Bu müşteri projesi bir Fortune 500 gıda şirketinin talep tahminini iyileştirmesine yardımcı oldu. Şirket, ürünleri doğrudan birden fazla perakende satış noktasına iletir. İyileştirme, ürünlerinin Birleşik Devletler çeşitli bölgelerindeki farklı mağazalarda stoklarını iyileştirmelerine yardımcı oldu. Bunu başarmak için Microsoft'un Ticari Yazılım Mühendisliği (CSE) ekibi, seçilen bölgeler için özelleştirilmiş makine öğrenmesi modelleri geliştirmek üzere bir pilot çalışma üzerinde istemcinin veri bilimciler ile birlikte çalıştı. Modeller şunları dikkate alır:
- Alışveriş yapanların demografik bilgileri
- Geçmiş ve tahmin edilen hava durumu
- Geçmiş sevkiyatlar
- Ürün iadeleri
- Özel etkinlikler
Stoklama iyileştirme hedefi projenin önemli bir bileşenini temsil etti ve müşteri ilk saha denemelerinde önemli bir satış artışı gerçekleştirdi. Ayrıca ekip, geçmiş ortalama temel modeliyle karşılaştırıldığında ortalama mutlak yüzde hatasının (MAPE) tahmininde %40 azalmayla karşı karşıya kaldı.
Projenin önemli bir parçası, pilot çalışmadan üretim düzeyine kadar veri bilimi iş akışının ölçeğini artırmayı bulmaktı. Bu üretim düzeyi iş akışı, CSE ekibinin aşağıdakileri yapmak için gerekli olduğunu gerektiriyor:
- Birçok bölge için model geliştirme.
- Modellerin performansını sürekli güncelleştirin ve izleyin.
- Veri ve mühendislik ekipleri arasında işbirliğini kolaylaştırın.
Günümüzde tipik veri bilimi iş akışı, üretim iş akışına kıyasla tek seferlik bir laboratuvar ortamına daha yakındır. Veri bilimciler için bir ortam, bunlar için uygun olmalıdır:
- Verileri hazırlayın.
- Farklı modellerle denemeler yapın.
- Hiper parametreleri ayarlayın.
- Derleme-test-değerlendirme-iyileştirme döngüsü oluşturun.
Bu görevler için kullanılan çoğu aracın belirli amaçları vardır ve otomasyon için uygun değildir. Üretim düzeyinde makine öğrenmesi işleminde, uygulama yaşam döngüsü yönetimi ve DevOps konusunda daha fazla dikkate alınması gerekir.
CSE ekibi, istemcinin işlemin ölçeğini üretim düzeylerine yükseltmesine yardımcı oldu. Sürekli tümleştirme ve sürekli teslim (CI/CD) özelliklerinin çeşitli yönlerini uyguladılar ve gözlemlenebilirlik ve Azure özellikleriyle tümleştirme gibi sorunları ele aldılar. Uygulama sırasında ekip, mevcut MLOps kılavuzundaki boşlukları ortaya çıkardı. MLOps'un daha iyi anlaşılabilmesi ve uygun ölçekte uygulanması için bu boşlukların doldurulması gerekiyordu.
MLOps uygulamalarını anlamak, kuruluşların sistemin ürettiği makine öğrenmesi modellerinin iş performansını geliştiren üretim kalitesi modelleri olmasını sağlamasına yardımcı olur. MLOps uygulandığında, kuruluşun artık üretim düzeyinde işlemler için makine öğrenmesi modelleri geliştirmek ve çalıştırmak için gereken altyapı ve mühendislik çalışmalarıyla ilgili düşük düzey ayrıntılara zaman harcaması gerekmez. MLOps'un uygulanması, veri bilimi ve yazılım mühendisliği topluluklarının üretime hazır bir sistem sunmak için birlikte çalışmayı öğrenmesine de yardımcı olur.
CSE ekibi makine öğrenmesi topluluğu gereksinimlerini karşılamak için mlOps olgunluk modeli geliştirme gibi sorunları ele alarak bu projeyi kullandı. Bu çabalar, MLOps sürecindeki önemli oyuncuların tipik zorluklarını anlayarak MLOps benimsemesini iyileştirmeyi hedeflemektedir.
Katılım ve teknik senaryolar
Görevlendirme senaryosunda CSE ekibinin çözmesi gereken gerçek dünya zorlukları ele alınmaktadır. Teknik senaryo, iyi oluşturulmuş DevOps yaşam döngüsü kadar güvenilir bir MLOps yaşam döngüsü oluşturma gereksinimlerini tanımlar.
Görevlendirme senaryosu
Müşteri ürünleri düzenli bir zamanlamaya göre perakende satış noktalarına doğrudan teslim eder. Her perakende satış noktası, ürün kullanım düzenlerinde farklılık gösterdiğinden, ürün envanteri her haftalık teslimatta değişiklik gösterilmelidir. Satışları en üst düzeye çıkarmak ve ürün getirilerini ve kayıp satış fırsatlarını en aza indirmek, müşterinin kullandığı talep tahmini yöntemlerinin hedefleridir. Bu proje, tahminleri geliştirmek için makine öğrenmesini kullanmaya odaklandı.
CSE ekibi projeyi iki aşamaya böldü. 1. Aşama, seçilen bir satış bölgesi için makine öğrenmesi tahmininin etkinliğine yönelik alan tabanlı bir pilot çalışmayı desteklemek için makine öğrenmesi modelleri geliştirmeye odaklandı. 1. Aşama'nın başarısı, ekibin ilk pilot çalışmayı tek bir coğrafi bölgeyi destekleyen minimum bir model grubundan müşterinin tüm satış bölgeleri için sürdürülebilir üretim düzeyindeki bir dizi modele ölçeklendirdiği 2. Aşama'ya yol açtı. Ölçeği artırma çözümünde dikkat edilmesi gereken başlıca nokta, çok sayıda coğrafi bölgeyi ve bunların yerel perakende satış noktalarını barındırma ihtiyacıydı. Ekip, makine öğrenmesi modellerini her bölgedeki hem büyük hem de küçük perakende satış noktalarına ayırdı.
1. Aşama pilot çalışması, bir bölgenin perakende satış noktalarına ayrılmış bir modelin bölgedeki satış noktaları için talep tahminini iyileştirmek için yerel satış geçmişi, yerel demografik bilgiler, hava durumu ve özel etkinlikleri kullanabileceğini belirledi. Dört grup makine öğrenmesi tahmin modeli, tek bir bölgede pazar satış noktalarına hizmet verdi. Modeller verileri haftalık toplu işlerde işledi. Ayrıca ekip, karşılaştırma için geçmiş verileri kullanarak iki temel model geliştirdi.
Ölçeği artırılan 2. Aşama çözümünün ilk sürümü için CSE ekibi, küçük ve büyük pazar yerleri dahil olmak üzere 14 coğrafi bölgeyi seçti. 50'den fazla makine öğrenmesi tahmin modeli kullandılar. Ekip, daha fazla sistem büyümesi ve makine öğrenmesi modellerinde iyileştirmenin devam etmesi bekleniyor. Bu geniş ölçekli makine öğrenmesi çözümünün yalnızca makine öğrenmesi ortamı için DevOps'un en iyi uygulama ilkelerine dayalı olması durumunda sürdürülebilir olduğu kısa sürede netleşti.
| Ortam | Pazar Bölgesi | Biçimlendir | Modeller | Model Alt Bölüm | Model Açıklaması |
|---|---|---|---|---|---|
| Geliştirme ortamı | Her coğrafi pazar/bölge (örneğin, Kuzey Teksas) | Büyük biçimli mağazalar (süpermarketler, büyük kutu mağazaları vb.) | İki grup modeli | Yavaş hareket eden ürünler | Yavaş ve hızlı her ikisi de en az mutlak küçültme ve seçim operatörü (LASSO) doğrusal regresyon modeline ve kategorik eklemelere sahip bir sinir ağına sahiptir |
| Hızlı hareket eden ürünler | Hem yavaş hem de hızlı bir LASSO doğrusal regresyon modeli ve kategorik eklemeler içeren bir sinir ağı grubuna sahiptir | ||||
| Tek bir topluluk modeli | Yok | Geçmiş ortalama | |||
| Küçük biçimli mağazalar (eczaneler, marketler vb.) | İki grup modeli | Yavaş hareket eden ürünler | Hem yavaş hem de hızlı bir LASSO doğrusal regresyon modeli ve kategorik eklemeler içeren bir sinir ağı grubuna sahiptir | ||
| Hızlı hareket eden ürünler | Yavaş ve her ikisi de bir LASSO doğrusal regresyon modeline ve kategorik eklemelere sahip bir sinir ağına sahiptir | ||||
| Tek bir topluluk modeli | Yok | Geçmiş ortalama | |||
| Ek 13 coğrafi bölge için yukarıdakiyle aynı | |||||
| Üretim ortamı için yukarıdakiyle aynı |
MLOps işlemi, makine öğrenmesi modellerinin tüm yaşam döngüsünü ele alan ölçeklendirilmiş sistem için bir çerçeve sağladı. Çerçeve geliştirme, test, dağıtım, işlem ve izlemeyi içerir. Klasik bir CI/CD işleminin gereksinimlerini karşılar. Ancak DevOps ile karşılaştırıldığında göreli olgunlaşmamışlığı nedeniyle mevcut MLOps kılavuzunda boşluklar olduğu ortaya çıkıyor. Proje ekibi bu boşlukların bazılarını doldurmak için çalıştı. Ölçeklendirilmiş makine öğrenmesi çözümünün uygulanabilirliğini güvenceye alan işlevsel bir süreç modeli sağlamak istediler.
Bu projeden geliştirilen MLOps işlemi, MLOps'u daha yüksek bir olgunluk ve uygulanabilirlik düzeyine taşımak için önemli bir gerçek dünya adımına neden oldu. Yeni süreç, diğer makine öğrenmesi projeleri için doğrudan geçerlidir. CSE ekibi öğrendiklerini kullanarak herkesin diğer makine öğrenmesi projelerine uygulayabileceği bir MLOps olgunluk modelinin taslağını oluşturmuş oldu.
Teknik senaryo
Makine öğrenmesi için DevOps olarak da bilinen MLOps, makine öğrenmesi yaşam döngülerini üretim ortamında uygulamayla ilgili felsefeleri, uygulamaları ve teknolojileri kapsayan bir şemsiye terimdir. Hala nispeten yeni bir kavramdır. MLOps'un ne olduğunu tanımlamaya yönelik birçok girişim yapılmıştır ve birçok kişi MLOps'un veri hazırlama yönteminden makine öğrenmesi sonuçlarını nasıl teslim ettiklerine, izlediklerine ve değerlendirdiklerine kadar her şeyi destekleyip veremeyeceğini sorgulamıştır. DevOps'un bir dizi temel uygulama geliştirmesi için yıllar olsa da MLOps henüz geliştirme aşamasındadır. Geliştikçe, genellikle farklı beceri kümeleriyle ve önceliklerle çalışan iki disiplini bir araya getirmenin zorluklarını keşfediyoruz: yazılım/operasyon mühendisliği ve veri bilimi.
MLOps'un gerçek dünya üretim ortamlarında uygulanması, üstesinden gelinilmesi gereken benzersiz zorluklara sahiptir. Teams, MLOps desenlerini desteklemek için Azure'ı kullanabilir. Azure, istemcilere makine öğrenmesi yaşam döngüsünü etkili bir şekilde yönetmek için varlık yönetimi ve düzenleme hizmetleri de sağlayabilir. Azure hizmetleri, bu makalede açıkladığımız MLOps çözümünün temelini oluşturur.
Makine öğrenmesi modeli gereksinimleri
1. Aşama pilot saha çalışması sırasındaki çalışmanın büyük bir kısmı, CSE ekibinin tek bir bölgedeki büyük ve küçük perakende mağazaları için uyguladığı makine öğrenmesi modellerini oluşturmaktı. Dahil edilen modeller için önemli gereksinimler:
Azure Machine Learning hizmetinin kullanımı.
Jupyter not defterlerinde geliştirilen ve Python'da uygulanan ilk deneysel modeller.
Not
Ekipler büyük ve küçük mağazalar için aynı makine öğrenmesi yaklaşımını kullandı, ancak eğitim ve puanlama verileri mağazanın boyutuna bağlıydı.
Model tüketimi için hazırlık gerektiren veriler.
Gerçek zamanlı değil, toplu olarak işlenen veriler.
Kod veya veri değiştiğinde veya model eskiye gittiğinde model yeniden eğitme.
Power BI panolarında model performansını görüntüleme.
Geçmiş ortalama temel modelle karşılaştırıldığında MAPE <= %45 olduğunda puanlamada önemli olarak kabul edilen model performansı.
MLOps gereksinimleri
Ekibin, tek bir satış bölgesi için yalnızca birkaç modelin geliştirildiği 1. Aşama pilot saha çalışmasından çözümün ölçeğini genişletmek için çeşitli önemli gereksinimleri karşılaması gerekiyordu. 2. Aşama, birden çok bölge için özel makine öğrenmesi modelleri uyguladı. Uygulama aşağıdakileri içerir:
Modelleri yeni veri kümeleriyle yeniden eğitmek için her bölgedeki büyük ve küçük depolar için haftalık toplu işleme.
Makine öğrenmesi modellerinin sürekli iyileştirmesi.
MLOps için DevOps benzeri bir işleme ortamında CI/CD ile ortak geliştirme/test/paket/test/dağıtım işleminin tümleştirilmesi.
Not
Bu, veri bilimciler ve veri mühendislerinin geçmişte yaygın olarak çalıştığı bir değişimi temsil eder.
Mağaza geçmişine, demografik bilgilere ve diğer anahtar değişkenlere göre büyük ve küçük mağazalar için her bölgeyi temsil eden benzersiz bir model. Modelin hata işleme riskini en aza indirmek için veri kümesinin tamamını işlemesi gerekiyordu.
Başlangıçta ölçeği artırarak 14 satış bölgesini destekleyebilme ve ölçeği daha da artırmayı planla.
Bölgeler ve diğer mağaza kümeleri için daha uzun vadeli tahmin için ek modeller için planlar.
Makine öğrenmesi modeli çözümü
Veri bilimi yaşam döngüsü olarak da bilinen makine öğrenmesi yaşam döngüsü, kabaca aşağıdaki üst düzey süreç akışına uyar:
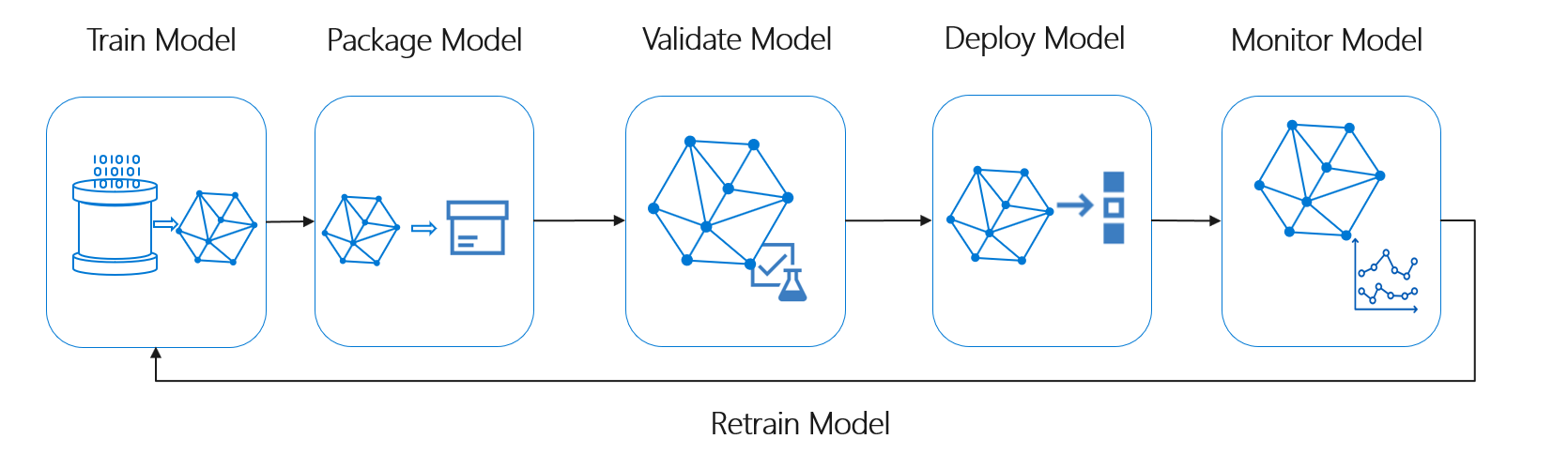
Modeli burada dağıtın, doğrulanmış makine öğrenmesi modelinin tüm operasyonel kullanımını temsil edebilir. DevOps ile karşılaştırıldığında MLOps, makine öğrenmesi yaşam döngüsünü tipik CI/CD işlemiyle tümleştirme konusunda ek zorluk sunar.
Veri bilimi yaşam döngüsü tipik yazılım geliştirme yaşam döngüsünü izlemez. Modelleri eğitmek ve puan almak için Azure Machine Learning'in kullanımını içerdiğinden bu adımların CI/CD otomasyonuna dahil edilmesi gerekiyordu.
Verilerin toplu olarak işlenmesi mimarinin temelini oluşturur. biri eğitim, diğeri puanlama için olmak üzere iki Azure Machine Learning işlem hattı sürecin merkezinde yer alır. Bu diyagramda, istemci projesinin ilk aşaması için kullanılan veri bilimi metodolojisi gösterilmektedir:
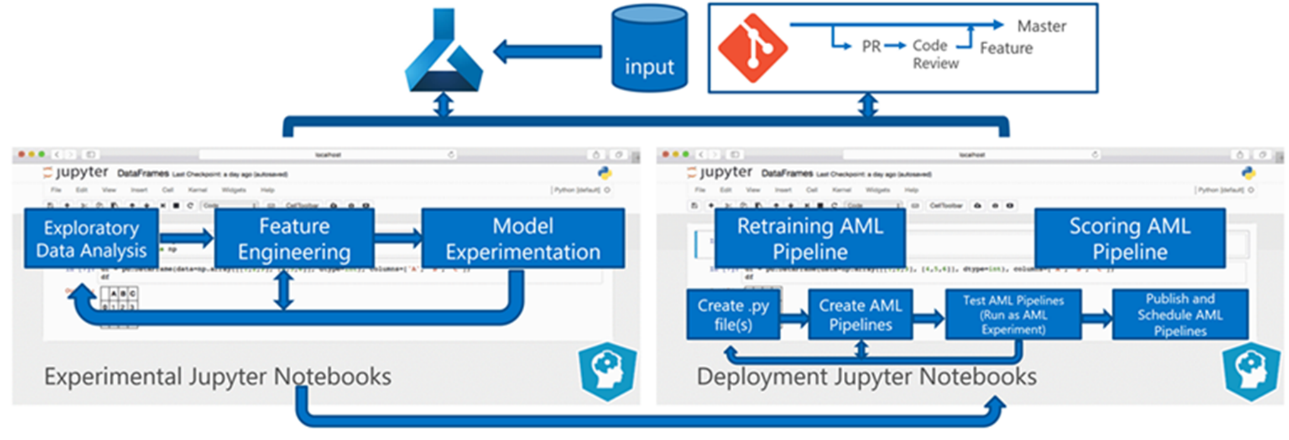
Ekip çeşitli algoritmaları test etti. Sonunda bir LASSO doğrusal regresyon modelinin ve kategorik eklemeleri olan bir sinir ağının topluluk tasarımını seçtiler. Ekip, istemcinin hem büyük hem de küçük mağazalar için sitede depoladığı ürün düzeyine göre tanımlanan aynı modeli kullandı. Ekip, modeli hızlı ve yavaş hareket eden ürünlere böler.
Veri bilimcileri, ekip yeni kod yayınladığında ve yeni veriler kullanılabilir olduğunda makine öğrenmesi modellerini eğitmektedir. Eğitim genellikle haftalık olarak gerçekleşir. Sonuç olarak, her işleme çalıştırması büyük miktarda veri içerir. Ekip, birçok kaynaktan verileri farklı biçimlerde topladığı için, veri bilimciler işlemeden önce verileri kullanılabilir bir biçime koymak için koşullandırma gerektirir. Veri koşullandırma için önemli bir el ile çalışma gerekiyor ve CSE ekibi bunu otomasyon için birincil aday olarak tanımladı.
Veri bilimciler, bu tahmin yaklaşımının yararlılığını değerlendirmek için 1. Aşama pilot saha çalışmasında deneysel Azure Machine Learning modellerini geliştirip tek bir satış bölgesine uyguladı. CSE ekibi, pilot çalışmadaki mağazaların satış asansörlerinin önemli olduğunu değerlendirdi. Bu başarı, çözümün 14 coğrafi bölgeden ve binlerce mağazadan başlayarak 2. Aşamadaki tam üretim düzeylerine uygulanmasını haklı göstermiş oldu. Ekip daha sonra ek bölgeler eklemek için aynı düzeni kullanabilir.
Pilot model, ölçeği artırılan çözümün temeli olarak hizmet verdi, ancak CSE ekibi modelin performansını geliştirmek için sürekli olarak daha fazla iyileştirmeye ihtiyacı olduğunu biliyordu.
MLOps çözümü
MLOps kavramları büyüdükçe ekipler genellikle veri bilimi ve DevOps uzmanlık alanlarını bir araya getirmenin zorluklarını keşfeder. Bunun nedeni, disiplinlerdeki asıl oyuncuların, yazılım mühendislerinin ve veri bilimcilerinin farklı beceri kümeleriyle ve önceliklerle çalışmasıdır.
Ama üzerinde inşa etmek için benzerlikler vardır. DEVOps gibi MLOps, bir araç zinciri tarafından uygulanan bir geliştirme işlemidir. MLOps araç zinciri şunları içerir:
- Sürüm denetimi
- Kod analizi
- Derleme otomasyonu
- Sürekli tümleştirme
- Test çerçeveleri ve otomasyon
- CI/CD işlem hatlarıyla tümleştirilmiş uyumluluk ilkeleri
- Dağıtım otomasyonu
- İzleme
- Olağanüstü durum kurtarma ve yüksek kullanılabilirlik
- Paket ve kapsayıcı yönetimi
Yukarıda belirtildiği gibi, çözüm mevcut DevOps kılavuzundan yararlanır, ancak istemcinin ve veri bilimi topluluğunun gereksinimlerini karşılayan daha olgun bir MLOps uygulaması oluşturmak için geliştirilmiştir. MLOps, aşağıdaki ek gereksinimlerle DevOps yönergelerini oluşturur:
- Veri ve model sürümü oluşturma, kod sürümü oluşturma ile aynı değildir: Şema ve kaynak verileri değiştikçe veri kümelerinin sürümü oluşturulmalıdır.
- Dijital denetim izi gereksinimleri: Kod ve istemci verileriyle ilgilenirken tüm değişiklikleri izleyin.
- Genelleştirme: Veri bilimcilerinin modelleri giriş verilerine ve senaryoya göre ayarlaması gerektiğinden modeller yeniden kullanım kodundan farklıdır. Modeli yeni bir senaryo için yeniden kullanmak için ince ayar yapmanız/aktarmanız/öğrenmeniz gerekebilir. Eğitim işlem hattına ihtiyacınız var.
- Eski modeller: Modeller zamanla bozulma eğilimindedir ve üretimle ilgili olduklarından emin olmak için isteğe bağlı olarak bunları yeniden eğitme yeteneğine ihtiyacınız vardır.
MLOps zorlukları
Olgunlaşmamış MLOps standardı
MLOps için standart desen hala gelişmektedir. Çözüm genellikle sıfırdan oluşturulur ve belirli bir istemcinin veya kullanıcının gereksinimlerine uyacak şekilde oluşturulur. CSE ekibi bu boşluğu fark etti ve bu projede DevOps en iyi yöntemlerini kullanmaya çalıştı. DevOps işlemini MLOps'un ek gereksinimlerine uyacak şekilde artırdılar. Ekibin geliştirdiği süreç, MLOps standart deseninin nasıl görünmesi gerektiğini gösteren uygulanabilir bir örnektir.
Beceri kümelerindeki farklılıklar
Yazılım mühendisleri ve veri bilimciler takıma benzersiz beceri kümeleri getirir. Bu farklı beceri kümeleri, herkesin ihtiyaçlarına uygun bir çözüm bulmayı zorlaştırabilir. Denemeden üretime model teslimi için iyi anlaşılmış bir iş akışı oluşturmak önemlidir. Ekip üyelerinin MLOps işlemini bozmadan değişiklikleri sisteme nasıl tümleştirebileceklerini anlamaları gerekir.
Birden çok modeli yönetme
Zor makine öğrenmesi senaryolarını çözmek için genellikle birden çok modele ihtiyaç vardır. MLOps'un zorluklarından biri, aşağıdakiler dahil olmak üzere bu modelleri yönetmektir:
- Uyumlu bir sürüm oluşturma şemasına sahip olma.
- Tüm modelleri sürekli değerlendirme ve izleme.
Model sorunlarını tanılamak ve yeniden üretilebilir modeller oluşturmak için hem kod hem de verilerin izlenebilir kökeni de gereklidir. Özel panolar, dağıtılan modellerin nasıl performans gösterdiğine anlam verebilir ve ne zaman müdahale yapılacağını belirtebilir. Ekip bu proje için bu tür panolar oluşturdu.
Veri koşullandırma ihtiyacı
Bu modellerle kullanılan veriler birçok özel ve genel kaynaktan gelir. Özgün veriler düzensiz olduğundan, makine öğrenmesi modelinin ham durumunda kullanması mümkün değildir. Veri bilimciler, verileri makine öğrenmesi modeli tüketimi için standart bir biçimde koşullanmalıdır.
Pilot alan testinin büyük bir kısmı, makine öğrenmesi modelinin işleyebilmesi için ham verileri koşullandırmaya odaklanmıştır. MlOps sisteminde ekip bu işlemi otomatikleştirmeli ve çıkışları izlemelidir.
MLOps olgunluk modeli
MLOps olgunluk modelinin amacı, ilkeleri ve uygulamaları netleştirmek ve mlOps uygulamasındaki boşlukları belirlemektir. Ayrıca, bir istemciye mlOps özelliğini aynı anda yapmak yerine artımlı olarak nasıl büyüyeceğini göstermenin bir yoludur. İstemci bunu aşağıdakiler için bir kılavuz olarak kullanmalıdır:
- Proje için çalışmanın kapsamını tahmin edin.
- Başarı ölçütlerini belirleme.
- Teslim edilebilir öğeleri tanımlama.
MLOps olgunluk modeli beş teknik özellik düzeyi tanımlar:
| Level | Açıklama |
|---|---|
| 0 | İşlem Yok |
| 1 | DevOps ama MLOps yok |
| 2 | Otomatik eğitim |
| 3 | Otomatik model dağıtımı |
| 4 | Otomatik işlemler (tam MLOps) |
MLOps olgunluk modelinin geçerli sürümü için MLOps olgunluk modeli makalesine bakın.
MLOps işlem tanımı
MLOps, ham veri almaktan puanlama olarak da bilinen model çıktısı teslimine kadar tüm etkinlikleri içerir:
- Veri koşullandırma
- Model eğitimi
- Model testi ve değerlendirmesi
- Derleme tanımı ve işlem hattı
- Yayın işlem hattı
- Dağıtım
- Puanlama
Temel makine öğrenmesi süreci
Temel makine öğrenmesi süreci geleneksel yazılım geliştirmeye benzer, ancak önemli farklılıklar vardır. Bu diyagramda makine öğrenmesi sürecindeki başlıca adımlar gösterilmektedir:
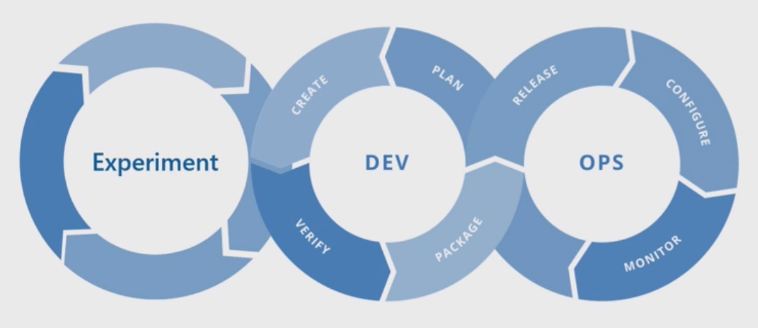
Deneme aşaması, veri bilimi yaşam döngüsüne özgüdür ve bu da veri bilimciler tarafından geleneksel olarak işlerinin nasıl yapıldığını yansıtır. Kod geliştiricilerinin işlerini yapma şeklinden farklıdır. Aşağıdaki diyagramda bu yaşam döngüsü daha ayrıntılı olarak gösterilmiştir.
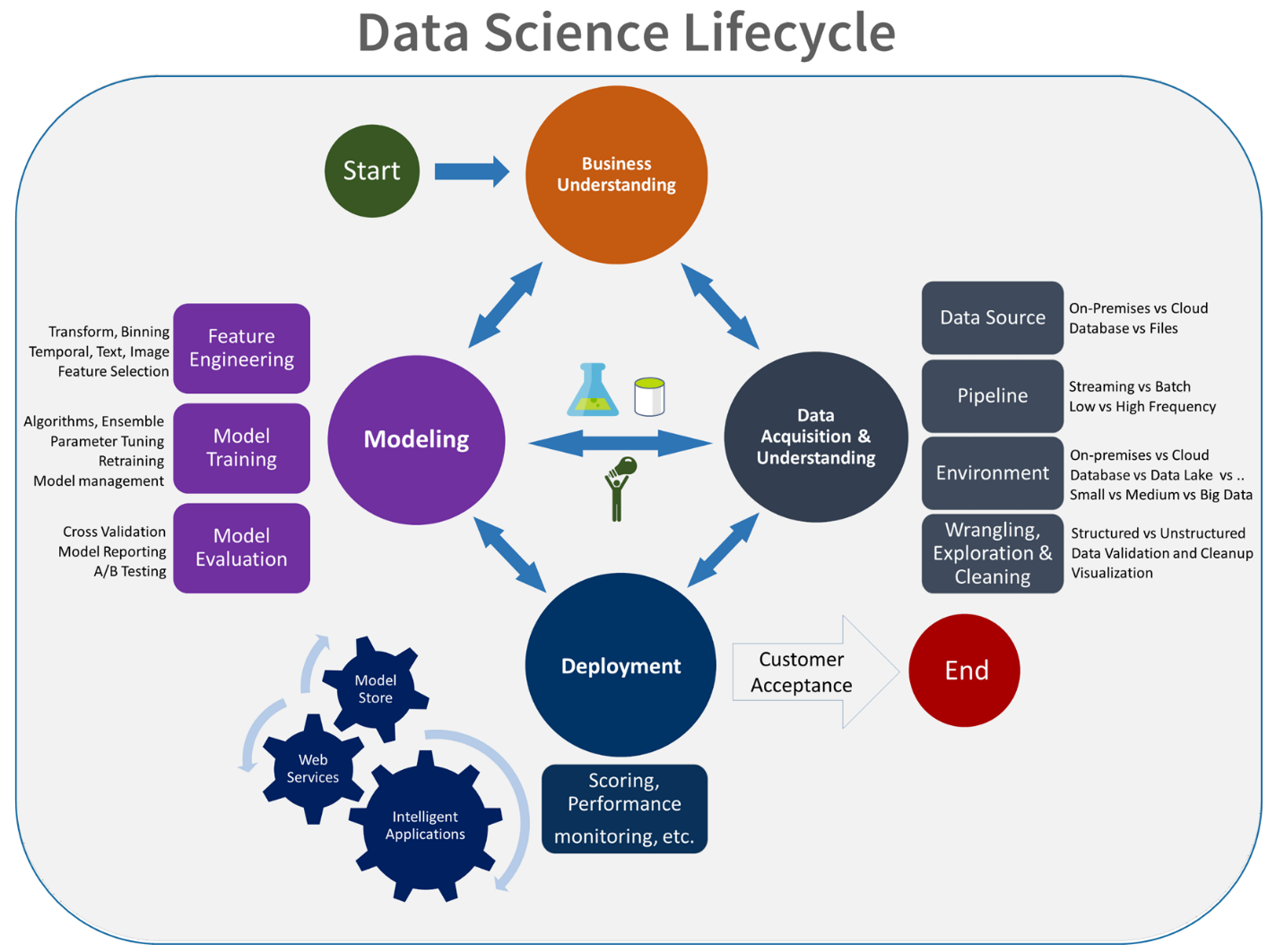
Bu veri geliştirme işlemini MLOps ile tümleştirmek bir zorluk oluşturur. Burada ekibin süreci MLOps'un destekleyebilecekleri bir formda tümleştirmek için kullandığı deseni görürsünüz:
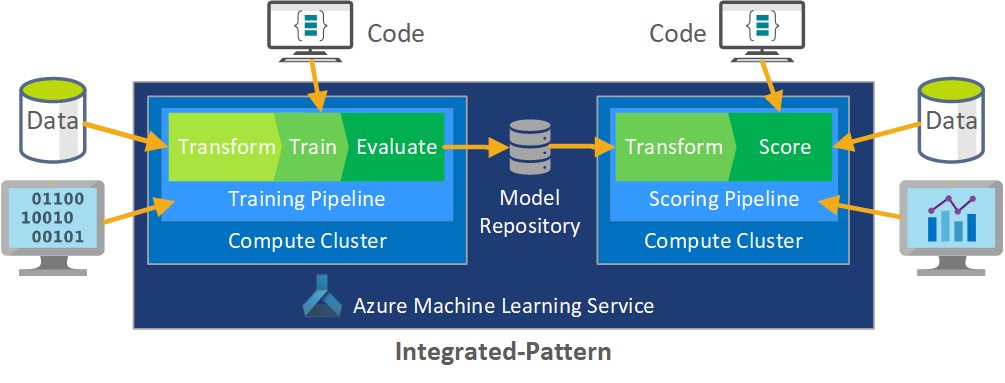
MLOps'un rolü, üretim düzeyindeki sistemlerde ortak olan büyük ölçekli CI/CD ortamlarını verimli bir şekilde destekleyebilecek eşgüdümlü bir işlem oluşturmaktır. Kavramsal olarak MLOps modelinin denemeden puanlamaya kadar tüm işlem gereksinimlerini içermesi gerekir.
CSE ekibi MLOps işlemini istemcinin özel gereksinimlerine uyacak şekilde geliştirdi. En önemli ihtiyaç, gerçek zamanlı işleme yerine toplu işlemeydi. Ekip ölçeği artırılan sistemi geliştirirken bazı eksiklikleri belirledi ve çözdü. Bu eksikliklerden en önemlileri, ekibin Azure Data Factory'de yerleşik bir bağlayıcı kullanarak uyguladığı Azure Data Factory ile Azure Machine Learning arasında bir köprü geliştirilmesine yol açtı. Bu bileşen kümesini, işlem otomasyonunun çalışması için gereken tetiklemesi ve durum izlemesini kolaylaştırmak için oluşturmuştur.
Bir diğer temel değişiklik de veri bilimcilerinin eğitim ve puanlama işlemlerini doğrudan tetikleme yerine Deneysel kodu Jupyter not defterlerinden MLOps dağıtım sürecine aktarma özelliğine ihtiyaç duyduğuydu.
MlOps işlem modeli kavramının son hali aşağıdadır:
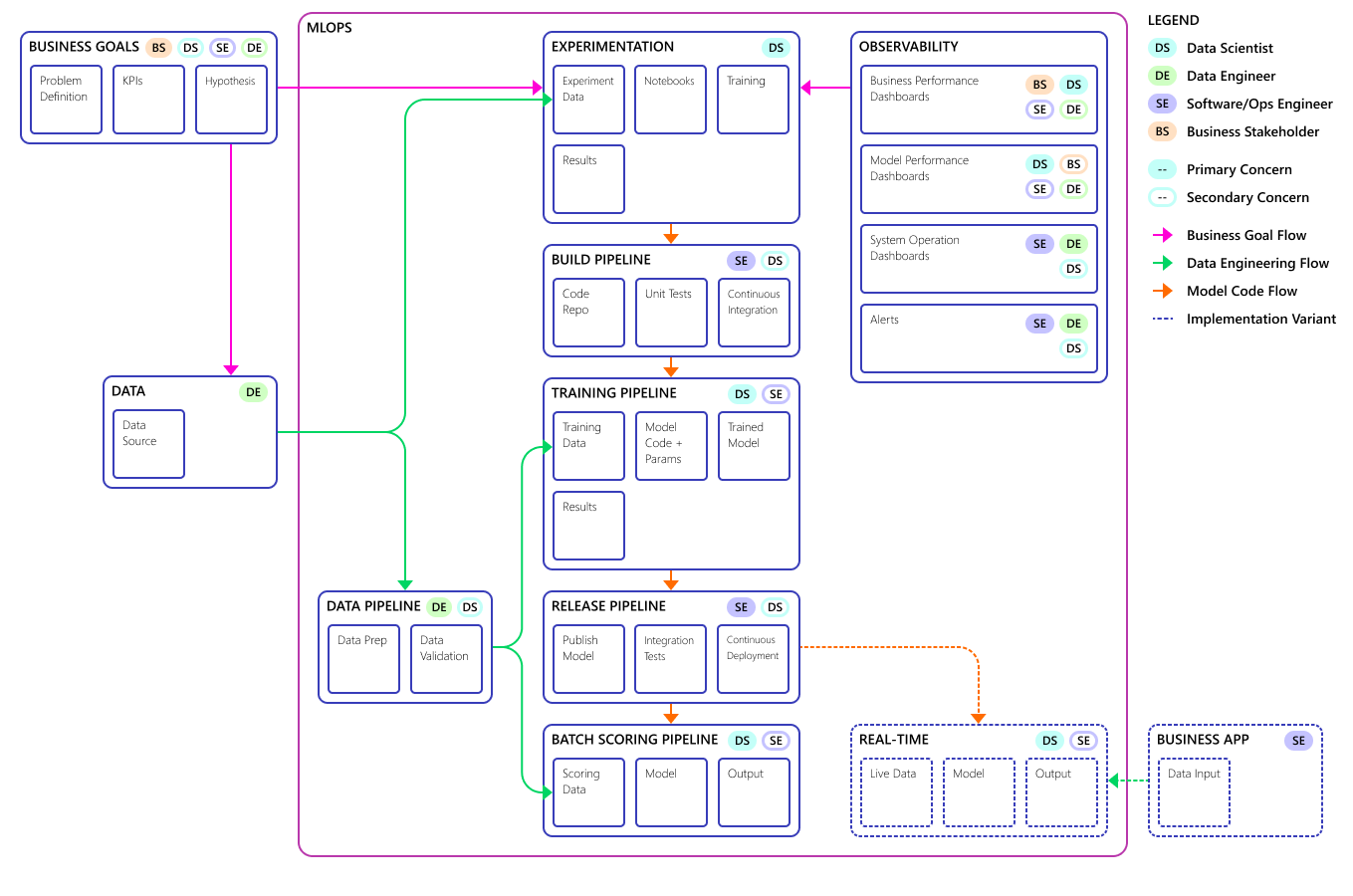
Önemli
Puanlama son adımdır. İşlem, tahminlerde bulunmak için makine öğrenmesi modelini çalıştırır. Bu, talep tahmini için temel iş kullanım örneği gereksinimini giderir. Takım, istatistiksel tahmin yöntemlerinin tahmin doğruluğunun ölçüsü ve makine öğrenmesindeki regresyon sorunlarına yönelik bir kayıp işlevi olan MAPE'yi kullanarak tahminlerin kalitesini derecelendirilir. Bu projede ekip , = %45'lik bir MAPE'yi <dikkate alır.
MLOps işlem akışı
Aşağıdaki diyagramda, makine öğrenmesi yaşam döngüsüne CI/CD geliştirme ve yayın iş akışlarının nasıl uygulanacağı açıklanmaktadır:
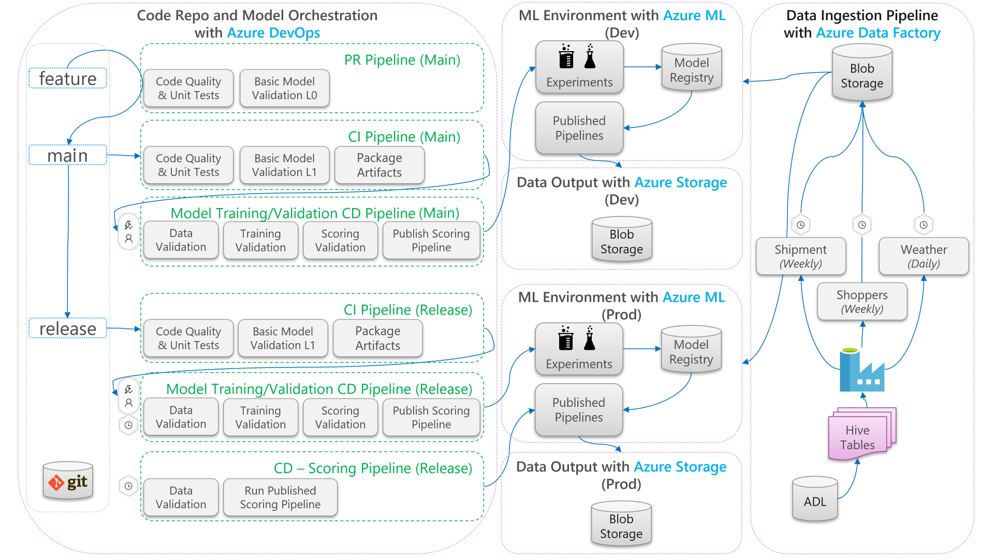
- Bir özellik dalından çekme isteği (PR) oluşturulduğunda işlem hattı, birim testleri ve kod kalitesi testleri aracılığıyla kodun kalitesini doğrulamak için kod doğrulama testleri çalıştırır. Kalite yukarı akışını doğrulamak için işlem hattı, örnek bir sahte veri kümesiyle uçtan uca eğitim ve puanlama adımlarını doğrulamak için temel model doğrulama testleri de çalıştırır.
- Çekme isteği ana dal ile birleştirildiğinde CI işlem hattı aynı kod doğrulama testlerini ve daha fazla dönem içeren temel model doğrulama testlerini çalıştırır. İşlem hattı daha sonra kodu ve ikili dosyaları içeren yapıtları makine öğrenmesi ortamında çalıştırılacak şekilde paketleyecektir.
- Yapıtlar kullanılabilir olduktan sonra bir model doğrulama CD işlem hattı tetiklenir. Geliştirme makine öğrenmesi ortamında uçtan uca doğrulama çalıştırır. Puanlama mekanizması yayımlanır. Toplu puanlama senaryosunda, makine öğrenmesi ortamında bir puanlama işlem hattı yayımlanır ve sonuç üretmek için tetikler. Gerçek zamanlı puanlama senaryosu kullanmak istiyorsanız bir web uygulaması yayımlayabilir veya kapsayıcı dağıtabilirsiniz.
- Bir kilometre taşı oluşturulup yayın dalı ile birleştirildikten sonra aynı CI işlem hattı ve model doğrulama CD işlem hattı tetiklenir. Bu kez yayın dalındaki koda karşı çalışır.
Yukarıda gösterilen MLOps işlem veri akışını benzer mimari seçimlere sahip projeler için bir arketip çerçevesi olarak düşünebilirsiniz.
Kod doğrulama testleri
Makine öğrenmesi için kod doğrulama testleri, kod tabanının kalitesini doğrulamaya odaklanır. Bu kavram, kod kalitesi testleri (lint), birim testleri ve kod kapsamı ölçümleri olan tüm mühendislik projelerine benzer.
Temel model doğrulama testleri
Model doğrulama genellikle geçerli bir makine öğrenmesi modeli oluşturmak için gereken tam uçtan uca işlem adımlarını doğrulamayı ifade eder. Aşağıdaki gibi adımları içerir:
- Veri doğrulama: Giriş verilerinin geçerli olduğundan emin olur.
- Eğitim doğrulaması: Modelin başarıyla eğitilmesini sağlar.
- Puanlama doğrulaması: Ekibin giriş verileriyle puanlama için eğitilen modeli başarıyla kullanabilmesini sağlar.
Makine öğrenmesi ortamında bu tam adımları çalıştırmak pahalı ve zaman alır. Sonuç olarak, ekip bir geliştirme makinesinde yerel olarak temel model doğrulama testleri yaptı. Yukarıdaki adımları çalıştırıp aşağıdakileri kullandı:
- Yerel test veri kümesi: Genellikle belirsiz olan, depoda iade edilen ve giriş veri kaynağı olarak kullanılan küçük bir veri kümesi.
- Yerel bayrak: Modelin kodunda, kodun veri kümesini yerel olarak çalıştırmayı amaçladığını gösteren bir bayrak veya bağımsız değişken. bayrağı, koda makine öğrenmesi ortamına yapılan çağrıları atlamasına ilişkin bilgi verir.
Bu doğrulama testlerinin amacı eğitilen modelin performansını değerlendirmek değildir. Bunun yerine, uçtan uca işlemin kodunun iyi kalitede olduğunu doğrulamaktır. Çekme isteği ve CI derlemesinde model doğrulama testlerinin eklenmesi gibi yukarı akışa gönderilen kodun kalitesini güvenceye alır. Ayrıca mühendislerin ve veri bilimcilerinin hata ayıklama amacıyla koda kesme noktaları yerleştirmesini de mümkün kılar.
Model doğrulama CD işlem hattı
Model doğrulama işlem hattının amacı, makine öğrenmesi ortamındaki uçtan uca model eğitimini ve puanlama adımlarını gerçek verilerle doğrulamaktır. Oluşturulan tüm eğitilmiş modeller, doğrulama tamamlandıktan sonra yükseltmeyi beklemek için model kayıt defterine eklenir ve etiketlenir. Toplu tahmin için yükseltme, modelin bu sürümünü kullanan bir puanlama işlem hattının yayımlanması olabilir. Gerçek zamanlı puanlama için model yükseltildiğini belirtmek üzere etiketlenebilir.
Puanlama CD işlem hattı
Puanlama CD işlem hattı, model doğrulaması için kullanılan aynı model düzenleyicinin yayımlanan puanlama işlem hattını tetiklediği toplu çıkarım senaryosu için geçerlidir.
Geliştirme ve üretim ortamları karşılaştırması
Geliştirme (geliştirme) ortamını üretim (üretim) ortamından ayırmak iyi bir uygulamadır. Ayırma, sistemin farklı zamanlamalarda model doğrulama CD işlem hattını ve puanlama CD işlem hattını tetiklemesini sağlar. Açıklanan MLOps akışı için ana dalı hedefleyen işlem hatları geliştirme ortamında, yayın dalını hedefleyen işlem hattı ise üretim ortamında çalışır.
Kod değişiklikleri ile veri değişiklikleri karşılaştırması
Önceki bölümlerde çoğunlukla kod değişikliklerini geliştirme aşamasından sürüme kadar nasıl işleyecekleri ele alınıyor. Ancak veri değişiklikleri, üretimde aynı doğrulama kalitesini ve tutarlılığını sağlamak için kod değişiklikleriyle aynı sıkılığı izlemelidir. Bir veri değişikliği tetikleyicisi veya zamanlayıcı tetikleyicisi ile sistem, sürüm dalı prod ortamında kod değişiklikleri için çalıştırılan işlemi çalıştırmak üzere model düzenleyicisinden model doğrulama CD işlem hattını ve puanlama CD işlem hattını tetikleyebilir.
MLOps kişilikleri ve rolleri
Herhangi bir MLOps işlemi için önemli bir gereksinim, işlemin birçok kullanıcısının gereksinimlerini karşılamasıdır. Tasarım amacıyla, bu kullanıcıları bireysel kişilikler olarak düşünün. Ekip bu proje için şu kişilikleri tanımladı:
- Veri bilimcisi: Makine öğrenmesi modelini ve algoritmalarını oluşturur.
- Mühendis
- Veri mühendisi: Veri koşullandırmayı işler.
- Yazılım mühendisi: Varlık paketi ve CI/CD iş akışıyla model tümleştirmesini işler.
- İşlemler veya BT: Sistem işlemlerini izler.
- İş paydaşları: Makine öğrenmesi modeli tarafından yapılan tahminler ve bu tahminlerin işletmeye nasıl yardımcı olduğuyla ilgilidir.
- Veri son kullanıcısı: Model çıkışını iş kararları almaya yardımcı olacak şekilde kullanır.
Ekip, kişilik ve rol çalışmalarından elde edilen üç önemli bulguyu ele almak zorunda kaldı:
- Veri bilimcileri ve mühendislerinin çalışmalarında yaklaşım ve beceri uyuşmazlığı vardır. MlOps işlem akışının tasarımında veri bilimcisi ve mühendisin işbirliği yapmasını kolaylaştırmak önemli bir noktadır. Tüm ekip üyelerinin yeni beceri edinmelerini gerektirir.
- Kimseyi yabancılaştırmadan tüm asıl kişilikleri birleştirmeye ihtiyaç vardır. Bunu gerçekleştirmenin bir yolu:
- MLOps için kavramsal modeli anladıklarından emin olun.
- Birlikte çalışacak ekip üyelerini kabul edin.
- Ortak hedeflere ulaşmak için çalışma yönergeleri oluşturun.
- İş katılımcısı ve veri son kullanıcısının modellerden gelen veri çıkışıyla etkileşime geçmek için bir yönteme ihtiyacı varsa, kullanıcı dostu bir kullanıcı arabirimi standart çözümdür.
Diğer ekipler, üretim kullanımı için ölçeği artırdıkça diğer makine öğrenmesi projelerinde de benzer sorunlarla karşılaşacaktır.
MLOps çözüm mimarisi
Mantıksal mimari
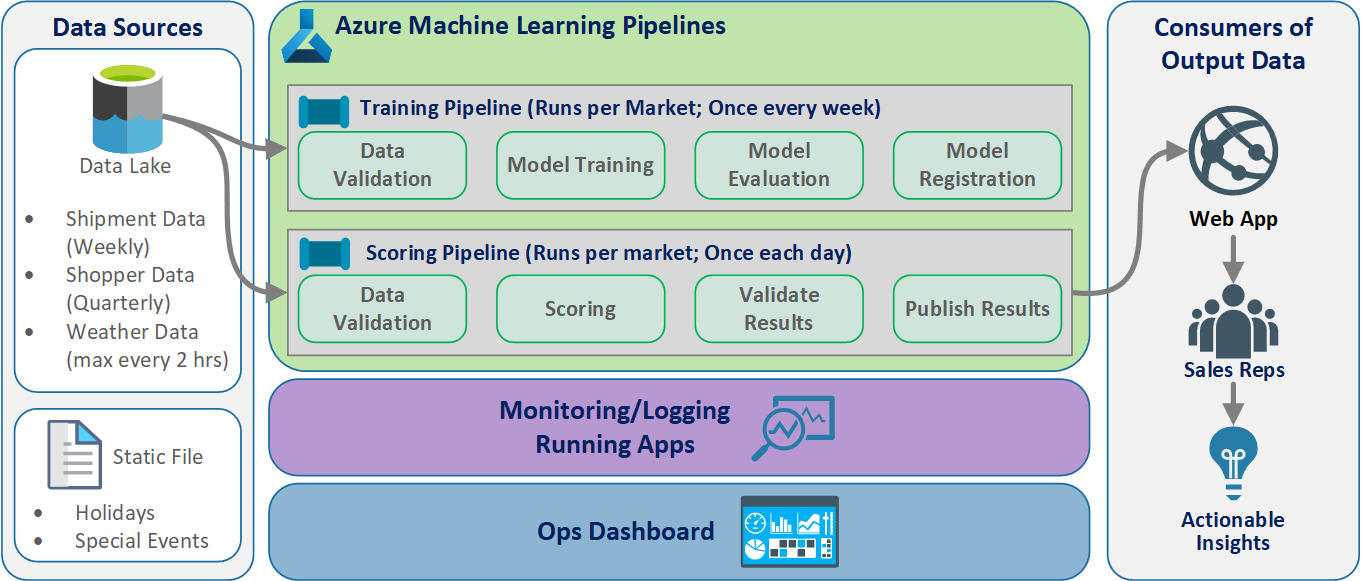
Veriler birçok farklı biçimdeki birçok kaynaktan gelir, bu nedenle veri gölüne eklenmeden önce koşullandırılır. Koşullandırma, Azure İşlevleri olarak çalışan mikro hizmetler kullanılarak yapılır. İstemciler, mikro hizmetleri veri kaynaklarına uyacak şekilde özelleştirir ve bunları eğitim ve puanlama işlem hatlarının tükettiği standartlaştırılmış bir csv biçimine dönüştürür.
Sistem mimarisi
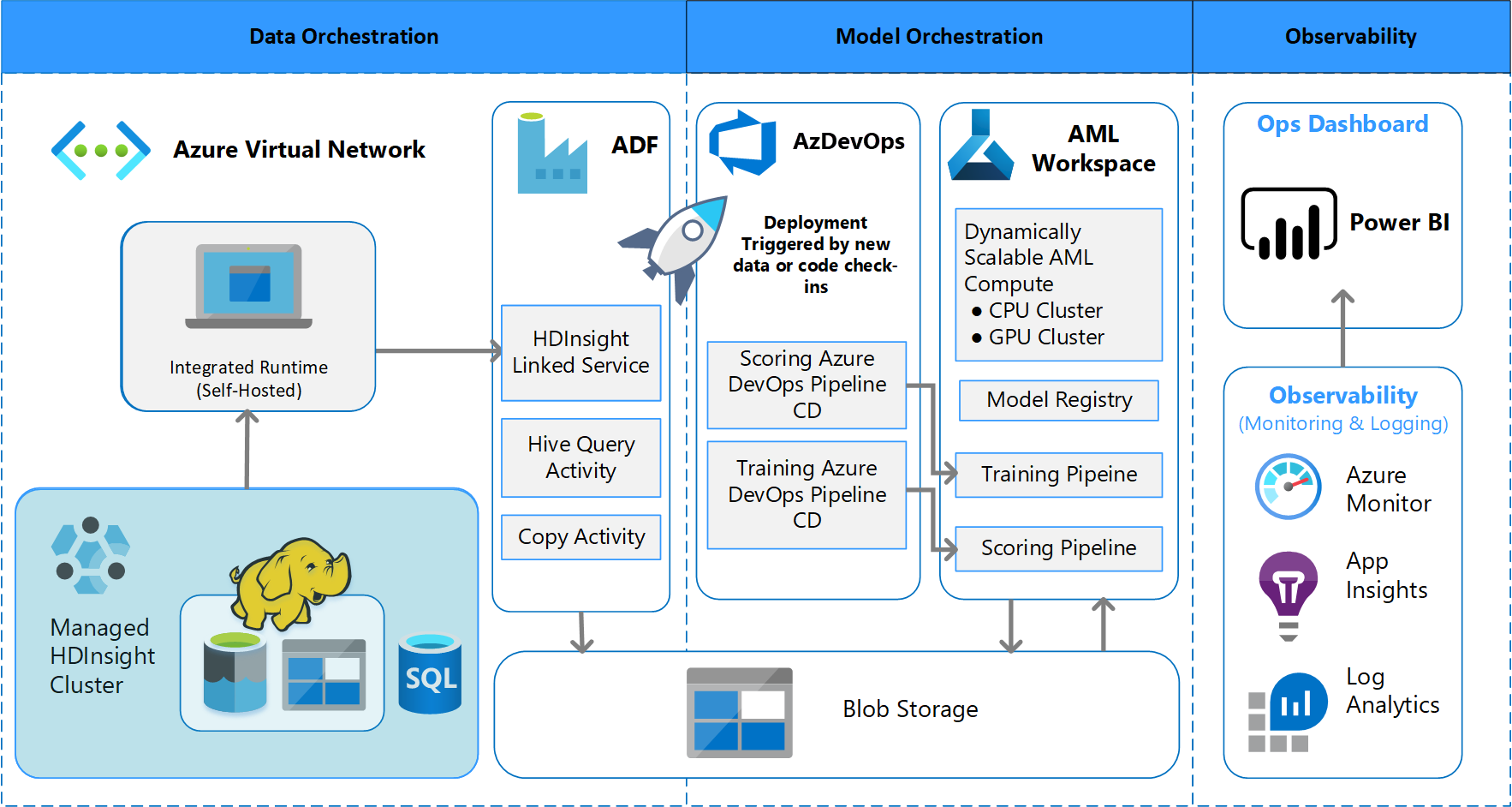
Toplu işlem mimarisi
Ekip, toplu veri işleme düzenini desteklemek için mimari tasarımını tasarlamıştı. Alternatifler vardır, ancak kullanılan her şey MLOps işlemlerini desteklemelidir. Kullanılabilir Azure hizmetlerinin tam kullanımı bir tasarım gereksinimiydi. Aşağıdaki diyagramda mimari gösterilmektedir:
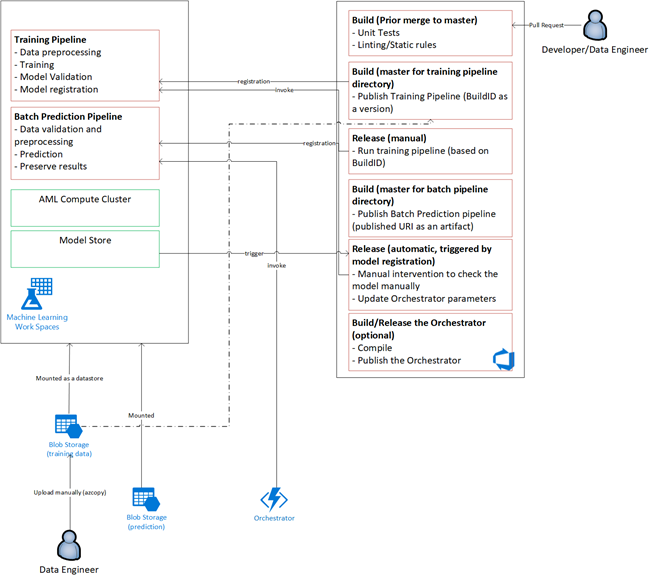
Çözüme genel bakış
Azure Data Factory aşağıdakileri yapar:
- Veri alımını ve Azure Machine Learning işlem hattını çalıştırmayı başlatmak için bir Azure işlevi tetikler.
- Azure Machine Learning işlem hattının tamamlanması için yoklama yapmak için dayanıklı bir işlev başlatır.
Power BI'daki özel panolarda sonuçlar görüntülenir. OpenCensus Python SDK'sı aracılığıyla Azure SQL, Azure İzleyici ve App Insights'a bağlı diğer Azure panoları, Azure kaynaklarını izler. Bu panolar, makine öğrenmesi sisteminin durumu hakkında bilgi sağlar. Ayrıca müşterinin ürün siparişi tahmini için kullandığı verileri de verir.
Model düzenleme
Model düzenleme şu adımları izler:
- Çekme isteği gönderildiğinde DevOps bir kod doğrulama işlem hattı tetikler.
- İşlem hattı birim testleri, kod kalitesi testleri ve model doğrulama testleri çalıştırır.
- Ana dalda birleştirildiğinde aynı kod doğrulama testleri çalıştırılır ve DevOps yapıtları paketler.
- Yapıtların DevOps tarafından toplanması, Azure Machine Learning'in aşağıdakileri gerçekleştirmesini tetikler:
- Veri doğrulama.
- Eğitim doğrulaması.
- Puan doğrulama.
- Doğrulama tamamlandıktan sonra son puanlama işlem hattı çalıştırılır.
- Verilerin değiştirilmesi ve yeni bir çekme isteğinin gönderilmesi doğrulama işlem hattını yeniden tetikler ve ardından son puanlama işlem hattı tetiklenir.
Denemeyi etkinleştirme
Belirtildiği gibi, geleneksel veri bilimi makine öğrenmesi yaşam döngüsü, değişiklik yapmadan MLOps işlemini desteklemez. Etkili bir CI/CD işlemi için kolayca ölçeklendirilmeyecek farklı türlerde el ile araç ve deneme, doğrulama, paketleme ve model teslimi kullanır. MLOps, yüksek düzeyde işlem otomasyonu gerektirir. İster yeni bir makine öğrenmesi modeli geliştiriliyor ister eski bir model değiştiriliyor olsun, makine öğrenmesi modelinin yaşam döngüsünü otomatikleştirmek gerekir. 2. Aşama projesinde ekip, eğitim görevleri için Azure Machine Learning işlem hatlarını düzenleme ve yeniden yayımlama amacıyla Azure DevOps'u kullandı. Uzun süre çalışan ana dal, modellerin temel testlerini gerçekleştirir ve uzun süre çalışan yayın dalı aracılığıyla kararlı sürümler göndermeye devam eder.
Kaynak denetimi bu işlemin önemli bir parçası haline gelir. Git, not defteri ve model kodunu izlemek için kullanılan sürüm denetim sistemidir. Ayrıca süreç otomasyonlarını da destekler. Kaynak denetimi için uygulanan temel iş akışı aşağıdaki ilkeleri uygular:
- Kod ve veri kümeleri için resmi sürüm oluşturma kullanın.
- Kod tamamen geliştirilip doğrulanana kadar yeni kod geliştirme için bir dal kullanın.
- Yeni kod doğrulandıktan sonra ana dalda birleştirilebilir.
- Yayın için, ana daldan ayrı kalıcı sürüme sahip bir dal oluşturulur.
- Her veri kümesinin bütünlüğünü koruyabilmeniz için eğitim veya tüketim için koşullandırılmış veri kümeleri için sürümleri ve kaynak denetimini kullanın.
- Jupyter Notebook denemelerinizi izlemek için kaynak denetimini kullanın.
Veri kaynaklarıyla tümleştirme
Veri bilimciler farklı makine öğrenmesi modelleriyle deneme yapmak için birçok ham veri kaynağı ve işlenmiş veri kümesi kullanır. Üretim ortamındaki veri hacmi zor olabilir. Veri bilimciler farklı modellerle denemeler yapmak için Azure Data Lake gibi yönetim araçlarını kullanmaları gerekir. Resmi tanımlama ve sürüm denetimi gereksinimi tüm ham veriler, hazırlanmış veri kümeleri ve makine öğrenmesi modelleri için geçerlidir.
Projede, veri bilimciler modele giriş için aşağıdaki verileri koşullandırdı:
- Ocak 2017'den bu yana geçmiş haftalık sevkiyat verileri
- Her posta kodu için geçmiş ve tahmin edilen günlük hava durumu verileri
- Her mağaza kimliği için müşteri verileri
Kaynak denetimiyle tümleştirme
Veri bilim adamlarının en iyi mühendislik uygulamalarını uygulaması için kullandıkları araçları GitHub gibi kaynak denetim sistemleriyle kolayca tümleştirmek gerekir. Bu uygulama makine öğrenmesi modeli sürümü oluşturmaya, ekip üyeleri arasında işbirliğine ve ekiplerde veri kaybı veya sistem kesintisi yaşanması halinde olağanüstü durum kurtarma olanağı sağlar.
Model grubu desteği
Bu projedeki model tasarımı bir topluluk modeliydi. Yani, veri bilimciler son model tasarımında birçok algoritma kullandı. Bu durumda, modeller aynı temel algoritma tasarımını kullandı. Tek fark, farklı eğitim verileri ve puanlama verileri kullanmalarıydı. Modeller, LASSO doğrusal regresyon algoritması ve sinir ağı birleşimini kullandı.
Ekip, belirli bir isteğe hizmet vermek için üretimde çalışan birçok gerçek zamanlı modelin desteklendiği noktaya kadar süreci ileriye taşıma seçeneğini keşfetti ancak uygulamadı. Bu seçenek, grup modellerinin A/B testlerinde ve araya kaydedilen denemelerde kullanılmasını sağlayabilir.
Son kullanıcı arabirimleri
Ekip gözlemlenebilirlik, izleme ve izleme için son kullanıcı URI'leri geliştirdi. Belirtildiği gibi panolar makine öğrenmesi modeli verilerini görsel olarak görüntüler. Bu panolar aşağıdaki verileri kullanıcı dostu bir biçimde gösterir:
- Giriş verilerinin önceden işlenmesi de dahil olmak üzere işlem hattı adımları.
- Makine öğrenmesi modeli işleme durumunu izlemek için:
- Dağıtılan modelinizden hangi ölçümleri topluyorsunuz?
- MAPE: Ortalama mutlak yüzde hatası, genel performans için izlenen temel ölçüm. (Her model için = 0,45 mape değerini <hedefleyin.)
- RMSE 0: Gerçek hedef değer = 0 olduğunda kök ortalama kare hatası (RMSE).
- RMSE Tümü: Veri kümesinin tamamında RMSE.
- Modelinizin üretimde beklendiği gibi çalışıp performans göstermediğini nasıl değerlendirirsiniz?
- Üretim verilerinin beklenen değerlerden çok fazla sapma olup olmadığını anlamanın bir yolu var mı?
- Modeliniz üretimde düşük performans mı sergilemektedir?
- Yük devretme durumunuz var mı?
- Dağıtılan modelinizden hangi ölçümleri topluyorsunuz?
- İşlenen verilerin kalitesini izleyin.
- Makine öğrenmesi modeli tarafından üretilen puanlama/tahminleri görüntüleyin.
Uygulama, panoları verilerin doğasına ve verileri işleme ve analiz etme şekline göre doldurur. Bu nedenle, ekip her kullanım örneği için panoların tam düzenini tasarlamalıdır. burada iki örnek pano verilmiştir:
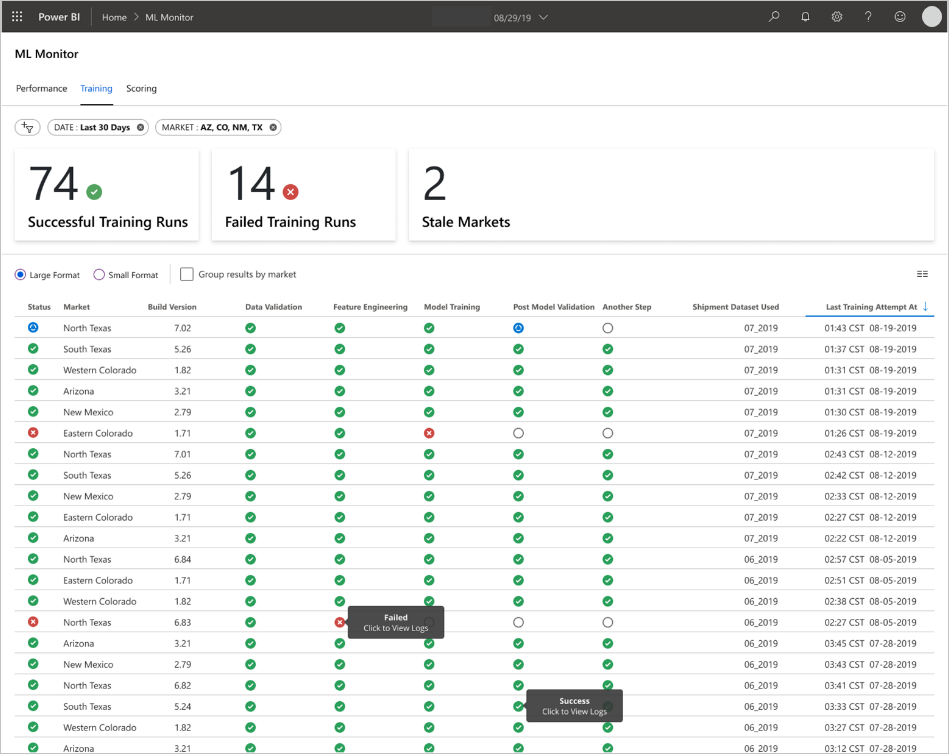
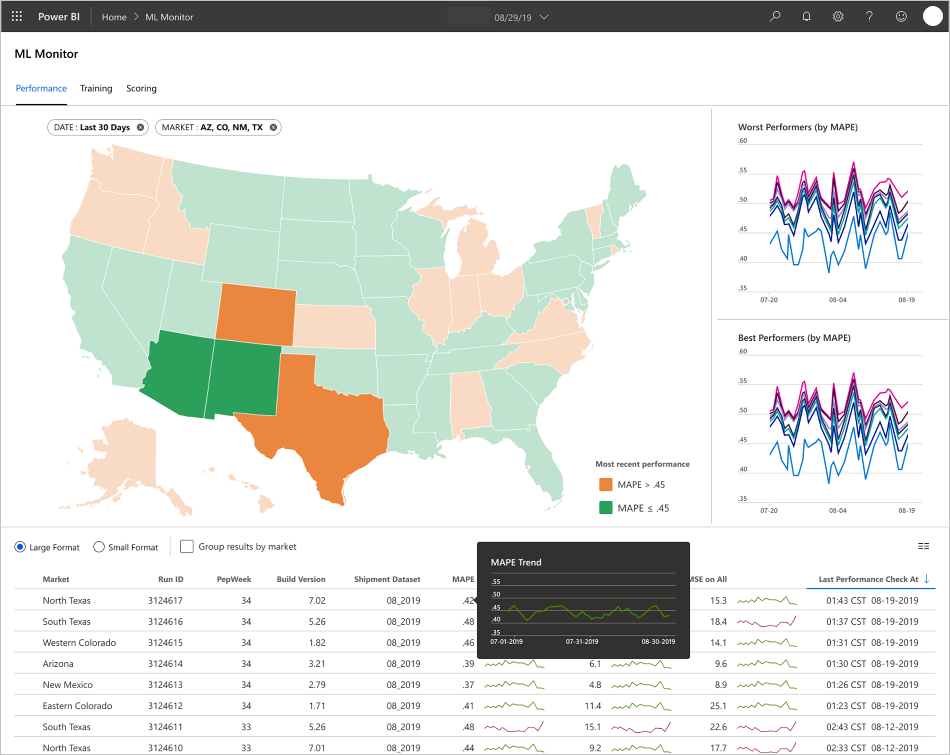
Panolar, makine öğrenmesi modeli tahminlerinin son kullanıcısı tarafından kullanıma hazır bilgiler sağlamak üzere tasarlanmıştır.
Not
Eski modeller, veri bilimcilerinin puanlamanın gerçekleştiği 60 günden fazla puanlama için kullanılan modeli eğittiği puanlama çalıştırmalarıdır. ML İzleyici panosunun Puanlama sayfası bu sistem durumu ölçümünü görüntüler.
Bileşenler
- Azure Machine Learning
- Azure Blob Depolama
- Azure Data Lake Storage
- Azure Pipelines
- Azure Data Factory
- Python için Azure İşlevleri
- Azure İzleyici
- Azure SQL Veritabanı
- Azure Panoları
- Power BI
Dikkat edilmesi gereken noktalar
Burada keşfedilecek noktaların listesini bulabilirsiniz. Bunlar, CSE ekibinin proje sırasında öğrendiği dersleri temel alır.
Ortamla ilgili dikkat edilmesi gerekenler
- Veri bilimciler genellikle Jupyter not defterlerinden başlayarak Python kullanarak makine öğrenmesi modellerinin çoğunu geliştirir. Bu not defterlerini üretim kodu olarak uygulamak zor olabilir. Jupyter not defterleri daha çok deneysel bir araçken Python betikleri üretim için daha uygundur. Ekiplerin genellikle model oluşturma kodunu Python betiklerine yeniden düzenlemeye zaman ayırması gerekir.
- DevOps ve makine öğrenmesi alanında yeni olan istemcilerin deneme ve üretimin farklı bir titizlik gerektirdiğini anlaması için ikisini ayırmak iyi bir uygulamadır.
- Azure Machine Learning Görsel Tasarımcısı veya AutoML gibi araçlar, istemci çözümün geri kalanı için geçerli olacak standart DevOps uygulamalarını kullanırken temel modellerin yerden kalkmasında etkili olabilir.
- Azure DevOps, işlem hattı adımlarını tetikleme konusunda yardımcı olmak için Azure Machine Learning ile tümleştirilebilen eklentilere sahiptir. MLOpsPython deposunda bu tür işlem hatlarının birkaç örneği vardır.
- Makine öğrenmesi genellikle eğitim için güçlü grafik işleme birimi (GPU) makineleri gerektirir. İstemcide bu tür bir donanım yoksa Azure Machine Learning işlem kümeleri, otomatik ölçeklendirmeye sahip uygun maliyetli güçlü donanımları hızlı bir şekilde sağlamak için etkili bir yol sağlayabilir. İstemcinin gelişmiş güvenlik veya izleme gereksinimleri varsa standart VM'ler, Databricks veya yerel işlem gibi başka seçenekler de vardır.
- Bir istemcinin başarılı olması için model oluşturma ekiplerinin (veri bilimciler) ve dağıtım ekiplerinin (DevOps mühendisleri) güçlü bir iletişim kanalına sahip olması gerekir. Bunu günlük stand-up toplantılarıyla veya resmi bir çevrimiçi sohbet hizmetiyle gerçekleştirebilirler. Her iki yaklaşım da geliştirme çalışmalarını bir MLOps çerçevesiyle tümleştirmeye yardımcı olur.
Veri hazırlama konusunda dikkat edilmesi gerekenler
Azure Machine Learning'i kullanmaya yönelik en basit çözüm, verileri desteklenen bir veri depolama çözümünde depolamaktır. Azure Data Factory gibi araçlar, belirli bir zamanlamaya göre bu konumlara giden ve bu konumlardan veri almak için etkilidir.
İstemcilerin modellerini güncel tutmak için sık sık ek yeniden eğitme verileri yakalaması önemlidir. Henüz bir veri işlem hattı yoksa, bir işlem hattı oluşturmak genel çözümün önemli bir parçası olacaktır. Azure Machine Learning'de Veri Kümeleri gibi bir çözüm kullanmak, modellerin izlenebilirliğine yardımcı olmak için verilerin sürümü oluşturmada yararlı olabilir.
Model eğitimi ve değerlendirme konuları
Makine öğrenmesi yolculuğuna yeni başlayan bir istemcinin tam MLOps işlem hattını uygulamaya çalışması çok zor. Gerekirse, deneme çalıştırmalarını izlemek için Azure Machine Learning'i ve eğitim hedefi olarak Azure Machine Learning işlemini kullanarak bunu kolaylaştırabilir. Bu seçenekler, Azure hizmetlerini tümleştirmeye başlamak için daha düşük bir giriş çözümü engeli oluşturabilir.
Bir not defteri denemesinden tekrarlanabilir betiklere geçmek, birçok veri bilim insanı için zorlu bir geçiştir. Python betiklerinde eğitim kodlarını ne kadar erken yazabilirseniz, eğitim kodlarının sürümünü oluşturma ve yeniden eğitme işlemlerini etkinleştirme o kadar kolay olur.
Mümkün olan tek yöntem bu değildir. Databricks, not defterlerini iş olarak zamanlamayı destekler. Ancak geçerli istemci deneyimine bağlı olarak, test sınırlamaları nedeniyle bu yaklaşımı tam DevOps uygulamalarıyla izlemek zordur.
Modeli başarılı olarak değerlendirmek için hangi ölçümlerin kullanıldığını anlamak da önemlidir. Tek başına doğruluk genellikle bir modelin genel performansını başka bir modele göre belirleyecek kadar iyi değildir.
İşlemle ilgili dikkat edilmesi gerekenler
- Müşteriler işlem ortamlarını standartlaştırmak için kapsayıcıları kullanmayı düşünmelidir. Neredeyse tüm Azure Machine Learning işlem hedefleri Docker'ın kullanılmasını destekler. Bir kapsayıcının bağımlılıkları işlemesi, özellikle ekip birçok işlem hedefi kullanıyorsa, uyuşma durumlarını önemli ölçüde azaltabilir.
Model sunma konusunda dikkat edilmesi gerekenler
- Azure Machine Learning SDK'sı, kayıtlı bir modelden doğrudan Azure Kubernetes Service'e (AKS) dağıtma seçeneği sunar ve hangi güvenlik/ölçümlerin uygulandığına ilişkin sınırlar oluşturur. İstemcilerin modellerini test etmeleri için daha kolay bir çözüm bulmaya çalışabilirsiniz, ancak üretim iş yükleri için AKS'ye daha güçlü bir dağıtım geliştirmek en iyisidir.
Sonraki adımlar
- MLOps hakkında daha fazla bilgi edinin
- Azure'da MLOps
- Azure İzleyici Görselleştirmeleri
- Machine Learning Yaşam Döngüsü
- Azure DevOps Machine Learning uzantısı
- Azure Machine Learning CLI
- Azure Machine Learning olayları temelinde uygulamaları, işlemleri veya CI/CD iş akışlarını tetikleme
- Azure DevOps ile model eğitimi ve dağıtımı ayarlama
İlgili kaynaklar
- MLOps olgunluk modeli
- Databricks Not Defteri'ni kullanarak Azure Databricks'te MLOps'u düzenleme
- Azure Machine Learning kullanan Python modelleri için MLOps
- Azure Databricks ile veri bilimi ve makine öğrenmesi
- Power Platform ile Vatandaş Yapay Zekası
- Şirket içinde ve uçta yapay zeka ve makine öğrenmesi bilgi işlem dağıtma