Önbelleğe alma, bir sistemin performansını ve ölçeklenebilirliğini artırmayı amaçlayan yaygın bir tekniktir. Sık erişilen verileri uygulamaya yakın bir konumdaki hızlı depolama alanına geçici olarak kopyalayarak verileri önbelleğe alır. Bu hızlı veri depolama alanının konumu uygulamaya özgün kaynaktan daha yakınsa, önbelleğe alma işlemi verileri daha hızlı sunarak istemci uygulamaların yanıt sürelerini önemli ölçüde artırabilir.
Önbelleğe alma işleminin en etkili olduğu durum, özellikle özgün veri deposunda aşağıdaki koşullar geçerli olduğunda bir istemci örneğinin aynı verileri tekrarlayarak okumasıdır:
- Oldukça statik kalır.
- Önbellek hızıyla karşılaştırıldığında yavaştır.
- Yüksek düzeyde bir çekişmeye tabidir.
- Ağ gecikmesi erişimin yavaşlamasına neden olabileceği zaman uzaktadır.
Dağıtılmış uygulamalar verileri önbelleğe alırken genellikle aşağıdaki stratejilerin birini ya da her ikisini birden uygular:
- Bir uygulamanın veya hizmetin örneğini çalıştıran bilgisayarda verilerin yerel olarak tutulduğu özel bir önbellek kullanırlar.
- Birden çok işlem ve makine tarafından erişilebilen ortak bir kaynak olarak hizmet veren paylaşılan bir önbellek kullanırlar.
Her iki durumda da önbelleğe alma işlemi istemci tarafında ve sunucu tarafında gerçekleştirilebilir. İstemci tarafında önbelleğe alma işlemi, web tarayıcısı ya da masaüstü uygulaması gibi bir sistemin kullanıcı arabirimini sağlayan işlem tarafından yapılır. Sunucu tarafı önbelleğe alma işlemi, uzaktan çalışan iş hizmetleri sağlayan işlem tarafından gerçekleştirilir.
En temel önbellek türü bir bellek içi depodur. Tek bir işlemin adres alanında tutulur ve bu işlemde çalışan kod tarafından doğrudan erişilir. Bu önbellek türüne erişmek hızlı bir işlemdir. Ayrıca, mütevazı miktarda statik veri depolamak için etkili bir yol da sağlayabilir. Önbelleğin boyutu genellikle işlemi barındıran makinede kullanılabilir bellek miktarıyla kısıtlanır.
Bellekte fiziksel olarak mümkün olandan daha fazla bilgi depolamanız gerekirse, önbelleğe alınmış verileri yerel dosya sistemine yazabilirsiniz. Bu işlem, bellekte tutulan verilere göre daha yavaş erişim sağlar, ancak yine de ağ üzerinden veri almaktan daha hızlı ve daha güvenilir olmalıdır.
Bu modeli kullanan bir uygulamanın eşzamanlı olarak çalışan birden fazla örneğine sahipseniz, her uygulama örneği kendi veri kopyasını tutan bağımsız bir önbelleğe sahiptir.
Önbelleği, özgün verilerin geçmiş bir noktadaki anlık görüntüsü olarak düşünün. Bu veriler statik değilse, büyük olasılıkla farklı uygulama örnekleri önbelleklerinde verilerin farklı sürümlerini barındırır. Bu nedenle, Şekil 1'de gösterildiği gibi bu örnekler tarafından gerçekleştirilen aynı sorgu farklı sonuçlar döndürebilir.
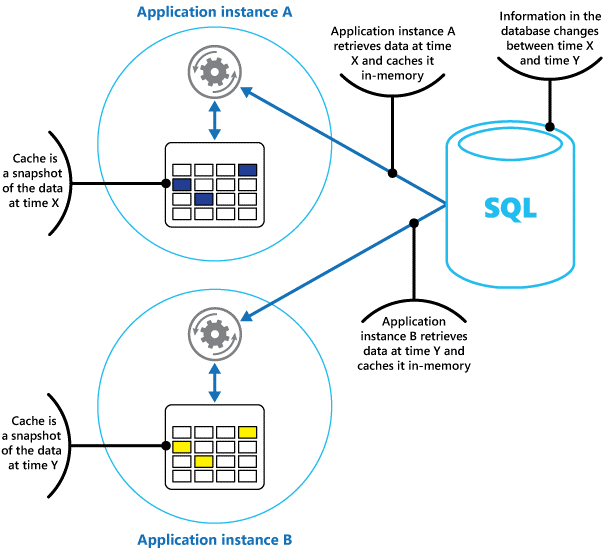
Şekil 1: Bir uygulamanın farklı örneklerinde bellek içi önbellek kullanma.
Paylaşılan bir önbellek kullanıyorsanız, verilerin her önbellekte farklılık gösterebileceği ve bellek içi önbelleğe alma ile ortaya çıkabilecek endişelerin hafifletilmesine yardımcı olabilir. Paylaşılan önbelleğe alma işlemi, farklı uygulama örneklerinin önbelleğe alınmış verilere ait aynı görünümünü görmesini sağlar. Şekil 2'de gösterildiği gibi önbelleği genellikle ayrı bir hizmetin parçası olarak barındırılan ayrı bir konumda bulur.
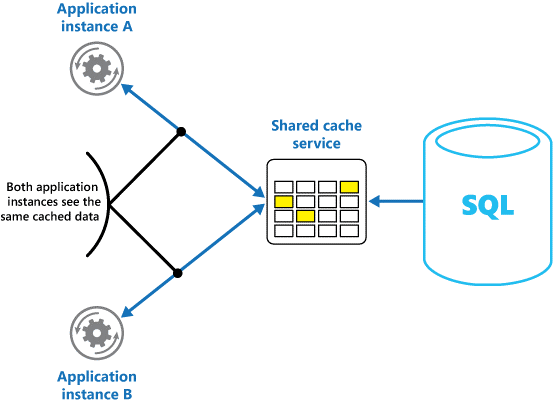
Şekil 2: Paylaşılan önbellek kullanma.
Paylaşılan önbelleğe alma yaklaşımının önemli bir avantajı, sağladığı ölçeklenebilirlik özelliğidir. Birçok paylaşılan önbellek hizmeti, bir sunucu kümesi kullanılarak uygulanır ve verileri kümeye saydam bir şekilde dağıtmak için yazılım kullanılır. Uygulama örneği, önbellek hizmetine bir istek gönderir. Temel alınan altyapı, önbelleğe alınan verilerin kümedeki konumunu belirler. Daha fazla sunucu ekleyerek önbelleği kolayca ölçeklendirebilirsiniz.
Paylaşılan önbelleğe alma yaklaşımın iki ana dezavantajları vardır:
- Önbellek, artık her uygulama örneğinde yerel olarak tutulmadığından erişim daha yavaştır.
- Ayrı bir önbellek hizmeti uygulama gereksinimi, çözüme karmaşıklık katabilir.
Aşağıdaki bölümlerde bir önbellek tasarlama ve kullanmaya ilişkin konular daha ayrıntılı olarak açıklanmaktadır.
Önbelleğe alma işlemi performans, ölçeklenebilirlik ve kullanılabilirliği önemli ölçüde artırabilir. Sahip olduğunuz veri miktarı ve bu verilere erişmesi gereken kullanıcı sayısı arttıkça, önbelleğe alma işleminin avantajları çoğalır. Önbelleğe alma, özgün veri deposundaki büyük hacimli eşzamanlı istekleri işlemeyle ilişkili gecikme süresini ve çekişmesini azaltır.
Örneğin, bir veritabanı sınırlı sayıda eşzamanlı bağlantıyı destekleyebilir. Ancak, temel alınan veritabanı yerine paylaşılan bir önbellekten veri almak, kullanılabilir bağlantı sayısı o anda tükenmiş olsa bile, bir istemci uygulamanın bu verilere erişmesini mümkün kılar. Ayrıca, veritabanı kullanılamaz duruma gelirse, istemci uygulamalar önbellekte tutulan verileri kullanarak çalışmaya devam edebilir.
Sıklıkla okunan ancak nadiren değişiklik yapılan verileri (örneğin, okuma işlemlerinin oranı yazma işlemlerinden büyük olan veriler) önbelleğe almayı düşünün. Ancak, önbelleği kritik bilgilerin yetkili deposu olarak kullanmanız önerilmez. Bunun yerine, uygulamanızın kaybetmeyi göze alamayacakları tüm değişikliklerin her zaman kalıcı bir veri deposuna kaydedildiğinden emin olun. Önbellek kullanılamıyorsa, uygulamanız veri deposunu kullanarak çalışmaya devam edebilir ve önemli bilgileri kaybetmezsiniz.
Bir önbelleği etkili bir şekilde kullanmanın anahtarı, önbelleğe alınacak en uygun verilerin belirlenmesi ve uygun zamanda önbelleğe alınmasıdır. Veriler, bir uygulama tarafından ilk kez alındığında isteğe bağlı olarak önbelleğe eklenebilir. Uygulamanın verileri veri deposundan yalnızca bir kez getirmesi gerekir ve sonraki erişim önbelleği kullanılarak karşılanabilir.
Alternatif olarak, bir önbellek genellikle uygulama başladığında önceden kısmen ya da tamamen doldurulabilir (dengeli dağıtım olarak bilinen yaklaşım). Ancak, uygulama çalışmaya başladığında bu yaklaşım özgün veri deposunda ani ve yüksek bir yük oluşturabileceğinden, büyük bir önbellek için dengeli dağıtımın uygulanması önerilmeyebilir.
Genellikle kullanım düzenlerinin analizi, bir önbelleği tamamen ya da kısmen önceden doldurmaya karar vermenize ve önbelleğe alınacak verileri seçmeye yardımcı olabilir. Örneğin, önbelleği, uygulamayı düzenli olarak (belki de her gün) kullanan ancak uygulamayı haftada yalnızca bir kez kullanan müşteriler için değil statik kullanıcı profili verileriyle görebilirsiniz.
Önbelleğe alma işlemi genellikle değişmez veya seyrek değişen verilerle iyi bir şekilde çalışır. Örnekler arasında bir e-ticaret uygulamasındaki ürün ve fiyatlandırma bilgileri veya oluşturulması maliyetli olan paylaşılan statik kaynaklar sayılabilir. Kaynak talebini en aza indirmek ve performansı artırmak amacıyla bu verilerin bazıları veya tümü, uygulama başlangıcında önbelleğe yüklenebilir. Ayrıca, güncel olduğundan emin olmak için önbellekteki başvuru verilerini düzenli aralıklarla güncelleştiren bir arka plan işlemine sahip olmak isteyebilirsiniz. Alternatif olarak, başvuru verileri değiştiğinde arka plan işlemi önbelleği yenileyebilir.
Bazı özel durumları olsa da, önbelleğe alma işlemi dinamik veriler için daha az yararlıdır (daha fazla bilgi için bu makalenin sonraki bölümlerinde yer alan Yüksek oranda dinamik verileri önbelleğe alma bölümüne bakın). Özgün veriler düzenli olarak değiştiğinde, önbelleğe alınan bilgiler hızla eskir veya önbelleği özgün veri deposuyla eşitleme yükü önbelleğe alma etkinliğini azaltır.
Önbelleğin bir varlığın tüm verilerini içermesi gerekmez. Örneğin, bir veri öğesi ad, adres ve hesap bakiyesi olan bir banka müşterisi gibi çok değerli bir nesneyi temsil ederse, bu öğelerden bazıları ad ve adres gibi statik kalabilir. Hesap bakiyesi gibi diğer öğeler daha dinamik olabilir. Bu gibi durumlarda, verilerin statik bölümlerini önbelleğe almak ve yalnızca gerekli olduğunda kalan bilgileri almak (veya hesaplamak) yararlı olabilir.
Önbelleğin önceden doldurulup doldurulmadığını veya isteğe bağlı olarak yüklenmesinin veya ikisinin bir bileşiminin uygun olup olmadığını belirlemek için performans testi ve kullanım analizi gerçekleştirmenizi öneririz. Bu karar, verilerin geçiciliğine ve kullanım düzenine göre verilmelidir. Önbellek kullanımı ve performans analizi, ağır yüklerle karşılaşan ve yüksek oranda ölçeklenebilir olması gereken uygulamalarda önemlidir. Örneğin, yüksek oranda ölçeklenebilir senaryolarda yoğun zamanlarda veri deposundaki yükü azaltmak için önbelleğin dağıtımını yapabilirsiniz.
Önbelleğe alma işlemi ayrıca uygulama çalışırken hesaplamaları yinelemekten kaçınmak için kullanılabilir. Bir işlem veri dönüştürüyor ve karmaşık bir hesaplama gerçekleştiriyorsa, işlemin sonuçlarını önbelleğe kaydedebilir. Aynı hesaplama daha sonra gerekli olursa, uygulama önbellekten sonuçları alabilir.
Uygulama, önbellekte tutulan verileri değiştirebilir. Ancak, önbelleğin her an kaybolabilecek geçici bir veri deposu olarak düşünülmesi önerilir. Değerli verileri yalnızca önbellekte depolamayın; bilgileri özgün veri deposunda da sakladığınıza emin olun. Böylece, önbellek kullanılamaz duruma gelirse veri kaybetme olasılığını en aza indirirsiniz.
Hızla değişen bilgileri kalıcı bir veri deposunda depoladığınızda, bu durum sisteme ek yük getirebilir. Örneğin, sürekli olarak durum veya başka bir ölçüm bildiren bir cihaz düşünün. Bir uygulama, önbelleğe alınan bilgilerin neredeyse her zaman eski olacağı gerekçesiyle bu verileri önbelleğe almamayı seçerse, aynı gerekçe veri deposundan bu bilgileri depolayıp alırken de geçerli olabilir. Bu verileri kaydetmek ve getirmek için geçen sürede veriler değişmiş olabilir.
Bunun gibi bir durumda, dinamik bilgileri kalıcı veri deposu yerine doğrudan önbellekte depolamanın avantajlarını göz önünde bulundurun. Veriler kritik değilse ve denetim gerekmiyorsa, zaman zaman yapılan değişikliğin kaybedilip kaybedilmesi önemli değildir.
Çoğu durumda, bir önbellekte tutulan veriler özgün veri deposunda tutulan verilerin bir kopyasıdır. Özgün veri deposundaki veriler önbelleğe alındıktan sonra değişebilir ve önbelleğe alınmış verilerin eskimesine yol açabilir. Birçok önbelleğe alma sistemi, önbelleği verilerin süresi dolacak ve eski verilerin kalabileceği süreyi azaltacak şekilde yapılandırmanıza olanak tanır.
Önbelleğe alınan verilerin süresi dolduğunda önbellekten kaldırılır ve uygulamanın verileri özgün veri deposundan alması gerekir (yeni getirilen bilgileri önbelleğe geri alabilir). Önbelleği yapılandırırken varsayılan bir süre sonu ilkesi ayarlayabilirsiniz. Birçok önbellek hizmetinde, önbellekte program aracılığıyla depoladığınız her bir nesne için de süre sonu belirtebilirsiniz. Bazı önbellekler, son kullanma süresini mutlak bir değer olarak veya belirtilen süre içinde erişilmiyorsa öğenin önbellekten kaldırılmasına neden olan kayan değer olarak belirtmenizi sağlar. Bu ayar, yalnızca belirtilen nesneler için önbellek genelindeki süre sonu ilkesini geçersiz kılar.
Not
Önbellek için süre sonunu ve içerdiği nesneleri dikkatlice düşünün. Süreyi çok kısa tutarsanız nesnelerin süresi çok çabuk dolar ve önbelleği kullanma avantajları azalır. Süreyi çok uzun tutarsanız verileri eskitme riski oluşur.
Verilerin çok uzun süre kalmasına izin verilirse önbelleğin dolması da mümkündür. Bu durumda, önbelleğe yeni öğe eklemeye yönelik her istek, bazı öğelerin çıkarma olarak bilinen bir işlemde zorla kaldırılmasına yol açabilir. Önbellek hizmetleri genellikle verileri en uzak zamanda kullanılan (LRU) verilere göre çıkarır, ancak genellikle bu ilkeyi geçersiz kılabilir ve öğelerin çıkarılmasını engelleyebilirsiniz. Ancak, bu yaklaşımı benimserseniz önbellekte mevcut olan belleği aşma riski oluşturabilirsiniz. Önbelleğe öğe eklemeye çalışan bir uygulama bir özel durum dışında başarısız olur.
Bazı önbelleğe alma uygulamaları, ek çıkarma ilkeleri sağlayabilir. Çıkarma ilkelerinin birkaç türü vardır. Bu modüller şunlardır:
- En son kullanılan ilke (verilerin yeniden gerekli olmayacağı beklentisi ile).
- İlk giren ilk çıkar ilkesi (en eski veriler ilk önce çıkarılır).
- Tetiklenen bir olaya dayalı açık bir kaldırma ilkesi (verilerin değiştirilmesi gibi).
İstemci tarafı önbelleğinde tutulan verilerin genellikle istemciye veri sağlayan hizmetin gözetimi dışında olduğu kabul edilir. Bir hizmet, istemciyi doğrudan istemci tarafı önbelleğine bilgi eklemeye veya kaldırmaya zorlayamaz.
Diğer bir deyişle, kötü yapılandırılmış önbellek kullanan bir istemcinin süresi geçmiş bilgileri kullanmaya devam etmesi mümkündür. Örneğin, önbelleğin süre sonu ilkeleri düzgün bir şekilde uygulanmazsa, istemci özgün veri kaynağındaki bilgiler değiştiğinde yerel olarak önbelleğe alınmış eski bilgileri kullanabilir.
HTTP bağlantısı üzerinden veri sunan bir web uygulaması oluşturursanız, bir web istemcisini (tarayıcı veya web ara sunucusu gibi) en son bilgileri getirmeye örtük olarak zorlayabilirsiniz. Bir kaynak, kaynağın URI'sindeki bir değişiklik ile güncelleştirilirse bunu yapabilirsiniz. Web istemcileri genellikle bir kaynağın URI’sini istemci tarafı önbelleğinde anahtar olarak kullanır; bu nedenle, URI değişirse web istemcisi bir kaynağın daha önce önbelleğe alınmış tüm sürümlerini yok sayar ve onun yerine yeni sürümü getirir.
Önbellekler genellikle bir uygulamanın birden fazla örneği tarafından paylaşılacak şekilde tasarlanır. Her uygulama örneği, önbellekteki verileri okuyup değiştirebilir. Sonuç olarak, paylaşılan her deposunda gerçekleşen eşzamanlılık sorunlarının aynısı önbellek için de geçerli olur. Bir uygulamanın önbellekte tutulan verileri değiştirmesi gereken bir durumda, uygulamanın bir örneği tarafından yapılan güncelleştirmelerin başka bir örnek tarafından yapılan değişikliklerin üzerine yazılmadığından emin olmanız gerekebilir.
Verilerin niteliğine ve çakışma olasılığına bağlı olarak iki eşzamanlılık yaklaşımından birini benimseyebilirsiniz:
- İyimser. Verileri güncelleştirmeden hemen önce uygulama, önbellekteki verilerin alındıktan sonra değiştirilip değiştirilmediğini denetler. Veri hala aynı ise değişiklik yapılabilir. Aksi takdirde, uygulamanın güncelleştirip güncelleştirmeyeceğine karar vermesi gerekir. (Bu kararı yönlendiren iş mantığı uygulamaya özgü olacaktır.) Bu yaklaşım, güncelleştirmelerin seyrek gerçekleştiği veya çakışmaların gerçekleşme olasılığının düşük olduğu durumlar için uygundur.
- Kötümser. Uygulama, verileri aldığında başka bir örneğin değiştirmesini önlemek için önbelleğe kilitler. Bu işlem çakışmaların oluşmamasını sağlar, ancak aynı verileri işlemesi gereken diğer örnekleri de engelleyebilir. Kötümser eşzamanlılık, bir çözümün ölçeklenebilirliğini etkileyebilir ve yalnızca kısa süreli işlemler için önerilir. Bu yaklaşım, çakışma olasılığının daha yüksek olduğu durumlarda, özellikle bir uygulama önbellekteki birden fazla öğeyi güncelleştiriyorsa ve bu değişikliklerin tutarlı bir şekilde uygulandığından emin olması gerekiyorsa uygun olabilir.
Bir önbelleği birincil veri deposu olarak kullanmamaya özen gösterin; bu, önbelleğin doldurulduğu özgün veri deposunun rolüdür. Özgün veri deposu, verilerin sürekliliğini sağlamaktan sorumludur.
Çözümlerinizde, paylaşılan bir önbellek hizmetinin kullanılabilirliğine yönelik kritik bağımlılıklar oluşturmamaya dikkat edin. Paylaşılan önbelleği sağlayan hizmet kullanılamıyorsa, uygulama çalışmaya devam edebilmelidir. Uygulama yanıt vermemeye başlamamalı veya önbellek hizmetinin sürdürülmesi beklenirken başarısız olmamalıdır.
Bu nedenle uygulama, önbellek hizmetinin kullanılabilirliğini algılamaya hazır olmalı ve önbellek erişilemez durumdaysa özgün veri deposuna geri dönmelidir. Bu senaryoyu gerçekleştirmek için Devre Kesici düzeni yararlıdır. Önbelleği sağlayan hizmet kurtarılabilir ve kullanılabilir hale geldikten sonra veriler özgün veri deposundan okunurken Edilgen Önbellek düzeni gibi bir strateji izlenerek önbellek önceden doldurulabilir.
Ancak önbellek geçici olarak kullanılamadığında uygulama özgün veri deposuna geri düşerse sistem ölçeklenebilirliği etkilenebilir. Veri deposu kurtarılırken özgün veri deposuna çok sayıda veri isteği gidebilir, bu yüzden zaman aşımları ve bağlantı hataları yaşanabilir.
Bir uygulamanın her örneğinde tüm uygulama örneklerinin eriştiği ortak önbellekle birlikte yerel ve özel bir önbellek uygulamayı düşünün. Uygulama bir öğeyi aldığında öncelikle yerel önbelleğini, sonra paylaşılan önbelleğini ve son olarak özgün veri deposunu denetleyebilir. Yerel önbellek, paylaşılan önbellekteki veya paylaşılan önbellek kullanılamıyorsa veritabanındaki veriler kullanılarak doldurulabilir.
Bu yaklaşım, yerel önbelleğin paylaşılan önbelleğe göre çok eski duruma gelmesini önleyen dikkatli bir yapılandırma gerektirir. Bununla birlikte, paylaşılan önbellek ulaşılamaz durumdaysa yerel önbellek bir arabellek gibi davranır. Şekil 3'te bu yapı gösterilmiştir.
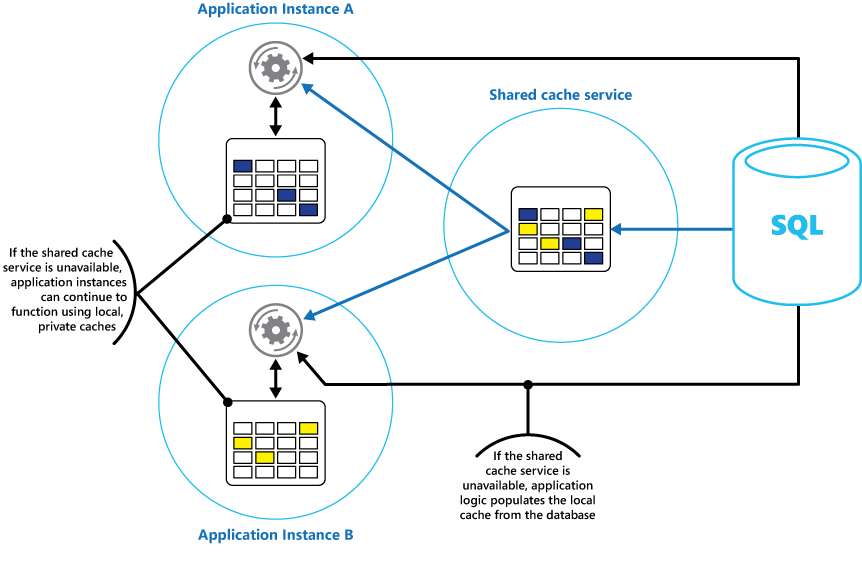
Şekil 3: Paylaşılan önbellekle yerel özel önbellek kullanma.
Görece uzun süreli veriler tutan büyük önbellekleri desteklemek için bazı önbellek hizmetleri, önbellek kullanılamaz hale gelirse otomatik yük devretme uygulayan bir yüksek kullanılabilirlik seçeneği sağlar. Bu yaklaşım genellikle bir birincil önbellek sunucusunda depolanmış önbelleğe alınmış verilerin bir ikincil önbellek sunucusuna çoğaltılmasını ve birincil sunucu başarısız olur ya da bağlantı kaybedilirse ikincil sunucuya geçmeyi içerir.
Birden çok hedefe yazma ile ilişkili gecikme süresini azaltmak için, veriler birincil sunucudaki önbelleğe yazılırken ikincil sunucuya çoğaltma işlemi zaman uyumsuz olarak gerçekleşebilir. Bu yaklaşım, bir hata olduğunda önbelleğe alınan bazı bilgilerin kaybedilme olasılığına yol açar, ancak bu verilerin oranı önbelleğin genel boyutuna kıyasla küçük olmalıdır.
Paylaşılan önbellek büyükse, çekişme olasılığını azaltmak ve ölçeklenebilirliği artırmak için düğümler arasındaki önbelleğe alınmış verilerin bölümlere ayrılması faydalı olabilir. Birçok paylaşılan önbellek, dinamik olarak düğüm ekleme (ve kaldırma) özelliğini destekler ve bölümler arasında verileri yeniden dengeler. Bu yaklaşım, düğüm koleksiyonlarının istemci uygulamalara sorunsuz, tek bir önbellek olarak sunulduğu küme oluşturma işlemini gerektirebilir. Ancak, dahili olarak veriler yükü eşit şekilde dengeleyen önceden tanımlanmış bir dağıtım stratejisine göre düğümler arasında dağıtılır. Olası bölümleme stratejileri hakkında daha fazla bilgi için bkz . Veri bölümleme kılavuzu.
Kümeleme işlemi de önbelleğin kullanılabilirliğini artırabilir. Bir düğüm başarısız olursa, önbelleğin geri kalanına hala erişilebilir. Kümeleme sıklıkla çoğaltma ve yük devretme ile birlikte kullanılır. Her düğüm çoğaltılabilir ve düğüm başarısız olursa çoğaltma hızlıca çevrimiçi duruma getirilebilir.
Birçok okuma ve yazma işlemi muhtemelen tek verili değerler veya nesneler içerir. Ancak, bazen büyük hacimlerde verilerin hızlıca depolanması veya alınması gerekebilir. Örneğin, bir önbelleğin dağıtılması için yüzlerce veya binlerce öğenin önbelleğe yazılması gerekebilir. Ayrıca, bir uygulamanın, aynı isteğin parçası olarak çok sayıda ilgili öğeyi önbellekten alması gerekli olabilir.
Çok sayıda büyük ölçekli önbellek bu amaçla toplu işlemler sağlar. Bu özellik, bir istemci uygulamanın büyük hacimli öğeleri tek bir istek halinde paketlemesini sağlar ve çok sayıda küçük isteği gerçekleştirmeyle ilgili ek yükü azaltır.
Edilgen önbellek düzeninin işe yaraması için, uygulamanın önbelleği dolduran örneğinin en son ve en tutarlı veri sürümüne erişiminin olması gerekir. Son tutarlılığı uygulayan bir sistemde (çoğaltılmış veri deposu gibi), bu durum geçerli olmayabilir.
Uygulamanın bir örneği bir veri öğesini değiştirebilir ve bu öğenin önbelleğe alınmış sürümünü geçersiz hale getirebilir. Uygulamanın başka bir örneği, bu öğeyi bir önbellekten okumaya çalışarak önbellek kaçağına neden olabilir, bu nedenle verileri veri deposundan okur ve önbelleğe ekler. Ancak, veri deposu diğer çoğaltmalarla tam olarak eşitlenmemişse, uygulama örneği önbelleği okuyabilir ve eski değerle doldurabilir.
Veri tutarlılığını işleme hakkında daha fazla bilgi için bkz. Veri tutarlılığı temel bilgileri.
Kullandığınız önbellek hizmetine bakılmaksızın, önbellekte tutulan verilerin yetkisiz erişimden nasıl korunacağını düşünün. İki temel sorun vardır:
- Önbellekteki verilerin gizliliği.
- Önbellek ile önbelleği kullanan uygulama arasında akan verilerin gizliliği.
Önbellekteki verileri korumak için, önbellek hizmeti uygulamaların aşağıdakileri belirtmesini gerektiren bir kimlik doğrulama mekanizması uygulayabilir:
- Önbellekteki verilere hangi kimliklerin erişebileceği.
- Bu kimliklerin hangi işlemleri (okuma ve yazma) gerçekleştirmesine izin verildiği.
Verileri okuma ve yazma ile ilişkili ek yükü azaltmak için, bir kimliğe önbellekte yazma veya okuma erişimi verildikten sonra, bu kimlik önbellekteki tüm verileri kullanabilir.
Önbelleğe alınan verilerin alt kümelerine erişimi kısıtlamanız gerekirse aşağıdakilerden birini yapabilirsiniz:
- Önbelleği bölümlere ayırın (farklı önbellek sunucuları kullanarak) ve kimliklere yalnızca kullanmalarına izin verilen bölümler için erişim verin.
- Farklı anahtarlar kullanarak her bir alt kümedeki verileri şifreleyin ve yalnızca her bir kümeye erişebilmesi gereken kimliklere şifreleme anahtarları sağlayın. Bir istemci uygulama hala önbellekteki verilerin tümünü alabilir, ancak yalnızca anahtarları olan verilerin şifresini çözebilecektir.
Ayrıca, önbellek içine ve dışına akan verileri korumanız gerekir. Bunun yapılması, istemci uygulamaların önbelleğe bağlanmak üzere kullandığı ağ altyapısı tarafından sağlanan güvenlik özelliklerine bağlıdır. Önbellek, istemci uygulamaları barındıran aynı kuruluş içindeki yerinde bir sunucu kullanılarak uygulanmışsa, ağın kendisini yalıtmak için ek adımlar uygulamanız gerekmeyebilir. Önbellek uzaktaysa ve bir ortak ağ (İnternet gibi) üzerinden TCP veya HTTP bağlantısı gerektiriyorsa, SSL uygulamayı düşünün.
Redis için Azure Cache, Azure veri merkezinde hizmet olarak çalışan açık kaynak Redis önbelleğinin bir uygulamasıdır. Bulut hizmeti, web sitesi veya bir Azure sanal makinesi içinde uygulanmasına bakılmaksızın herhangi bir Azure uygulamasından erişilebilen bir önbelleğe alma hizmeti sağlar. Önbellekler, uygun erişim anahtarına sahip istemci uygulamalar tarafından paylaşılabilir.
Redis için Azure Cache kullanılabilirlik, ölçeklenebilirlik ve güvenlik sağlayan yüksek performanslı bir önbelleğe alma çözümüdür. Genellikle bir veya daha fazla ayrılmış makineye yayılmış bir hizmet olarak çalışır. Hızlı erişim sağlamak için bellekte mümkün olduğunca fazla bilgi depolamaya çalışır. Bu mimari, yavaş G/Ç işlemleri gerçekleştirme gereksinimini azaltarak düşük gecikme süresi ve yüksek aktarım hızı sağlamaya yöneliktir.
Redis için Azure Cache, istemci uygulamaları tarafından kullanılan çeşitli API'lerin çoğuyla uyumludur. Şirket içinde çalışan Redis için Azure Cache kullanan mevcut uygulamalarınız varsa, Redis için Azure Cache bulutta önbelleğe almak için hızlı bir geçiş yolu sağlar.
Redis basit bir önbellek sunucusundan fazlasıdır. Çok sayıda senaryoyu destekleyen kapsamlı bir komut kümesi ile dağıtılmış bir bellek içi veritabanı sağlar. Bu konular bu belgede daha sonra Redis önbelleğini kullanma bölümünde açıklanmaktadır. Bu bölümde Redis tarafından sağlanan bazı temel özellikler özetlenmektedir.
Redis hem okuma hem de yazma işlemlerini destekler. Redis’te yazma işlemleri düzenli aralıklarla bir yerel anlık görüntü dosyasında ya da yalnızca eklenebilen günlük dosyasında depolanarak sistem hatasından korunabilir. Bu durum, geçişli veri depoları olarak kabul edilmesi gereken birçok önbellekte böyle değildir.
Tüm yazma işlemleri zaman uyumsuz olur ve istemcilerin veri okumalarını ve yazmalarını engellemez. Redis çalışmaya başladığında anlık görüntü ya da günlük dosyasından verileri okur ve bu verileri bellek içi önbelleği oluşturmak için kullanır. Daha fazla bilgi için Redis web sitesindeki Redis kalıcılığı bölümüne bakın.
Not
Redis, yıkıcı bir hata olduğunda tüm yazmaların kaydedileceğini garanti etmez, ancak en kötü ihtimalle yalnızca birkaç saniyelik verileri kaybedebilirsiniz. Bir önbelleğin yetkili bir veri kaynağı olarak davranması amaçlanmamıştır ve kritik verilerin uygun bir veri deposuna başarıyla kaydedilmesini sağlamak için önbelleği kullanan uygulamaların sorumluluğundadır. Daha fazla bilgi için bkz. Edilgen önbellek düzeni.
Redis; değerlerin basit türler ya da karmalar, listeler ve kümeler gibi karmaşık türler içerebildiği bir anahtar-değer deposudur. Bu veri türlerinde atomik işlemleri destekler. Anahtarları kalıcı olabilir veya sınırlı bir yaşam süresi ile etiketlenebilir. Sınırlı yaşam süresi olduğunda anahtar ve karşılık gelen değeri, önbellekten otomatik olarak kaldırılır. Redis anahtarları ve değerleri hakkında daha fazla bilgi için Redis web sitesinde Redis veri türleri ve soyutlamalarına giriş sayfasını ziyaret edin.
Redis, kullanılabilirliği sağlamaya ve aktarım hızını korumaya yardımcı olmak için birincil/alt çoğaltmayı destekler. Redis birincil düğümüne yazma işlemleri bir veya daha fazla alt düğüme çoğaltılır. Okuma işlemleri birincil veya alt işlemlerden herhangi biri tarafından sunulur.
Bir ağ bölümünüz varsa, astlar verileri sunmaya devam edebilir ve ardından bağlantı yeniden başlatıldığında birincil bölümle saydam olarak yeniden eşitlenebilir. Daha fazla ayrıntı için Redis web sitesinde Çoğaltma sayfasını ziyaret edin.
Redis ayrıca verileri sunucular arasında saydam bir şekilde parçalara bölmenize ve yükü dağıtmanıza olanak tanıyan kümeleme özelliğini sağlar. Önbellek boyutu arttıkça yeni Redis sunucuları eklenebildiği ve veriler yeniden bölümlenebildiği için bu özellik ölçeklenebilirliği artırır.
Ayrıca, kümedeki her sunucu birincil/alt çoğaltma kullanılarak çoğaltılabilir. Böylece, kümedeki her düğümde kullanılabilirlik sağlanır. Kümeleme ve parçalama hakkında daha fazla bilgi için Redis web sitesinde Redis kümesi öğretici sayfasını ziyaret edin.
Redis önbelleği, ana bilgisayarda kullanılabilir kaynaklara bağlı olan sınırlı bir boyuta sahiptir. Bir Redis sunucusunu yapılandırırken kullanabileceği en büyük bellek miktarını belirtebilirsiniz. Ayrıca, redis önbelleğindeki bir anahtarı son kullanma süresine sahip olacak şekilde yapılandırabilir ve ardından bu anahtar önbellekten otomatik olarak kaldırılır. Bu özellik, bellek içi önbelleğin eski veya tarihi geçmiş verilerle doldurulmasını önlemeye yardımcı olabilir.
Bellek doldukça Redis birkaç ilkeyi izleyerek anahtarları ve değerlerini otomatik olarak çıkarabilir. Varsayılan değer LRU'dur (en son kullanılır), ancak anahtarları rastgele çıkarma veya çıkarma işlemini tamamen kapatma gibi diğer ilkeleri de seçebilirsiniz (bu durumda, önbelleğe öğe ekleme girişimi doluysa başarısız olur). Redis’i LRU önbelleği olarak kullanma sayfasında daha fazla bilgi verilmektedir.
Redis bir istemci uygulamanın önbellekte atomik bir işlem olarak veri okuyup yazan bir dizi işlem göndermesine olanak tanır. İşlemdeki tüm komutların sırayla çalışması garanti edilir ve diğer eşzamanlı istemciler tarafından gönderilen hiçbir komut bunlar arasında birbirine karışmaz.
Ancak bunlar ilişkisel bir veritabanı tarafından gerçekleştirileceğinden gerçek işlemler değildir. İşlem iki aşamada gerçekleştirilir: Birinci aşamada komutlar kuyruğa alınır, ikincisinde ise komutlar çalıştırılır. Komutu kuyruğa alma aşamasında işlemi oluşturan komutlar istemci tarafından gönderilir. Bu noktada bir tür hata oluşursa (söz dizimi hatası veya yanlış sayıda parametre gibi), Redis işlemin tamamını gerçekleştirmeyi reddeder ve işlemi iptal eder.
Çalıştırma aşamasında Redis, kuyruğa alınmış her bir komutu sırayla gerçekleştirir. Bu aşamada bir komut başarısız olursa, Redis bir sonraki kuyruğa alınan komutla devam eder ve zaten çalıştırılmış olan komutların etkilerini geri almaz. Bu basit işlem biçimi, performansı korumaya yardımcı olur ve çekişmeden kaynaklanan performans sorunlarını önler.
Redis, tutarlılığı sürdürmeye yardımcı olmak üzere iyimser türde bir kilitleme uygulamaz. İşlemler ve Redis ile kilitleme hakkında ayrıntılı bilgi için Redis web sitesinde İşlemler sayfasını ziyaret edin.
Redis, isteklerin işlem dışı toplu işlemlerini de destekler. İstemcilerin bir Redis sunucusuna komut göndermek için kullandığı Redis protokolü, bir istemcinin aynı istek kapsamında bir dizi işlem göndermesini sağlar. Bu özellik, ağ üzerinde paket parçalanmasını azaltmaya yardımcı olabilir. Toplu iş gerçekleştirilirken her bir komut uygulanır. Bu komutlardan herhangi biri yanlış biçimlendirilmişse reddedilir (işlemle gerçekleşmez), ancak kalan komutlar gerçekleştirilir. Toplu işteki komutların işlenme sırası hakkında da bir garanti yoktur.
Redis yalnızca verilere hızlı erişim sağlamaya odaklanır ve yalnızca güvenilir istemcilerin erişebildiği güvenilir bir ortamda çalışacak şekilde tasarlanmıştır. Redis, parola ile kimlik doğrulamasını temel alan sınırlı bir güvenlik modelini destekler. (Bunu önermesek de kimlik doğrulamasını tamamen kaldırmak mümkündür.)
Kimliği doğrulanmış tüm istemciler aynı genel parolayı paylaşır ve aynı kaynaklara erişime sahiptir. Daha kapsamlı bir oturum açma güvenliğine gereksinim duyuyorsanız, Redis sunucusunun önünde kendi güvenlik katmanınızı uygulamanız ve tüm istemci isteklerinin bu ek katmandan geçmesi gerekir. Redis'in güvenilmeyen veya kimliği doğrulanmamış istemcilere doğrudan açık olmaması gerekir.
Komutları devre dışı bırakarak veya yeniden adlandırarak (ve yalnızca yeni adlara sahip ayrıcalıklı istemciler sağlayarak) komutlara erişimi kısıtlayabilirsiniz.
Redis herhangi bir veri şifreleme biçimini doğrudan desteklemez, bu nedenle tüm kodlamanın istemci uygulamaları tarafından gerçekleştirilmesi gerekir. Ayrıca, Redis herhangi bir aktarım güvenliği sağlamaz. Ağda akan verileri korumanız gerekiyorsa SSL ara sunucusu kullanmanız önerilir.
Daha fazla bilgi için Redis web sitesindeki Redis güvenliği sayfasını ziyaret edin.
Not
Redis için Azure Cache, istemcilerin bağlandığı kendi güvenlik katmanını sağlar. Temel alınan Redis sunucuları genel ağa sunulmaz.
Redis için Azure Cache, Bir Azure veri merkezinde barındırılan Redis sunucularına erişim sağlar. Erişim denetimi ve güvenlik sağlayan bir cephe gibi hareket eder. Azure portalını kullanarak bir önbellek sağlayabilirsiniz.
Portal, önceden tanımlanmış birkaç yapılandırma sağlar. Bunlar, %99,9 kullanılabilirlik hizmet düzeyi sözleşmesi (SLA) ile SSL iletişimini (gizlilik için) ve ana/alt çoğaltmayı destekleyen ayrılmış bir hizmet olarak çalışan 53 GB önbellekten, paylaşılan donanımda çalıştırılan çoğaltma olmadan 250 MB önbelleğe (kullanılabilirlik garantisi yok) kadar değişir.
Azure portalını kullanarak önbelleğin çıkarma ilkesini de yapılandırabilir ve sağlanan rollere kullanıcı ekleyerek önbelleğe erişimi denetleyebilirsiniz. Üyelerin gerçekleştirebileceği işlemleri tanımlayan bu roller Sahip, Katkıda Bulunan ve Okuyucu rolleridir. Örneğin, Sahip rolünün üyeleri önbellek (güvenlik dahil) ve içerikleri üzerinde tam denetime sahiptir, Katkıda Bulunan rolünün üyeleri önbellekteki bilgileri okuyup yazabilir ve Okuyucu rolünün üyeleri yalnızca önbellekten veri alabilir.
Çoğu yönetim görevi Azure portalı üzerinden gerçekleştirilir. Bu nedenle, yapılandırmayı program aracılığıyla değiştirme, Redis sunucusunu kapatma, ek astları yapılandırma veya verileri zorla diske kaydetme gibi standart Redis sürümünde kullanılabilen yönetim komutlarının çoğu kullanılamaz.
Azure portalı, önbelleğin performansını izlemenize olanak tanıyan kolay bir grafik görüntüsü içerir. Örneğin, kurulan bağlantı sayısını, gerçekleştirilen istek sayısını, okuma ve yazma işlemleri hacmini ve önbellek isabetlerinin önbellek kaçaklarına oranını görüntüleyebilirsiniz. Bu bilgileri kullanarak, önbelleğin verimliliğini belirleyebilir ve gerekirse farklı bir yapılandırmaya geçebilir veya çıkarma ilkesini değiştirebilirsiniz.
Ayrıca, bir veya daha fazla kritik ölçüm beklenen aralığın dışındaysa yöneticiye e-posta iletileri gönderen uyarılar oluşturabilirsiniz. Örneğin, önbellek kaçaklarının sayısı son bir saat içinde belirtilen değeri aşıyorsa, bu durum önbelleğin çok küçük olabileceği veya verilerin çok hızlı çıkarılabileceği anlamına geldiğinden yöneticiyi uyarmak isteyebilirsiniz.
Ayrıca, önbelleğin CPU, bellek ve ağ kullanımını da izleyebilirsiniz.
Redis için Azure Cache oluşturma ve yapılandırma hakkında daha fazla bilgi ve örnek için Azure blogundaki Redis için Azure Cache etrafında tur sayfasını ziyaret edin.
Azure web rollerini kullanarak çalışan ASP.NET web uygulamaları oluşturursanız, oturum durumu bilgilerini ve HTML çıkışını bir Redis için Azure Cache kaydedebilirsiniz. Redis için Azure Cache için oturum durumu sağlayıcısı, bir ASP.NET web uygulamasının farklı örnekleri arasında oturum bilgilerini paylaşmanızı sağlar ve istemci-sunucu benziminin kullanılamadığı ve bellek içindeki oturum verilerini önbelleğe almanın uygun olmadığı web grubu durumlarında çok yararlıdır.
Oturum durumu sağlayıcısının Redis için Azure Cache ile kullanılması aşağıdakiler gibi çeşitli avantajlar sağlar:
- Oturum durumunu çok sayıda ASP.NET web uygulaması örneğiyle paylaşma.
- Geliştirilmiş ölçeklenebilirlik sağlama.
- Birden fazla okuyucu ve tek yazar için aynı oturum durumu verilerine denetimli, eşzamanlı erişimi denetleme.
- Bellek kaydetme ve ağ performansını iyileştirme amacıyla sıkıştırmayı kullanma.
Daha fazla bilgi için bkz. Redis için Azure Cache için oturum durumu sağlayıcısı ASP.NET.
Not
Azure ortamının dışında çalışan ASP.NET uygulamalarla Redis için Azure Cache için oturum durumu sağlayıcısını kullanmayın. Önbelleğe Azure dışından erişimin neden olduğu gecikme süresi, verileri önbelleğe almanın performans avantajlarını ortadan kaldırabilir.
Benzer şekilde, Redis için Azure Cache için çıkış önbelleği sağlayıcısı, bir ASP.NET web uygulaması tarafından oluşturulan HTTP yanıtlarını kaydetmenizi sağlar. Çıktı önbelleği sağlayıcısının Redis için Azure Cache ile kullanılması, karmaşık HTML çıkışını işleyen uygulamaların yanıt sürelerini iyileştirebilir. Benzer yanıtlar oluşturan uygulama örnekleri, bu HTML çıkışını yeniden oluşturmak yerine önbellekteki paylaşılan çıkış parçalarını kullanabilir. Daha fazla bilgi için bkz. Redis için Azure Cache için çıktı önbelleği sağlayıcısı ASP.NET.
Redis için Azure Cache, temel alınan Redis sunucuları için bir cephe görevi görür. Azure Redis önbelleği (53 GB'tan büyük önbellek gibi) kapsamında olmayan gelişmiş bir yapılandırmaya ihtiyacınız varsa, Azure Sanal Makineler kullanarak kendi Redis sunucularınızı derleyebilir ve barındırabilirsiniz.
Bu karmaşık olabilecek bir işlemdir çünkü çoğaltma uygulamak istiyorsanız birincil ve alt düğümler olarak görev yapmak için birkaç VM oluşturmanız gerekebilir. Ayrıca, bir küme oluşturmak istiyorsanız birden çok birincil sunucuya ve alt sunucuya ihtiyacınız vardır. Yüksek düzeyde kullanılabilirlik ve ölçeklenebilirlik sağlayan en düşük kümelenmiş çoğaltma topolojisi, üç çift birincil/alt sunucu olarak düzenlenmiş en az altı VM'lerden oluşur (bir küme en az üç birincil düğüm içermelidir).
Gecikme süresini en aza indirmek için her birincil/alt çift birbirine yakın bir yerde bulunmalıdır. Ancak, önbelleğe alınan verileri kullanma olasılığı en yüksek uygulamaların yakınına konumlandırmak isterseniz, her çift kümesi farklı bölgelerde bulunan farklı Azure veri merkezlerinde çalışabilir. Azure VM olarak çalışan bir Redis düğümü derleme ve yapılandırma örneği için bkz. Azure’da CentOS Linux sanal makinesinde Redis’i çalıştırma.
Not
Kendi Redis önbelleğinizi bu şekilde uygularsanız, hizmeti izlemek, yönetmek ve güvenliğini sağlamak sizin sorumluluğunuzdadır.
Önbelleğin bölümlenmesi için önbelleğin birden fazla bilgisayara bölünmesi gerekir. Bu yapı, tek bir önbellek sunucusu kullanmaya göre aşağıdaki birkaç avantajı sağlar:
- Tek bir sunucuda depolanabilecek boyuttan çok daha büyük bir önbellek oluşturma.
- Verileri sunucular arasında dağıtma, kullanılabilirliği artırma. Bir sunucu arıza yapar veya erişilemez duruma gelirse, içindeki veriler kullanılamaz ancak kalan sunuculardaki verilere hala erişilebilir. Önbellek için bu önemli değildir çünkü önbelleğe alınan veriler yalnızca veritabanında tutulan verilerin geçici bir kopyasıdır. Erişilemez duruma gelen bir sunucuda önbelleğe alınmış veriler, farklı bir sunucuda önbelleğe alınabilir.
- Yükü sunucular arasında yayma, böylece performans ve ölçeklenebilirliği geliştirme.
- Verileri, veriye erişen kullanıcıların yakınındaki bir coğrafi bölgeye konumlandırma, böylece gecikme süresini azaltma.
Bir önbellek için en yaygın bölümleme türü parçalamadır. Bu stratejide her bölüm (veya parça) kendi çapında bir Redis önbelleğidir. Veriler, verileri dağıtmaya yönelik çeşitli yaklaşımlar kullanabilen parçalama mantığı kullanılarak belirli bir bölüme yönlendirilir. Parçalama düzeni bölümünde parçalama uygulaması hakkında daha fazla bilgi verilmektedir.
Bir Redis önbelleğinde bölümlemeyi uygulamak için aşağıdaki yaklaşımlardan birini benimseyebilirsiniz:
- Sunucu tarafı sorgu yönlendirme. Bu teknikte bir istemci uygulama, önbelleği oluşturan Redis sunucularından herhangi birine (muhtemelen en yakın sunucuya) bir istek gönderir. Her Redis sunucusu, içerdiği bölümü açıklayan meta verileri depolar ve ayrıca diğer sunucularda hangi bölümlerin bulunduğu hakkında bilgi içerir. Redis sunucusu, istemci isteğini inceler. Yerel olarak çözülebiliyorsa istenen işlemi gerçekleştirir. Aksi takdirde isteği uygun sunucuya iletir. Bu model Redis kümeleme ile gerçekleştirilir ve Redis web sitesinin Redis kümesi öğreticisi sayfasında daha ayrıntılı olarak açıklanır. Redis kümelemesi istemci uygulamaları için saydamdır ve istemcileri yeniden yapılandırmanıza gerek kalmadan kümeye ek Redis sunucuları eklenebilir (ve veriler yeniden bölümlenebilir).
- İstemci-tarafı bölümleme. Bu modelde istemci uygulama, istekleri uygun Redis sunucusuna yönlendiren mantığı (büyük olasılıkla bir kitaplık biçiminde) içerir. Bu yaklaşım Redis için Azure Cache ile kullanılabilir. Birden çok Redis için Azure Cache (her veri bölümü için bir tane) oluşturun ve istekleri doğru önbelleğe yönlendiren istemci tarafı mantığını uygulayın. Bölümleme düzeni değişirse (örneğin ek Redis için Azure Cache oluşturulursa), istemci uygulamalarının yeniden yapılandırılması gerekebilir.
- Ara sunucu destekli bölümleme. Bu düzende istemci uygulamalar, istekleri verilerin nasıl bölümlendiğini anlayan bir ara sunucu hizmetine gönderir ve sonra isteği uygun Redis sunucusuna yönlendirir. Bu yaklaşım Redis için Azure Cache ile de kullanılabilir; ara sunucu hizmeti bir Azure bulut hizmeti olarak uygulanabilir. Bu yaklaşım, hizmeti uygulamak için ilave bir karmaşıklık düzeyi gerektirir ve isteklerin gerçekleştirilmesi, istemci tarafı bölümleme yöntemine göre daha uzun sürebilir.
Redis web sitesinin Bölümleme: verileri birden çok Redis örneği arasında bölme sayfasında, Redis ile bölümlemeyi gerçekleştirme hakkında daha fazla bilgi verilmektedir.
Redis, pek çok programlama dilinde yazılmış istemci uygulamaları destekler. .NET Framework kullanarak yeni uygulamalar derliyorsanız StackExchange.Redis istemci kitaplığını kullanmanızı öneririz. Bu kitaplık bir Redis sunucusuna bağlanma, komut gönderme ve yanıt almaya ilişkin ayrıntıları özetleyen bir .NET Framework nesne modeli sağlar. Visual Studio'da NuGet paketi olarak kullanılabilir. Bir Redis için Azure Cache veya vm üzerinde barındırılan özel bir Redis önbelleğine bağlanmak için aynı kitaplığı kullanabilirsiniz.
Bir Redis sunucusuna bağlanmak için ConnectionMultiplexer sınıfının statik Connect yöntemini kullanırsınız. Bu yöntemin oluşturduğu bağlantı, istemci uygulamanın kullanım ömrü boyunca kullanılacak şekilde tasarlanmıştır ve aynı bağlantı birden fazla eşzamanlı iş parçacığı tarafından kullanılabilir. Redis işlemini her gerçekleştirdiğinizde yeniden bağlanmayın ve bağlantıyı kesin çünkü bu işlem performansı düşürebilir.
Redis ana bilgisayarının adresi ve parola gibi bağlantı parametrelerini belirtebilirsiniz. Redis için Azure Cache kullanıyorsanız parola, Azure portalı kullanılarak Redis için Azure Cache için oluşturulan birincil veya ikincil anahtardır.
Redis sunucusuna bağlandıktan sonra, Redis Veritabanı'nda önbellek işlevi gören bir tanıtıcı elde edebilirsiniz. Redis bağlantısı bunu yapmak için GetDatabase yöntemini sağlar. Bundan sonra önbellekten öğeleri alabilir ve StringGet ile StringSet yöntemlerini kullanarak önbellekte verileri depolayabilirsiniz. Bu yöntemler parametre olarak bir anahtar bekler ve önbellekte eşleşen bir değere (StringGet) sahip öğeyi döndürür ya da öğeyi bu anahtarla (StringSet) önbelleğe ekler.
Redis sunucusunun konumuna bağlı olarak, bir istek sunucuya aktarıldığında ve istemciye bir yanıt döndürüldüğünde birçok işlem biraz gecikme süresi oluşturabilir. StackExchange kitaplığı, istemci uygulamaların yanıt verebilir durumda kalmasına yardımcı olmak üzere kullanıma sunduğu birçok yöntemin zaman uyumsuz sürümlerini sağlar. Bu yöntemler .NET Framework'teki Görev Tabanlı Zaman Uyumsuz desenini destekler.
Aşağıdaki kod parçacığı RetrieveItem adlı bir yöntemi gösterir. Redis ve StackExchange kitaplığını temel alan bir edilgen önbellek düzeni uygulamasını göstermektedir. Yöntem bir dize anahtar değeri alır ve StringGetAsync yöntemini çağırarak (zaman uyumsuz StringGet sürümü) Redis önbelleğinden ilgili öğeyi almaya çalışır.
Öğe bulunamazsa, yöntemi kullanılarak GetItemFromDataSourceAsync temel alınan veri kaynağından getirilir (StackExchange kitaplığının parçası değil yerel bir yöntemdir). Ardından, bir sonraki sefere daha hızlı alınabilmesi için StringSetAsync yöntemi kullanılarak önbelleğe eklenir.
// Connect to the Azure Redis cache
ConfigurationOptions config = new ConfigurationOptions();
config.EndPoints.Add("<your DNS name>.redis.cache.windows.net");
config.Password = "<Redis cache key from management portal>";
ConnectionMultiplexer redisHostConnection = ConnectionMultiplexer.Connect(config);
IDatabase cache = redisHostConnection.GetDatabase();
...
private async Task<string> RetrieveItem(string itemKey)
{
// Attempt to retrieve the item from the Redis cache
string itemValue = await cache.StringGetAsync(itemKey);
// If the value returned is null, the item was not found in the cache
// So retrieve the item from the data source and add it to the cache
if (itemValue == null)
{
itemValue = await GetItemFromDataSourceAsync(itemKey);
await cache.StringSetAsync(itemKey, itemValue);
}
// Return the item
return itemValue;
}
StringGet ve StringSet yöntemleri, dize değerlerini alma veya depolama ile sınırlı değildir. Bir bayt dizisi olarak seri hale getirilmiş herhangi bir öğeyi alabilirler. Bir .NET nesnesini kaydetmeniz gerekiyorsa, bayt akışı olarak seri hale getirebilir ve StringSet yöntemini kullanarak önbelleğe yazabilirsiniz.
Benzer şekilde, StringGet yöntemini kullanarak ve bir .NET nesnesi olarak seri durumdan çıkararak nesneyi önbellekten okuyabilirsiniz. Aşağıdaki kod, IDatabase arabirimi için bir genişletme yöntemleri kümesini (bir Redis bağlantısının GetDatabase yöntemi bir IDatabase nesnesi döndürür) ve önbellekte bir BlogPost nesnesini okumak ve yazmak için bu yöntemleri kullanan bazı örnek kodları gösterir:
public static class RedisCacheExtensions
{
public static async Task<T> GetAsync<T>(this IDatabase cache, string key)
{
return Deserialize<T>(await cache.StringGetAsync(key));
}
public static async Task<object> GetAsync(this IDatabase cache, string key)
{
return Deserialize<object>(await cache.StringGetAsync(key));
}
public static async Task SetAsync(this IDatabase cache, string key, object value)
{
await cache.StringSetAsync(key, Serialize(value));
}
static byte[] Serialize(object o)
{
byte[] objectDataAsStream = null;
if (o != null)
{
var jsonString = JsonSerializer.Serialize(o);
objectDataAsStream = Encoding.ASCII.GetBytes(jsonString);
}
return objectDataAsStream;
}
static T Deserialize<T>(byte[] stream)
{
T result = default(T);
if (stream != null)
{
var jsonString = Encoding.ASCII.GetString(stream);
result = JsonSerializer.Deserialize<T>(jsonString);
}
return result;
}
}
Aşağıdaki kod, edilgen önbellek düzenini izleyerek önbellekte seri hale getirilebilir bir BlogPost nesnesini okumak ve yazmak üzere bu genişletme yöntemlerini kullanan RetrieveBlogPost adlı bir yöntemi gösterir:
// The BlogPost type
public class BlogPost
{
private HashSet<string> tags;
public BlogPost(int id, string title, int score, IEnumerable<string> tags)
{
this.Id = id;
this.Title = title;
this.Score = score;
this.tags = new HashSet<string>(tags);
}
public int Id { get; set; }
public string Title { get; set; }
public int Score { get; set; }
public ICollection<string> Tags => this.tags;
}
...
private async Task<BlogPost> RetrieveBlogPost(string blogPostKey)
{
BlogPost blogPost = await cache.GetAsync<BlogPost>(blogPostKey);
if (blogPost == null)
{
blogPost = await GetBlogPostFromDataSourceAsync(blogPostKey);
await cache.SetAsync(blogPostKey, blogPost);
}
return blogPost;
}
Bir istemci uygulama birden çok zaman uyumsuz istek gönderirse Redis, komut kanalı oluşturmayı destekler. Redis, komutları katı bir sırayla alıp yanıtlamak yerine aynı bağlantıyı kullanarak çoğullayabilir.
Bu yaklaşım, ağdan daha verimli bir şekilde yararlanarak gecikme süresini azaltmaya yardımcı olur. Aşağıdaki kod parçacığı, iki müşterinin ayrıntılarını eşzamanlı olarak alan bir örnek göstermektedir. Kod, iki isteği gönderir ve sonra sonuçları almayı beklemeden önce bazı başka işlemler (gösterilmemiştir) yapar. Önbellek nesnesinin Wait yöntemi, .NET Framework Task.Wait yöntemine benzerdir:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
var task1 = cache.StringGetAsync("customer:1");
var task2 = cache.StringGetAsync("customer:2");
...
var customer1 = cache.Wait(task1);
var customer2 = cache.Wait(task2);
Redis için Azure Cache kullanabilen istemci uygulamaları yazma hakkında ek bilgi için Redis için Azure Cache belgelerine bakın. StackExchange.Redis sayfasında da daha fazla bilgi bulunabilir.
Aynı web sitesindeki İşlem hatları ve çoğullayıcılar sayfasında, Redis ve StackExchange kitaplığı zaman uyumsuz işlemler ve kanal oluşturma hakkında daha fazla bilgi verilmektedir.
Redis’in önbelleğe alma amacıyla en basit kullanımı, değerin herhangi bir ikili veriyi içerebilen rastgele uzunluktaki yorumlanmamış bir dize olduğu anahtar-değer çiftleridir. (Temelde dize olarak ele alınabilen bir bayt dizisidir). Bu senaryo, bu makalenin önceki kısımlarında yer alan Redis Önbelleği istemci uygulamalarını kullanma bölümünde gösterilmiştir.
Anahtarların aynı zamanda yorumlanmamış veriler içerdiğini, bu nedenle herhangi bir ikili bilgiyi anahtar olarak kullanabileceğinizi unutmayın. Ancak, anahtar uzadıkça depolanması için daha fazla alan gerekir ve arama işlemlerinin gerçekleştirilmesi daha uzun sürer. Kullanılabilirlik ve bakım kolaylığı için anahtar alanınızı dikkatlice tasarlayın ve anlamlı (ayrıntılı değil) anahtarlar kullanın.
Örneğin, kimliği 100 olarak müşterinin anahtarını açıklamak için yalnızca "100" yerine "müşteri:100" gibi yapılandırılmış anahtarlar kullanın. Bu düzen, farklı veri türlerini depolayan değerleri birbirinden kolayca ayırt etmenizi sağlar. Örneğin, kimliği 100 olarak siparişin anahtarını açıklamak için "siparişler:100" anahtarını da kullanabilirsiniz.
Tek boyutlu ikili dizeler dışında bir Redis anahtar-değer çiftindeki değer, listeler, kümeler (sıralı ve sırasız) ve karmalar gibi daha yapılandırılmış bilgileri de tutabilir. Redis bu türleri yönetebilen kapsamlı bir komut kümesi sağlar ve bu komutların birçoğu StackExchange gibi bir istemci kitaplığı aracılığıyla .NET Framework uygulamaları tarafından kullanılabilir. Redis web sitesindeki Redis veri türleri ve soyutlamalarına giriş sayfasında bu türlere ve bunları yönetmek için kullanabileceğiniz komutlara ilişkin daha ayrıntılı bir genel bakış sunulmaktadır.
Bu bölümde, bu veri türleri ve komutlar için bazı ortak kullanım örnekleri özetlenmektedir.
Redis, dize değerleri üzerinde bir dizi atomik al ve ayarla işlemini destekler. Bu işlemler, ayrı GET ve SET komutlarını kullanırken oluşabilecek olası çalışma tehlikelerini ortadan kaldırır. Kullanılabilir işlemler şunlardır:
Tamsayı veri değerleri üzerinde atomik artımlı ve azalımlı işlemler gerçekleştirebilen
INCR,INCRBY,DECRveDECRBY. StackExchange kitaplığı bu işlemleri gerçekleştirmek içinIDatabase.StringIncrementAsyncileIDatabase.StringDecrementAsyncyöntemlerinin aşırı yüklenmiş sürümlerini sağlar ve önbellekte depolanmış sonuç değerini döndürür. Aşağıdaki kod parçacığı bu yöntemlerin nasıl kullanılacağını gösterir:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... await cache.StringSetAsync("data:counter", 99); ... long oldValue = await cache.StringIncrementAsync("data:counter"); // Increment by 1 (the default) // oldValue should be 100 long newValue = await cache.StringDecrementAsync("data:counter", 50); // Decrement by 50 // newValue should be 50Bir anahtar ile ilişkili değeri alan ve yeni bir değerle değiştiren
GETSET. StackExchange kitaplığı bu işlemiIDatabase.StringGetSetAsyncyöntemiyle kullanılabilir hale getirir. Aşağıdaki kod parçacığında bu yöntemin bir örneği gösterilmektedir. Bu kod, önceki örnekte yer alan "veri:sayaç" anahtarı ile ilişkili geçerli değeri döndürür. Ardından, bu anahtarın değerini aynı işlemin parçası olarak tekrar sıfırlar:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... string oldValue = await cache.StringGetSetAsync("data:counter", 0);Bir dize değerleri kümesini tek bir işlem olarak döndürebilen veya değiştirebilen
MGETveMSET. Aşağıdaki örnekte gösterildiği gibi,IDatabase.StringGetAsyncveIDatabase.StringSetAsyncyöntemleri bu işlevleri desteklemek için aşırı yüklenmiştir:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... // Create a list of key-value pairs var keysAndValues = new List<KeyValuePair<RedisKey, RedisValue>>() { new KeyValuePair<RedisKey, RedisValue>("data:key1", "value1"), new KeyValuePair<RedisKey, RedisValue>("data:key99", "value2"), new KeyValuePair<RedisKey, RedisValue>("data:key322", "value3") }; // Store the list of key-value pairs in the cache cache.StringSet(keysAndValues.ToArray()); ... // Find all values that match a list of keys RedisKey[] keys = { "data:key1", "data:key99", "data:key322"}; // values should contain { "value1", "value2", "value3" } RedisValue[] values = cache.StringGet(keys);
Ayrıca, bu makalenin önceki kısımlarında yer alan Redis ile işlemler ve toplu işler bölümünde açıklanan şekilde birden fazla işlemi tek bir Redis işleminde birleştirebilirsiniz. StackExchange kitaplığı, ITransaction arabirimi üzerinden işlem desteği sağlar.
IDatabase.CreateTransaction yöntemini kullanarak bir ITransaction nesnesi oluşturabilirsiniz. ITransaction nesnesi tarafından sağlanan yöntemleri kullanarak işleme komut çağırabilirsiniz.
ITransaction arabirimi, tüm yöntemlerin zaman uyumsuz olması dışında IDatabase arabirimi tarafından erişilenlere benzer bir yöntemler kümesine erişim sağlar. Bu, yalnızca yöntemi çağrıldığında ITransaction.Execute gerçekleştirildikleri anlamına gelir. ITransaction.Execute yöntemi tarafından döndürülen değer, işlemin başarıyla oluşturulduğunu (true) veya başarısız olduğunu (false) gösterir.
Aşağıdaki kod parçacığı, iki sayacı aynı işlemin parçası olarak artırıp azaltan bir örnek göstermektedir:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
ITransaction transaction = cache.CreateTransaction();
var tx1 = transaction.StringIncrementAsync("data:counter1");
var tx2 = transaction.StringDecrementAsync("data:counter2");
bool result = transaction.Execute();
Console.WriteLine("Transaction {0}", result ? "succeeded" : "failed");
Console.WriteLine("Result of increment: {0}", tx1.Result);
Console.WriteLine("Result of decrement: {0}", tx2.Result);
Redis işlemlerinin ilişkisel veritabanlarındaki işlemlerden farklı olduğunu unutmayın. Execute yöntemi, çalıştırılacak işlemi oluşturan tüm komutları basitçe kuyruğa alır ve herhangi biri hatalı biçimlendirilmişse işlem durdurulur. Tüm komutlar başarıyla kuyruğa alınmışsa her komut zaman uyumsuz olarak çalışır.
Herhangi bir komut başarısız olsa bile diğerleri işlenmeye devam eder. Bir komutun başarıyla tamamlandığını doğrulamanız gerekirse, yukarıdaki örnekte gösterildiği gibi ilgili görevin Result özelliğini kullanarak komutun sonuçlarını getirmeniz gerekir. Result özelliğinin okunması, görev tamamlanana kadar çağıran iş parçacığını engeller.
Daha fazla bilgi için bkz . Redis'te İşlemler.
Toplu işlemleri gerçekleştirirken StackExchange kitaplığının IBatch arabirimini kullanabilirsiniz. Bu arabirim, tüm yöntemlerin zaman uyumsuz olması dışında IDatabase arabirimi tarafından erişilenlere benzer bir yöntemler kümesine erişim sağlar.
IDatabase.CreateBatch yöntemini kullanarak bir IBatch nesnesi oluşturabilir ve sonra aşağıdaki örnekte gösterildiği gibi IBatch.Execute yöntemini kullanarak toplu işi çalıştırabilirsiniz. Bu kod yalnızca bir dize değeri ayarlar, önceki örnekte kullanılan sayaçları artırıp azaltır ve sonuçları gösterir:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
IBatch batch = cache.CreateBatch();
batch.StringSetAsync("data:key1", 11);
var t1 = batch.StringIncrementAsync("data:counter1");
var t2 = batch.StringDecrementAsync("data:counter2");
batch.Execute();
Console.WriteLine("{0}", t1.Result);
Console.WriteLine("{0}", t2.Result);
İşlemin aksine, toplu işlemdeki bir komut hatalı biçimlendirilmiş olduğu için başarısız olursa diğer komutların yine de çalışabileceğini anlamak önemlidir. IBatch.Execute yöntemi herhangi bir başarı veya başarısızlık göstergesi döndürmez.
Redis, komut bayrakları kullanarak başlat ve unut işlemlerini destekler. Bu durumda istemci yalnızca bir işlem başlatır, ancak sonuçla ilgilenmez ve komutun tamamlanmasını beklemez. Aşağıdaki örnekte INCR komutunun bir başlat ve unut işlemi olarak gerçekleştirilmesi gösterilmektedir:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
await cache.StringSetAsync("data:key1", 99);
...
cache.StringIncrement("data:key1", flags: CommandFlags.FireAndForget);
Bir öğeyi Redis önbelleğinde depoladığınızda öğenin önbellekten otomatik olarak silineceği bir zaman aşımı süresi belirtebilirsiniz. Ayrıca, TTL komutunu kullanarak bir anahtarın süre sonuna ne kadar kaldığını sorgulayabilirsiniz. Bu komut, IDatabase.KeyTimeToLive yöntemi ile StackExchange uygulamaları tarafından kullanılabilir.
Aşağıdaki kod parçacığında, bir anahtar için 20 saniye sona erme süresini ayarlama ve anahtarın kalan kullanım ömrünü sorgulama işlemi gösterilmektedir:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration time of 20 seconds
await cache.StringSetAsync("data:key1", 99, TimeSpan.FromSeconds(20));
...
// Query how much time a key has left to live
// If the key has already expired, the KeyTimeToLive function returns a null
TimeSpan? expiry = cache.KeyTimeToLive("data:key1");
Ayrıca, StackExchange kitaplığında KeyExpireAsync yöntemi olarak mevcut olan EXPIRE komutunu kullanarak sona erme zamanını belirli bir tarih ve saate ayarlayabilirsiniz:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration date of midnight on 1st January 2015
await cache.StringSetAsync("data:key1", 99);
await cache.KeyExpireAsync("data:key1",
new DateTime(2015, 1, 1, 0, 0, 0, DateTimeKind.Utc));
...
İpucu
StackExchange kitaplığında IDatabase.KeyDeleteAsync yöntemi olarak mevcut olan DEL komutunu kullanarak bir öğeyi önbellekten el ile kaldırabilirsiniz.
Redis kümesi, tek bir anahtarı paylaşan birden çok öğenin oluşturduğu bir koleksiyondur. SADD komutunu kullanarak bir küme oluşturabilirsiniz. Bir kümedeki öğeleri SMEMBERS komutunu kullanarak alabilirsiniz. StackExchange kitaplığı, SADD komutunu IDatabase.SetAddAsync yöntemiyle ve SMEMBERS komutunu IDatabase.SetMembersAsync yöntemiyle uygular.
Ayrıca, SDIFF (küme farkı), SINTER (küme kesişimi) ve SUNION (küme birleşimi) komutlarını kullanarak yeni kümeler oluşturmak için var olan kümeleri birleştirebilirsiniz. StackExchange kitaplığı bu işlemleri IDatabase.SetCombineAsync yönteminde birleştirir. Bu yöntemin ilk parametresi, gerçekleştirilecek küme işlemini belirtir.
Aşağıdaki kod parçacıkları, kümelerin ilgili öğelerden oluşan koleksiyonları hızlıca depolamak ve almak için nasıl faydalı olabileceğini gösterir. Bu kod, bu makalenin önceki kısımlarında yer alan Redis Önbelleği İstemci Uygulamalarını kullanma bölümünde açıklanan BlogPost türünü kullanır.
Bir BlogPost nesnesi dört alandan oluşur: kimlik, başlık, sıralama puanı ve etiket koleksiyonu. Aşağıdaki ilk kod parçacığında BlogPost nesnelerinin bir C# listesini doldurmak için kullanılan örnek veriler gösterilmektedir:
List<string[]> tags = new List<string[]>
{
new[] { "iot","csharp" },
new[] { "iot","azure","csharp" },
new[] { "csharp","git","big data" },
new[] { "iot","git","database" },
new[] { "database","git" },
new[] { "csharp","database" },
new[] { "iot" },
new[] { "iot","database","git" },
new[] { "azure","database","big data","git","csharp" },
new[] { "azure" }
};
List<BlogPost> posts = new List<BlogPost>();
int blogKey = 0;
int numberOfPosts = 20;
Random random = new Random();
for (int i = 0; i < numberOfPosts; i++)
{
blogKey++;
posts.Add(new BlogPost(
blogKey, // Blog post ID
string.Format(CultureInfo.InvariantCulture, "Blog Post #{0}",
blogKey), // Blog post title
random.Next(100, 10000), // Ranking score
tags[i % tags.Count])); // Tags--assigned from a collection
// in the tags list
}
Her bir BlogPost nesnesinin etiketlerini bir Redis önbelleğinde küme olarak depolayabilir ve her kümeyi BlogPost kimliği ile ilişkilendirebilirsiniz. Bunun yapılması, belirli bir blog gönderisine ait olan tüm etiketleri hızlıca bulmayı sağlar. Ters yönde aramayı etkinleştirmek ve belirli bir etiketi paylaşan tüm blog gönderilerini bulmak için anahtardaki etiket kimliğine başvuran blog gönderilerini tutan başka bir küme oluşturabilirsiniz:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Tags are easily represented as Redis Sets
foreach (BlogPost post in posts)
{
string redisKey = string.Format(CultureInfo.InvariantCulture,
"blog:posts:{0}:tags", post.Id);
// Add tags to the blog post in Redis
await cache.SetAddAsync(
redisKey, post.Tags.Select(s => (RedisValue)s).ToArray());
// Now do the inverse so we can figure out which blog posts have a given tag
foreach (var tag in post.Tags)
{
await cache.SetAddAsync(string.Format(CultureInfo.InvariantCulture,
"tag:{0}:blog:posts", tag), post.Id);
}
}
Bu yapılar birçok ortak sorguyu çok verimli bir şekilde gerçekleştirmenizi sağlar. Örneğin, blog gönderisi 1 için tüm etiketleri şu şekilde bulup görüntüleyebilirsiniz:
// Show the tags for blog post #1
foreach (var value in await cache.SetMembersAsync("blog:posts:1:tags"))
{
Console.WriteLine(value);
}
Aşağıdaki gibi bir küme kesişimi işlemi gerçekleştirerek blog gönderisi 1 ve blog gönderisi 2 için ortak olan tüm etiketleri bulabilirsiniz:
// Show the tags in common for blog posts #1 and #2
foreach (var value in await cache.SetCombineAsync(SetOperation.Intersect, new RedisKey[]
{ "blog:posts:1:tags", "blog:posts:2:tags" }))
{
Console.WriteLine(value);
}
Ayrıca, belirli bir etiketi içeren tüm blog gönderilerini bulabilirsiniz:
// Show the ids of the blog posts that have the tag "iot".
foreach (var value in await cache.SetMembersAsync("tag:iot:blog:posts"))
{
Console.WriteLine(value);
}
Birçok uygulama için gerekli olan genel bir görev, son erişilen öğelerin bulunmasıdır. Örneğin, bir blog sitesi en son okunan blog gönderilerine ilişkin bilgileri görüntülemek isteyebilir.
Bir Redis listesi kullanarak bu işlevi uygulayabilirsiniz. Redis listesi, aynı anahtarı paylaşan birden fazla öğe içerir. Liste çift uçlu bir sıra gibi davranır. LPUSH (sola gönder) ve RPUSH (sağa gönder) komutlarını kullanarak öğeleri listenin herhangi bir ucuna gönderebilirsiniz. LPOP ve RPOP komutlarını kullanarak listenin herhangi bir ucundan öğeleri alabilirsiniz. Ayrıca, LRANGE ve RRANGE komutlarını kullanarak bir öğe kümesi döndürebilirsiniz.
Aşağıdaki kod parçacıkları, StackExchange kitaplığını kullanarak bu işlemleri nasıl gerçekleştirebileceğinizi gösterir. Bu kod, önceki örnekte yer alan BlogPost türünü kullanır. Blog gönderisi bir kullanıcı tarafından okunduğunda IDatabase.ListLeftPushAsync yöntemi, blog gönderisinin başlığını Redis önbelleğinde "blog:recent_posts" anahtarıyla ilişkili olan bir listeye gönderir.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:recent_posts";
BlogPost blogPost = ...; // Reference to the blog post that has just been read
await cache.ListLeftPushAsync(
redisKey, blogPost.Title); // Push the blog post onto the list
Daha fazla blog gönderisi okundukça başlıkları aynı listeye gönderilir. Liste, başlıkların eklendiği sıraya göre düzenlenir. En son okunan blog gönderileri listenin sol ucuna doğru. (Aynı blog gönderisi birden çok kez okunursa listede birden çok girişi olacaktır.)
IDatabase.ListRange yöntemini kullanarak en son okunan gönderilerin başlıklarını görüntüleyebilirsiniz. Bu yöntem liste, başlangıç noktası ve bitiş noktası içeren anahtarı alır. Aşağıdaki kod, listenin en sol ucundaki 10 blog gönderisini (0 ile 9 arasındaki öğeler) alır:
// Show latest ten posts
foreach (string postTitle in await cache.ListRangeAsync(redisKey, 0, 9))
{
Console.WriteLine(postTitle);
}
yönteminin listeden ListRangeAsync öğe kaldırmadığını unutmayın. Bunu yapmak için IDatabase.ListLeftPopAsync ve IDatabase.ListRightPopAsync yöntemlerini kullanabilirsiniz.
Listenin süresiz olarak büyümesini engellemek için listeyi kırparak öğeleri düzenli aralıklarla seçebilirsiniz. Aşağıdaki kod parçacığında listenin en solundaki beş öğe dışında tüm öğelerin nasıl kaldırılacağı gösterilmektedir:
await cache.ListTrimAsync(redisKey, 0, 5);
Varsayılan olarak, bir kümedeki öğeler belirli bir sırada tutulmaz. ZADD komutunu (StackExchange kitaplığındaki IDatabase.SortedSetAdd yöntemi) kullanarak sıralı bir küme oluşturabilirsiniz. Öğeler, komuta bir parametre olarak sağlanan ve puan adı verilen sayısal bir değer kullanılarak sıralanır.
Aşağıdaki kod parçacığı, bir blog gönderisinin başlığını sıralı bir listeye ekler. Bu örnekte her blog gönderisi, blog gönderisinin sıralamasını içeren bir puan alanına sahiptir.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:post_rankings";
BlogPost blogPost = ...; // Reference to a blog post that has just been rated
await cache.SortedSetAddAsync(redisKey, blogPost.Title, blogPost.Score);
IDatabase.SortedSetRangeByRankWithScores yöntemini kullanarak blog gönderisi başlıklarını ve puanları artan puan sırasıyla alabilirsiniz:
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(redisKey))
{
Console.WriteLine(post);
}
Not
StackExchange kitaplığı, verileri puan sırasına IDatabase.SortedSetRangeByRankAsync göre döndüren yöntemini de sağlar, ancak puanları döndürmez.
Öğeleri ayrıca azalan puan sırasına göre alabilir ve IDatabase.SortedSetRangeByRankWithScoresAsync yöntemine ek parametreler sağlayarak döndürülen öğe sayısını sınırlayabilirsiniz. Aşağıdaki örnekte ilk 10 sıradaki blog gönderilerinin başlık ve puanları gösterilmektedir:
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(
redisKey, 0, 9, Order.Descending))
{
Console.WriteLine(post);
}
Aşağıdaki örnekte, döndürülen öğeleri belirli bir puan aralığına denk gelen öğelerle sınırlamak için kullanabileceğiniz IDatabase.SortedSetRangeByScoreWithScoresAsync yöntemi kullanılır:
// Blog posts with scores between 5000 and 100000
foreach (var post in await cache.SortedSetRangeByScoreWithScoresAsync(
redisKey, 5000, 100000))
{
Console.WriteLine(post);
}
Redis sunucusu bir veri önbelleği olarak hareket etmesinin dışında yüksek performanslı bir yayımcı/abone mekanizması aracılığıyla mesajlaşma sağlar. İstemci uygulamalar bir kanala abone olabilir ve diğer uygulama veya hizmetler, kanala ileti yayımlayabilir. Daha sonra, abone olan uygulamalar bu iletileri alıp işleyebilir.
Redis, istemci uygulamaların kanallara abone olmak üzere kullanması için SUBSCRIBE komutunu sağlar. Bu komut, uygulamanın iletileri kabul edeceği bir veya daha fazla kanalın adını bekler. StackExchange kitaplığı, bir .NET Framework uygulamasının kanallara abone olup yayımlamasını sağlayan ISubscription arabirimini içerir.
Redis sunucusu ile bağlantı kurmak için GetSubscriber yöntemini kullanarak bir ISubscription nesnesi oluşturabilirsiniz. Ardından, bu nesnenin SubscribeAsync yöntemini kullanarak bir kanaldaki iletileri dinleyebilirsiniz. Aşağıdaki kod örneğinde "messages:blogPosts" adlı bir kanala nasıl abone olunacağı gösterilmektedir:
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
await subscriber.SubscribeAsync("messages:blogPosts", (channel, message) => Console.WriteLine("Title is: {0}", message));
Subscribe yönteminin ilk parametresi, kanalın adıdır. Bu ad, önbellekteki anahtarlar tarafından kullanılan kuralların aynısını izler. Ad herhangi bir ikili veri içerebilir, ancak iyi bir performans ve bakım sağlamaya yardımcı olmak için nispeten kısa ve anlamlı dizeler kullanmanızı öneririz.
Ayrıca, kanallar tarafından kullanılan ad alanının, anahtarlar tarafından kullanılan ad alanından ayrı olduğunu unutmayın. Başka bir deyişle, aynı ada sahip kanallarınız ve anahtarlarınız olabilir, ancak bu durum uygulama kodunuzun sürdürülmesini zorlaştırabilir.
İkinci parametre bir Eylem temsilcisidir. Bu temsilci, kanalda yeni bir iletinin göründüğü her durumda zaman uyumsuz olarak çalışır. Bu örnek yalnızca konsol üzerindeki iletiyi gösterir (ileti bir blog gönderisinin başlığını içerecektir).
Bir kanalda yayımlamak için uygulama Redis PUBLISH komutunu kullanabilir. StackExchange kitaplığı bu işlemi gerçekleştirmek için IServer.PublishAsync yöntemini sağlar. Aşağıdaki kod parçacığı, "messages:blogPosts" kanalında nasıl ileti yayımlanacağını gösterir:
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
BlogPost blogPost = ...;
subscriber.PublishAsync("messages:blogPosts", blogPost.Title);
Yayımlama/abone olma mekanizması hakkında anlaşılması gereken birkaç nokta mevcuttur:
- Birden çok abone aynı kanala abone olabilir ve hepsi bu kanalda yayımlanan iletileri alır.
- Aboneler yalnızca abone olduktan sonra yayımlanan iletileri alır. Kanallar arabelleğe alınamaz ve bir ileti yayımlandıktan sonra Redis altyapısı iletiyi her aboneye gönderir ve ardından kaldırır.
- Varsayılan olarak, iletiler aboneler tarafından gönderilme sırasına göre alınır. Çok sayıda ileti ve çok sayıda abone ile yayımcı içeren yüksek oranda etkin bir sistemde iletilerin kesin olarak sıralı bir şekilde teslim edilmesi, sistemin performansını yavaşlatabilir. Her ileti bağımsız ve sıra önemsizse, Redis sistemi tarafından eşzamanlı işlemeyi etkinleştirebilir ve yanıt hızını iyileştirmeye yardımcı olabilirsiniz. Bir StackExchange istemcisinde bunu yapmak için abone tarafından kullanılan bağlantının PreserveAsyncOrder değerini false olarak ayarlayın:
ConnectionMultiplexer redisHostConnection = ...;
redisHostConnection.PreserveAsyncOrder = false;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
Bir seri hale getirme biçimi seçtiğinizde performans, birlikte çalışabilirlik, sürüm oluşturma, var olan sistemlerle uyumluluk, veri sıkıştırma ve bellek ek yükü arasındaki dengeleri göz önünde bulundurun. Performansı değerlendirirken, karşılaştırmaların bağlama son derece bağımlı olduğunu unutmayın. Bunlar gerçek iş yükünüzü yansıtmayabilir ve yeni kitaplıkları veya sürümleri dikkate almayabilir. Tüm senaryolar için tek bir "en hızlı" seri hale getirici yoktur.
Dikkate alınması gereken bazı seçenekler:
Protokol Arabellekleri (aynı zamanda protobuf olarak adlandırılır), yapılandırılmış verileri verimli bir şekilde serileştirmek amacıyla Google tarafından geliştirilmiş bir serileştirme biçimidir. İleti yapılarını tanımlamak için kesin olarak yazılan tanım dosyalarını kullanır. Bu tanım dosyaları daha sonra iletileri serileştirmek ve seri durumdan çıkarmak için dile özgü kod halinde derlenir. Protobuf mevcut RPC mekanizmaları üzerinde kullanılabilir veya bir RPC hizmeti oluşturabilir.
Apache Thrift, kesin türü belirtilmiş tanım dosyaları ve serileştirme kodu ile RPC hizmetlerini oluşturmaya yönelik bir derleme adımı ile benzer bir yaklaşım kullanır.
Apache Avro , Protokol Arabellekleri ve Thrift'e benzer işlevler sağlar, ancak derleme adımı yoktur. Bunun yerine, serileştirilmiş veriler her zaman yapıyı tanımlayan bir şema içerir.
JSON, okunaklı metin alanları kullanan bir açık standarttır. Geniş bir platformlar arası desteğe sahiptir. JSON ileti şemalarını kullanmaz. Metin tabanlı bir biçim olması, kablo üzerinde çok verimli değildir. Ancak, bazı durumlarda önbelleğe alınmış öğeleri HTTP aracılığıyla doğrudan bir istemciye döndürüyor olabilirsiniz; bu durumda JSON başka bir biçimde seri durumdan çıkarma ve sonra JSON biçiminde serileştirme maliyetinden tasarruf edebilir.
ikili JSON (BSON), JSON'a benzer bir yapı kullanan ikili serileştirme biçimidir. BSON, JSON’a kıyasla basit, kolay taranabilir ve hızlı serileştirilip seri durumdan çıkarılabilir şekilde tasarlanmıştır. Yükler boyut bakımından JSON ile benzerdir. Verilere bağlı olarak bir BSON yükü, JSON yükünden daha küçük veya daha büyük olabilir. BSON,JSON'da bulunmayan bazı ek veri türlerine sahiptir( özellikle BinData (bayt dizileri için) ve Date.
MessagePack, kablo üzerinden aktarım için kompakt şekilde tasarlanmış bir ikili serileştirme biçimidir. İleti şemaları veya ileti türü denetimi yoktur.
Bond, şema haline getirilmiş verilerle çalışmaya yönelik bir platformlar arası çerçevedir. Diller arası serileştirme ve seri durumdan çıkarmayı destekler. Burada listelenen diğer sistemlerle belirgin farklılıkları, devralma, tür diğer adları ve genel türlere yönelik desteğidir.
gRPC , Google tarafından geliştirilen bir açık kaynak RPC sistemidir. Varsayılan olarak, tanım dili ve temel alınan ileti değişim biçimi için Protokol Arabellekleri’ni kullanır.
- Redis için Azure Cache belgeleri
- Redis için Azure Cache SSS
- Görev Tabanlı Zaman Uyumsuz desen
- Redis belgeleri
- StackExchange.Redis
- Veri bölümleme kılavuzu
Aşağıdaki desenler, uygulamalarınızda önbelleğe alma uyguladığınızda senaryonuzla da ilgili olabilir:
Edilgen önbellek düzeni: Bu düzen bir veri deposundaki verileri isteğe bağlı olarak bir önbelleğe yükleme işlemini açıklar. Bu düzen ayrıca önbellekte tutulan veriler ile özgün veri deposundaki veriler arasında tutarlılığı sürdürmeye yardımcı olur.
Parçalama düzeni, büyük miktarlarda verileri depolarken ve böyle verilere erişirken ölçeklenebilirliği artırmaya yardımcı olmak üzere yatay bölümleme uygulama hakkında bilgiler sağlar.