Belge Zekası okuma modeli
Önemli
- Document Intelligence genel önizleme sürümleri, etkin geliştirme aşamasında olan özelliklere erken erişim sağlar.
- Genel Kullanılabilirlik (GA) öncesinde kullanıcı geri bildirimlerine göre özellikler, yaklaşımlar ve süreçler değişebilir.
- Belge Zekası istemci kitaplıklarının genel önizleme sürümü varsayılan olarak REST API sürüm 2024-02-29-preview'dır.
- Genel önizleme sürümü 2024-02-29-preview şu anda yalnızca aşağıdaki Azure bölgelerinde kullanılabilir:
- Doğu ABD
- Batı ABD2
- Batı Avrupa
Bu içerik şunlar için geçerlidir:![]() v4.0 (önizleme) | Önceki sürümler:
v4.0 (önizleme) | Önceki sürümler:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)
Bu içerik şunlar için geçerlidir: ![]() v3.1 (GA) | En son sürüm:
v3.1 (GA) | En son sürüm: ![]() v4.0 (önizleme) | Önceki sürümler:
v4.0 (önizleme) | Önceki sürümler: ![]() v3.0
v3.0
Bu içerik şunlar için geçerlidir: ![]() v3.0 (GA) | En son sürümler:
v3.0 (GA) | En son sürümler:![]() v4.0 (önizleme)
v4.0 (önizleme)![]() v3.1
v3.1
Not
Etiketler, sokak işaretleri ve posterler gibi dış görüntülerden metin ayıklamak için, kullanıcı deneyimi senaryolarınıza OCR eklemeyi kolaylaştıran, performans açısından gelişmiş bir zaman uyumlu API ile genel, belge dışı görüntüler için iyileştirilmiş Azure AI Görüntü Analizi v4.0 Okuma özelliğini kullanın.
Belge Zekası Okuma Optik Karakter Tanıma (OCR) modeli, Azure AI Görüntü İşleme Okuma'dan daha yüksek çözünürlükte çalışır ve PDF belgelerinden ve taranmış görüntülerden yazdırma ve el yazısı metinleri ayıklar. Ayrıca Microsoft Word, Excel, PowerPoint ve HTML belgelerinden metin ayıklama desteği de içerir. Paragrafları, metin satırlarını, sözcükleri, konumları ve dilleri algılar. Okuma modeli, özel modellere ek olarak Düzen, Genel Belge, Fatura, Makbuz, Kimlik (Kimlik) belgesi, Sağlık sigortası kartı, W2 gibi önceden oluşturulmuş diğer Belge Zekası modelleri için temel alınan OCR altyapısıdır.
Belgeler için OCR nedir?
Belgeler için Optik Karakter Tanıma (OCR), birden çok dosya biçiminde ve genel dilde büyük metin ağırlıklı belgeler için iyileştirilmiştir. Daha küçük ve yoğun metinlerin daha iyi işlenmesi için belge görüntülerinin daha yüksek çözünürlüklü taranmış olması gibi özellikler içerir; paragraf algılama; ve doldurulabilir form yönetimi. OCR özellikleri, tek karakterli kutular gibi gelişmiş senaryoları ve faturalarda, makbuzlarda ve diğer önceden oluşturulmuş senaryolarda yaygın olarak bulunan anahtar alanlarının doğru ayıklarını içerir.
Dağıtım seçenekleri
Document Intelligence v4.0 (2024-02-29-preview, 2023-10-31-preview) aşağıdaki araçları, uygulamaları ve kitaplıkları destekler:
| Özellik | Kaynaklar | Model Kimliği |
|---|---|---|
| OCR modelini okuma | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
önceden oluşturulmuş okuma |
Document Intelligence v3.1 aşağıdaki araçları, uygulamaları ve kitaplıkları destekler:
| Özellik | Kaynaklar | Model Kimliği |
|---|---|---|
| OCR modelini okuma | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
önceden oluşturulmuş okuma |
Document Intelligence v3.0 aşağıdaki araçları, uygulamaları ve kitaplıkları destekler:
| Özellik | Kaynaklar | Model Kimliği |
|---|---|---|
| OCR modelini okuma | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
önceden oluşturulmuş okuma |
Giriş gereksinimleri
En iyi sonuçları elde için belge başına tek bir net fotoğraf veya yüksek kaliteli tarama sağlayın.
Desteklenen dosya biçimleri:
Model PDF Resim:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) ve HTMLOkundu ✔ ✔ ✔ Düzen ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Genel Belge ✔ ✔ Önceden oluşturulmuş ✔ ✔ Özel ayıklama ✔ ✔ Özel sınıflandırma ✔ ✔ ✔ (2024-02-29-preview) PDF ve TIFF için en fazla 2000 sayfa işlenebilir (ücretsiz katman aboneliğiyle yalnızca ilk iki sayfa işlenir).
Belgeleri analiz etmek için dosya boyutu ücretli (S0) katman için 500 MB ve ücretsiz (F0) katmanı için 4 MB'tır.
Görüntü boyutları 50 x 50 piksel ile 10.000 piksel x 10.000 piksel arasında olmalıdır.
PDF’leriniz parola korumalıysa göndermeden önce kilidi kaldırmanız gerekir.
Ayıklanacak metnin en düşük yüksekliği 1024 x 768 piksel görüntü için 12 pikseldir. Bu boyut, inç başına 150 nokta (DPI) olan yaklaşık
8noktalı metne karşılık gelir.Özel model eğitimi için eğitim verileri için en fazla sayfa sayısı özel şablon modeli için 500, özel sinir modeli için 50.000'dir.
Özel ayıklama modeli eğitimi için eğitim verilerinin toplam boyutu şablon modeli için 50 MB ve sinir modeli için 1G-MB'tır.
Özel sınıflandırma modeli eğitimi için eğitim verilerinin toplam boyutu en fazla 10.000 sayfadır
1GB.
Okuma modelini kullanmaya başlama
Document Intelligence Studio'yu kullanarak formlardan ve belgelerden metin ayıklamayı deneyin. Aşağıdaki varlıklara ihtiyacınız vardır:
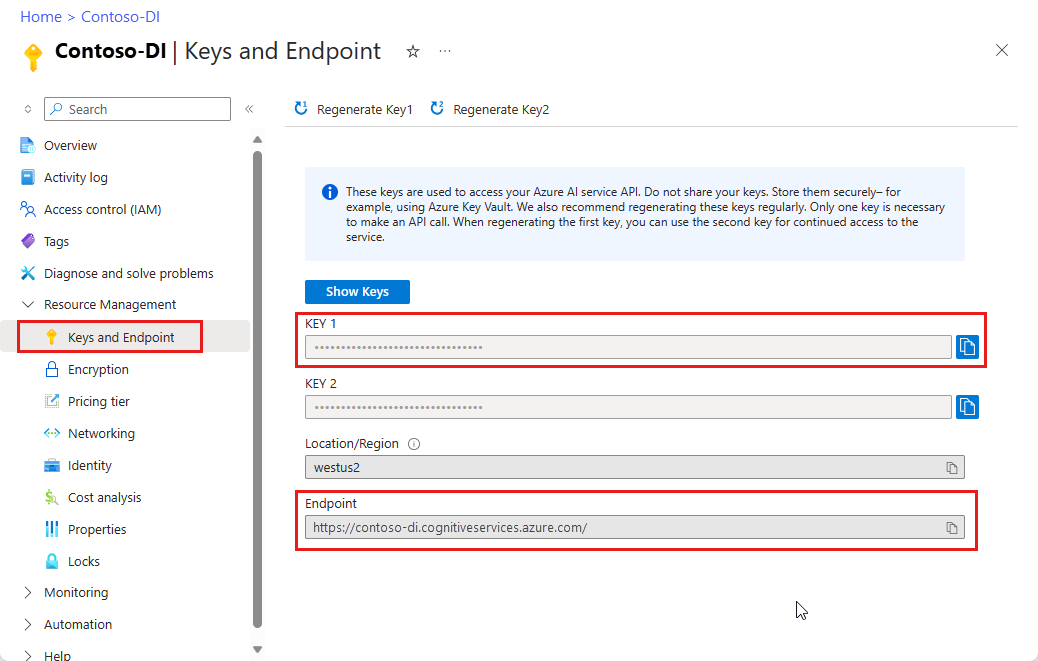
Azure aboneliği: Ücretsiz olarak bir abonelik oluşturabilirsiniz.
Azure portalında bir Belge Zekası örneği. Hizmeti denemek için ücretsiz fiyatlandırma katmanını (
F0) kullanabilirsiniz. Kaynağınız dağıtıldıktan sonra anahtarınızı ve uç noktanızı almak için Kaynağa git'i seçin.
Not
Document Intelligence Studio şu anda Microsoft Word, Excel, PowerPoint ve HTML dosya biçimlerini desteklememektedir.
Document Intelligence Studio ile işlenen örnek belge
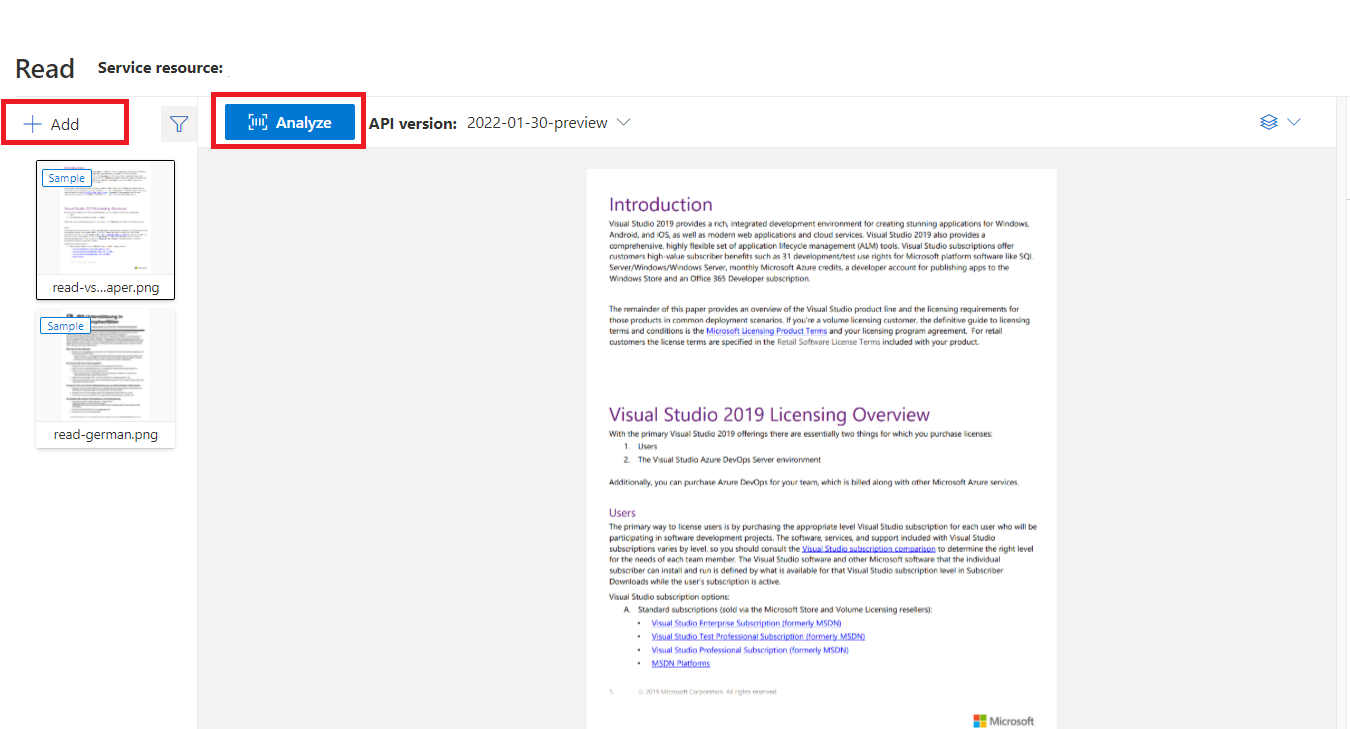
Document Intelligence Studio giriş sayfasında Oku'yu seçin.
Örnek belgeyi analiz edebilir veya kendi dosyalarınızı karşıya yükleyebilirsiniz.
Analizi çalıştır düğmesini seçin ve gerekirse Çözümle seçeneklerini yapılandırın:

Document Intelligence Studio'yu deneyin.
Desteklenen diller ve yerel ayarlar
Desteklenen dillerin tam listesi için Dil Desteği— belge çözümleme modelleri sayfamıza bakın.
Veri ayıklama
Not
Microsoft Word ve HTML dosyası v3.1 ve sonraki sürümlerde desteklenir. PDF ve görüntülerle karşılaştırıldığında aşağıdaki özellikler desteklenmez:
- Her sayfa nesnesiyle açı, genişlik/yükseklik ve birim yoktur.
- Algılanan her nesne için sınırlayıcı çokgen veya sınırlayıcı bölge yoktur.
- Sayfa aralığı (
pages) parametre olarak desteklenmez. - Nesne yok
lines.
Sayfalar
Sayfalar koleksiyonu, belgedeki sayfaların listesidir. Her sayfa belge içinde sıralı olarak temsil edilir ve sayfanın döndürülmüş olup olmadığını ve genişlik ile yüksekliği (piksel cinsinden boyutlar) gösteren yönlendirme açısını içerir. Model çıkışındaki sayfa birimleri gösterildiği gibi hesaplanır:
| Dosya biçimi | Hesaplanan sayfa birimi | Toplam sayfa sayısı |
|---|---|---|
| Görüntüler (JPEG/JPG, PNG, BMP, HEIF) | Her resim = 1 sayfa birimi | Toplam resim sayısı |
| PDF ' deki her sayfa = 1 sayfa birimi | PDF'deki toplam sayfa sayısı | |
| TIFF | TIFF = 1 sayfa birimindeki her resim | TIFF'deki toplam görüntü sayısı |
| Word (DOCX) | En fazla 3.000 karakter = 1 sayfa birimi, eklenmiş veya bağlantılı görüntüler desteklenmez | Her biri en fazla 3.000 karakterden oluşan toplam sayfa sayısı |
| Excel (XLSX) | Her çalışma sayfası = 1 sayfa birimi, eklenmiş veya bağlı görüntüler desteklenmez | Toplam çalışma sayfası |
| PowerPoint (PPTX) | Her slayt = 1 sayfalık birim, eklenmiş veya bağlı görüntüler desteklenmez | Toplam slayt sayısı |
| HTML | En fazla 3.000 karakter = 1 sayfa birimi, eklenmiş veya bağlantılı görüntüler desteklenmez | Her biri en fazla 3.000 karakterden oluşan toplam sayfa sayısı |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
# Analyze pages.
for page in result.pages:
print(f"----Analyzing document from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
# Analyze pages.
for page in result.pages:
print(f"----Analyzing document from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
Metin ayıklama için sayfaları seçme
Çok sayfalı büyük PDF belgeleri için, metin ayıklama için belirli sayfa numaralarını veya sayfa aralıklarını belirtmek üzere sorgu parametresini kullanın pages .
Paragraf
Belge Zekası'ndaki Okuma OCR modeli, koleksiyondaki paragraphs tanımlanan tüm metin bloklarını altında analyzeResultsen üst düzey nesne olarak ayıklar. Bu koleksiyondaki her girdi bir metin bloğunu temsil eder ve ayıklanan metni ve sınırlayıcı polygon koordinatları içerircontent. Bilgiler, span belgenin tam metnini içeren üst düzey content özellik içindeki metin parçasını gösterir.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Metin, satır ve sözcükler
Okuma OCR modeli, yazdırma ve el yazısı stil metinlerini ve wordsolarak lines ayıklar. Model, sınırlayıcı polygon koordinatlar ve confidence ayıklanan sözcükler için çıkış oluşturur. Koleksiyon, styles algılanırsa satırlar için el yazısı stilini ve ilişkili metne işaret eden aralıkları içerir. Bu özellik desteklenen el yazısı diller için geçerlidir.
Microsoft Word, Excel, PowerPoint ve HTML için, Belge Zekası Okuma modeli v3.1 ve sonraki sürümler tüm eklenmiş metni olduğu gibi ayıklar. Metinler sözcük ve paragraf olarak eklenir. Eklenmiş görüntüler desteklenmez.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
# Analyze lines.
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has {len(words)} words and text '{line.content}' within bounding polygon '{format_polygon(line.polygon)}'"
)
# Analyze words.
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
# Analyze lines.
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has {len(words)} words and text '{line.content}' within bounding polygon '{line.polygon}'"
)
# Analyze words.
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
Metin satırları için el yazısı stili
Yanıt, her metin satırının el yazısı stilinde olup olmadığını ve güvenilirlik puanını sınıflandırmayı içerir. Daha fazla bilgi için bkz. El yazısı dil desteği. Aşağıdaki örnekte örnek bir JSON kod parçacığı gösterilmektedir.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Yazı tipi/stil eklentisi özelliğini etkinleştirdiyseniz, nesnenin bir parçası styles olarak yazı tipi/stil sonucunu da alırsınız.
Sonraki adımlar
Belge Zekası hızlı başlangıcını tamamlama:
REST API'mizi keşfedin:
GitHub'da daha fazla örnek bulun:
GitHub'da daha fazla örnek bulun:
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin