Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Azure Depolama
Sorguların sıklıkla başvurduğu veri kaynaklarındaki alanlar üzerinden dizin oluşturun. Bu düzen, uygulamaların bir veri deposundan alınacak verileri daha hızlı bir şekilde bulmasına olanak vererek sorgu performansını iyileştirebilir.
Bağlam ve sorun
Birçok veri deposu birincil anahtarı kullanan varlık koleksiyonları için verileri düzenler. Uygulamalar bu anahtarı verileri bulmak ve almak için kullanabilir. Şekilde, müşteri bilgileri içeren bir veri deposu örneği gösterilmektedir. Birincil anahtar müşteri kimliğidir. Şekilde birincil anahtara (Müşteri Kimliği) göre düzenlenen kullanıcı bilgileri gösterilmektedir.
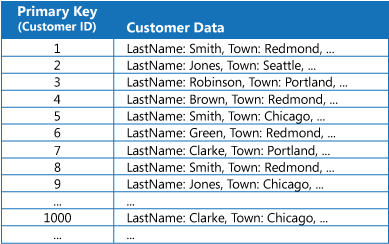
Birincil anahtar, bu anahtarın değerine göre veri alan sorgular için değerli olsa da, bir uygulamanın bazı diğer temel alanlara göre veri alması gerekirse birincil anahtarı kullanması mümkün olmayabilir. Müşteriler örneğinde uygulama, verileri yalnızca diğer bir özniteliğin değerine başvurarak sorguluyorsa, örneğin müşterinin bulunduğu şehir gibi, Müşteri Kimliği birincil anahtarını kullanamaz. Böyle bir sorguyu gerçekleştirmek için uygulamanın her müşteri kaydını alıp incelemesi gerekebilir ve bu yavaş bir işlem olabilir.
Pek çok ilişkisel veritabanı yönetim sistemi ikincil dizinler destekler. İkincil dizin, bir veya daha fazla birincil olmayan (ikincil) anahtar alanlarına göre düzenlenmiş ayrı bir veri yapısıdır ve dizini oluşturulmuş her bir değerin verilerinin nerede depolandığını belirtir. İkincil dizindeki öğeler, hızlı veri arama olanağı sunmak için genellikle ikincil anahtarların değerlerine göre sıralanır. Bu dizinler çoğunlukla veritabanı yönetim sistemi tarafından otomatik olarak sürdürülür.
Uygulamanızın gerçekleştirdiği farklı sorguları desteklemek için gereksinim duyduğunuz kadar çok ikincil dizin oluşturabilirsiniz. Örneğin, Müşteri Kimliğinin birincil anahtar olduğu ilişkisel bir veritabanındaki Müşteriler tablosunda, uygulama müşterileri bulundukları şehre göre arıyorsa şehir alanına ikincil bir dizin eklemek faydalı olur.
Ancak, ikincil dizinler ilişkisel sistemlerde yaygın olsa da, bulut uygulamaları tarafından kullanılan bazı NoSQL veri depoları eşdeğer bir özellik sağlamaz.
Çözüm
Veri deposu ikincil dizinleri desteklemiyorsa, bunları el ile kendi dizin tablolarınızı oluşturarak kullanabilirsiniz. Dizin tabloları, verileri belirli anahtar verilere göre düzenler. Bir dizin tablosunu yapılandırmak için genellikle gereken ikincil dizin sayısına ve uygulamanın gerçekleştirdiği sorguların yapısına göre üç strateji kullanılır.
İlk strateji, her dizin tablosundaki verileri yinelemek ancak farklı anahtarlara (tam normalleştirilmişlikten çıkarma) göre düzenlemektir. Sonraki şekilde, aynı müşteri bilgilerini Şehir ve Soyadı bilgilerine göre düzenleyen dizin tabloları gösterilir.
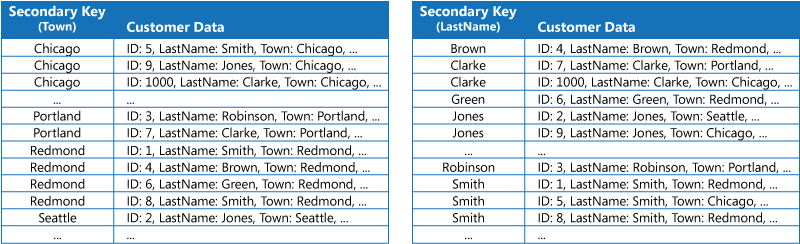
Veriler, her anahtar kullanılarak kaç defa sorgulandığı açısından görece statik ise bu strateji uygundur. Veriler daha dinamik ise, her dizin tablosunu işleme yükü bu yaklaşımın kullanışlı olmayacağı kadar büyük hale gelir. Ayrıca, veri hacmi yüksekse, yinelenen verileri depolamak için gereken alan miktarı önemlidir.
İkinci strateji, farklı anahtarlara göre düzenlenen ve özgün verilere birincil anahtarı yinelemek yerine bu anahtarı kullanarak ulaşan (aşağıdaki şekilde gösterilmiştir) normalleştirilmiş dizin tabloları oluşturmaktır. Özgün verilere olgu tablosu adı verilir.
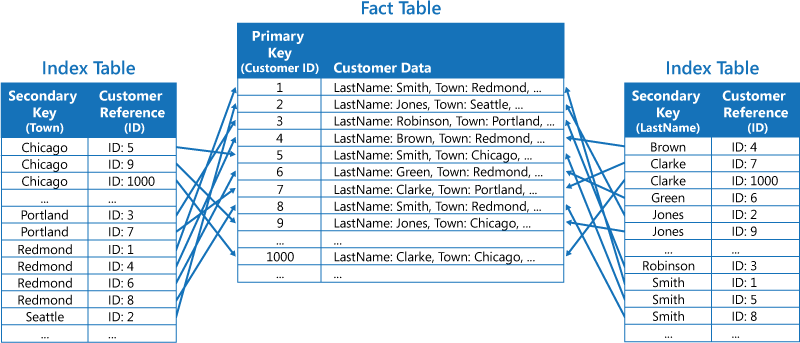
Bu teknik, alan tasarrufu yapılmasını sağlar ve yinelenen verileri saklama yükünü azaltır. Olumsuz yönüyse, uygulamanın ikincil bir anahtar kullanarak verileri bulmak üzere iki arama işlemi gerçekleştirmesi gerekmesidir. Dizin tablosundaki veriler için birincil anahtarı bulmalıdır, ardından birincil anahtarla olgu tablosundaki verilere bakmalıdır.
Üçüncü strateji, sık alınan alanları yineleyen farklı anahtarlara göre düzenlenmiş kısmen normalleştirilmiş dizin tabloları oluşturmaktır. Daha az sıklıkta erişilen erişim alanlarına erişmek için olgu tablosuna başvurun. Aşağıdaki şekilde, her dizin tablosunda sıklıkla erişilen verilerin nasıl yinelendiği gösterilmiştir.
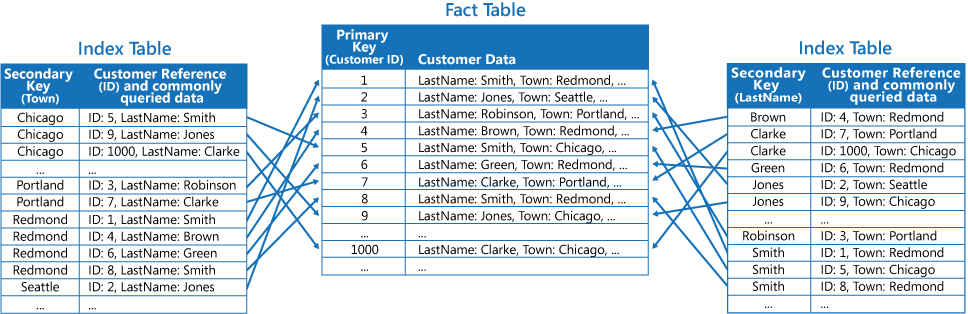
Bu strateji ile ilk iki yaklaşım arasında bir denge kurabilirsiniz. Genel sorgular için veriler tek bir arama kullanılarak alınabilir, alanı ve bakım yükü de tüm veri kümesinin çoğaltılmasında olduğu kadar fazla değildir.
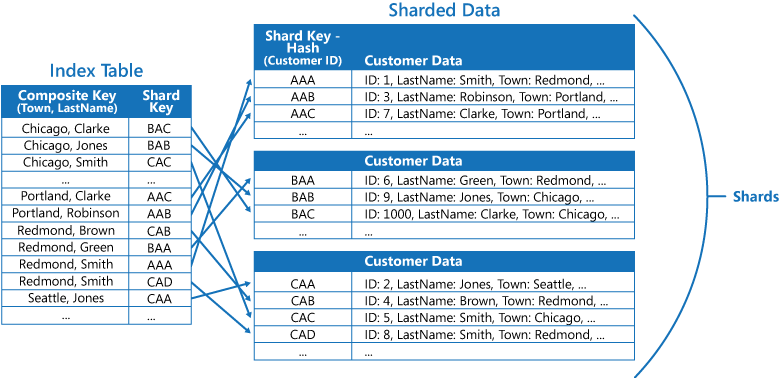
Bir uygulama sık sık değerlerin bir bileşimini belirterek (örneğin, "Redmond'da yaşayan ve soyadı Smith olan tüm müşterileri bul") verileri sorgularsa, dizin tablosundaki öğelerin anahtarlarını Town özniteliğiyle LastName özniteliğinin birleştirilmesi olarak uygulayabilirsiniz. Sonraki şekilde bileşik anahtara göre bir dizin tablosu gösterilir. Anahtarlar önce Şehre göre, sonra da Şehir için aynı değere sahip olan kayıtlar için Soyadına göre sıralanır.

Dizin tabloları, parçalı veriler üzerinde sorgu işlemlerini hızlandırabilir ve parça anahtarı karma olduğunda özellikle yararlıdır. Sonraki şekilde parça anahtarının Müşteri Kimliği karması olduğu bir örnek gösterilmiştir. Dizin tablosu, verileri karma olmayan değerlere göre düzenleyebilir (Şehir ve Soyadı) ve arama verisi olarak karma haline getirilmiş parça anahtarını sağlayabilir. Böylece uygulamanın belirli bir aralıktan veri alması gerekiyorsa veya karma olmayan anahtara göre veri getirmesi gerekiyorsa sürekli karma anahtarları hesaplaması gerekmez (bu pahalı bir işlemdir). Örneğin, "Redmond'da yaşayan tüm müşterileri bul" gibi bir sorgu, eşleşen öğeleri dizin tablosunda bularak hızlı bir şekilde çözümlenebilir ve bunların hepsi bitişik bir blokta depolanır. Ardından, dizin tablosunda depolanan parça anahtarları kullanılarak müşteri verilerine başvurular izlenir.
Sorunlar ve dikkat edilmesi gerekenler
Bu düzenin nasıl uygulanacağına karar verirken aşağıdaki noktaları göz önünde bulundurun:
İkincil dizinlerin bakım maliyeti önemli ölçüde fazla olabilir. Uygulamanızın kullandığı sorguları analiz etmeniz ve anlamanız gerekir. Dizin tablolarını yalnızca düzenli olarak kullanılma olasılığı varsa oluşturun. Bir uygulamanın gerçekleştirmediği veya nadiren gerçekleştirdiği sorguları desteklemek için kurgusal dizin tabloları oluşturmayın.
Bir dizin tablosunda veri çoğaltma yapılması depolama maliyetlerini ve verilerin birden çok kopyasını tutmak için gereken çabayı önemli ölçüde artırabilir.
Bir dizin tablosunu orijinal verilere başvuruda bulunan normalleştirilmiş bir yapı olarak uygulamak, uygulamanın veri bulmak için iki arama işlemi gerçekleştirmesini gerektirir. İlk işlem, birincil anahtarı almak için dizin tablosunda arama yapar ve ikinci işlem de veri getirmek için birincil anahtarı kullanır.
Bir sistem büyük veri kümeleri üzerinde bir dizi dizin tablosuna sahipse, dizin tabloları ile özgün veriler arasında tutarlılık sağlamak zor olabilir. Uygulamayı son tutarlılık modeline göre tasarlamak mümkün olabilir. Örneğin veri eklemek, güncelleştirmek veya silmek için bir uygulama, sıraya bir ileti gönderebilir ve ayrı bir görevin bu işlemi yapmasına ve bu verilere zaman uyumsuz olarak başvuran dizin tablolarını tutmasına olanak verebilir. Son tutarlılık uygulama hakkında daha fazla bilgi için bkz. Veri tutarlılığı Temel Bilgileri.
İpucu
Microsoft Azure depolama tabloları aynı bölümde tutulan verilerde yapılan değişiklikler için işlem güncelleştirmelerini (varlık grubu işlemleri olarak adlandırılır) destekler. Bir olgu tablosu için verileri ve bir veya daha fazla dizin tablosunu aynı bölümde depolayabilirseniz, tutarlılık sağlanmasına yardımcı olması için bu özelliği kullanabilirsiniz.
Dizin tabloları bölümlenmiş ya da parçalı olabilir.
Bu düzenin kullanılacağı durumlar
Bir uygulamanın sıklıkla birincil (veya parçalı) anahtarı dışında bir anahtar kullanarak veri alması gerekiyorsa sorgu performansını artırmak için bu düzeni kullanın.
Bu düzen aşağıdaki durumlarda kullanışlı olmayabilir:
- Veriler geçicidir. Bir dizin tablosu çok hızlı bir şekilde eskiyerek verimsizleşebilir veya tutulması, dizin tablosunu kullanarak yapılan tasarruflardan daha masraflı hale gelebilir.
- Bir dizin tablosu için ikincil anahtar olarak seçilen alanlar fark gözetmez ve yalnızca küçük bir değerler kümesi (örneğin cinsiyet) olabilir.
- Bir dizin tablosu için ikincil anahtar olarak seçilen alanın veri değerleri büyük oranda asimetriktir. Örneğin, kayıtların % 90'ı alandaki aynı değeri içeriyorsa, bu alana göre veri aramak için bir dizin tablosunun oluşturulması ve bakımı verileri sırayla taramaya göre daha fazla ek yük oluşturabilir. Ancak, sorgular çok sık geri kalan %10 içinde bulunan değerleri hedefliyorsa, bu dizin yararlı olabilir. Uygulamanızın çalıştırdığı sorguları ve bu sorguların ne sıklıkla çalıştırıldığını bilmeniz gerekir.
İş yükü tasarımı
Bir mimar, Azure İyi Tasarlanmış Çerçeve yapılarında ele alınan hedefleri ve ilkeleri ele almak için dizin tablosu düzeninin iş yükünün tasarımında nasıl kullanılabileceğini değerlendirmelidir. Örneğin:
| Yapı Taşı | Bu desen sütun hedeflerini nasıl destekler? |
|---|---|
| Güvenilirlik tasarımı kararları, iş yükünüzün arızaya karşı dayanıklı olmasına ve bir hata oluştuktan sonra tamamen çalışır duruma gelmesini sağlamaya yardımcı olur. | İstemciler bir arama işlemi aracılığıyla parçalarına, bölümlerine veya uç noktalarına işaret edildiğinden, veri erişimi için yük devretme yaklaşımını kolaylaştırmak için bu düzeni kullanabilirsiniz. - RE:06 Veri bölümleme - RE:09 Olağanüstü durum kurtarma |
| Performans Verimliliği , ölçeklendirme, veri ve kod iyileştirmeleri aracılığıyla iş yükünüzün talepleri verimli bir şekilde karşılamasını sağlar. | İstemciler performans iyileştirmesi için dinamik veri bölümlemesi etkinleştirebilen parçalarına, bölümlerine veya uç noktalarına işaret edilir. - PE:05 Ölçeklendirme ve bölümleme - PE:08 Veri performansı |
Herhangi bir tasarım kararında olduğu gibi, bu desenle ortaya konulabilecek diğer sütunların hedeflerine karşı herhangi bir dengeyi göz önünde bulundurun.
Örnek
Azure depolama tabloları, bulutta çalışan uygulamalar için yüksek oranda ölçeklenebilir bir anahtar/değer veri deposu sağlar. Uygulamalar, veri değerlerini bir anahtarı belirterek depolar ve alır. Bu veri değerleri birden çok alan içerebilir, ancak bir veri öğesinin yapısı tablo depolamaya göre donuk olur ve bu da her öğeyi bayt dizisi olarak değerlendirir.
Azure depolama tabloları, parçalamayı da destekler. Parçalama anahtarı bir bölüm anahtarı ve bir kayıt anahtarı olmak üzere iki öğe içerir. Aynı bölüm anahtarına sahip öğeler aynı bölümde (parça) saklanır ve öğeler, parça içindeki kayıt anahtarı sırasında depolanır. Tablo depolaması, bir bölüm içindeki bütün bir aralıkta kalan kayıt anahtarı değerlerinden veri alan sorguları gerçekleştirmek için en iyi duruma getirilmiştir. Azure tablolarında bilgi depolayan bulut uygulamaları oluşturuyorsanız, verilerinizi bu özelliğe göre yapılandırmalısınız.
Örneğin, filmlerle ilgili bilgiler depolayan bir uygulama düşünün. Uygulama sıklıkla filmleri türe göre sorgular (eylem, belgesel, tarihi, komedi ve drama gibi). Türü bölüm anahtarı olarak kullanarak ve satır anahtarı olarak film adı belirterek aşağıda gösterildiği gibi her bir tür için bölümleri olan bir Azure tablosu oluşturabilirsiniz.
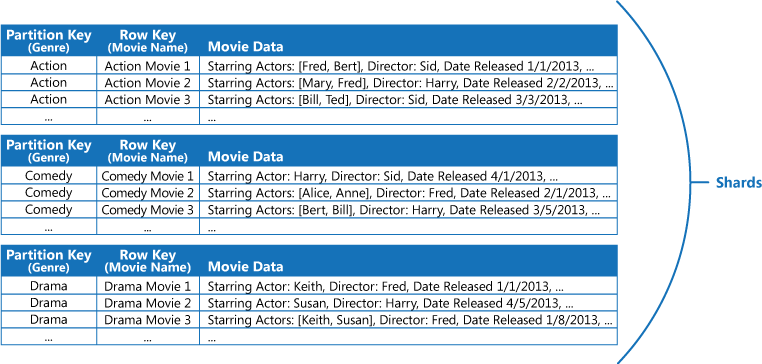
Bu yaklaşım, uygulamanın filmleri başrol aktörüne göre de sorgulaması gerekiyorsa daha az etkili olur. Bu durumda, bir dizin tablosu olarak davranan ayrı bir Azure tablosu oluşturabilirsiniz. Bölüm anahtarı aktör olur ve kayıt anahtarı da film adı olur. Her aktör için veriler ayrı bölümlerde depolanır. Bir filmde birden fazla aktör varsa aynı film birden çok bölümden oluşur.
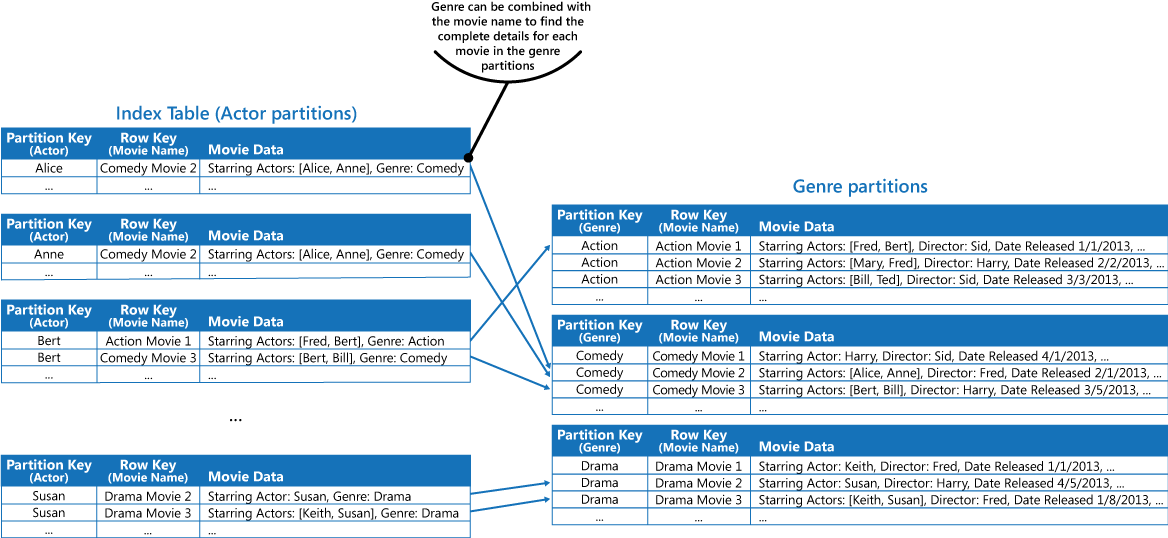
Yukarıdaki çözüm bölümünde açıklanan ilk yaklaşımı kullanarak her bölümde tutulan değerlerdeki film verilerini çoğaltabilirsiniz. Bununla birlikte, her filmin birkaç kez (her aktör için bir kez) çoğaltılması olasıdır. Bu nedenle (örneğin, diğer aktörler adları) en yaygın sorguları desteklemek için verileri kısmen normalleştirilmişten çıkarmak ve tür bölümlerinde tam bilgiyi bulmak için gereken bölüm anahtarını dahil ederek uygulamanın kalan diğer ayrıntıları almasına olanak vermek daha verimli olabilir. Bu yaklaşım, Çözüm bölümündeki üçüncü seçenekte açıklanmıştır. Sonraki şekilde bu yaklaşım gösterilmiştir.
Sonraki adımlar
- Veri Tutarlılığı Temel Bilgileri. Dizin tablosunun dizinlediği veriler değiştiğinde dizin tablosuna bakım yapılmalıdır. Bulutta, verileri değiştiren işlemin bir parçası olarak dizini güncelleştiren işlemleri gerçekleştirmek olası veya doğru olmayabilir. Bu durumda, sonuçta tutarlı bir yaklaşım daha uygundur. Son tutarlılıkla ilgili sorunlar hakkında bilgi sağlar.
İlgili kaynaklar
Bu desen uygulanırken aşağıdaki desenler de uygun olabilir:
- Parçalama düzeni. Dizin Tablosu düzeni, parça kullanarak bölümlenmiş verilerle birlikte sık kullanılır. Parçalama düzeni, bir veri deposunu parça kümesine bölme hakkında daha fazla bilgi sağlar.
- Gerçekleştirilmiş Görünüm düzeni. Verileri özetleyen sorguları desteklemek için veri dizini oluşturmak yerine verilerin gerçekleştirilmiş görünümünü oluşturmak daha uygun olabilir. Veriler üzerinde önceden doldurulmuş görünümler oluşturarak verimli özet sorgularının nasıl destekleneceğini açıklar.