Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu makalede, Azure İzleyici platform ölçümlerini ve özel ölçümleri destekleyen zaman serisi veritabanındaki ölçümlerin toplanması açıklanmaktadır. Makale standart Application Insights ölçümleri için de geçerlidir.
Bu makaledeki bu bilgiler karmaşıktır ve ölçüm sistemini daha ayrıntılı incelemek isteyenler için sağlanır. Azure İzleyici ölçümlerini etkili bir şekilde kullanmak için bunu anlamanız gerekmez.
Genel bakış ve terimler
Grafiğe ölçüm eklediğinizde ölçüm gezgini varsayılan toplama işlemini otomatik olarak önceden seçer. Temel senaryolarda varsayılan değer mantıklıdır, ancak ölçüm hakkında daha fazla içgörü elde etmek için farklı toplamalar kullanabilirsiniz. Grafikte farklı toplamaları görüntülemek için ölçüm gezgininin bunları nasıl işlediğini anlamanız gerekir.
Önce birkaç terimi net bir şekilde tanımlayalım:
- Ölçüm değeri : Belirli bir kaynak için toplanan tek bir ölçüm değeri.
- Zaman Serisi veritabanı - Bir değer ve buna karşılık gelen bir zaman damgası içeren veri noktalarının depolanması ve alınması için iyileştirilmiş bir veritabanı.
- Zaman aralığı : Genel bir zaman aralığı.
- Zaman aralığı : İki ölçüm değerinin toplanması arasındaki süre.
- Zaman aralığı : Grafikte görüntülenen zaman aralığı. Varsayılan değer 24 saattir. Yalnızca belirli aralıklar kullanılabilir.
- Zaman tanecikliği veya zaman dilimi : Bir grafikte görüntülenmesine izin vermek için değerleri birlikte toplamak için kullanılan zaman aralığı. Yalnızca belirli aralıklar kullanılabilir. Geçerli en düşük değer 1 dakikadır. Zaman ayrıntı düzeyi değerinin yararlı olması için seçilen zaman aralığından küçük olması gerekir, aksi takdirde grafiğin tamamı için yalnızca bir değer gösterilir.
- Toplama türü : Birden çok ölçüm değerinden hesaplanan bir istatistik türü.
- Toplama : Birden çok giriş değeri alma ve bunları kullanarak toplama türü tarafından tanımlanan kurallar aracılığıyla tek bir çıkış değeri oluşturma işlemi. Örneğin, birden çok değerin ortalamasını alma.
İşlemin özeti
Ölçümler, zaman damgası ile depolanan bir dizi değerdir. Azure'da ölçümlerin çoğu Azure Ölçümleri zaman serisi veritabanında depolanır. Bir grafik çizdiğinizde, seçilen ölçümlerin değerleri veritabanından alınır ve seçilen zaman ayrıntı düzeyine (zaman dilimi olarak da bilinir) göre ayrı ayrı toplanır. Ölçüm gezgini zaman seçicisini kullanarak zaman ayrıntı düzeyinin boyutunu seçersiniz. Açık bir seçim yapmazsanız, o anda seçili olan zaman aralığına göre zaman ayrıntı düzeyi otomatik olarak seçilir. Seçildikten sonra, her ayrıntı aralığı sırasında yakalanan ölçüm değerleri toplanır ve aralık başına bir veri noktası olan grafiğe yerleştirilir.
Toplama türleri
Ölçüm gezgininde beş temel toplama türü vardır. Ölçüm gezgini, ilgili olmayan ve belirli bir metrik için kullanılamayan toplamaları gizler.
- Sum : Toplama aralığı boyunca yakalanan tüm değerlerin toplamı. Bazen Toplam toplama olarak da adlandırılır.
- Count : Toplama aralığı boyunca yakalanan ölçülerin sayısı. Sayı, ölçümün değerine değil, yalnızca kayıt sayısına bakar.
- Average : Toplama aralığı boyunca yakalanan ölçüm değerlerinin ortalaması. Çoğu ölçüm için bu değer Toplam/Sayı'dır.
- Min : Toplama aralığı boyunca yakalanan en küçük değerdir.
- Max : Toplama aralığı boyunca yakalanan en büyük değerdir.
Örneğin, bir grafiğin son 24 saatlik süre boyunca Ağ Dışarı Toplam ölçümünü TOPLAM toplama yöntemiyle bir VM için gösterdiğini varsayalım. Zaman aralığı ve ayrıntı düzeyi, aşağıdaki ekran görüntüsünde gösterildiği gibi grafiğin sağ üst kısmından değiştirilebilir.
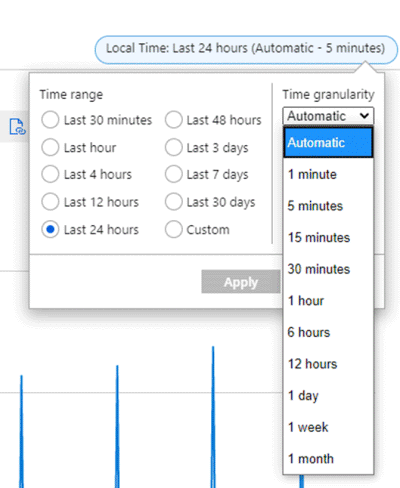
Zaman ayrıntı düzeyi = 30 dakika ve zaman aralığı = 24 saat için:
- Grafik 48 veri noktasından çizilir. Bu, saatte 24 saat x 2 veri noktası (60 dakika/30 dakika) toplam 1 dakikalık veri noktalarıdır.
- Çizgi grafik, grafik çizim alanındaki 48 noktayı bağlar.
- Her veri noktası, ilgili 30 dakikalık zaman aralıklarının her biri sırasında gönderilen tüm ağ çıkış baytlarının toplamını temsil eder.

Daha büyük sürümleri görmek için bu bölümdeki resimlere tıklayın.
Zaman ayrıntı düzeyini 15 dakikaya değiştirirseniz, grafik 96 toplanmış veri noktasından çizilir. Yani, 60 dakika/15 dakika = saatte 4 veri noktası x 24 saat.

5 dakikalık zaman ayrıntı düzeyi için 24 x (60/5) = 288 puan alırsınız.
1 dakikalık zaman ayrıntı düzeyi (grafikte mümkün olan en küçük değer) için 24 x 60/1 = 1440 puan alırsınız.

Grafikler, önceki ekran görüntülerinde gösterildiği gibi bu toplamalar için farklı görünür. Bu VM'nin zaman penceresinin geri kalanına göre küçük bir zaman aralığında nasıl çok sayıda çıkışa sahip olduğunu göreceksiniz.
Zaman ayrıntı düzeyi, grafikteki "sinyal-gürültü" oranını ayarlamanıza olanak tanır. Daha yüksek düzeyde birleştirme gürültüyü giderir ve ani artışları düzeltir. En alttaki 1 dakikalık grafikteki varyasyonlara ve siz daha yüksek ayrıntı düzeyi değerlerine gittiğinizde bunların nasıl düzgünleştirildiklerine dikkat edin.
Bu düzeltme davranışı, bu verileri diğer sistemlere (örneğin, uyarılar) gönderdiğinizde önemlidir. Genellikle CPU süresinde %90'ın üzerindeki kısa ani artışlarla uyarı almak istemezsiniz. Ancak CPU 5 dakika boyunca %90'da kalırsa bu büyük olasılıkla önemlidir. CPU 'da (veya herhangi bir ölçümde) bir uyarı kuralı ayarlarsanız, zaman ayrıntı düzeyini artırmak aldığınız hatalı uyarı sayısını azaltabilir.
İş yükünüzün en iyi zaman aralığını bilmesi için "normal" olan şeyleri belirlemeniz önemlidir. Bu, burada ele alınmayan farklı bir konu olan dinamik uyarıların avantajlarından biridir.
Sistem ölçümleri nasıl toplar?
Veri toplama metriklere göre değişir.
Uyarı
Aşağıdaki örnekler çizim için basitleştirilmiştir ve her toplamaya dahil edilen gerçek ölçüm verileri, değerlendirme gerçekleştiğinde sağlanan verilerden etkilenir.
Ölçüm toplama sıklığı
İki tür koleksiyon dönemi vardır.
Normal : Ölçüm, değişmeyen tutarlı bir zaman aralığında toplanır.
Etkinlik tabanlı - Ölçüm, belirli bir türdeki bir işlemin ne zaman gerçekleştiğine göre toplanır. Her işlemin bir ölçüm girişi ve zaman damgası vardır. Bunlar düzenli aralıklarla toplanmaz, bu nedenle belirli bir süre boyunca değişen sayıda kayıt vardır.
Granülerlik
Minimum zaman ayrıntı düzeyi 1 dakikadır, ancak temel alınan sistem ölçüme bağlı olarak verileri daha hızlı yakalayabilir. Örneğin, Azure VM'sinin CPU yüzdesi 15 saniyelik bir zaman aralığında yakalanır. HTTP hataları işlem olarak izlendiği için, genellikle dakikada birden fazla sayıya kolayca ulaşabilirler. SQL Depolama gibi diğer ölçümler her 20 dakikada bir zaman aralığında yakalanır. Bu seçim tek tek kaynak sağlayıcısına ve türüne göre yapılır. Çoğu, mümkün olan en küçük zaman aralığını sağlamaya çalışır.
Boyutlar, bölme ve filtreleme
Veriler her bir kaynak için kaydedilir. Ancak ölçümlerin toplandığı, depolandığı ve grafiklenebildiği düzey farklılık gösterebilir. Bu düzey, ölçüm boyutlarında kullanılabilen diğer ölçümlerle temsil edilir. Her kaynak sağlayıcısı, topladıkları verilerin ne kadar ayrıntılı olduğunu tanımlar. Azure İzleyici yalnızca bu tür ayrıntıların nasıl sunulması ve depolanması gerektiğini tanımlar.
Ölçüm gezgininde bir ölçüm grafiği oluştururken grafiği bir boyuta göre "bölme" seçeneğiniz vardır. Grafiği bölmek, daha fazla ayrıntı için temel alınan verileri incelediğiniz ve bu verilerin ölçüm gezgininde grafiklendiğini veya filtrelendiğini gördüğünüz anlamına gelir.
Örneğin, Microsoft.ApiManagement/service birçok ölçüm için boyut olarak Konum'a sahiptir.
Kapasite bu tür ölçümlerden biridir. Konum boyutu olduğunda temel sistem, her konumun kapasitesi için bir ölçüm kaydı depolar; bu, yalnızca toplam miktar için bir kayıt değil, her konum için ayrı ayrı kayıtlar olduğu anlamına gelir. Ardından bu bilgileri bir ölçüm grafiğinde alabilir veya bölebilirsiniz.
Ağ Geçidi İsteklerinin Genel Süresi'ne baktığınızda, tekrar iki boyut olduğunu ve bunların Konum ve Ana Bilgisayar Adı olduğunu, bir sürenin konumunu ve hangi ana bilgisayar adından geldiğini size bildirdiğini fark edeceksiniz.
Daha esnek ölçümlerden biri olan İstekler'in 7 farklı boyutu vardır.
Her ölçüm ve kullanılabilir boyutlar hakkında ayrıntılı bilgi için Azure İzleyici ile desteklenen ölçümler makalesine bakın. Ayrıca, her kaynak sağlayıcısının ve türünün belgeleri boyutlar ve ölçtükleri hakkında ek bilgi sağlayabilir.
Bir sorunu araştırmak için bölmeyi ve filtrelemeyi birlikte kullanabilirsiniz. Aşağıda, bir kaynak grubundaki bir vm grubu için Ortalama Disk Yazma Baytlarını gösteren bir grafik örneği verilmiştir. Bu ölçüme sahip tüm VM'lerden oluşan bir toplamamız var, ancak 06:00 civarındaki zirvelerden hangilerinin sorumlu olduğunu görmek isteyebiliriz. Aynı makine mi? Kaç makine söz konusu?

Daha büyük sürümleri görmek için bu bölümdeki resimlere tıklayın.
Bölme uyguladığımızda, temel alınan verileri görebiliriz, ancak bu biraz karışık bir durum. Yukarıdaki grafikte toplanmış 20 VM olduğu ortaya çıktı. Bu durumda, faremizi kullanarak 06:00'da büyük tepenin üzerinde durduk ve bu tepenin bize CH-DCVM11'in neden olduğunu gösterdiğini görüyoruz. Ancak diğer VM'lerin grafiği karmaşık hale getirmek nedeniyle bu VM ile ilişkili verilerin geri kalanını görmek zordur.

Filtrelemeyi kullanmak, gerçekte neler olduğunu görmek için grafiği temizlememize olanak tanır. Görmek istediğiniz VM'leri işaretleyebilir veya işaretini kaldırabilirsiniz. Noktalı çizgilere dikkat edin. Bunlar daha sonraki bir bölümde belirtilir.

Ölçüm gezgini grafiğinde bölünmüş boyut verilerini gösterme hakkında daha fazla bilgi için bkz. Boyut filtrelerini ve bölmeyi kullanma.
NULL ve sıfır değerleri
Sistem bir kaynaktan ölçüm verileri beklediğinde ancak bunu almadığında NULL değeri kaydeder. NULL, toplama ve grafik hesaplamasında önemli hale gelen sıfır değerinden farklıdır. NULL değerler geçerli ölçümler olarak sayılmaz.
NULL'lar farklı grafiklerde farklı şekilde gösterilir. Dağılım grafikleri, grafikte bir nokta göstermeyi ihmal eder. Çubuk grafikler çubuğun gösterimini atlar. Çizgi grafiklerde NULL, önceki bölümdeki ekran görüntüsünde gösterilenler gibi noktalı veya kesikli çizgiler olarak gösterilebilir. NULL içeren ortalamaları hesaplarken, ortalamayı alabileceğiniz veri noktaları daha azdır. Bu davranış bazen grafikteki değerlerde beklenmeyen bir düşüşe neden olabilir, ancak değerin sıfıra dönüştürülüp geçerli bir veri noktası olarak kullanılmasından daha az olabilir.
Özel ölçümler hiçbir veri alınmadığında her zaman NUL'leri kullanır. Platform ölçümleriyle her kaynak sağlayıcısı, belirli bir ölçüm için en anlamlı olan şeye göre sıfırları mı yoksa NUL'leri mi kullanacağınıza karar verir.
Azure İzleyici uyarıları, kaynak sağlayıcısının ölçüm veritabanına yazdığı değerleri kullanır, bu nedenle önce verileri görüntüleyerek kaynak sağlayıcısının NUL'leri nasıl işlediğini bilmek önemlidir.
Toplama nasıl çalışır?
Önceki sistemdeki ölçüm grafiklerinde farklı türlerde toplanmış veriler gösterilir. Sistem, istenen grafiklerin çok sayıda yinelenen hesaplama olmadan daha hızlı gösterilmesi için verileri önceden dağıtır.
Bu örnekte:
- HTTP hataları adlı kurgusal bir işlem ölçümü topluyoruz
- Sunucu , HTTP hataları ölçümü için bir boyutdur .
- Sunucu A, B ve C olmak üzere 3 sunucumuz var.
Açıklamayı basitleştirmek için yalnızca TOPLA toplama türüyle başlayacağız.
1 dakikadan kısa süreli toplama
İlk ham ölçüm verileri toplanır ve Azure İzleyici ölçüm veritabanında depolanır. Bu durumda, Sunucu bir boyut olduğundan, her sunucunun zaman damgasıyla depolanan işlem kayıtları vardır. Müşteri olarak görüntüleyebileceğiniz en küçük zaman aralığının 1 dakika olduğu düşünüldüğünde, bu zaman damgaları her bir sunucu için ilk olarak 1 dakikalık ölçüm değerlerine toplanır. Sunucu B için toplama işlemi aşağıdaki grafikte gösterilmiştir. A ve C sunucuları aynı şekilde yapılır ve farklı verilere sahiptir.
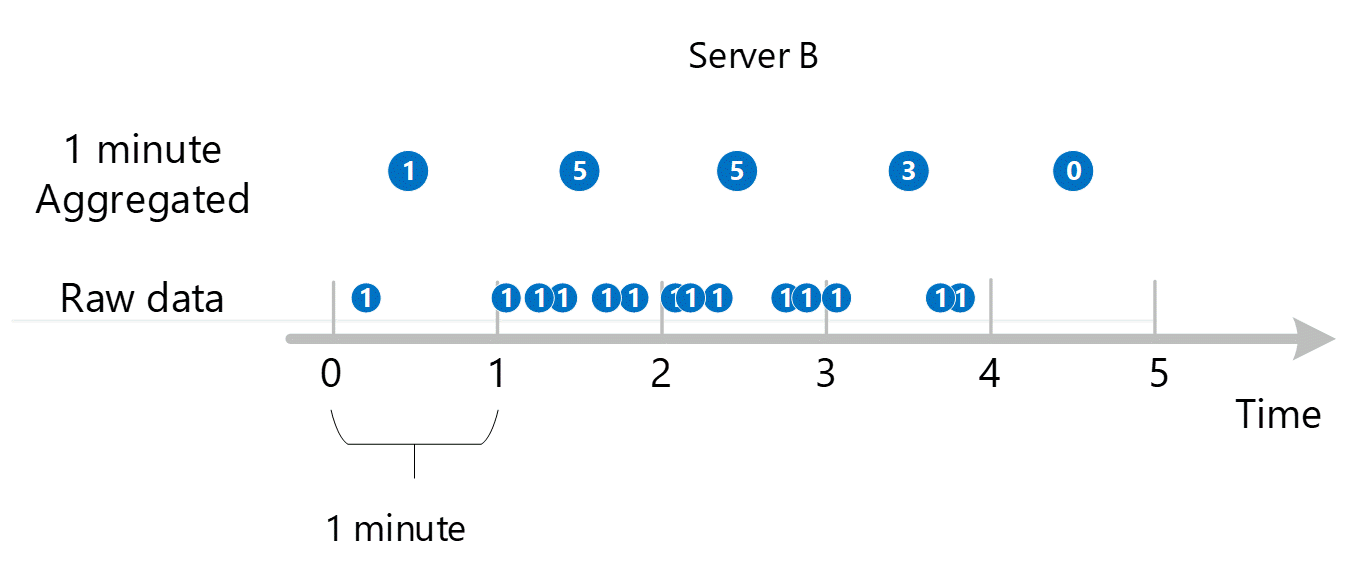
Elde edilen 1 dakikalık toplu değerler ölçüm veritabanında yeni girdiler olarak depolanır, böylece daha sonraki hesaplamalar için toplanabilirler.
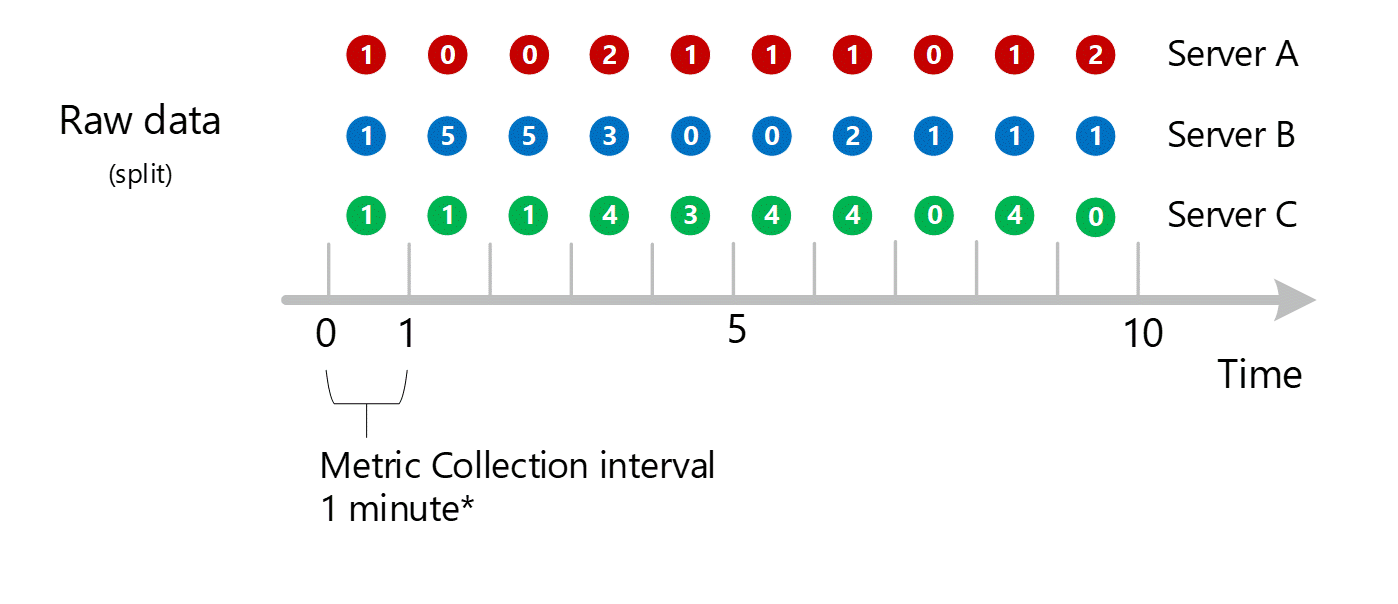
Boyut birleştirme
1 dakikalık hesaplamalar boyuta göre daraltılır ve yine tek tek kayıtlar olarak depolanır. Bu durumda, tek tek tüm sunuculardaki tüm veriler 1 dakikalık aralık ölçümünde toplanır ve sonraki toplamalarda kullanılmak üzere ölçüm veritabanında depolanır.
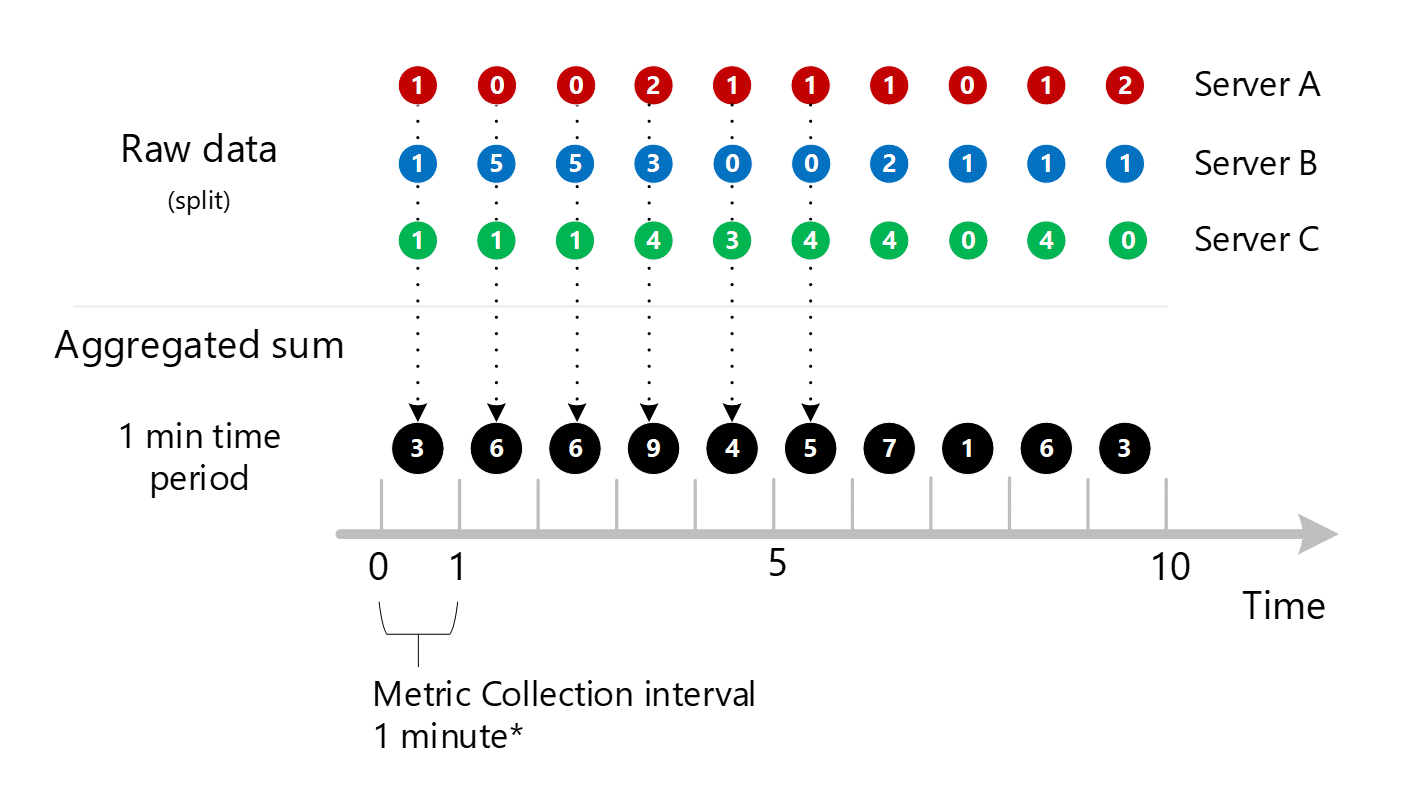
Netlik sağlamak için aşağıdaki tabloda toplama yöntemi gösterilmektedir.
| Dönem | Sunucu A | Sunucu B | Sunucu C | Toplam (A+B+C) |
|---|---|---|---|---|
| Dakika 1 | 1 | 1 | 1 | 3 |
| Dakika 2 | 0 | 5 | 1 | 6 |
| Dakika 3 | 0 | 5 | 1 | 6 |
| Dakika 4 | 2 | 3 | 4 | 9 |
| Dakika 5 | 1 | 0 | 3 | 4 |
| Dakika 6 | 1 | 0 | 4 | 5 |
| Dakika 7 | 1 | 2 | 4 | 7 |
| Dakika 8 | 0 | 1 | 0 | 1 |
| Dakika 9 | 1 | 1 | 4 | 6 |
| Dakika 10 | 2 | 1 | 0 | 3 |
Yukarıda yalnızca bir boyut gösterilir, ancak bu toplama ve depolama işlemi bir ölçümün desteklediği tüm boyutlar için gerçekleşir.
- Değerleri bu boyuta göre 1 dakikalık toplu kümede toplayın. Bu değerleri depolayın.
- Boyutu 1 dakikalık toplanmış bir toplam haline getir. Bu değerleri depolayın.
Şimdi HTTP hatalarının NetworkAdapter adlı başka bir boyutunu tanıtalım. Sunucu başına farklı sayıda bağdaştırıcımız olduğunu farz edelim.
- Sunucu A'nın 1 bağdaştırıcısı var
- Sunucu B'de 2 bağdaştırıcı var
- Sunucu C'de 3 bağdaştırıcı var
Aşağıdaki işlemler için ayrı ayrı veri toplarız. Bunlar şu şekilde işaretlenir:
- Bir an
- Bir değer
- İşlemin geldiği sunucu
- İşlemin geldiği adaptör
Bu alt akışlardan her biri 1 dakikalık zaman serisi değerlerine toplanır ve Azure İzleyici ölçüm veritabanında depolanır:
- Sunucu A, Bağdaştırıcı 1
- Sunucu B, Bağdaştırıcı 1
- Sunucu B, Bağdaştırıcı 2
- Sunucu C, Bağdaştırıcı 1
- Sunucu C, Bağdaştırıcı 2
- Sunucu C, Bağdaştırıcı 3
Ayrıca aşağıdaki çökertilmiş toplamalar da depolanacaktır.
- Sunucu A, Bağdaştırıcı 1 (daraltılacak bir şey olmadığından, yeniden depolanacaktır)
- Sunucu B, Bağdaştırıcı 1+2
- Sunucu C, Bağdaştırıcı 1+2+3
- Sunucular TÜMÜ, BağdaştırıcıLAR TÜMÜ
Bu, çok sayıda boyuta sahip ölçümlerin daha fazla sayıda toplamaya sahip olduğunu gösterir. Tüm permütasyonları bilmek önemli değil, sadece mantığı anlamak. Sistem, tek tek verilerin ve toplanan verilerin herhangi bir grafikte erişim için hızlı bir şekilde alınması için depolanmasını istiyor. Sistem, görüntülemeyi seçtiğiniz değere bağlı olarak en uygun depolanmış toplamayı veya temel alınan ham verileri seçer.
Boyut içermeyen toplama
Bu ölçümün boyut Sunucusu olduğundan, bu makalenin önceki bölümlerinde açıklandığı gibi bölme ve filtreleme yoluyla yukarıdaki A, B ve C sunucusu için temel alınan verilere ulaşabilirsiniz. Ölçümün Sunucu boyutu yoksa, müşteri olarak yalnızca diyagramda siyah olarak gösterilen 1 dakikalık toplamları erişebilirsiniz. Yani, 3, 6, 6, 9 vb. değerler. Sistem ayrıca hiçbir zaman kullanmayacağı bölünmüş değerleri toplamak için arka plandaki işi yapmaz, bunları ölçüm gezgini veya REST API'si aracılığıyla göndermeyecektir.
1 dakikanın üzerindeki zaman ayrıntı düzeylerini görüntüleme
Daha büyük bir ayrıntı düzeyinde ölçümler isterseniz, sistem daha büyük zaman taneciklerinin toplamlarını hesaplamak için 1 dakikalık toplamları kullanır. Aşağıda noktalı çizgiler 2 dakikalık ve 5 dakikalık zaman ayrıntı düzeyleri için toplama yöntemini gösterir. Yine basitlik için yalnızca TOPLA toplama türünü gösteriyoruz.
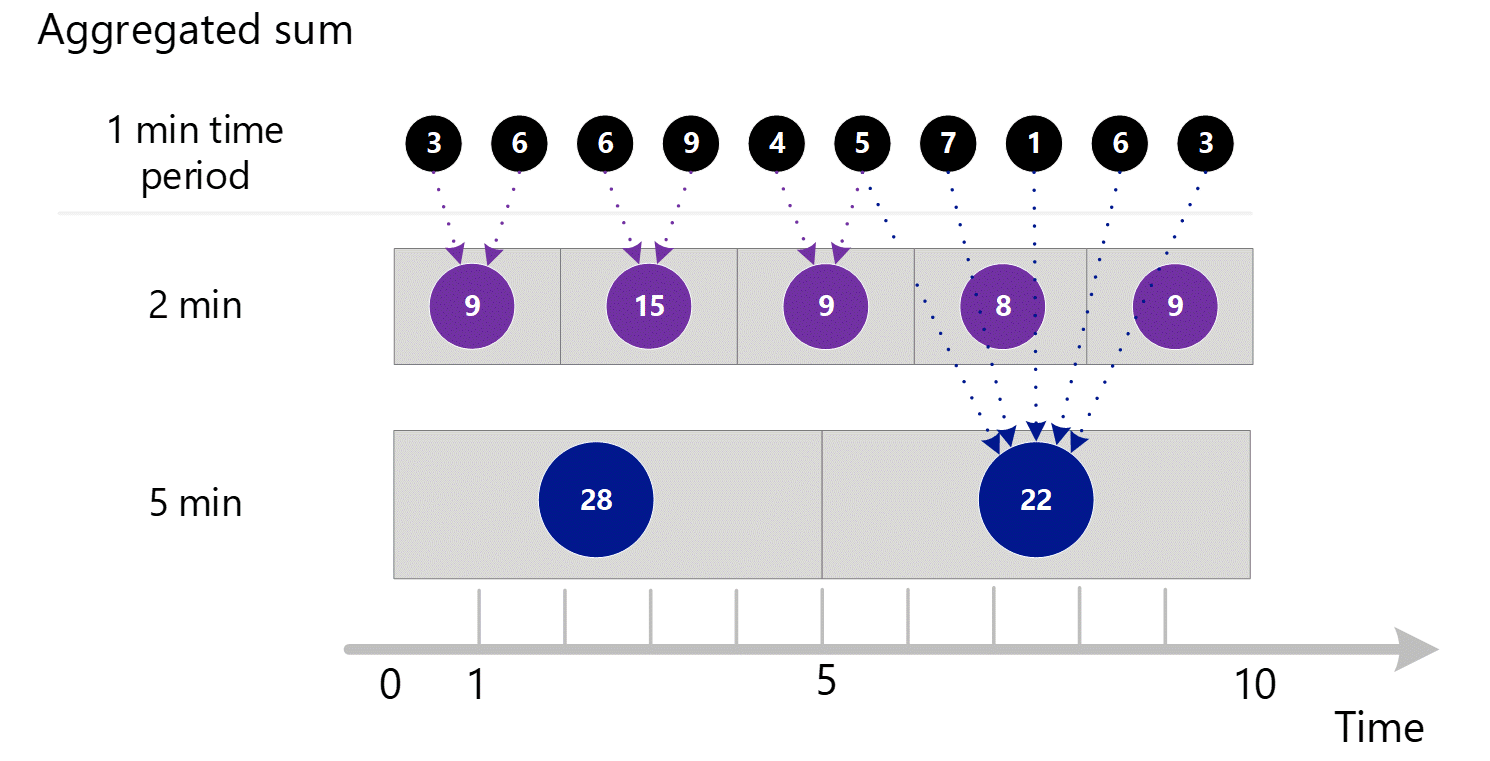
2 dakikalık zaman ayrıntı düzeyi için.
| Dönem | Toplamlar |
|---|---|
| Dakika 1 ve 2 | (3 + 6) = 9 |
| Dakika 3 ve 4 | (6 + 9) = 15 |
| Dakika 4 & 5 | (4 + 5) = 9 |
| Dakika 6 ve 7 | (7 + 1) = 8 |
| Dakika 8 ve 9 | (6 + 3) = 9 |
5 dakikalık zaman ayrıntı düzeyi için.
| Dönem | Toplamlar |
|---|---|
| Dakika 1 ile 5 arasında | 3 + 6 + 6 + 9 + 4 = 28 |
| Dakika 6 ile 10 arasında | 5 + 7 + 1 + 6 + 3 = 22 |
Sistem, en iyi performansı veren depolanan toplanmış verileri kullanır.
Yukarıdaki 1 dakikalık toplama işlemi için daha büyük diyagram aşağıdadır ve okunabilirliği artırmak için bazı oklar dışarıda bırakılır.
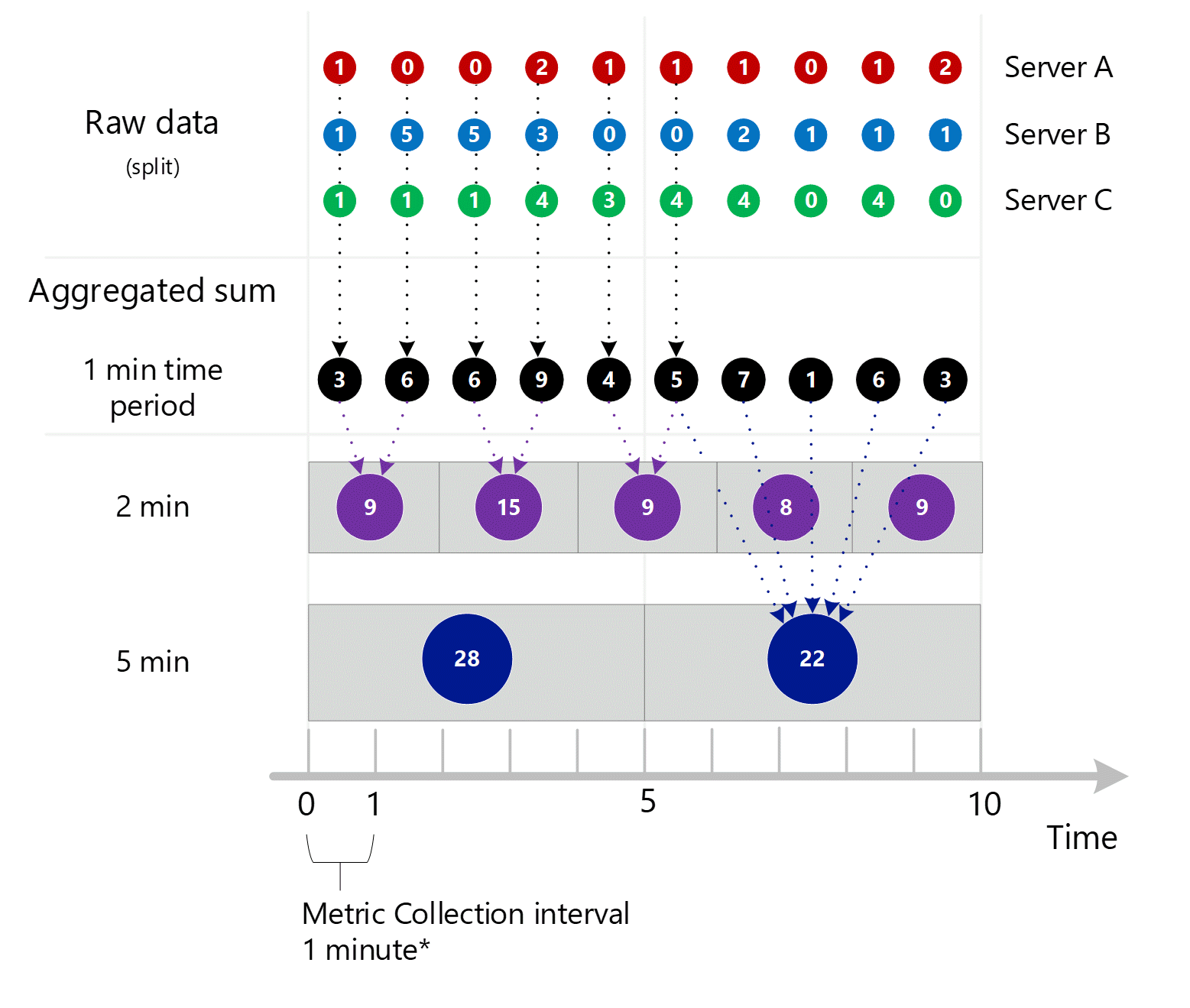
Daha karmaşık bir örnek
Aşağıda, milisaniye cinsinden HTTP Yanıt süresi adlı kurgusal bir ölçümün değerlerinin kullanıldığı daha büyük bir örnek verilmiştir. Burada diğer karmaşıklık düzeylerini tanıtacağız.
- Sum, Count, Min ve Max için toplama ve Ortalama hesaplamasını gösteririz.
- NULL değerleri ve bunların hesaplamaları nasıl etkilediğini gösteririz.
Aşağıdaki örneği göz önünde bulundurun. Kutular ve oklar, değerlerin nasıl toplanıp hesaplandıklarına ilişkin örnekler gösterir.
Önceki bölümde açıklanan 1 dakikalık ön toplama işlemi Sums, Count, Minimum ve Maximum için gerçekleşir. Ancak, Ortalama önceden toplanmamıştır. Hesaplama hatalarını önlemek için toplanan veriler kullanılarak yeniden hesaplanır.

Yukarıda vurgulandığı gibi 1 dakikalık toplama için 6. dakikayı göz önünde bulundurun. Bu dakika, Sunucu B'nin çevrimdışı olduğu ve muhtemelen bir yeniden başlatma nedeniyle verileri raporlamayı durdurduğu noktadır.
Yukarıdaki Dakika 6'dan hesaplanan 1 dakikalık toplama türleri şunlardır:
| Toplama türü | Değer | Notlar |
|---|---|---|
| Toplam | 53+20=73 | |
| Sayı | 2 | NULL'lerin etkisini gösterir. Sunucu çevrimiçi olsaydı değer 3 olurdu. |
| Asgari | 20 | |
| Maksimum | 53 | |
| Ortalama | 73 / 2 | Her zaman Toplam, Sayı'ya bölünür. Asla depolanmaz ve her zaman bu ayrıntı düzeyi için toplanan sayılar kullanılarak yeniden hesaplanır. Yukarıda vurgulandığı gibi 5 dakikalık ve 10 dakikalık zaman ayrıntı düzeyi için yeniden hesaplamaya dikkat edin. |
Kırmızı metin rengi, normal aralığın dışında kabul edilebilecek değerleri gösterir ve zaman ayrıntı düzeyi büyüdükçe bunların nasıl yayıldığını (veya başarısız olduğunu) gösterir. Zaman ayrıntı düzeyiniz arttıkça, Min ve Max değerlerinin altında yatan anomalileri gösterdiğini, ancak Ortalama ve Toplamlar'ın bu bilgileri kaybettiğini unutmayın.
AYRıCA, NULL'lerin bunun yerine sıfırların kullanılmasından daha iyi bir ortalama hesaplaması sunduğunu da görebilirsiniz.
Uyarı
Bu örnekte böyle olmasa da, bir ölçümün her zaman 1 değeriyle yakalandığı durumlarda Sayı, Toplam'a eşittir. Bu durum, ölçüm işlem olayının oluşumunu izlediğinde (örneğin, bu makalede önceki bir örnekte belirtilen HTTP hatalarının sayısı) sık karşılaşılan bir durumdur.