Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Doğal dil işleme, metin verilerini analiz eden, anlayan ve metin verilerinden insan dili oluşturan teknikleri kapsar. Azure yaklaşım analizi ve varlık tanımadan belge sınıflandırması ve metin özetlemesine kadar değişen doğal dil işleme iş yüklerine yönelik yönetilen API tabanlı hizmetler ve dağıtılmış açık kaynak çerçeveler sağlar. Bu kılavuz, iş yükü gereksinimlerinizle doğru teknolojiyi eşleştirebilmeniz için Azure birincil doğal dil işleme seçeneklerini değerlendirmenize ve seçmenize yardımcı olur.
Uyarı
Bu kılavuz, Azure Language ve Azure Databricks veya Microsoft Fabric üzerinde Spark NLP ile Apache Spark aracılığıyla kullanılabilen doğal dil işleme özelliklerine odaklanır. Dil modellerini seçme veya OpenAI çözümleri Azure tasarlama konusunda rehberlik sağlamaz. Bazı platform açıklamaları, uygulama ayrıntıları olarak desteklenen temel model veya konuşma modeli tümleştirmelerine başvurabilir, ancak bu kılavuz doğal dil işleme hizmeti seçimine odaklanır. Daha fazla bilgi için bkz. Yapay zeka hizmetleri teknolojisi seçme.
Doğal dil işleme ve dil modellerini anlama
Azure hizmetleri değerlendirmeden önce, doğal dil işlemenin ne olduğunu, dil modellerinden ne kadar farklı olduğunu ve hangi görevleri karşıladığını anlayın.
Doğal dil işlemeyi dil modellerinden ayırt edin
Bu bölüm, doğal dil işleme ve dil modelleri arasındaki sınırı açıklar ve doğal dil işleme tekniklerinin sağladığı temel özellikleri araştırmaktır.
| Boyut | Doğal dil işleme | Dil modelleri |
|---|---|---|
| Scope | Belirteçleme, kök bulma, varlık tanıma, duygu analizi ve belge sınıflandırması gibi çeşitli metin işleme tekniklerini kapsayan geniş bir alan. | Üst düzey dil anlama ve oluşturma görevlerine odaklanan, doğal dil işlemenin derin öğrenme alt kümesi. |
| Örnekler | Kural tabanlı ayrıştırıcılar, terim sıklığı ters belge sıklığı (TF-IDF) sınıflandırıcıları, adlandırılmış varlık tanıyıcıları, duygu analizi araçları. | GPT, BERT ve benzer transformatör tabanlı modeller, insansı, bağlamsal olarak duyarlı metinler oluşturur. |
| Çıkış | Etiketler, puanlar, ayıklanan span'lar ve ayrıştırılmış söz dizimi gibi yapılandırılmış sinyaller. | Oluşturulan metin, özetler, yanıtlar ve tamamlamalar gibi akıcı doğal dil. |
| İlişki | Üst etki alanı. Doğal dil işleme, metin işleme yöntemlerinin tüm yelpazesini kapsar. | Doğal dil işleme içindeki bir araç. Dil modelleri, doğal dil işlemeyi değiştirmeden geliştirir. Daha geniş bilişsel görevleri işler ancak doğal dil işleme ile eş anlamlı değildir. |
Doğal dil işleme özellikleri
Belgeleri hassas veya istenmeyen posta olarak etiketleyerek sınıflandırabilirsiniz. Doğal dil işleme, uyumluluk ve filtreleme iş akışlarını desteklemek için belgeleri içeriğe göre otomatik olarak kategorilere ayırır.
Belgedeki varlıkları tanımlayarak metni özetleyin. Doğal dil işleme, en önemli bilgileri yakalayan kısa özetler oluşturmak için anahtar varlıkları ayıklar.
Tanımlanan varlıkları kullanarak belgeleri anahtar sözcüklerle etiketleyin. Varlıkları tanımladıktan sonra, belge düzenlemeyi basitleştiren anahtar sözcük etiketleri oluşturabilirsiniz. İçerik tabanlı arama ve alma için bu etiketleri kullanın.
Navigasyon ve ilgili belge keşfi için konuları tespit etme. Doğal dil işleme, belge kategorilere ayırmayı ve konu tabanlı gezintiyi destekleyen ayıklanan varlıkları kullanarak önemli konuları tanımlar.
Metin duyarlılığını değerlendirme. Yaklaşım analizi, metnin duygusal tonunu değerlendirir ve içeriği pozitif, negatif veya nötr olarak sınıflandırır.
Doğal dil işleme çıkışlarını aşağı akış iş akışlarına besleyin. Ayıklanan varlıklar, duygu puanları ve konu etiketleri gibi sonuçlar, işleme, arama dizini oluşturma ve analiz için giriş görevi görür.
Olası kullanım örneklerini belirleme
Birçok sektördeki iş senaryoları, doğal dil işleme çözümlerinden yararlanır. Aşağıdaki kullanım örnekleri, doğal dil işleme tekniklerinin yapılandırılmamış belgeleri işlemeden siber güvenlik ve erişilebilirlikte gelişmekte olan uygulamalara olanak sağlayan gerçek dünyadaki zorlukları nasıl ele aldığı göstermektedir.
Belgeleri ve yapılandırılmamış metni işleme
Makine tarafından oluşturulan belgelerden bilgi çıkarma. Doğal dil işleme, finans, sağlık hizmetleri, perakende, kamu ve diğer sektörlerde belge işlemeye olanak tanır. Yapılandırılmamış girişlerden yapılandırılmış bilgileri ayıklamak için dijital olarak oluşturulan belgeleri analiz edebilirsiniz. El yazısı belgeler için, doğal dil işleme tekniklerini uygulamadan önce el yazısı içeriği metne dönüştürmek için Azure Belge Zekası kullanın.
Metin işleme için endüstriden bağımsız doğal dil işleme görevleri uygulayın. Adlandırılmış varlık tanıma (NER), sınıflandırma, özetleme ve ilişki ayıklama, yapılandırılmamış belge içeriğini otomatik olarak işlemenize ve çözümlemenize yardımcı olur. Bu görevler etki alanları arasında çalışır ve sektöre özgü özelleştirme gerektirmez.
Özelleştirilmiş analiz için etki alanına özgü modeller oluşturun. Bu görevlere örnek olarak sağlık hizmetleri için risk katmanlama modelleri, bilgi yönetimi için ontoloji sınıflandırması ve ürün ve müşteri verileri için perakende özetlemeleri verilebilir. Azure Language özel model eğitimi ve Spark NLP, bu etki alanına özgü belge biçimleri için doğruluğun geliştirilmesine yardımcı olur.
Yapılandırılmış veri girişlerinden otomatik raporlar oluşturma. Yapılandırılmış verilerden kapsamlı metinsel raporları sentezleyebilir ve oluşturabilirsiniz. Bu özellik, kapsamlı belgeler gerektiren finans ve uyumluluk gibi sektörlere yardımcı olur.
Aramayı, çeviriyi ve analizi etkinleştirme
Bilgi grafları oluşturun ve bilgi alma yoluyla anlamsal aramayı etkinleştirin. Doğal dil işleme, sistemlerin yalnızca anahtar sözcük eşleştirmeye güvenmek yerine sorgu anlamını yorumlamasına olanak tanıyan bilgi grafiği oluşturmayı ve anlamsal aramayı destekler.
Tıbbi bilgi graflarıyla ilaç bulmayı ve klinik denemeleri destekleme. Doğal dil işleme sistemleri klinik metinleri analiz edebilir. Bu metinden oluşturulan tıbbi bilgi grafikleri, ilaç bulma işlem hatlarını ve klinik deneme eşleştirmeyi destekler. Bu grafikler araştırma iş akışlarını hızlandırmak için uyuşturucu, koşullar ve sonuçlar gibi varlıkları birbirine bağlar. Azure Dilinde Text analytics for health bu grafikleri oluşturmak için kullanabileceğiniz tıbbi varlıkları, ilişkileri ve onayları ayıklar.
Müşteriye yönelik uygulamalarda konuşma yapay zekası için metin çevirisi yapın. Metin çevirisi, birden çok sektörde konuşma yapay zekası sağlar. Kullanıcının tercih ettiği dilde işleyen ve yanıt veren çok dilli müşterilere yönelik uygulamalar oluşturabilirsiniz. Spark NLP doğrudan çeviri özellikleri sağlar. Azure'da, Azure Dili'nden ayrı bir hizmet olan Azure Translator kullanın.
Marka algısı için yaklaşımı ve duygusal zekayı analiz edin. Yaklaşım analizi, metinden gelen pozitif, negatif ve nüanslı duygusal sinyalleri kullanarak marka algısını izlemenize ve müşteri geri bildirimlerini analiz etmenize yardımcı olur.
Doğal dil işlemeyi gelişmekte olan etki alanlarına genişletme
Nesnelerin İnterneti (IoT) ve akıllı cihazlar için sesle etkinleştirilmiş arabirimler oluşturun. Doğal dil işleme, kullanıcı amacını anlamak ve IoT ve akıllı cihaz senaryolarında anlam ayıklamak için konuşma tanıma sistemlerinin metin çıkışını işler. Sesle etkinleştirilen senaryolar, doğal dil işlemeden önce konuşmayı metne dönüştürme için Azure Speech gerektirir.
Uyarlamalı dil modellerini kullanarak dil çıkışını dinamik olarak ayarlayın. Uyarlamalı dil modelleri, dil çıkışını eğitim içerik teslimi ve erişilebilirliğini destekleyen farklı hedef kitle kavrama düzeylerine uyacak şekilde dinamik olarak ayarlar.
Siber güvenlik metin analizi aracılığıyla kimlik avını ve yanlış bilgiyi algılayın. Doğal dil işleme, dijital iletişimdeki olası güvenlik tehditlerini belirlemek için iletişim düzenlerini ve dil kullanımını gerçek zamanlı olarak analiz eder. Bu analiz, kimlik avı girişimlerini ve yanlış bilgi kampanyalarını algılamaya yardımcı olur.
Azure Dilini Değerlendirme
Azure Language, metni anlamak ve analiz etmek için doğal dil işleme özellikleri sağlayan bulut tabanlı bir hizmettir. Yönetebileceğiniz altyapı olmadan Foundry portalı, REST API'leri ve Python, C#, Java ve JavaScript için istemci kitaplıkları aracılığıyla erişebilirsiniz. Yapay zeka aracısı geliştirme için bu özelliklere Azure Dil Modeli Bağlam Protokolü (MCP) sunucusu üzerinden de erişebilirsiniz. Ona Microsoft Foundry araç kataloğunda bir uzak sunucu veya yerel olarak kendi barındırılan bir sunucu olarak erişebilirsiniz.
Önceden oluşturulmuş özellikler
Önceden oluşturulmuş özellikler model eğitimi gerektirmez ve kullanıma hazırdır:
NER: Metindeki varlıkları tanımlar ve kişiler, kuruluşlar, konumlar ve tarihler gibi önceden tanımlanmış türler halinde kategorilere ayırır.
PII algılama: Metin ve döküm konuşmalarında hassas kişisel veriler ve sağlık verileri de dahil olmak üzere kişisel olarak tanımlanabilir bilgileri (PII) tanımlar ve yeniden oluşturur.
Dil algılama: Çok çeşitli dil ve diyalektlerde bir belgenin dilini algılar.
Yaklaşım analizi ve görüş madenciliği: Metindeki pozitif, negatif veya nötr yaklaşımı tanımlar ve görüşleri ürün öznitelikleri veya hizmet yönleri gibi belirli öğelere bağlar.
Anahtar ifade ayıklama: Yapılandırılmamış metni değerlendirir ve ana kavramların ve anahtar ifadelerin listesini döndürür.
Özetleme: Metin, sohbet ve çağrı merkezi özetlemeyi destekleyen ayıklayıcı veya soyutlayıcı yaklaşımları kullanarak belgeleri ve konuşmaları daraltır.
Sağlık için metin analizi: Yapılandırılmamış klinik metinden tıbbi varlıklar, ilişkiler ve saptamalar dahil ilgili sağlık bilgilerini ayıklar ve etiketler.
Özel modelleri eğitin
Verilerinizdeki modelleri etki alanına özgü doğal dil işleme görevlerini işleyecek şekilde eğitmek için özelleştirilebilir özellikleri kullanabilirsiniz:
- Özel adlandırılmış varlık tanıma (CNER): Yapılandırılmamış metinden etki alanına özgü varlık kategorilerini ayıklamak için özel modeller oluşturun. Önceden oluşturulmuş NER kategorileri etki alanı sözlüğünüzü kapsamadığında CNER kullanın.
Azure Dili MCP sunucusu ve aracıları
Uyarı
Azure Dili MCP sunucusu ve hem amaç yönlendirme hem de tam soru yanıtlama aracıları önizleme aşamasındadır. Önizleme özellikleri hizmet düzeyi sözleşmesi (SLA) içermez ve bunları üretim iş yükleri için önermiyoruz. Bazı özellikler desteklenmeyebilir veya sınırlı özelliklere sahip olabilir. Daha fazla bilgi için bkz. Microsoft Azure önizlemeleri için uygun kullanım koşulları.
Azure Dili, üretim doğal dil işleme iş yükleri için önceden oluşturulmuş aracılar ve esnek dağıtım seçenekleri sağlar:
Amaç yönlendirme aracısı: Konuşma akışlarını yönetir. Kullanıcı amaçlarını anlar ve belirleyici, denetlenebilir mantık aracılığıyla doğru yanıtlara yönlendirir. Saydam, belirlenimci konuşma yönlendirmeye ihtiyacınız olduğunda bu aracıyı kullanın.
Tam soru yanıtlama aracısı: İnsan gözetim ve kalite denetimini korurken iş açısından kritik sorulara güvenilir ve sözcük temelli yanıtlar sağlar. Yanıt doğruluğu ve tutarlılığı önemli olduğunda bu aracıyı kullanın.
Her iki etmene de Foundry araç kataloğu üzerinden erişebilirsiniz. Daha fazla bilgi için bkz. Azure Dil MCP sunucusu ve aracıları (önizleme).
Azure Dili MCP sunucusu birden çok dağıtım seçeneğini destekler:
Bulutta barındırılan uzak MCP sunucusu: Döküm aracı kataloğunda bu sunucu listelenir. Sunucu, Azure Dil özelliklerine bulut tarafından yönetilen erişim sağlar ve yerel altyapı gerektirmez.
Şirket içinde barındırılan yerel MCP sunucusu: Uyumluluk, güvenlik veya veri yerleşimi gereksinimleri için şirket içi veya kendi kendine yönetilen dağıtımları destekler.
Kapsayıcılı dağıtım: Aşağıdaki özellikler, yerel işleme veya hava boşluklu ortamlar gerektiren senaryolar için kapsayıcılı dağıtımı destekler. Kullanılabilir kapsayıcıların tam listesi ve kullanılabilirlik durumları için bkz. Azure AI kapsayıcıları desteği.
- Duygu analizi
- Dil algılama
- Anahtar ifade ayıklama
- NER (İngilizce)
- PII algılama
- CNER
- Sağlık için metin analizi
- Özetleme (önizleme)
Spark NLP ile Apache Spark'ı değerlendirme
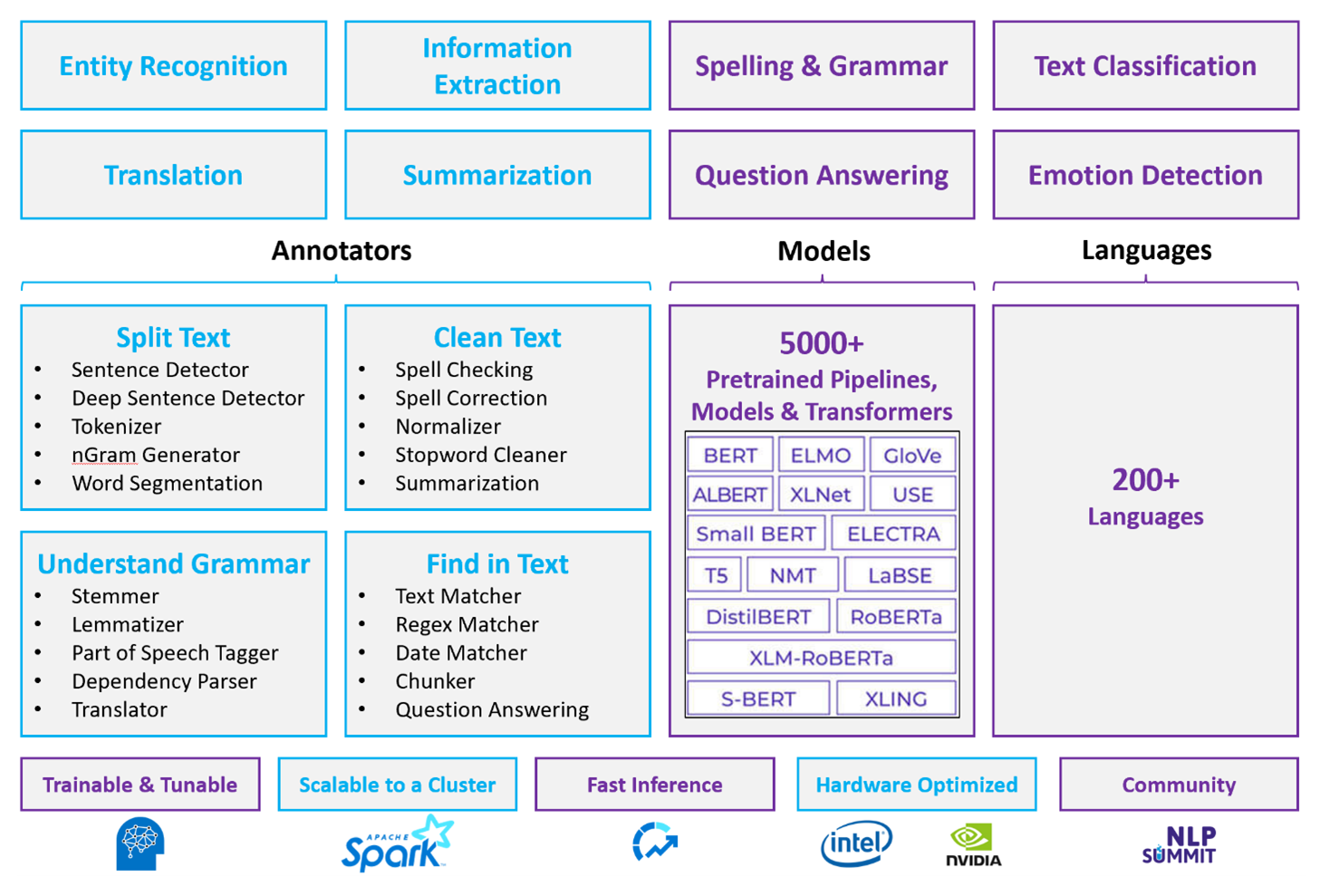
Spark NLP ile Apache Spark, küme ölçeğinde çalışan, doğal dil işlemeye yönelik dağıtılmış, açık kaynaklı bir yaklaşımdır. Spark NLP platform mimarisi, performansı ve önceden oluşturulmuş model ekosistemi, Azure Databricks veya Fabric üzerindeki büyük ölçekli, özelleştirilebilir doğal dil işleme iş yükleri için güçlü bir seçenektir.
Platformu ve mimariyi anlama
Apache Spark tabanlı doğal dil işleme iş yükleri için Fabric veya Azure Databricks kullanmanızı öneririz.
Apache Spark, büyük veri analizi için paralel, bellek içi işleme sağlar. Fabric ve Azure Databricks, büyük ölçekli doğal dil işleme iş yükleri için Apache Spark işleme özelliklerine erişmenizi sağlar.
Spark NLP, veri çerçevelerinde Spark ML'nin yerel bir uzantısı olarak çalışır. Bu tümleştirme, dağıtılmış kümelerde iyileştirilmiş performansla birleşik doğal dil işleme ve makine öğrenmesi işlem hatları sağlar.
Spark NLP, Python, Java ve Scala desteğine sahip açık kaynak bir kitaplıktır. Kitaplık, yazım denetimi, yaklaşım analizi ve belge sınıflandırması gibi spaCy ve Doğal Dil Araç Seti (NLTK) ile karşılaştırılabilir işlevsellik sağlar.

Apache®, Apache Spark ve alev logosu, Apache Software Foundation'ın Amerika Birleşik Devletleri'nde ve/veya diğer ülkelerdeki ticari markaları veya tescilli ticari markalarıdır. Bu işaretlerin kullanılması Apache Software Foundation tarafından onaylanmamaktadır.
Performansı ve ölçeklenebilirliği değerlendirme
Genel karşılaştırmalar , diğer doğal dil işleme kitaplıklarına göre önemli hız iyileştirmeleri gösterir. Spark NLP, spaCy ve NLTK gibi çerçevelerle karşılaştırıldığında dağıtılmış kümelerde daha hızlı eğitim ve çıkarım sağlar. Spark NLP'nin eğittikleri özel modeller, diğer doğal dil işleme çerçeveleriyle eşleşen doğruluk düzeylerine ulaşır ve bu da hız ve duyarlık gerektiren üretim iş yükleri için uygun olmasını sağlar.
CPU'lar, GPU'lar ve Intel Xeon yongaları için iyileştirilmiş derlemeler Apache Spark kümelerini tam olarak kullanır. Bu derlemeler, eğitim ve çıkarımın küme düğümleri arasında verimli bir şekilde ölçeklendirilmesine olanak tanır.
MPNet eklemeleri ve ONNX desteği, hassas, bağlama duyarlı işlemeyi etkinleştirir. MPNet, anlamsal anlamı yakalayan yoğun vektör gösterimleri oluşturur ve ONNX desteği çıkarım için iyileştirilmiş modelleri içeri aktarmanızı ve çalıştırmanızı sağlar.
Önceden oluşturulmuş modelleri ve işlem hatlarını kullanma
Önceden oluşturulmuş derin öğrenme modelleri NER, belge sınıflandırma ve yaklaşım algılamayı işler. Kitaplık, önceden oluşturulmuş derin öğrenme modelleriyle birlikte gelir.
Önceden eğitilmiş dil modelleri sözcük, öbek, cümle ve belge ekleme özelliklerini destekler. Kitaplık, sözcük, öbek, cümle ve belge ekleme düzeylerini destekleyen önceden eğitilmiş dil modellerini içerir. Bu eklemeler, benzerlik arama ve sınıflandırma gibi aşağı akış görevlerini etkinleştiren yoğun vektör gösterimleri sağlar.
Birleşik doğal dil işleme ve makine öğrenmesi işlem hatları, belge sınıflandırma ve risk tahminlerini destekler. Spark ML ile tümleştirme, belge sınıflandırması ve risk tahmini gibi görevler için birleşik doğal dil işleme ve makine öğrenmesi işlem hatlarını destekler. Bu birleşik yaklaşımla, metin işlemeyi geleneksel makine öğrenmesi modelleriyle tek bir işlem hattında birleştirerek mimari karmaşıklığı azaltabilirsiniz.
Yaygın doğal dil işleme zorluklarını giderme
Hem Azure Language hem de Spark NLP ile Apache Spark, doğal dil işlemede büyük ölçekte yaygın zorluklarla karşı karşıya kalır. Bu zorlukları anlarsanız, iki seçenekte de işlemeden önce kaynakları planlayabilir, işlem hatları tasarlayabilir ve doğruluk beklentilerini ayarlayabilirsiniz.
Kaynak işleme
Serbest biçimli metinlerin işlenmesi için önemli hesaplama kaynakları ve zaman gerekir. Serbest biçimli metin belgeleri hesaplama açısından pahalıdır ve analiz etmek için zaman gerektirir. Her belge kullanılabilir sonuçlar üretmeden önce belirteç oluşturma, normalleştirme ve model çıkarımı gerektirir.
Spark NLP iş yükleri genellikle GPU işlem dağıtımı gerektirir. Büyük ölçekli Spark NLP işlem hatları için,
Azure Databricks veyaFabric eğitim ve çıkarım için gereken paralel işleme gücünü sağlar. Llama 3.x model niceleme gibi iyileştirmeler, bellek ayak izini azaltmaya ve bu yoğun görevler için aktarım hızını artırmaya yardımcı olur.Azure Dili, aktarım hızı planlaması ve kota yönetimi gerektirir. Hizmet kaynak yönetimini işler, ancak yüksek hacimli API çağrıları dikkatli aktarım hızı planlaması gerektirir. Azaltmayı önlemek ve tutarlı işleme performansı sağlamak için istek fiyatlarınızı hizmet sınırlarına ve hız sınırlarına göre izleyin.
Belge standardizasyonu
Gerçek dünyadaki belgeler tutarlı bir yapıyı nadiren izler. Bu tutarsızlık, ayıklama işlem hatları için zorluklar oluşturur ve kaynaklar arasında doğruluğu korumak için kasıtlı stratejiler gerektirir.
Tutarsız biçimler: Standartlaştırılmış bir belge biçimi olmadan, serbest biçimli metinden belirli olguları ayıklamak zor olabilir. Örneğin, farklı satıcıların fatura numaralarını ve tarihlerini ayıklamak zor olabilir çünkü alan düzenleri, etiketler ve biçimlendirme kaynaklar arasında farklılık gösterir.
Özel model eğitimi: Spark NLP ve Azure Language özel modelleri eğittiğinizde, etki alanına özgü belge biçimlerine uyarlayabilirsiniz. Gerçek belgelerinizin temsili örnekleri üzerinde eğitim yaptığınızda, önceden oluşturulmuş modellerin iyi işleyemediği alanlar, varlıklar ve desenler için ayıklama doğruluğunu artırabilirsiniz.
Veri çeşitliliği ve karmaşıklığı
Farklı belge yapıları ve dilsel nüanslar karmaşıklık katıyor. Gerçek dünya metin verileri birçok biçimde, yazma stillerinde ve dillerde gelir. Bu varyasyonları ele almak için doğruluğu korurken belirsizlik, argo, kısaltmalar ve etki alanına özgü terminolojiyi işleyebilen modeller gerekir.
Spark NLP'deki MPNet eklemeleri, gelişmiş bağlamsal anlayış sağlar. MPNet eklemeleri, spark NLP işlem hatlarının nüanslı metinleri daha etkili bir şekilde işlemesine yardımcı olan sözcükler ve tümcecikler arasındaki bağlamsal ilişkileri yakalar. Bu eklemeler, farklı belge biçimlerinde anlamsal anlamı koruyan yoğun vektör gösterimleri oluşturur.
Azure Dil'deki özel modeller, etki alanına özgü metin desenlerine uyarlanmıştır. CNER ile, etki alanınıza özgü desenleri tanımak için modelleri kendi etiketlenmiş verilerinizde eğitebilirsiniz. Bu yaklaşım, modele önceden oluşturulmuş modellerin eksik olduğu varlıkları ve kategorileri tanımayı öğreterek güvenilirliği artırır.
Anahtar seçim ölçütlerini uygulama
Gereksinimlerinize en uygun Azure doğal dil işleme seçeneğini belirlemek için aşağıdaki ölçütleri kullanın. Her ölçüt bir iş yükü özelliğini açıklar ve bu özelliği ele alan hizmeti tanımlar.
Yönetilen doğal dil işleme özellikleri: Varlık tanıma, amaç belirleme, konu algılama veya yaklaşım analizi için Azure Language API'lerini kullanın. Bu özellikler, en az kurulumla yönetilen hizmetler olarak kullanılabilir ve herhangi bir altyapıyı sağlamanız veya yönetmeniz gerekmez.
Öncelemeli veya önceden eğitilmiş modeller: Altyapıyı yönetmeden önceden oluşturulmuş veya önceden eğitilmiş modelleri kullanmayı planlıyorsanız Azure Dili kullanın. Bu yaklaşım, önceden oluşturulmuş modellerin yeterli doğruluk sunduğu küçük ve orta ölçekli veri kümelerine ve standart doğal dil işleme görevlerine uygundur. Küme yönetimi ek yükü olmadan otomatik ölçeklendirme, yerleşik güvenlik ve çağrı başına ödeme fiyatlandırması sağlar.
Spark NLP ile büyük metin veri kümelerinde özel model eğitimi: Spark NLP ile Azure Databricks veya Fabric kullanın. Bu platformlar, büyük metin veri kümelerinde kapsamlı model eğitimi için ihtiyacınız olan hesaplama gücünü ve esnekliği sağlar. Ayrıca Llama 3.x ve MPNet de dahil olmak üzere Spark NLP aracılığıyla modelleri indirebilirsiniz.
Düşük seviyeli doğal dil işleme yapıtaşları: Belirteç oluşturma, kök ayıklama, lemmatizasyon ve TF-IDF için Azure Databricks veya Fabric'i Spark NLP ile kullanın. Alternatif olarak, spaCy veya NLTK gibi bir açık kaynak kitaplığı kullanın. Döküm Araçları'ndaki Azure Dili, model işlem hattının bir parçası olarak belirteç oluşturmayı dahili olarak kullanır, ancak bu adımları tek başına, denetlenebilir API'ler olarak sunmaz.
Spark NLP kullanarak doğal dil işleme işlem hatları oluşturma
Spark NLP, doğal dil işleme işlem hattı çalıştırdığınızda geleneksel Spark ML modellerinin geliştirme desenini izler. Eğitilen modelleri, deneme izleme ve üretim dağıtımı için MLflow kullanarak yönetirsiniz.

Çekirdek işlem hattı bileşenlerini birleştirme
Spark NLP işlem hattı, ek açıklayıcıları ardışık bir şekilde bağlar. Her bir açıklama yapan, önceki aşamanın çıktısını dönüştürür ve ham metni anlamsal vektörler oluşturacak şekilde geliştirir.
DocumentAssembler, her Spark NLP işlem hattının giriş noktasıdır.
setCleanupModeisteğe bağlı metin ön işlemesini, HTML etiketi kaldırma veya boşluk normalleştirme gibi işlemleri, sonraki süreç açıklayıcıları çalıştırılmadan önce uygulamak için kullanın.SentenceDetector, birleştirilmiş belgedeki cümle sınırlarını tanımlar. İşlem hattı yapılandırmanıza bağlı olarak
Arrayalgılanan tümceleri tek bir satır içinde veya ayrı satırlar olarak döndürür. Birçok aşağı akış işlemcisi cümle düzeyinde çalıştığı için doğru cümle tespiti önemlidir.Belirteç Oluşturucu ham metni sözcükler, sayılar ve simgeler gibi ayrık belirteçlere böler. Varsayılan kurallar etki alanınız için yetersizse, özel sözlük, hecelenmiş terimler veya etki alanına özgü desenleri işlemek için özel kurallar ekleyin.
Normalleştirici, normal ifadeler ve sözlük dönüştürmeleri uygulayarak belirteçleri daraltır. Eklemeden önce gürültüyü azaltmak için metni temizler. Örneğin, aksanları kaldırabilir, küçük harflere dönüştürebilir veya terminolojiyi standartlaştırmak için özel sözlük eşlemeleri uygulayabilirsiniz.
WordEmbeddings, bağlamsal işleme için belirteçleri anlamsal vektörlerle eşler. Her belirteç, diğer belirteçlere göre anlamını yakalayan yoğun bir vektör olarak temsil edilir. Ekleme sözlüğünde görünmeyen çözümlenmemiş belirteçler varsayılan olarak sıfır vektörleridir.
MLflow kullanarak modelleri yönetme
Spark NLP, yerel MLflow desteğine sahip Spark MLlib işlem hatlarını kullanır. Özel serileştirme veya tümleştirme kodu yazmanız gerekmez.
MLflow, deneme izleme, model sürümü oluşturma ve dağıtımı yönetir. Eğitim işlemleri sırasında işlem hattı parametrelerini, metriklerini ve artifaktlarını günlüğe kaydedebilirsiniz. MLflow her denemeyi izler, böylece yinelemelerdeki sonuçları karşılaştırabilir ve başarılı yapılandırmaları yeniden oluşturabilirsiniz.
MLflow doğrudan Azure Databricks ve Fabric ile tümleşir. Azure Databricks MLflow önceden yüklenmiş olarak gelir ve çalışma alanıyla sıkı bir şekilde tümleşir. Fabric ayrıca yerel deneme izleme ve otomatik kaydetme ile built-in MLflow deneyimi sağlar, bu nedenle MLflow'u ayrı olarak yüklemeniz gerekmez. Spark NLP'yi başka bir Apache Spark tabanlı ortamda çalıştırırsanız, MLflow'u ayrı olarak yükleyebilir ve uzaktan izleme sunucusuna yönelik denemeleri izlemek için yapılandırabilirsiniz.
Modelleri üretime yükseltmek ve idareyi korumak için MLflow Model Kayıt Defteri'ni kullanın. Model Kayıt Defteri, doğal dil işleme işlem hatlarınızdaki model sürümlerini yönetmek için merkezi bir depo sağlar. Klasik dağıtımlarda, modeller aşamalar halinde ön hazırlık, prodüksiyon ve arşivleme gibi süreçlerden geçer. Azure Databricks'da, daha yeni dağıtımlar Unity Kataloğu'ndaki Modelleri kullanır ve bu da sabit aşamaları daha esnek yaşam döngüsü yönetimi için özel diğer adlar ve etiketlerle değiştirir. Fabric üzerinde çalışma alanı kendi MLflow tabanlı model kayıt defterini sağlar.
Yetenek matrisi
Aşağıdaki tablolarda, Azure Databricks veya Fabric ile Azure Dili'nde Spark NLP arasındaki özelliklerdeki temel farklar özetlemektedir.
Genel özellikler
| Kabiliyet | Spark NLP (Azure Databricks veya Fabric) | Azure Dili |
|---|---|---|
| Hizmet olarak önceden eğitilmiş modeller | Evet | Evet |
| REST API | Evet | Evet |
| Programlanabilirlik | Python, Scala | Bkz. Desteklenen programlama dilleri. |
| Büyük veri kümelerinin ve büyük belgelerin işlenmesini destekler | Evet | Sınırlı 1 |
1.Azure Dili, moda göre değişen istek başına belge boyutu sınırlarına sahiptir. Zaman uyumlu istekler belge başına en çok 5.120 karakteri, zaman uyumsuz istekler ise belge başına en fazla 125.000 karakteri destekler. Her iki mod da API çağrısı başına en fazla 25 belgeyi destekler. Toplu işlem ve sayfalandırma aracılığıyla büyük veri kümesi birimlerini işleyebilirsiniz, ancak seçtiğiniz mod için karakter sınırını aşan tek tek belgeler için öbekleme gerekir. Daha fazla bilgi için bkz. Veri ve Azure Dili için hız sınırları.
Ek açıklama özellikleri
| Kabiliyet | Spark NLP (Azure Databricks veya Fabric) | Azure Dili |
|---|---|---|
| Cümle algılayıcısı | Evet | Hayı |
| Derin cümle algılayıcısı | Evet | Hayı |
| Belirteçleyici | Evet | Yalnızca iç kullanım için (bağımsız bir API olarak sunulmaz) |
| N-gram oluşturucu | Evet | Hayı |
| Kelime segmentasyonu | Evet | Evet |
| Stemmer | Evet | Hayı |
| Lemmatizer (Lema Çıkarıcı) | Evet | Hayı |
| Konuşma bölümü etiketleme | Evet | Hayı |
| Bağımlılık ayrıştırıcısı | Evet | Hayı |
| Çeviri | Evet | Hayı |
| Stopword temizleyici | Evet | Hayı |
| Yazım düzeltmesi | Evet | Hayı |
| Normalleştirici | Evet | Evet |
| Metin eşleştirici | Evet | Hayı |
| TF-IDF | Evet | Hayı |
| Normal ifade eşleştiricisi | Evet | Sınırlı |
| Tarih eşleştirici | Evet | Sınırlı |
| Öbekleyici | Evet | Hayı |
Üst düzey doğal dil işleme özellikleri
| Kabiliyet | Spark NLP (Azure Databricks veya Fabric) | Azure Dili |
|---|---|---|
| Yazım denetimi | Evet | Hayı |
| Özetleme | Evet | Evet |
| Soru cevaplama | Evet | Evet |
| Duygu algılama | Evet | Evet |
| Duygu algılama | Evet | Sınırlı 2 |
| Belirteç sınıflandırması | Evet | Sınırlı 3 |
| Metin sınıflandırması | Evet | Sınırlı 3 |
| Metin gösterimi | Evet | Hayı |
| NER (İngilizce) | Evet | Evet (önceden oluşturulmuş). CNER, özel modeller aracılığıyla kullanılabilir. 3 |
| Dil algılama | Evet | Evet |
| İngilizce dışındaki dilleri destekler | Evet. Bkz. Spark NLP tarafından desteklenen diller. | Evet. Bkz. Azure Dil desteklenen diller. |
2.Azure Dil, metnin belirli yönlerine bağlı yaklaşımları tanımlayan ancak özel duygu algılama (neşe, öfke veya üzüntü sınıflandırması gibi) sağlamayan görüş madenciliği destekler.
3.Özelmodeller aracılığıyla kullanılabilir. CNER veya özel varlık tanıma modellerini kendi etiketli verileriniz üzerinde eğitebilirsiniz.
Katkıda Bulunanlar
Microsoft bu makaleyi korur. Bu makaleyi aşağıdaki katkıda bulunanlar yazdı.
Asıl yazarlar:
- Ananya Ghosh Chowdhury | Ana Bulut Çözümü Mimarı
- Kranthi Manchikanti | Kıdemli Yapay Zeka Çözümleri Mühendisi
Diğer katkıda bulunanlar:
- Freddy Ayala | Bulut Çözümü Mimarı
- Tincy Elias | Üst Düzey Bulut Çözümü Mimarı
- Moritz Steller | Üst Düzey Bulut Çözümü Mimarı
Gizli LinkedIn profillerini görmek için LinkedIn'de oturum açın.
Sonraki adımlar
İlgili kaynaklar
Azure Dili belgeleri:
Spark NLP belgeleri:
Azure bileşenleri:
Kaynakları öğrenin: