafından geliştirilen bir sunuyu temel alır. Bulut için web uygulamalarını başarıyla geliştirmenize yardımcı olabilecek 13 desen ve uygulama açıklanmaktadır. E-kitap hakkında bilgi için ilk bölüme bakın.
Herhangi bir uygulama türünü oluştururken düşünmeniz gereken şeylerden biri, ancak özellikle de çok sayıda kişinin kullanacağı bulutta çalışacak olan uygulama, hataları düzgün bir şekilde işleyebilmesi ve mümkün olduğunca değer sunmaya devam edebilmesi için uygulamayı nasıl tasarlayabileceğinizdir. Yeterince zaman verildiğinde, herhangi bir ortamda veya herhangi bir yazılım sisteminde işler ters gidecektir. Uygulamanızın bu durumları nasıl ele aldığı, müşterilerinizin ne kadar üzüleceğini ve sorunları analiz etmek ve düzeltmek için ne kadar zaman harcamanız gerekeceğini belirler.
Hata türleri
Farklı şekilde işlemek isteyeceğiniz iki temel hata kategorisi vardır:
- Aralıklı ağ bağlantısı sorunları gibi geçici, kendi kendini iyileştiren hatalar.
- Müdahale gerektiren kalıcı hatalar.
Geçici hatalar için, uygulamanın çoğu zaman hızlı ve otomatik olarak kurtarılmasını sağlamak için bir yeniden deneme ilkesi uygulayabilirsiniz. Müşterileriniz yanıt süresinin biraz daha uzun olduğunu fark edebilir, ancak aksi takdirde etkilenmez. Geçici Hata İşleme bölümünde bu hataları işlemenin bazı yollarını göstereceğiz.
Kalıcı hatalar için, sorunlar oluştuğunda sizi hemen bilgilendiren ve kök neden analizini kolaylaştıran izleme ve günlüğe kaydetme işlevselliği uygulayabilirsiniz. İzleme ve Telemetri bölümünde bu tür hatalardan haberdar olmanıza yardımcı olacak bazı yollar göstereceğiz.
Hata kapsamı
Ayrıca tek bir makinenin etkilenip etkilenmediğini, SQL Veritabanı veya Depolama gibi bir hizmetin tamamının ya da bölgenin tamamının hata kapsamı hakkında düşünmeniz gerekir.

Makine hataları
Azure'da, başarısız bir sunucu otomatik olarak yeni bir sunucuyla değiştirilir ve iyi tasarlanmış bir bulut uygulaması bu tür hatalardan otomatik ve hızlı bir şekilde kurtarılır. Daha önce durum bilgisi olmayan bir web katmanının ölçeklenebilirlik avantajlarını vurguladık ve başarısız bir sunucudan kurtarma kolaylığı durum bilgisizliğinin bir diğer avantajıdır. Kurtarma kolaylığı, SQL Veritabanı ve Azure App Service Web Apps gibi hizmet olarak platform (PaaS) özelliklerinin avantajlarından biridir. Donanım hataları nadirdir, ancak oluştuğunda bu hizmetler bunları otomatik olarak işler; bu hizmetlerden birini kullanırken makine hatalarını işlemek için kod yazmanız bile gerekmez.
Hizmet hataları
Bulut uygulamaları genellikle birden çok hizmet kullanır. Örneğin, Düzelt uygulaması SQL Veritabanı hizmetini, Depolama hizmetini kullanır ve web uygulaması Azure App Service dağıtılır. Bağımlı olduğunuz hizmetlerden biri başarısız olursa uygulamanız ne yapar? Bazı hizmet hataları için kolay bir "üzgünüz, daha sonra yeniden deneyin" iletisi yapabileceğiniz en iyi ileti olabilir. Ancak birçok senaryoda daha iyisini yapabilirsiniz. Örneğin, arka uç veri deponuz kapandığında kullanıcı girişini kabul edebilir, "isteğiniz alındı" ifadesini görüntüleyebilir ve girişi geçici olarak başka bir yerde depolayabilirsiniz; ardından ihtiyacınız olan hizmet yeniden çalışır duruma geldiğinde girişi alabilir ve işleyebilirsiniz.
Kuyruk Merkezli çalışma düzeni bölümünde bu senaryoyu işlemenin bir yolu gösterilmektedir. Düzelt uygulaması görevleri SQL Veritabanı'de depolar, ancak SQL Veritabanı devre dışı bırakıldığında çalışmayı bırakması gerekmez. Bu bölümde bir görevin kullanıcı girişini kuyrukta depolamayı ve kuyruğu okuyup görevi güncelleştirmek için çalışan işlemini kullanmayı göreceğiz. SQL çalışmıyorsa Düzelt görevlerini oluşturma özelliği etkilenmez; çalışan işlemi, SQL Veritabanı kullanılabilir olduğunda yeni görevleri bekleyebilir ve işleyebilir.
Bölge hataları
Bölgelerin tamamı başarısız olabilir. Doğal bir afet bir veri merkezini yok edebilir, bir meteor tarafından düzleştirilebilir, veri merkezine giden ana hat bir çiftçi tarafından kesilebilir ve bir ineği arka bezle gömebilir vb. Uygulamanız kısıtlı veri merkezinde barındırılıyorsa ne yaparsınız? Azure'da uygulamanızı aynı anda birden çok bölgede çalışacak şekilde ayarlayabilirsiniz, böylece bir bölgede olağanüstü durum oluşursa başka bir bölgede çalışmaya devam edebilirsiniz. Bu tür hatalar son derece nadir karşılaşılan durumlardır ve çoğu uygulama, bu tür hatalarda kesintisiz hizmet sağlamak için gereken çemberlerden atlamaz. Bölge hatası durumunda bile uygulamanızı kullanılabilir durumda tutma hakkında bilgi için bölümün sonundaki Kaynaklar bölümüne bakın.
Azure'ın bir hedefi, bu tür hataların tümünün işlenmesini çok daha kolay hale getirmektir ve aşağıdaki bölümlerde bunu nasıl yaptığımıza ilişkin bazı örnekler göreceksiniz.
SLA’lar
Kişiler genellikle bulut ortamındaki hizmet düzeyi sözleşmelerini (SLA) duyarsınız. Temel olarak bunlar, şirketlerin hizmetlerinden ne kadar güvenilir oldukları konusunda verdikleri sözlerdir. %99,9 SLA, hizmetin %99,9 oranında düzgün çalışmasını beklemeniz gerektiği anlamına gelir. Bu, bir SLA için oldukça tipik bir değerdir ve kulağa çok yüksek bir sayı gibi gelir, ancak %1'in gerçekte ne kadar çalışmadığını fark etmeyebilirsiniz. Aşağıda çeşitli SLA yüzdelerinin bir yıl, bir ay ve bir haftadan daha fazla kapalı kalma süresinin ne kadar olduğunu gösteren bir tablo yer almaktadır.
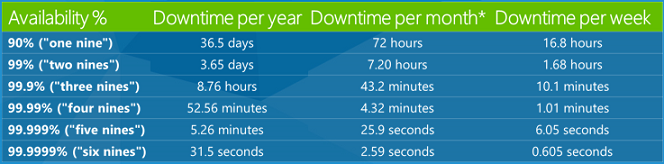
Dolayısıyla %99,9 SLA, hizmetinizin yılda 8,76 saat veya ayda 43,2 dakika düşebileceği anlamına gelir. Bu çoğu insanın fark edebileceğinden daha fazla zaman. Bu nedenle bir geliştirici olarak belirli bir sürenin mümkün olduğunu ve bunu zarif bir şekilde ele alındığını bilmek istiyorsunuz. Bir noktada birisi uygulamanızı kullanacaktır ve bir hizmet kapanacaktır ve bunun müşteri üzerindeki olumsuz etkisini en aza indirmek istiyorsunuz.
SLA hakkında bilmeniz gereken bir şey, hangi zaman çerçevesine başvurduğudur: saat her hafta, her ay veya her yıl sıfırlanır mı? Azure'da saati her ay sıfırlarız. Bu sizin için yıllık SLA'dan daha iyidir çünkü yıllık SLA, kötü ayları bir dizi iyi ayla sıfırlayarak gizleyebilir.
Elbette her zaman SLA'dan daha iyisini yapmak istiyoruz; Genellikle bundan çok daha az inersin. Söz veriyorum, eğer en uzun çalışma süresinden daha uzun süre kalırsak para isteyebilirsiniz. Geri alacağınız para miktarı muhtemelen fazla çalışma süresinin iş etkisini tam olarak telafi etmez, ancak SLA'nın bu yönü bir uygulama ilkesi işlevi görür ve bunu çok ciddiye aldığımızı bilmenizi sağlar.
Bileşik SLA'lar
SLA'lara bakarken dikkate almanız gereken önemli bir nokta, bir uygulamada her hizmetin ayrı bir SLA'ya sahip olduğu birden çok hizmet kullanmanın etkisidir. Örneğin, Düzelt uygulaması Azure App Service Web Apps, Azure Depolama ve SQL Veritabanı kullanır. Bu e-kitabın Aralık 2013'te yazıldığı tarih itibarıyla SLA numaraları şunlardır:
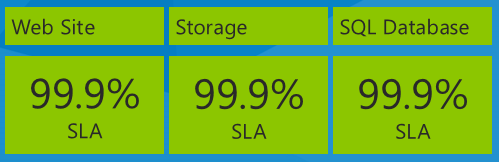
Bu hizmet SLA'larına göre uygulama için beklemeniz gereken en uzun çalışma süresi nedir? Bu durumda, aşağı inme sürenizin en kötü SLA yüzdesine veya %99,9'a eşit olacağını düşünebilirsiniz. Üç hizmet de her zaman aynı anda başarısız olursa bu doğru olur, ancak gerçekte olan bu olmayabilir. Her hizmet farklı zamanlarda bağımsız olarak başarısız olabilir, bu nedenle tek tek SLA sayılarını çarparak bileşik SLA'yı hesaplamanız gerekir.
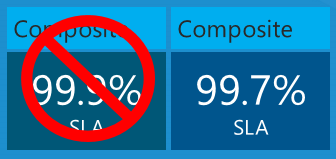
Bu nedenle uygulamanız ayda yalnızca 43,2 dakika değil, bu tutarın 3 katı, ayda 108 dakika olabilir ve yine de Azure SLA sınırları içinde olabilir.
Bu sorun Azure'a özgü değildir. Aslında kullanılabilir tüm bulut hizmetlerinin en iyi bulut SLA'larını sağlarız ve satıcının bulut hizmetlerini kullanıyorsanız benzer sorunlarla karşılaşırsınız. Bunun vurguladığı nokta, müşterilerinizi veya kullanıcılarınızı etkilemek için yeterince sık gerçekleşebileceğinden, uygulamanızı kaçınılmaz hizmet hatalarını düzgün bir şekilde ele almak için nasıl tasarlayabileceğinizi düşünmenin önemidir.
Kurumsal kesinti süresi deneyimiyle karşılaştırıldığında bulut SLA'ları
Kişiler bazen "Kurumsal uygulamamda bu sorunları hiç yaşamam" deyin. Ayda ne kadar çalışma zamanları olduğunu sorarsanız genellikle "Ara sıra olur" derler. Ne sıklıkta sorulduğunu sorarsanız, "Bazen yeni bir sunucu yedeklememiz veya yüklememiz ya da yazılımı güncelleştirmemiz gerekir" sözlerini kabul ederler. Tabii ki, bu aşağı zaman olarak sayılır. Özellikle görev açısından kritik olmayan çoğu kurumsal uygulama, hizmet SLA'larımızın izin verdiği süreden daha uzun süredir çalışmıyor. Ancak sunucunuz, altyapınız ve bundan sorumlu olduğunuzda ve denetimi size ait olduğunda, aşağı zamanlarda kendinizi daha az angst hissetme eğiliminde olursunuz. Bulut ortamında başka birine bağımlısınız ve neler olduğunu bilmiyorsunuz, bu nedenle bu konuda daha fazla endişelenme eğiliminde olabilirsiniz.
Bir kuruluş, bulut SLA'sından elde ettiğinizden daha fazla çalışma süresi yüzdesi elde ettiğinde, bunu donanıma çok daha fazla para harcayarak yapar. Bir bulut hizmeti bunu yapabilir ancak hizmetleri için çok daha fazla ücret ödemesi gerekir. Bunun yerine, uygun maliyetli hizmetlerden yararlanıp yazılımınızı, kaçınılmaz hataların müşterileriniz için en düşük kesintiye neden olacak şekilde tasarlamanız gerekir. Bulut uygulaması tasarımcısı olarak işiniz, felaketten kaçınmak için başarısızlığı önlemek için çok fazla değildir ve bunu donanıma değil yazılıma odaklanarak yaparsınız. Kurumsal uygulamalar hatalar arasındaki ortalama süreyi en üst düzeye çıkarmaya çalışırken, bulut uygulamaları ortalama kurtarma süresini en aza indirmeye çalışır.
Tüm bulut hizmetlerinin SLA'ları yoktur
Ayrıca her bulut hizmetinin bile bir SLA'sı olmadığını unutmayın. Uygulamanız çalışma süresi garantisi olmayan bir hizmete bağımlıysa hayal edebileceğinizden çok daha uzun süre aşağıda olabilirsiniz. Örneğin, Facebook veya Twitter gibi bir sosyal hizmet sağlayıcısı kullanarak sitenizde oturum açmayı etkinleştirirseniz bir SLA olup olmadığını öğrenmek için hizmet sağlayıcısına başvurun ve bir SLA olmadığını öğrenebilirsiniz. Ancak kimlik doğrulama hizmeti kapanırsa veya ona attığınız isteklerin hacmini destekleyemezse, müşterileriniz uygulamanızdan kilitlenir. Günler veya daha uzun süre aşağıda olabilirsiniz. Yeni bir uygulamanın oluşturucuları yüz milyonlarca indirme bekliyor ve Facebook kimlik doğrulamasına bağımlıydı – ancak canlı yayına geçmeden önce Facebook'la konuşmadı ve bu hizmet için SLA olmadığını çok geç keşfetti.
Tüm kapalı kalma süreleri SLA'lara göre sayılmaz
Bazı bulut hizmetleri, uygulamanız bunları aşırı kullanıyorsa hizmeti kasıtlı olarak reddedebilir. Buna azaltma denir. Bir hizmetin SLA'sı varsa, kısıtlanabileceğiniz koşulları belirtmeli ve uygulama tasarımınız bu koşullardan kaçınmalı ve olursa azaltmaya uygun şekilde tepki vermelidir. Örneğin, bir hizmete yönelik istekler belirli bir sayıyı /saniyeyi aştığınızda başarısız oluyorsa, otomatik yeniden denemelerin azaltmanın devam etmelerine neden olacak kadar hızlı gerçekleşmediğinden emin olmak istersiniz. Geçici Hata İşleme bölümünde azaltma hakkında daha fazla şey söyleyeceğiz.
Özet
Bu bölüm, gerçek bir bulut uygulamasının hatalara düzgün bir şekilde devam etmek için neden tasarlanması gerektiğini anlamanızı sağlamaya çalıştı. Sonraki bölümden başlayarak, bu serideki kalan desenler, bunu yapmak için kullanabileceğiniz bazı stratejiler hakkında daha ayrıntılı bilgi sağlar:
- İyi izleme ve telemetriye sahip olun; böylece müdahale gerektiren hatalar hakkında hızlı bir şekilde bilgi edinebilir ve bunları çözmek için yeterli bilgiye sahip olursunuz.
- Geçici hataları işlemek için akıllı yeniden deneme mantığı uygulayarak uygulamanızın uygun olduğunda otomatik olarak kurtarılması ve kurtarılamadığında devre kesici mantığına geri dönmesi sağlanır.
- Veritabanı erişimiyle ilgili aktarım hızını, gecikme süresini ve bağlantı sorunlarını en aza indirmek için dağıtılmış önbelleğe alma özelliğini kullanın.
- Arka uç kapatıldığında uygulamanızın ön ucunun çalışmaya devam edebilmesi için kuyruk merkezli iş düzeni aracılığıyla gevşek bağlama uygulayın.
Kaynaklar
Daha fazla bilgi için bu e-kitabın sonraki bölümlerine ve aşağıdaki kaynaklara bakın.
Belgeler:
- Failsafe: Dayanıklı Bulut Mimarileri kılavuzu. Marc Mercuri, Ulrich Homann ve Andrew Townhill tarafından teknik inceleme. FailSafe video serisinin web sayfası sürümü.
- Azure Cloud Services'da Large-Scale Hizmetleri Tasarımı için En İyi Yöntemler. Mark Simms ve Michael Thomassy'nin teknik incelemesi.
- Azure İş Sürekliliği Teknik Kılavuzu. Patrick Wickline ve Jason Roth'un teknik incelemesi.
- Azure Uygulamaları için Olağanüstü Durum Kurtarma ve Yüksek Kullanılabilirlik. Michael McKeown, Hanu Kommalapati ve Jason Roth'un teknik incelemesi.
- Microsoft Desenleri ve Uygulamaları - Azure Kılavuzu. Bkz. Multi Data Center Dağıtım kılavuzu, Devre kesici düzeni.
- Azure Desteği - Hizmet Düzeyi Sözleşmeleri.
- Azure SQL Veritabanında İş Sürekliliği. SQL Veritabanı yüksek kullanılabilirlik ve olağanüstü durum kurtarma özellikleri hakkında belgeler.
- Azure Sanal Makineler'da SQL Server için Yüksek Kullanılabilirlik ve Olağanüstü Durum Kurtarma.
Videolar:
- FailSafe: Ölçeklenebilir, Dayanıklı Cloud Services Oluşturma. Ulrich Homann, Marc Mercuri ve Mark Simms'in dokuz bölümden oluşan serisi. Microsoft Müşteri Danışmanlığı Ekibi (CAT) deneyiminin gerçek müşterilerle olan hikayeleriyle üst düzey kavramları ve mimari ilkelerini çok erişilebilir ve ilginç bir şekilde sunar. Bölüm 1 ve 8, hatalardan kurtulmak için bulut uygulamaları tasarlamanın nedenlerini ayrıntılı olarak açıklar. Ayrıca bölüm 2'de saat 49:57'den başlayarak azaltmanın izleme tartışmasını, 2. bölümde hata noktalarının ve hata modlarının 56:05'te başlaması ve bölüm 3'teki devre kesicilerin 40:55'te başlayan tartışmaları da inceleyin.
- Büyük Derleme: Azure müşterilerinden alınan dersler - Bölüm II. Mark Simms, başarısızlık tasarımından ve her şeyi izlemeden bahsediyor. Failsafe serisine benzer ancak daha fazla nasıl yapılır ayrıntılarına gider.
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin