Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Azure
Bir uygulamanın bir hizmete veya ağa bağlanmayı denerken karşılaştığı geçici hataları, başarısız olmuş bir işlemi saydam bir şekilde yeniden deneyerek işlemesine olanak tanıyın. Bu, uygulamanın kararlılığını iyileştirebilir.
Bağlam ve sorun
Bulutta çalışan öğelerle iletişim kuran bir uygulama, bu ortamda oluşabilecek geçici hataları duyarlı olmalıdır. Bileşen ve hizmetlerle ağ bağlantısının anlık olarak kaybedilmesi, bir hizmetin geçici olarak kullanım dışı kalması veya bir hizmet meşgul olduğunda gerçekleşen zaman aşımları bu hatalar arasında yer alır.
Bu hatalar genellikle kendi kendine düzelir ve hataya yol açan eylem uygun gecikme süresi dolunca yinelenirse başarılı olma olasılığı yüksektir. Örneğin, çok sayıda eşzamanlı isteği işleyen bir veritabanı hizmeti, iş yükü hafifleyene kadar diğer istekleri geçici olarak reddeden bir azaltma stratejisi uygulayabilir. Veritabanına erişmeye çalışan bir uygulama bağlanamayabilir, ancak gecikme süresi dolunca yeniden denerse başarılı olabilir.
Çözüm
Bulutta geçici hatalar beklenmeli ve bir uygulama bunları zarif ve şeffaf bir şekilde işleyecek şekilde tasarlanmalıdır. Bunun yapılması, hataların uygulamanın gerçekleştirdiği iş görevleri üzerindeki etkilerini en aza indirir. Ele alınacak en yaygın tasarım deseni, yeniden deneme mekanizmasını tanıtmaktır.
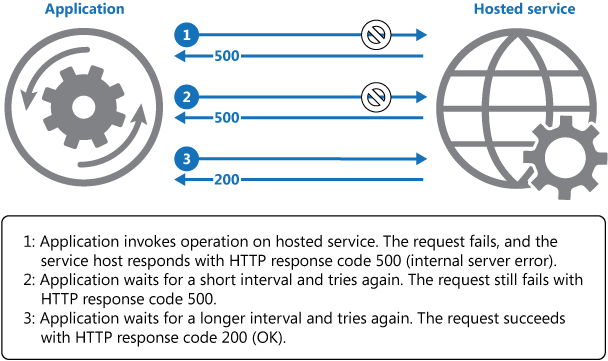
Yukarıdaki diyagramda, yeniden deneme mekanizması kullanılarak barındırılan bir hizmetteki bir işlemi çağırma gösterilmektedir. Önceden tanımlanmış bir girişim sayısına ulaşılmasına rağmen istek başarısız olursa uygulama hatayı özel bir durum olarak ele almalı ve uygun şekilde işlemelidir.
Not
Geçici hataların yaygın doğası gereği, yerleşik yeniden deneme mekanizmaları artık birçok istemci kitaplığında ve bulut hizmetinde kullanılabilir ve en fazla yeniden deneme sayısı, yeniden denemeler arasındaki gecikme ve diğer parametreler için bir derece yapılandırılabilirlik sunar. Örneğin, Entity Framework Corebaşarısız veritabanı işlemlerini yeniden deneme olanağı sağlar.
Yeniden deneme stratejileri
Bir uygulama uzak bir hizmete istek göndermeye çalışırken bir hata algılarsa, hatayı aşağıdaki stratejileri kullanarak işleyebilir:
İptal etme. Hatanın geçici olmadığı veya yinelenirse başarılı sonuç alma olasılığının düşük olduğu belirtiliyorsa uygulama işlemi iptal etmeli ve bir özel durum bildirmelidir.
Hemen yeniden deneyin. Bildirilen belirli hata, bir ağ paketinin iletilirken bozulması gibi olağan dışı veya nadir bir hataysa, en iyi eylem isteği hemen yeniden denemek olabilir.
Gecikme süresi dolunca yeniden deneme. Hatanın nedeni daha yaygın bağlantı sorunlarından veya aşırı yüklenmelerden biriyse, bağlantı sorunları giderilirken veya iş yükü birikimi temizlenirken ağ veya hizmetin kısa bir süreye ihtiyacı olabilir, bu nedenle yeniden denemeyi programlı olarak geciktirmek iyi bir stratejidir. Birçok durumda, uygulamanın birden fazla örneğinden gelen isteklerin mümkün olduğunca eşit bir şekilde dağıtılması için, tekrar denemeler arasındaki aralık, meşgul bir hizmetin aşırı yük altında kalma olasılığını azaltacak şekilde seçilmelidir.
İstek yine başarısız olursa, uygulama bir süre bekleyip başka bir girişimde bulunabilir. Gerekirse, en fazla istek girişimi sayısına ulaşılana kadar, yeniden deneme girişleri arasındaki gecikme süresi artırılarak bu işlem yinelenebilir. Gecikme süresi, hatanın türüne ve ilgili süre içinde düzelme olasılığına bağlı olarak kademeli bir şekilde veya katlanarak artırılabilir.
Uygulama, uzak bir hizmete erişmeye yönelik tüm girişimleri, yukarıda listelenen stratejilerden biriyle eşleşen bir yeniden deneme ilkesi uygulayan kodda sarmalamalıdır. Farklı hizmetlere gönderilen istekler farklı ilkelere tabi olabilir.
Uygulamalar hataların ve başarısız işlemlerin ayrıntılarını günlüğe kaydetmelidir. Bu bilgiler operatörler için yararlıdır. Bu nedenle, yeniden denenen girişimlerin başarılı olduğu operasyonlar hakkında işleçlerin uyarı yağmuruna tutulmasını önlemek için, ilk hataların bilgilendirme girişi olarak günlüğe kaydedilmesi ve yalnızca son yeniden deneme girişiminin başarısızlığının gerçek bir hata olarak kaydedilmesi en iyisidir. Bu günlük modelinin nasıl görünebileceğine bir örnek aşağıda verilmiştir.
Bir hizmet sık sık kullanılamaz hale geliyor veya meşgul oluyorsa çoğu zaman bunun nedeni hizmetin kaynaklarını tüketmiş olmasıdır. Hizmetin ölçeğini genişleterek bu hataların sıklığını azaltabilirsiniz. Örneğin, bir veritabanı hizmeti sürekli olarak aşırı yükleniyorsa veritabanını bölümlemek ve yükü birden çok sunucuya dağıtmak yararlı olabilir.
Sorunlar ve dikkat edilmesi gerekenler
Bu düzeni nasıl uygulayacağınıza karar verirken aşağıdaki noktaları dikkate almalısınız.
Performans üzerindeki etki
Yeniden deneme ilkesi, uygulamanın iş gereksinimleri ve hatanın yapısı ile eşleşecek şekilde ayarlanmalıdır. Bazı kritik olmayan işlemler için, birkaç kez yeniden denemek ve uygulamanın aktarım hızını etkilemek yerine hızlı başarısız olmak daha iyidir. Örneğin, uzak bir hizmete erişen etkileşimli bir web uygulamasında, yeniden deneme girişimleri arasında yalnızca kısa bir gecikmeyle daha az sayıda yeniden denemeden sonra başarısız olmak ve kullanıcıya uygun bir ileti görüntülemek daha iyidir (örneğin, "lütfen daha sonra yeniden deneyin"). Bir toplu iş uygulaması için girişimler arasındaki gecikme süresini katlamalı bir şekilde artırarak yeniden deneme girişimi sayısını artırmak daha uygun olabilir.
Girişimler arasındaki minimal gecikmeyle ve yüksek sayıda tekrar deneme içeren agresif bir yeniden deneme ilkesi, kapasitesine yakın veya tam kapasitede çalışan meşgul bir hizmetin performansını daha da düşürebilir. Uygulama sürekli başarısız olan bir işlemi gerçekleştirmeye çalışıyorsa, bu yeniden deneme ilkesi uygulamanın yanıt verme hızını da etkileyebilir.
Önemli sayıda yeniden denemeden sonra istek yine başarısız olursa, uygulamanın aynı kaynağa giden diğer istekleri önlemesi ve hemen bir hata bildirmesi daha iyidir. Süre dolduğunda, uygulama bir veya daha fazla isteğe kontrollü bir şekilde izin vererek bunların başarılı olup olmadığını denetleyebilir. Bu strateji hakkında daha fazla bilgi için Devre Kesici deseni’ne bakın.
Idempotans
İşlemin etkisiz değişmez olup olmadığını göz önünde bulundurun. Eğer öyleyse, tekrar denemek doğası gereği güvenlidir. Aksi takdirde, yeniden deneme girişimleri işlemin birden fazla kez yürütülmesine ve istenmeyen yan etkilere neden olabilir. Örneğin, bir hizmet isteği alıp başarıyla işlemesine rağmen yanıt gönderemiyor olabilir. Bu noktada, yeniden deneme mantığı ilk isteğin alınmadığını varsayarak isteği yeniden gönderebilir.
Özel durum türü
Bir hizmete yönelik istek, hatanın niteliğine bağlı olarak farklı özel durumlara neden olan çeşitli nedenlerden dolayı başarısız olabilir. Bazı özel durumlar hızlı bir şekilde çözülebilecek bir hata olduğunu gösterirken, bazıları hatanın daha kalıcı olduğunu gösterebilir. Yeniden deneme ilkesinin özel durum türüne göre yeniden deneme girişimleri arasındaki süreyi ayarlaması yararlıdır.
İşlem tutarlılığı
Bir işlemin parçası olan bir alt işlemin yeniden denenmesinin genel işlem tutarlılığını nasıl etkileyeceğini göz önünde bulundurun. İşlem alt işlemlerinin başarı olasılığını en üst düzeye çıkarmak ve tüm işlem adımlarını geri alma gereksinimini azaltmak için yeniden deneme ilkesinde ince ayar yapın.
Genel kılavuz
Tüm yeniden deneme kodlarının çeşitli hata koşullarına karşı tam olarak test edilmiş olduğundan emin olun. Uygulamanın performansını veya güvenilirliğini ciddi şekilde etkilemediğinden, hizmet ve kaynaklarda aşırı yüke neden olmadığından veya yarış koşulları ya da performans sorunları oluşturup oluşturmadığını denetleyin.
Yalnızca başarısız olan bir işlemin tam bağlamının anlaşıldığı durumlarda yeniden deneme mantığı uygulayın. Örneğin, yeniden deneme ilkesi içeren bir görev yeniden deneme ilkesi içeren başka bir görevi çağırdığında, bu ek yeniden deneme katmanı işlemlerde daha uzun gecikme yaşanmasına neden olabilir. Daha düşük düzeyli görevi, hızlıca başarısız olacak ve hatanın nedenini kendisini çağıran göreve raporlayacak şekilde yapılandırmak daha iyi olabilir. Daha sonra, bu üst düzey görev hatayı kendi ilkesine göre işleyebilir.
Yeniden denemeye neden olan tüm bağlantı hatalarını günlüğe kaydederek uygulama, hizmetler veya kaynaklarla ilgili temel sorunların tanımlanabilmesini sağlayın.
Bir hizmet veya kaynak için gerçekleşme olasılığı en yüksek hataları araştırarak bunların uzun süreli veya kalıcı olup olmadığını keşfedin. Böyle durumlarda hatanın bir özel durum olarak ele alınması daha iyidir. Uygulama özel durumu bildirebilir veya günlüğe kaydedebilir ve sonra alternatif bir hizmeti (varsa) çağırarak ya da daha düşük işlevsellik sunarak devam etmeye çalışabilir. Uzun süreli hataları algılama ve işleme hakkında daha fazla bilgi için bkz. Devre Kesici düzeni.
Bu düzenin kullanılacağı durumlar
Bir uygulamanın uzak bir hizmetle etkileşim kurarken veya uzak bir kaynağa erişirken geçici hatalar yaşama olasılığı varsa bu düzeni kullanın. Bu hataların kısa süreli olması beklenir ve daha önce başarısız olmuş bir istek, sonraki bir denemede başarılı olabilir.
Bu düzen aşağıdaki durumlarda kullanışlı olmayabilir:
- Bir hatanın uzun süreli olma olasılığı yüksekse, çünkü bu, bir uygulamanın yanıt verme hızını etkileyebilir. Uygulama, başarısız olma olasılığı yüksek olan bir isteği tekrarlamaya çalışarak zaman ve kaynak israfı yapıyor olabilir.
- Bir uygulamanın iş mantığındaki hatalardan kaynaklanan iç özel durumlar gibi geçici hatalardan kaynaklanmayan hataların işlenmesi için.
- Bir sistemdeki ölçeklenebilirlik sorunlarını gidermek için alternatif bir yöntem olarak. Bir uygulamada sık sık meşguliyet hataları oluşuyorsa, bu genellikle erişilen hizmetin veya kaynağın büyütülmesi gerektiğini gösteren bir işarettir.
İş yükü tasarımı
Bir mimar, Azure İyi Tasarlanmış Çerçeve yapılarında ele alınan hedefleri ve ilkeleri ele almak için yeniden deneme düzeninin iş yükünün tasarımında nasıl kullanılabileceğini değerlendirmelidir. Örneğin:
| Kolon | Bu desen sütun hedeflerini nasıl destekler? |
|---|---|
| Güvenilirlik tasarımı kararları, iş yükünüzün arızaya karşı dayanıklı olmasına ve bir hata oluştuktan sonra tamamen çalışır duruma gelmesini sağlamaya yardımcı olur. | Dağıtılmış bir sistemde geçici hataları azaltmak, bir iş yükünün dayanıklılığını geliştirmeye yönelik temel bir tekniktir. - RE:07 Kendini koruma - RE:07 Geçici hatalar |
Herhangi bir tasarım kararında olduğu gibi, bu desenle ortaya çıkabilecek diğer sütunların hedeflerine karşı yapılabilecek tavizleri göz önünde bulundurun.
Örnek
Yerleşik yeniden deneme mekanizması desteğiyle Azure SDK'sını kullanarak ayrıntılı bir örnek için .NET ile yeniden deneme ilkesi uygulama kılavuzuna bakın.
Sonraki adımlar
Özel yeniden deneme mantığı yazmadan önce.NET için Polly veya Java için Resilience4j gibi genel bir çerçeve kullanmayı göz önünde bulundurun.
İş verilerini değiştiren komutları işlerken, yeniden denemelerin eylemin iki kez gerçekleştirilmesiyle sonuçlanabileceğini ve bu eylemin müşterinin kredi kartını ücretlendirmeye benzer bir işlem olması durumunda sorunlu olabileceğini unutmayın. Bu blog gönderisinde açıklanan idempotence desenini kullanmak bu durumları çözmeye yardımcı olabilir.
İlgili kaynaklar
Çoğu Azure hizmeti için istemci SDK'ları yerleşik yeniden deneme mantığını içerir.
Devre Kesici düzeni. Bir hatanın daha uzun süreli olması bekleniyorsa, Devre Kesici düzeninin uygulanması daha uygun olabilir. Yeniden Deneme ve Devre Kesici desenlerinin birleştirilmesi, hataları işlemeye yönelik kapsamlı bir yaklaşım sağlar.