Belge Zekası düzen modeli, Belge Zekası bulutunda kullanılabilen gelişmiş bir makine öğrenmesi tabanlı belge analizi API'sidir. Belgeleri çeşitli biçimlerde almanıza ve belgelerin yapılandırılmış veri gösterimlerini döndürmenize olanak tanır. Metinleri, tabloları, seçim işaretlerini ve belge yapısını ayıklamak için güçlü Optik Karakter Tanıma (OCR) özelliklerimizin gelişmiş bir sürümünü derin öğrenme modelleriyle birleştirir.
Belge yapısı düzen analizi
Belge yapısı düzen analizi, ilgilendiğiniz bölgeleri ve aralarındaki ilişkileri ayıklamak için bir belgeyi analiz etme işlemidir. Amaç, daha iyi anlamsal anlayış modelleri oluşturmak için sayfadan metin ve yapısal öğeleri ayıklamaktır. Belge düzeninde iki tür rol vardır:
Geometrik roller: Metin, tablolar, şekiller ve seçim işaretleri geometrik rollere örnektir.
Mantıksal roller: Başlıklar, başlıklar ve alt bilgiler, metinlerin mantıksal rollerine örnektir.
Aşağıdaki çizimde örnek bir sayfanın görüntüsündeki tipik bileşenler gösterilmektedir.
Dağıtım seçenekleri
Belge Yönetim Bilgileri v4.0: 2024-11-30 (GA) aşağıdaki araçları, uygulamaları ve kitaplıkları destekler:
Document Intelligence v4.0: 2024-11-30 (GA) düzen modeli aşağıdaki dosya biçimlerini destekler:
Model
PDF
Resim: JPEG/JPG, PNG, BMP, TIFF, HEIF
Microsoft Office: Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTML
Düzen
✔
✔
✔
Giriş gereksinimleri
En iyi sonuçları elde için belge başına tek bir net fotoğraf veya yüksek kaliteli tarama sağlayın.
PDF ve TIFF için en fazla 2.000 sayfa işlenebilir (ücretsiz katman aboneliğiyle yalnızca ilk iki sayfa işlenir).
PDF’leriniz parola korumalıysa göndermeden önce kilidi kaldırmanız gerekir.
Belgeleri analiz etmek için dosya boyutu ücretli (S0) katman için 500 MB ve 4 ücretsiz (F0) katman için MB'tır.
Görüntü boyutları 50 piksel x 50 piksel ile 10.000 piksel x 10.000 piksel arasında olmalıdır.
Ayıklanacak metnin en düşük yüksekliği 1024 x 768 piksel görüntü için 12 pikseldir. Bu boyut, yaklaşık 150 nokta/inç (DPI) nokta metnine karşılık gelir 8 .
Özel model eğitimi için eğitim verileri için en fazla sayfa sayısı özel şablon modeli için 500, özel sinir modeli için 50.000'dir.
Özel ayıklama modeli eğitimi için eğitim verilerinin toplam boyutu şablon modeli için 50 MB ve 1 sinir modeli için GB'tır.
Özel sınıflandırma modeli eğitimi için eğitim verilerinin toplam boyutu en fazla 10.000 sayfa ile GB'tır 1 . (GA) için 2024-11-30 , en fazla 10.000 sayfa ile eğitim verilerinin toplam boyutu GB'tır 2 .
Model kullanımı, kotalar ve hizmet sınırları hakkında daha fazla bilgi için bkz. hizmet sınırları.
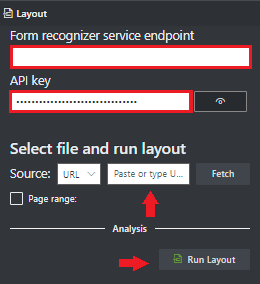
Düzen modelini kullanmaya başlama
Metin, tablo, tablo üst bilgileri, seçim işaretleri ve yapı bilgileri gibi verilerin Belge Yönetim Bilgileri kullanılarak belgelerden nasıl ayıklandığına bakın. Aşağıdaki kaynaklara ihtiyacınız vardır:
Azure portalında bir Belge Zekası örneği. Hizmeti denemek için ücretsiz fiyatlandırma katmanını (F0) kullanabilirsiniz. Kaynağınız dağıtıldıktan sonra anahtarınızı ve uç noktanızı almak için Kaynağa git'i seçin.
Anahtarınızı ve uç noktanızı aldıktan sonra, Belge Zekası uygulamalarınızı derlemek ve dağıtmak için aşağıdaki geliştirme seçeneklerini kullanabilirsiniz:
Düzen modeli, belgelerinizdeki yapısal öğeleri ayıklar. İzleyebileceğiniz bu yapısal öğelerin açıklamaları ve bunları belge girişinizden nasıl ayıkladığınıza ilişkin yönergeler verilmiştir:
Sayfalar koleksiyonu, belgedeki sayfaların listesidir. Her sayfa belge içinde sıralı olarak temsil edilir ve sayfanın döndürülmüş olup olmadığını ve genişlik ile yüksekliği (piksel cinsinden boyutlar) gösteren yönlendirme açısını içerir. Model çıkışındaki sayfa birimleri gösterildiği gibi hesaplanır:
Dosya biçimi
Hesaplanan sayfa birimi
Toplam sayfa sayısı
Görüntüler (JPEG/JPG, PNG, BMP, HEIF)
Her resim = 1 sayfa birimi
Toplam resim sayısı
PDF
PDF ' deki her sayfa = 1 sayfa birimi
PDF'deki toplam sayfa sayısı
TIFF
TIFF = 1 sayfa birimindeki her resim
TIFF'deki toplam görüntü sayısı
Word (DOCX)
En fazla 3.000 karakter = 1 sayfa birimi, eklenmiş veya bağlantılı görüntüler desteklenmez
Her biri en fazla 3.000 karakterden oluşan toplam sayfa sayısı
Excel (XLSX)
Her çalışma sayfası = 1 sayfa birimi, eklenmiş veya bağlı görüntüler desteklenmez
Toplam çalışma sayfası
PowerPoint (PPTX)
Her slayt = 1 sayfalık birim, eklenmiş veya bağlı görüntüler desteklenmez
Toplam slayt sayısı
HTML
En fazla 3.000 karakter = 1 sayfa birimi, eklenmiş veya bağlantılı görüntüler desteklenmez
Her biri en fazla 3.000 karakterden oluşan toplam sayfa sayısı
# Analyze pages.for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
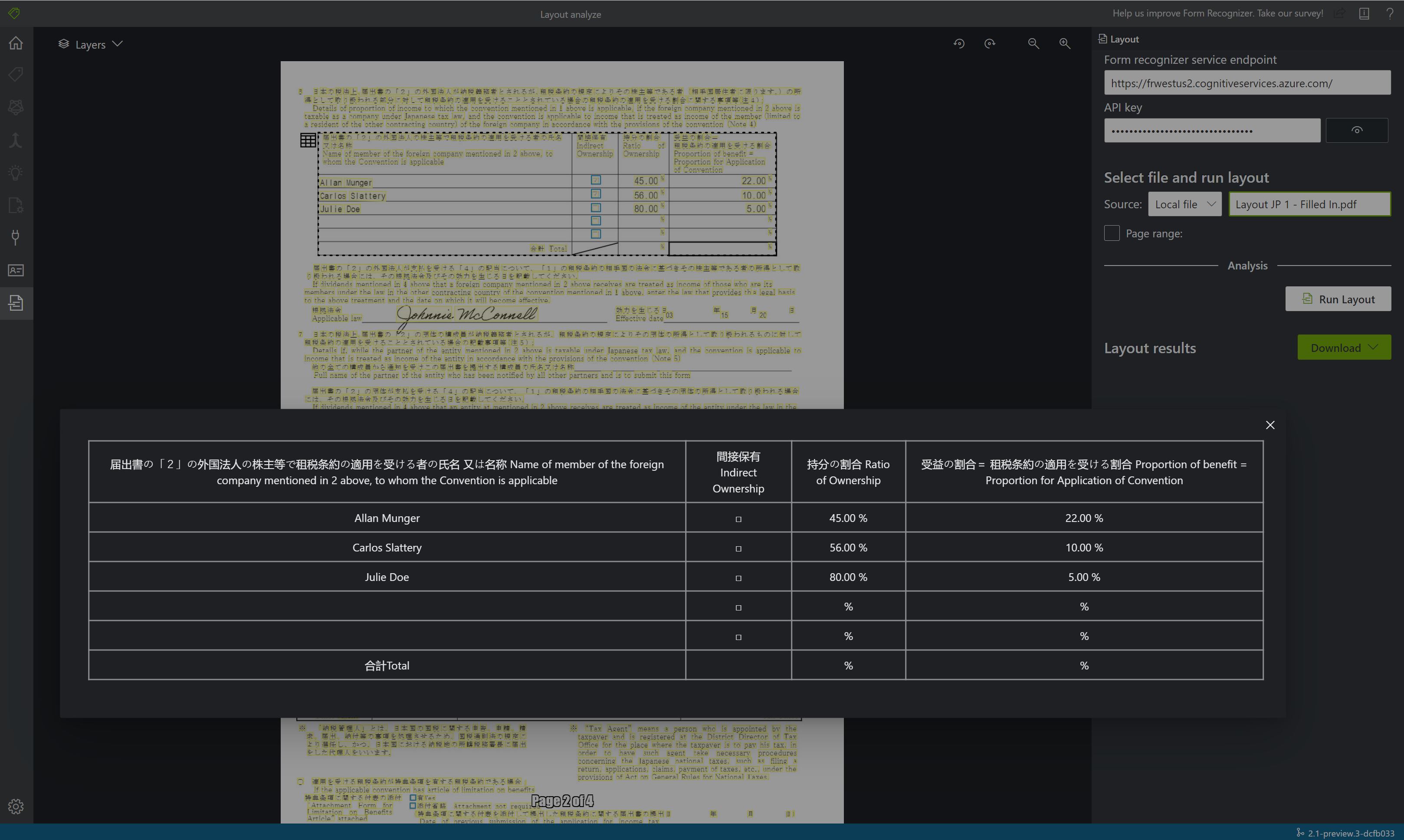
Çok sayfalı büyük belgeler için, belirli sayfa numaralarını veya metin ayıklama için sayfa aralıklarını belirtmek üzere sorgu parametresini kullanın pages .
Paragraf
Düzen modeli, koleksiyondaki paragraphs tanımlanan tüm metin bloklarını altında analyzeResultsen üst düzey nesne olarak ayıklar. Bu koleksiyondaki her girdi bir metin bloğunu ve .. /, ayıklanan metni olarakcontentve sınırlayıcı polygon koordinatları içerir. Bilgiler, span belgenin tam metnini içeren en üst düzey content özellik içindeki metin parçasına işaret eder.
JSON
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Paragraf rolleri
Yeni makine öğrenmesi tabanlı sayfa nesnesi algılama, başlıklar, bölüm başlıkları, sayfa üst bilgileri, sayfa alt bilgileri ve daha fazlası gibi mantıksal rolleri ayıklar. Belge Yönetim Bilgileri Düzeni modeli, koleksiyondaki paragraphs belirli metin bloklarını model tarafından tahmin edilen özelleştirilmiş rolü veya türüyle atar. Daha zengin bir anlam analizi için ayıklanan içeriğin düzenini anlamanıza yardımcı olması için yapılandırılmamış belgelerle paragraf rollerini kullanmak en iyisidir. Aşağıdaki paragraf rolleri desteklenir:
Belge Yönetim Bilgileri'ndeki belge düzeni modeli, yazdırma ve el yazısı stil metinlerini ve wordsolarak lines ayıklar. Koleksiyon styles .. /, ilişkili metne işaret eden yayılma alanlarıyla birlikte algılanırsa satırlar için herhangi bir el yazısı stili içerir. Bu özellik desteklenen el yazısı diller için geçerlidir.
Microsoft Word, Excel, PowerPoint ve HTML için, Belge Zekası v4.0 2024-11-30 (GA) Düzeni modeli, ekli tüm metni olduğu gibi ayıklar. Metinler sözcük ve paragraf olarak ayıklanır. Eklenmiş görüntüler desteklenmez.
# Analyze lines.if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "f"within bounding polygon '{line.polygon}'"
)
# Analyze words.for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
Metin satırları için el yazısı stili
Yanıt .. /, her metin satırının el yazısı stilinde olup olmadığını ve güvenilirlik puanını sınıflandırmayı içerir. Daha fazla bilgi için. Bkz. El yazısı dil desteği. Aşağıdaki örnekte örnek bir JSON kod parçacığı gösterilmektedir.
Yazı tipi/stil eklentisi özelliğini etkinleştirirseniz, nesnenin bir parçası styles olarak yazı tipi/stil sonucunu da alırsınız.
Seçim işaretleri
Düzen modeli, belgelerden seçim işaretlerini de ayıklar. Ayıklanan seçim işaretleri her sayfa için koleksiyon içinde pages görünür. Sınırlayıcı polygon, confidenceve seçimini state (selected/unselected) içerir. Metin gösterimi (yani :selected: ve :unselected) başlangıç dizini (offset) olarak da eklenir ve length belgenin tam metnini içeren en üst düzey content özelliğe başvurur.
# Analyze selection marks.if page.selection_marks:
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "f"'{selection_mark.polygon}' and has a confidence of {selection_mark.confidence}"
)
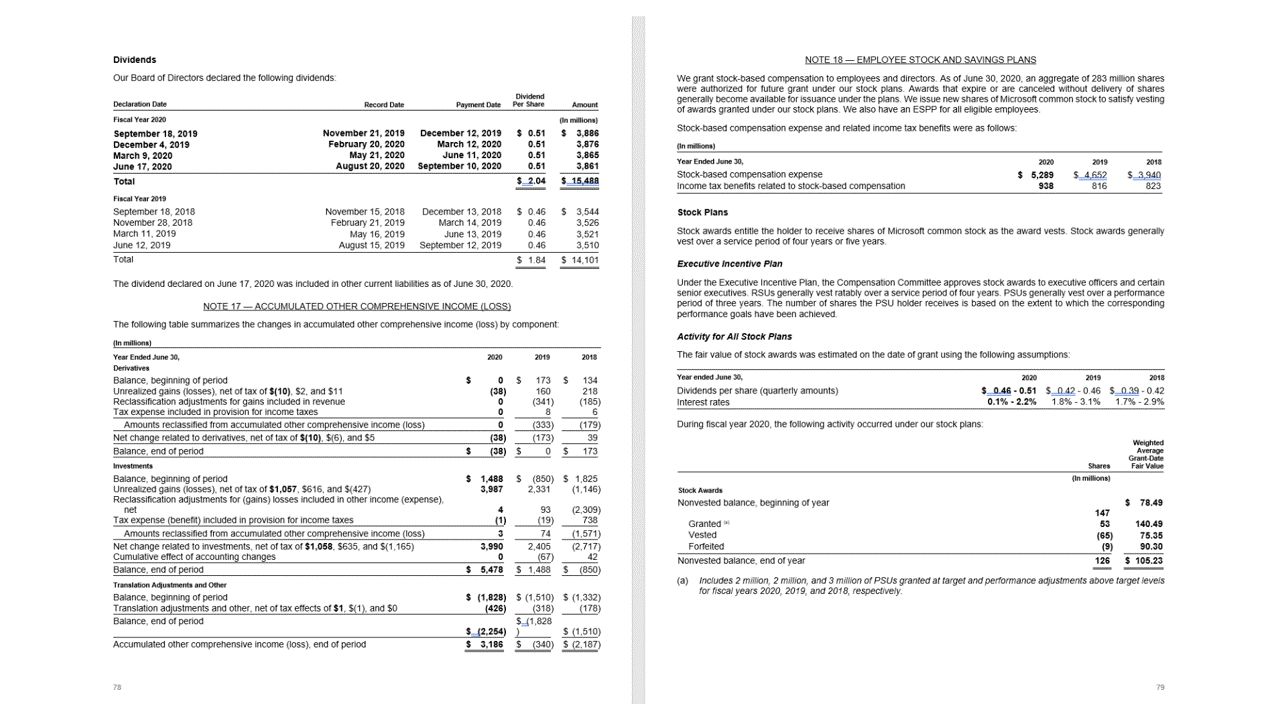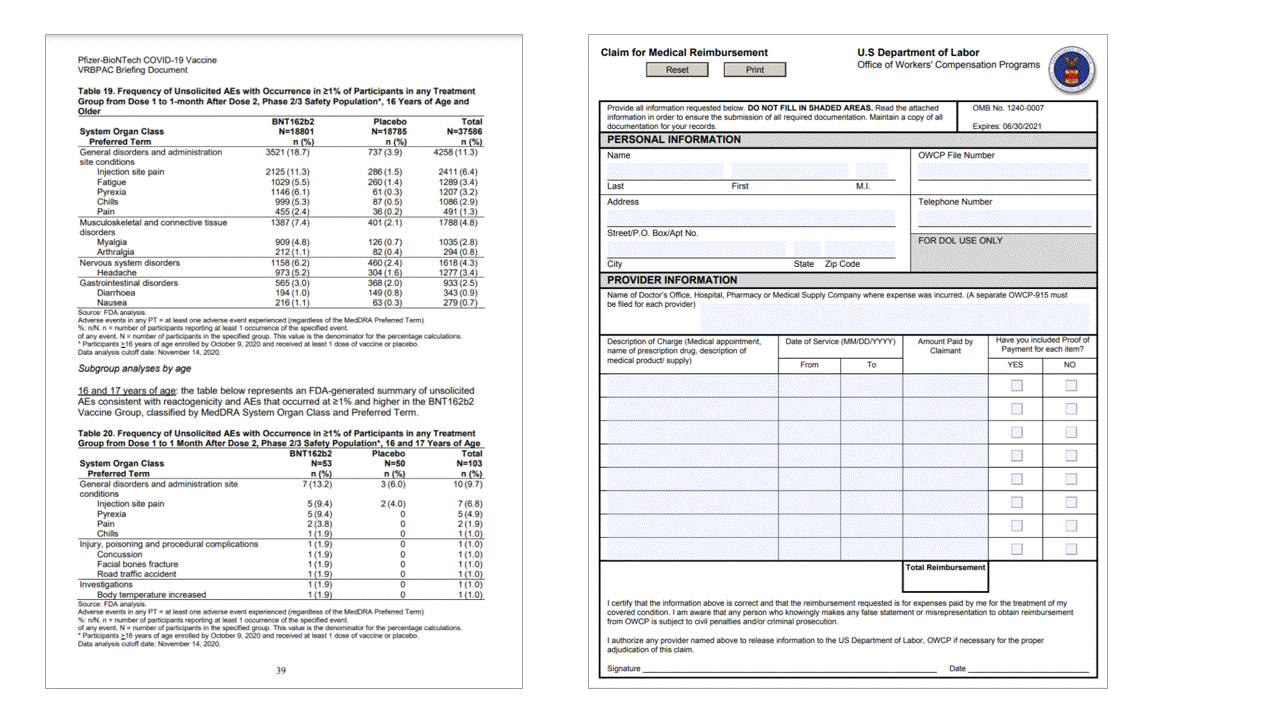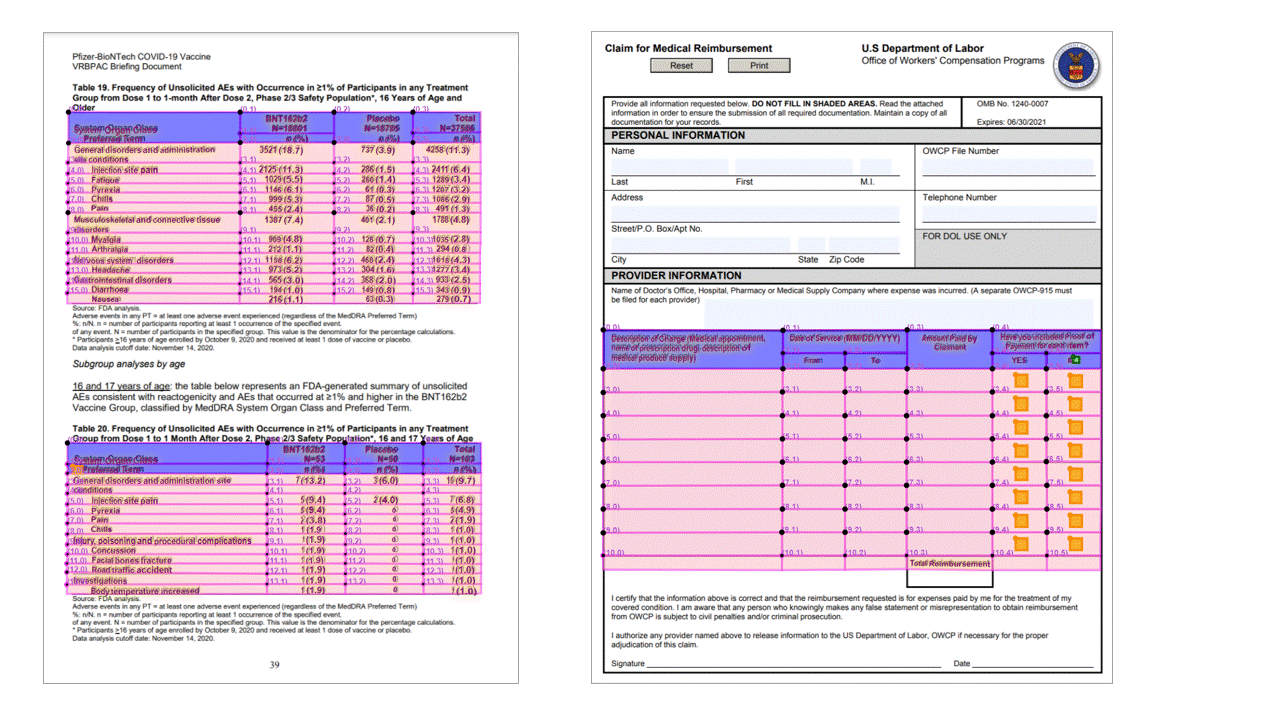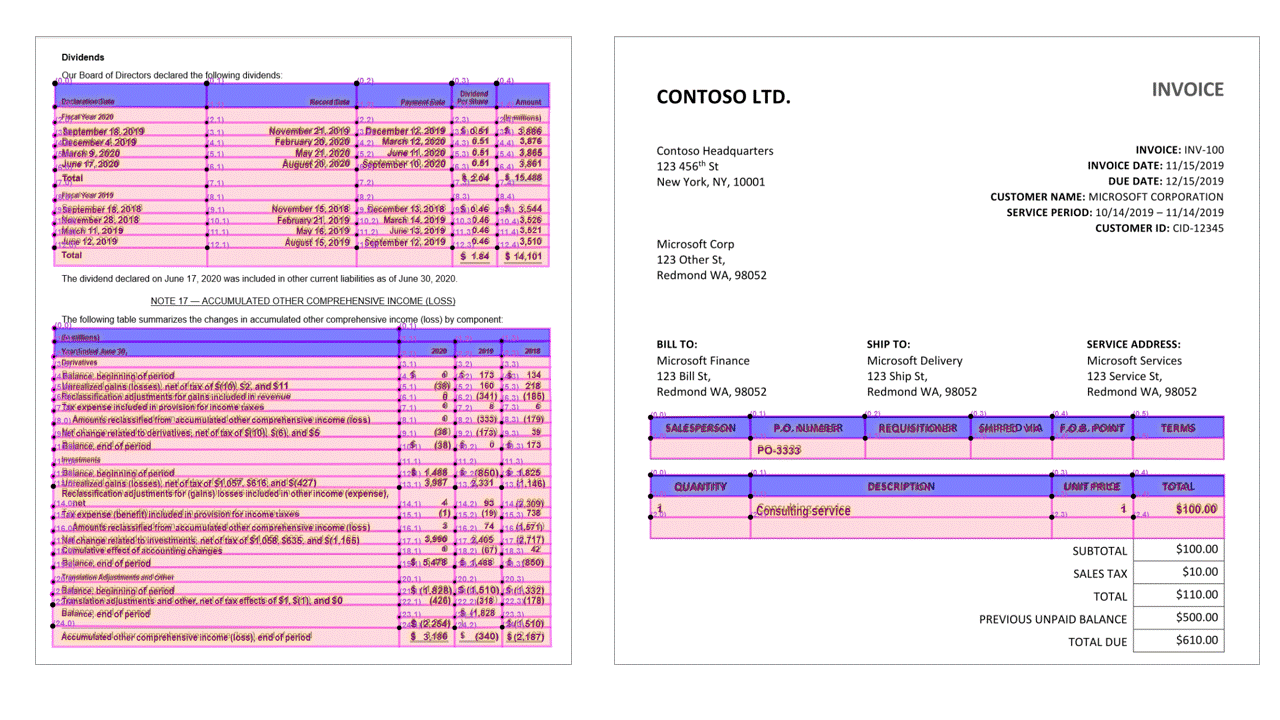
Tabloları ayıklamak, genellikle tablo olarak biçimlendirilmiş büyük hacimli verileri içeren belgeleri işlemek için önemli bir gereksinimdir. Düzen modeli, JSON çıkışının pageResults bölümündeki tabloları ayıklar. Ayıklanan tablo bilgileri.. /sütun ve satır sayısını, satır aralığını ve sütun aralığını içerir. Sınırlayıcı çokgeni olan her hücre, alanın bir columnHeader olarak tanınıp tanınmadığı bilgisinin yanı sıra çıkıştır. Model, döndürülen tabloları ayıklamayı destekler. Her tablo hücresi satır ve sütun dizinini ve sınırlayıcı çokgen koordinatlarını içerir. Hücre metni için model, başlangıç dizinini span (offset ) içeren bilgileri verir. Model, belgedeki tam metni içeren en üst düzey içeriğin içinde çıkışını da length verir.
Belge Zekası balya ayıklama özelliğini kullanırken göz önünde bulundurmanız gereken birkaç faktör şunlardır:
Ayıklamak istediğiniz veriler tablo olarak sunuluyor mu ve tablo yapısı anlamlı mı?
Veriler tablo biçiminde değilse veriler iki boyutlu bir kılavuza sığabilir mi?
Tablolarınız birden çok sayfaya yayılsın mı? Bu durumda, tüm sayfaları etiketlemek zorunda kalmamak için Belge Yönetim Bilgileri'ne göndermeden önce PDF'yi sayfalara bölün. Analizden sonra sayfaları tek bir tabloya işleyin.
Giriş dosyası XLSX ise tablo analizi desteklenmez.
2024-11-30 (GA) için, şekiller ve tablolar için sınırlayıcı bölgeler yalnızca temel içeriği kapsar ve ilişkili açıklamalı alt yazıları ve dipnotları hariç tutar.
if result.tables:
for table_idx, table in enumerate(result.tables):
print(f"Table # {table_idx} has {table.row_count} rows and "f"{table.column_count} columns")
if table.bounding_regions:
for region in table.bounding_regions:
print(f"Table # {table_idx} location on page: {region.page_number} is {region.polygon}")
# Analyze cells.for cell in table.cells:
print(f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'")
if cell.bounding_regions:
for region in cell.bounding_regions:
print(f"...content on page {region.page_number} is within bounding polygon '{region.polygon}'")
Düzen API'si, ayıklanan metnin çıkışını markdown biçiminde verebilir. Markdown'da çıkış biçimini belirtmek için öğesini outputContentFormat=markdown kullanın. Markdown içeriği, bölümün bir parçası olarak çıktılanır content .
Not
v4.0 2024-11-30 (GA) için, birleştirilmiş hücrelerin, çok satırlı üst bilgilerin vb. işlenmesini sağlamak için tabloların gösterimi HTML tabloları olarak değiştirilir. İlgili bir diğer değişiklik de Unicode onay kutusu karakterleri ☒ kullanmak ve ☐ :selected: ve :unselected: yerine seçim işaretleri kullanmaktır. Bunun, seçim işareti alanlarının içeriğinin :selected değerini içereceği anlamına geldiğini unutmayın: bunların yayılma alanları üst düzey yayılma alanındaki Unicode karakterlerine başvuruda bulunsa bile.
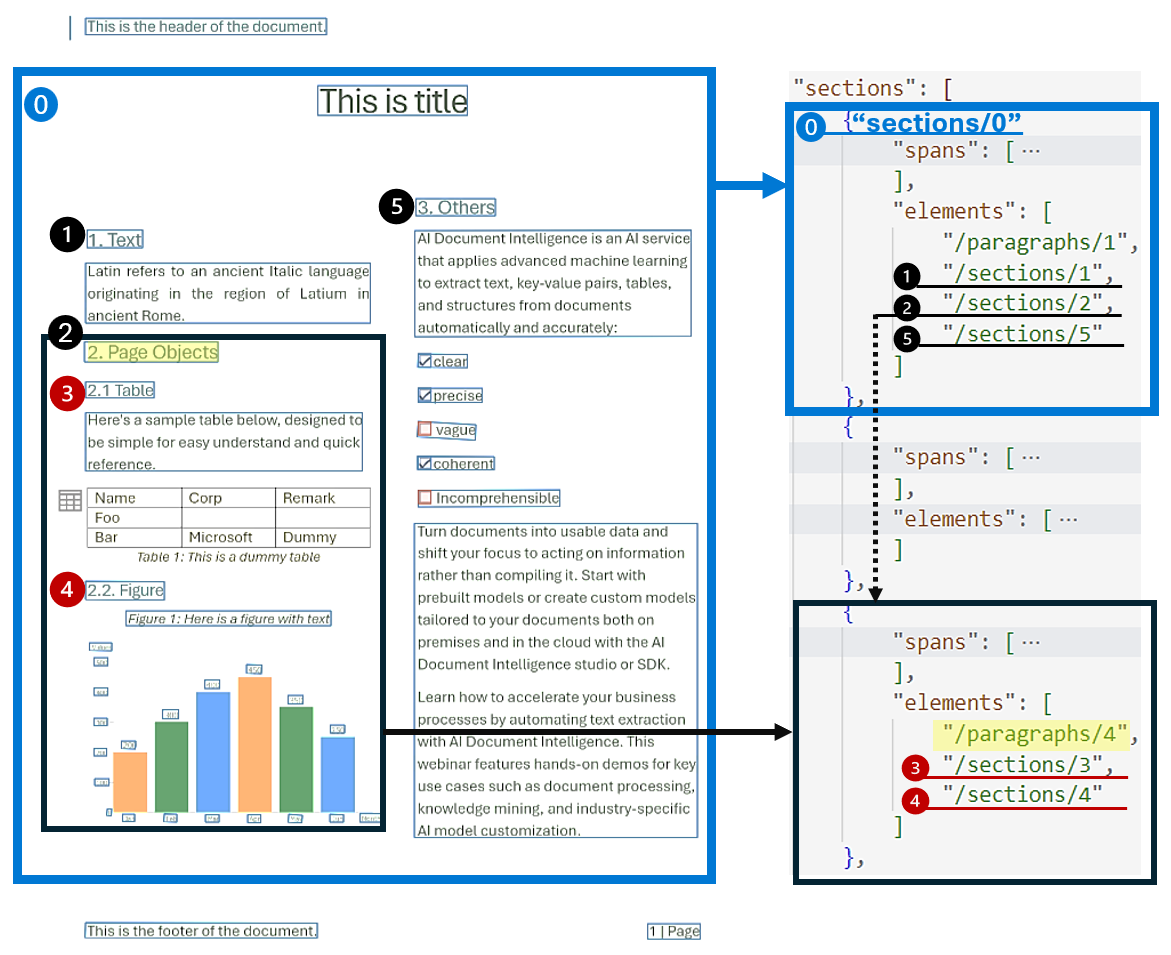
PageHeader="This is the header of the document."
This is title
===# 1\. Text
Latin refers to an ancient Italic language originating in the region of Latium in ancient Rome.
# 2\. Page Objects## 2.1 Table
Here's a sample table below, designed to be simple for easy understand and quick reference.
| Name | Corp | Remark |
| - | - | - |
| Foo | | |
| Bar | Microsoft | Dummy |
Table 1: This is a dummy table
## 2.2. Figure<figure><figcaption>
Figure 1: Here is a figure with text
</figcaption>

FigureContent="500 450 400 400 350 250 200 200 200- Feb"
</figure># 3\. Others
Al Document Intelligence is an Al service that applies advanced machine learning to extract text, key-value pairs, tables, and structures from documents automatically and accurately:
:selected:
clear
:selected:
precise
:unselected:
vague
:selected:
coherent
:unselected:
Incomprehensible
Turn documents into usable data and shift your focus to acting on information rather than compiling it. Start with prebuilt models or create custom models tailored to your documents both on premises and in the cloud with the Al Document Intelligence studio or SDK.
Learn how to accelerate your business processes by automating text extraction with Al Document Intelligence. This webinar features hands-on demos for key use cases such as document processing, knowledge mining, and industry-specific Al model customization.
PageFooter="This is the footer of the document."
PageFooter="1 | Page"
Rakam
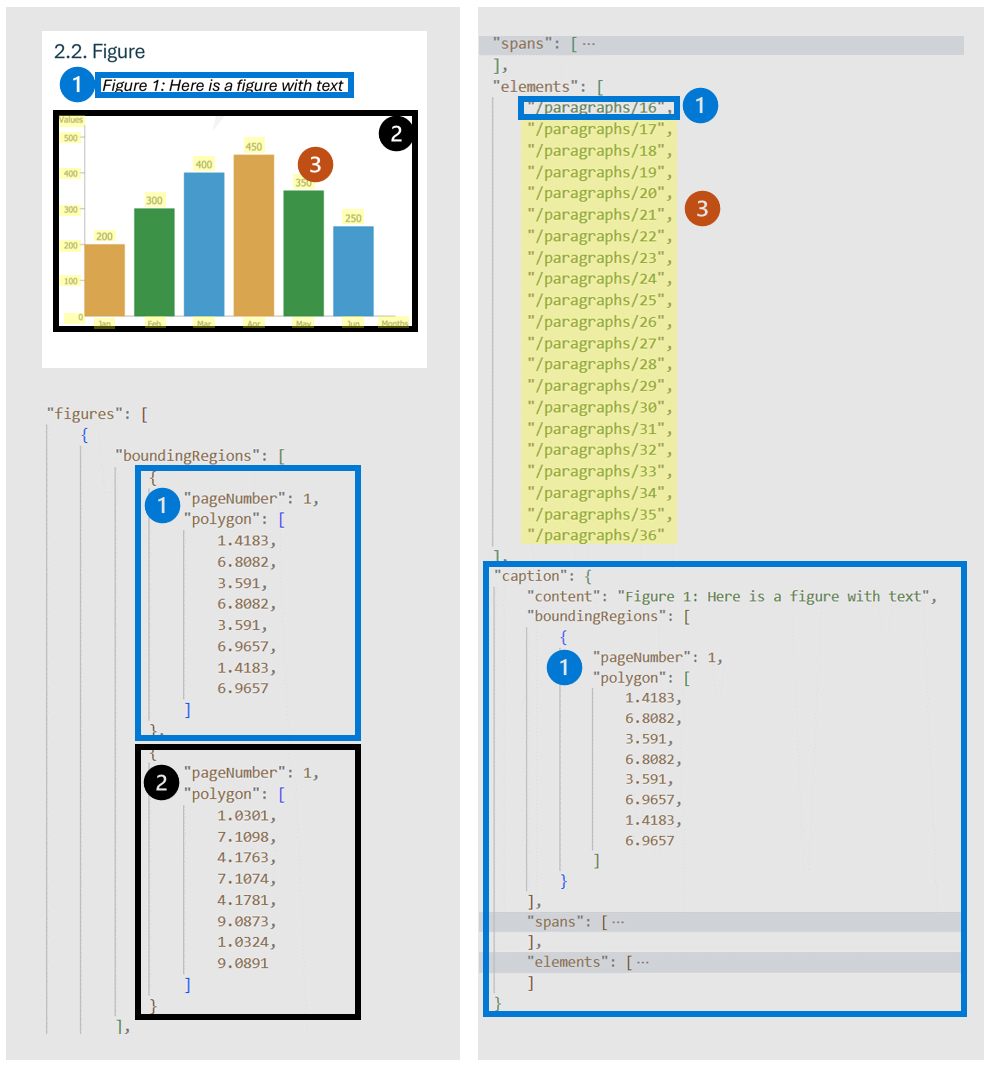
Belgelerdeki şekiller (grafikler, resimler) metin içeriğinin tamamlanması ve geliştirilmesinde önemli bir rol oynar ve karmaşık bilgilerin anlaşılmasına yardımcı olan görsel gösterimler sağlar. Düzen modeli tarafından algılanan şekiller nesnesinin temel özellikleri boundingRegions vardır (belge sayfalarındaki şeklin uzamsal konumları, sayfa numarası ve şeklin sınırını özetleyen çokgen koordinatlar dahil), spans (şekille ilgili metin aralıklarının ayrıntıları, belgenin metni içindeki uzaklıklarını ve uzunluklarını belirtme. Bu bağlantı, şeklin ilgili metin bağlamıyla, elements (belgedeki şekille ilgili veya açıklamalı metin öğelerinin veya paragrafların tanımlayıcıları) ve caption varsa ilişkilendirmeye yardımcı olur.
İlk analiz işlemi sırasında output=figures belirtildiğinde, hizmet aracılığıyla /analyeResults/{resultId}/figures/{figureId}erişilebilen tüm algılanan şekiller için kırpılmış görüntüler oluşturur.
FigureId her şekil nesnesine eklenir ve sayfa başına bir taneye sıfırlandığına yönelik {pageNumber}.{figureIndex}figureIndex belgelenmemiş bir kurala uyar.
Not
v4.0 2024-11-30 (GA) için, şekiller ve tablolar için sınırlayıcı bölgeler yalnızca temel içeriği kapsar ve ilişkili açıklamalı alt yazıları ve dipnotları hariç tutar.
# Analyze figures.if result.figures:
for figures_idx,figures in enumerate(result.figures):
print(f"Figure # {figures_idx} has the following spans:{figures.spans}")
for region in figures.bounding_regions:
print(f"Figure # {figures_idx} location on page:{region.page_number} is within bounding polygon '{region.polygon}'")
{
"figures": [
{
"id": "{figureId}",
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15",
...
],
"caption": {
"content": "Here is a figure with some text",
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15"
]
}
}
]
}
Bölümler
Hiyerarşik belge yapısı analizi, kapsamlı belgelerin düzenlenmesi, anlaşılması ve işlenmesinde çok önemlidir. Bu yaklaşım, kavramayı artırmak, gezinmeyi kolaylaştırmak ve bilgi alımını geliştirmek için uzun belgeleri sembolik olarak segmentlere ayırmak için çok önemlidir. Belge oluşturucu yapay zekada Alma Artırılmış Neslinin (RAG) gelişi, hiyerarşik belge yapısı analizinin öneminin altını çizer. Düzen modeli, çıkıştaki bölümleri ve alt bölümleri destekler ve bu da her bölümdeki bölümlerin ve nesnenin ilişkisini tanımlar. Hiyerarşik yapı her bölümde korunur elements . Markdown'da bölümleri ve alt bölümleri kolayca almak için çıkış yanıtını markdown biçiminde kullanabilirsiniz.
Bu içerik şunlar için geçerlidir:v3.1 (GA) | En son sürüm: v4.0 (GA) | Önceki sürümler: v3.0v2.1
Bu içerik şunlar için geçerlidir:v3.0 (GA) | En son sürümler: v4.0 (GA) v3.1 | Önceki sürüm:v2.1
Bu içerik şunlar için geçerlidir:v2.1 | En son sürüm:v4.0 (GA)
Belge Zekası düzen modeli, Belge Zekası bulutunda kullanılabilen gelişmiş bir makine öğrenmesi tabanlı belge analizi API'sidir. Belgeleri çeşitli biçimlerde almanıza ve belgelerin yapılandırılmış veri gösterimlerini döndürmenize olanak tanır. Metinleri, tabloları, seçim işaretlerini ve belge yapısını ayıklamak için güçlü Optik Karakter Tanıma (OCR) özelliklerimizin gelişmiş bir sürümünü derin öğrenme modelleriyle birleştirir.
Belge düzeni analizi
Belge yapısı düzen analizi, ilgilendiğiniz bölgeleri ve aralarındaki ilişkileri ayıklamak için bir belgeyi analiz etme işlemidir. Amaç, daha iyi anlamsal anlayış modelleri oluşturmak için sayfadan metin ve yapısal öğeleri ayıklamaktır. Belge düzeninde iki tür rol vardır:
Geometrik roller: Metin, tablolar, şekiller ve seçim işaretleri geometrik rollere örnektir.
Mantıksal roller: Başlıklar, başlıklar ve alt bilgiler, metinlerin mantıksal rollerine örnektir.
Aşağıdaki çizimde örnek bir sayfanın görüntüsündeki tipik bileşenler gösterilmektedir.
Desteklenen diller ve yerel ayarlar
Desteklenen dillerin tam listesi için Dil Desteği— belge çözümleme modelleri sayfamıza bakın.
Document Intelligence v2.1 aşağıdaki araçları, uygulamaları ve kitaplıkları destekler:
Microsoft Office: Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTML
Okundu
✔
✔
✔
Düzen
✔
✔
✔
Genel Belge
✔
✔
Önceden oluşturulmuş
✔
✔
Özel ayıklama
✔
✔
Özel sınıflandırma
✔
✔
✔
En iyi sonuçları elde için belge başına tek bir net fotoğraf veya yüksek kaliteli tarama sağlayın.
PDF ve TIFF için en fazla 2.000 sayfa işlenebilir (ücretsiz katman aboneliğiyle yalnızca ilk iki sayfa işlenir).
Belgeleri analiz etmek için dosya boyutu ücretli (S0) katman için 500 MB ve 4 ücretsiz (F0) katman için MB'tır.
Görüntü boyutları 50 piksel x 50 piksel ile 10.000 piksel x 10.000 piksel arasında olmalıdır.
PDF’leriniz parola korumalıysa göndermeden önce kilidi kaldırmanız gerekir.
Ayıklanacak metnin en düşük yüksekliği 1024 x 768 piksel görüntü için 12 pikseldir. Bu boyut, yaklaşık 150 nokta/inç (DPI) nokta metnine karşılık gelir 8 .
Özel model eğitimi için eğitim verileri için en fazla sayfa sayısı özel şablon modeli için 500, özel sinir modeli için 50.000'dir.
Özel ayıklama modeli eğitimi için eğitim verilerinin toplam boyutu şablon modeli için 50 MB ve 1 sinir modeli için GB'tır.
Özel sınıflandırma modeli eğitimi için eğitim verilerinin toplam boyutu en fazla 10.000 sayfa ile GB'tır 1 . 2024-11-30 (GA) için eğitim verilerinin toplam boyutu gb ve en fazla 10.000 sayfadır 2 .
Giriş kılavuzu
Desteklenen dosya biçimleri: JPEG, PNG, PDF ve TIFF.
Desteklenen sayfa sayısı: PDF ve TIFF için en fazla 2.000 sayfa işlenir. Ücretsiz katman aboneleri için yalnızca ilk iki sayfa işlenir.
Desteklenen dosya boyutu: Dosya boyutu 50 MB'tan az ve boyutlar en az 50 x 50 piksel ve en fazla 10.000 x 10.000 piksel olmalıdır.
Kullanmaya başlayın
Metin, tablo, tablo üst bilgileri, seçim işaretleri ve yapı bilgileri gibi verilerin Belge Yönetim Bilgileri kullanılarak belgelerden nasıl ayıklandığına bakın. Aşağıdaki kaynaklara ihtiyacınız vardır:
Azure portalında bir Belge Zekası örneği. Hizmeti denemek için ücretsiz fiyatlandırma katmanını (F0) kullanabilirsiniz. Kaynağınız dağıtıldıktan sonra anahtarınızı ve uç noktanızı almak için Kaynağa git'i seçin.
Anahtarınızı ve uç noktanızı aldıktan sonra, Belge Zekası uygulamalarınızı derlemek ve dağıtmak için aşağıdaki geliştirme seçeneklerini kullanabilirsiniz:
Not
Document Intelligence Studio, v3.0 API'leri ve sonraki sürümlerle kullanılabilir.
Düzen modeli, belgelerinizdeki yapısal öğeleri ayıklar. İzleyebileceğiniz bu yapısal öğelerin açıklamaları ve bunları belge girişinizden nasıl ayıkladığınıza ilişkin yönergeler verilmiştir:
Düzen modeli, belgelerinizdeki yapısal öğeleri ayıklar. İzleyebileceğiniz bu yapısal öğelerin açıklamaları ve bunları belge girişinizden nasıl ayıkladığınıza ilişkin yönergeler verilmiştir:
Sayfalar koleksiyonu, belgedeki sayfaların listesidir. Her sayfa, belge içinde sıralı olarak temsil edilir ve .. /, sayfanın döndürülmüş olup olmadığını ve genişlik ve yüksekliği (piksel cinsinden boyutlar) gösteren yönlendirme açısını içerir. Model çıkışındaki sayfa birimleri gösterildiği gibi hesaplanır:
Dosya biçimi
Hesaplanan sayfa birimi
Toplam sayfa sayısı
Görüntüler (JPEG/JPG, PNG, BMP, HEIF)
Her resim = 1 sayfa birimi
Toplam resim sayısı
PDF
PDF ' deki her sayfa = 1 sayfa birimi
PDF'deki toplam sayfa sayısı
TIFF
TIFF = 1 sayfa birimindeki her resim
TIFF'deki toplam görüntü sayısı
Word (DOCX)
En fazla 3.000 karakter = 1 sayfa birimi, eklenmiş veya bağlantılı görüntüler desteklenmez
Her biri en fazla 3.000 karakterden oluşan toplam sayfa sayısı
Excel (XLSX)
Her çalışma sayfası = 1 sayfa birimi, eklenmiş veya bağlı görüntüler desteklenmez
Toplam çalışma sayfası
PowerPoint (PPTX)
Her slayt = 1 sayfalık birim, eklenmiş veya bağlı görüntüler desteklenmez
Toplam slayt sayısı
HTML
En fazla 3.000 karakter = 1 sayfa birimi, eklenmiş veya bağlantılı görüntüler desteklenmez
Her biri en fazla 3.000 karakterden oluşan toplam sayfa sayısı
# Analyze pages.for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
Çok sayfalı büyük belgeler için, belirli sayfa numaralarını veya metin ayıklama için sayfa aralıklarını belirtmek üzere sorgu parametresini kullanın pages .
Paragraf
Düzen modeli, koleksiyondaki paragraphs tanımlanan tüm metin bloklarını altında analyzeResultsen üst düzey nesne olarak ayıklar. Bu koleksiyondaki her girdi bir metin bloğunu ve .. /, ayıklanan metni olarakcontentve sınırlayıcı polygon koordinatları içerir. Bilgiler, span belgenin tam metnini içeren en üst düzey content özellik içindeki metin parçasına işaret eder.
JSON
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Paragraf rolü
Yeni makine öğrenmesi tabanlı sayfa nesnesi algılama, başlıklar, bölüm başlıkları, sayfa üst bilgileri, sayfa alt bilgileri ve daha fazlası gibi mantıksal rolleri ayıklar. Belge Yönetim Bilgileri Düzeni modeli, koleksiyondaki paragraphs belirli metin bloklarını model tarafından tahmin edilen özelleştirilmiş rolü veya türüyle atar. Daha zengin bir anlam analizi için ayıklanan içeriğin düzenini anlamanıza yardımcı olması için yapılandırılmamış belgelerle paragraf rollerini kullanmak en iyisidir. Aşağıdaki paragraf rolleri desteklenir:
Belge Yönetim Bilgileri'ndeki belge düzeni modeli, yazdırma ve el yazısı stil metinlerini ve wordsolarak lines ayıklar. Koleksiyon styles .. /, ilişkili metne işaret eden yayılma alanlarıyla birlikte algılanırsa satırlar için herhangi bir el yazısı stili içerir. Bu özellik desteklenen el yazısı diller için geçerlidir.
Microsoft Word, Excel, PowerPoint ve HTML için, Belge Zekası v4.0 2024-11-30 (GA) Düzeni modeli, ekli tüm metni olduğu gibi ayıklar. Metinler sözcük ve paragraf olarak ayıklanır. Eklenmiş görüntüler desteklenmez.
JSON
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
# Analyze lines.for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "f"within bounding polygon '{format_polygon(line.polygon)}'"
)
# Analyze words.for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
El yazısı stili
Yanıt .. /, her metin satırının el yazısı stilinde olup olmadığını ve güvenilirlik puanını sınıflandırmayı içerir. Daha fazla bilgi için. Bkz. El yazısı dil desteği. Aşağıdaki örnekte örnek bir JSON kod parçacığı gösterilmektedir.
Yazı tipi/stil eklentisi özelliğini etkinleştirirseniz, nesnenin bir parçası styles olarak yazı tipi/stil sonucunu da alırsınız.
Seçim işareti
Düzen modeli, belgelerden seçim işaretlerini de ayıklar. Ayıklanan seçim işaretleri her sayfa için koleksiyon içinde pages görünür. Sınırlayıcı polygon, confidenceve seçimini state (selected/unselected) içerir. Metin gösterimi (yani :selected: ve :unselected) başlangıç dizini (offset) olarak da eklenir ve length belgenin tam metnini içeren en üst düzey content özelliğe başvurur.
# Analyze selection marks.for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "f"'{format_polygon(selection_mark.polygon)}' and has a confidence of {selection_mark.confidence}"
)
Tabloları ayıklamak, genellikle tablo olarak biçimlendirilmiş büyük hacimli verileri içeren belgeleri işlemek için önemli bir gereksinimdir. Düzen modeli, JSON çıkışının pageResults bölümündeki tabloları ayıklar. Ayıklanan tablo bilgileri.. /sütun ve satır sayısını, satır aralığını ve sütun aralığını içerir. Sınırlayıcı çokgeni olan her hücre, alanın bir columnHeader olarak tanınıp tanınmadığı bilgisinin yanı sıra çıkıştır. Model, döndürülen tabloları ayıklamayı destekler. Her tablo hücresi satır ve sütun dizinini ve sınırlayıcı çokgen koordinatlarını içerir. Hücre metni için model, başlangıç dizinini span (offset ) içeren bilgileri verir. Model, belgedeki tam metni içeren en üst düzey içeriğin içinde çıkışını da length verir.
Belge Zekası balya ayıklama özelliğini kullanırken göz önünde bulundurmanız gereken birkaç faktör şunlardır:
Ayıklamak istediğiniz veriler tablo olarak sunuluyor mu ve tablo yapısı anlamlı mı?
Veriler tablo biçiminde değilse veriler iki boyutlu bir kılavuza sığabilir mi?
Tablolarınız birden çok sayfaya yayılsın mı? Bu durumda, tüm sayfaları etiketlemek zorunda kalmamak için Belge Yönetim Bilgileri'ne göndermeden önce PDF'yi sayfalara bölün. Analizden sonra sayfaları tek bir tabloya işleyin.
Giriş dosyası XLSX ise tablo analizi desteklenmez.
Belge Zekası v4.0 2024-11-30 (GA), yalnızca temel içeriği kapsayan ve ilişkili açıklamalı alt yazıları ve dipnotları dışlayan şekiller ve tablolar için sınırlayıcı bölgeleri destekler.
# Analyze tables.for table_idx, table in enumerate(result.tables):
print(
f"Table # {table_idx} has {table.row_count} rows and "f"{table.column_count} columns"
)
for region in table.bounding_regions:
print(
f"Table # {table_idx} location on page: {region.page_number} is {format_polygon(region.polygon)}"
)
for cell in table.cells:
print(
f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'"
)
for region in cell.bounding_regions:
print(
f"...content on page {region.page_number} is within bounding polygon '{format_polygon(region.polygon)}'"
)
Düzen modeli, belgelerdeki denetimler ve çaprazlar gibi ek açıklamaları ayıklar. Yanıt .. /, güvenilirlik puanı ve sınırlayıcı çokgen ile birlikte ek açıklama türünü içerir.
Sorgu parametresiyle readingOrder metin satırlarının çıkış sırasını belirtebilirsiniz. Aşağıdaki örnekte gösterildiği gibi daha insan dostu bir okuma sırası çıkışı için kullanın natural . Bu özellik yalnızca Latin dilleri için desteklenir.
Metin ayıklama için sayfa numarası veya aralık seçme
Çok sayfalı büyük belgeler için, belirli sayfa numaralarını veya metin ayıklama için sayfa aralıklarını belirtmek üzere sorgu parametresini kullanın pages . Aşağıdaki örnekte, tüm sayfalar (1-10) ve seçili sayfalar (3-6) olmak üzere her iki durumda da metin ayıklanmış 10 sayfalı bir belge gösterilmektedir.
Çözümle Düzenini Al Sonucu işlemi
İkinci adım, Çözümle Düzenini Al Sonucu işlemini çağırmaktır. Bu işlem, işlemin oluşturduğu Sonuç Kimliğini Analyze Layout girdi olarak alır. Aşağıdaki olası değerleri içeren bir durum alanı içeren bir JSON yanıtı döndürür.
Alan
Tür
Olası değerler
durum
Dize
notStarted: Çözümleme işlemi başlatılmamış.
running: Çözümleme işlemi devam ediyor.
failed: Çözümleme işlemi başarısız oldu.
succeeded: Çözümleme işlemi başarılı oldu.
Değeri döndürene kadar bu işlemi yinelemeli olarak çağırın succeeded . Saniye başına istek (RPS) hızını aşmamak için 3 ila 5 saniyelik bir aralık kullanın.
Durum alanında succeeded değer olduğunda JSON yanıtı .. /ayıklanan düzeni, metni, tabloları ve seçim işaretlerini içerir. Ayıklanan veriler.. /, ayıklanan metin satırlarını ve sözcükleri, sınırlayıcı kutuları, el yazısı göstergeli metin görünümünü, tabloları ve seçili/seçili olmayan işaretli seçim işaretlerini içerir.
Metin satırları için el yazısı sınıflandırma (yalnızca Latin)
Yanıt .. /, her metin satırının el yazısı stilinde olup olmadığını ve güvenilirlik puanını sınıflandırmayı içerir. Bu özellik yalnızca Latin dilleri için desteklenir. Aşağıdaki örnekte, görüntüdeki metnin el yazısı sınıflandırması gösterilmektedir.
Örnek JSON çıkışı
Get Analyze Layout Result işlemine verilen yanıt, belgenin tüm bilgilerin ayıklandığı yapılandırılmış bir gösterimidir.
Örnek belge dosyası ve yapılandırılmış çıktı örnek düzen çıktısı için buraya bakın.
JSON çıkışının iki bölümü vardır:
readResults düğüm, tanınan metnin ve seçim işaretinin tümünü içerir. Metin sunu hiyerarşisi sayfa, satır ve sonra tek tek sözcüklerdir.
pageResults düğüm, sınırlayıcı kutularıyla ayıklanan tabloları ve hücreleri, güveni ve "readResults" alanındaki satır ve sözcüklere başvuruyu içerir.
Örnek Çıkış
Metin
Düzen API'si, birden çok metin açısına ve rengine sahip belgelerden ve görüntülerden metin ayıklar. Belge, faks, basılı ve/veya el yazısı (yalnızca İngilizce) metin ve karma mod fotoğraflarını kabul eder. Metin, satırlar, sözcükler, sınırlayıcı kutular, güvenilirlik puanları ve stil (el yazısı veya diğer) hakkında sağlanan bilgilerle ayıklanır. Tüm metin bilgileri JSON çıkışının bölümüne eklenir readResults .
Üst bilgi içeren tablolar
Düzen API'si, JSON çıkışının pageResults bölümündeki tabloları ayıklar. Belgeler taranabilir, fotoğraflanabilir veya dijitalleştirilebilir. Tablolar birleştirilmiş hücrelerde veya sütunlarda, kenarlıklı veya kenarlıksız ve tek açılarla karmaşık olabilir. Ayıklanan tablo bilgileri.. /sütun ve satır sayısını, satır aralığını ve sütun aralığını içerir. Sınırlayıcı kutusu olan her hücre, alanın bir üst bilginin parçası olarak tanınıp tanınmadığıyla birlikte çıkıştır. Modelde tahmin edilen üst bilgi hücreleri birden çok satıra yayılabilir ve tablodaki ilk satırlar olmayabilir. Ayrıca, döndürülmüş tablolarla da çalışırlar. Her tablo hücresi de .. /, bölümdeki tek tek sözcüklere readResults başvurular içeren tam metni içerir.
Seçim işaretleri (belgeler)
Düzen API'si belgelerden seçim işaretlerini de ayıklar. Ayıklanan seçim işaretleri sınırlayıcı kutuyu, güveni ve durumu (seçili/seçilmemiş) içerir. Seçim işareti bilgileri JSON çıkışının readResults bölümünde ayıklanır.
Geçiş kılavuzu
Uygulamalarınızda ve iş akışlarınızda v3.1 sürümünü kullanmayı öğrenmek için Belge Zekası v3.1 geçiş kılavuzumuzu izleyin.
Diğer geliştiriciler ve uzmanlarla gerçek dünyadaki kullanım örneklerini temel alan ölçeklenebilir yapay zeka çözümleri oluşturmak için toplantı serisine katılın.
Azure Belge zekası, belgelerin gerçek zamanlı, uygun ölçekte ve doğrulukla gönderilmesini sağlamak için büyük ölçekte verileri ayıklar. Bu modül, kullanıcılara Azure Belge zekası görüntü işleme API'sini kullanma araçları sağlar.
Belgelerinizden önemli verileri ve yapı öğelerini ayıklayan bir form işleme uygulaması oluşturmak için Belge Yönetim Bilgileri SDK'sını veya REST API'sini kullanın.
Belge Yönetim Bilgileri istemci kitaplıklarını veya REST API'sini kullanmayı ve belgelerden önemli verileri ayıklamak için uygulamalar oluşturmayı öğrenin.
AnalyzeDocument yanıtının bir parçası olarak döndürülen farklı nesnelerin açıklaması ve uygulamalarınızda belge çözümleme yanıtının nasıl kullanılacağı.
Metin, yapı ve anahtar-değer çiftlerini ayıklamak için OCR, belge düzeni, faturalar, kimlik, özel modeller ve daha fazlası için belge işleme modelleri.



{kind=link}