Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Azure NetApp Files birimindeki birim dili (istemci işletim sistemlerindeki sistem yerel ayarlarına göre) NFS ve SMB protokolleri kullanılırken desteklenen dilleri ve karakter kümelerini denetler. Azure NetApp Files, karakter kümeleri için POSIX uyumlu UTF-8 kodlaması sağlayan C.UTF-8'in varsayılan birim dilini kullanır. C.UTF-8 dili, Temel Çok Dilli Düzlemde (BMP) (Japonca, Almanca ve İbranice ve Kiril'in çoğu dahil) dünya dillerinin çoğunluğunu içeren 0-3 bayt boyutunda karakterleri yerel olarak destekler. BMP hakkında daha fazla bilgi için bkz. Unicode.
BMP dışındaki karakterler bazen Azure NetApp Files tarafından desteklenen 3 bayt boyutu aşıyor. Bu nedenle, yeni karakterler oluşturmak için birden çok karakter bayt kümesinin birleştirildiği vekil çift mantığını kullanmaları gerekir. Örneğin emoji sembolleri bu kategoriye girer ve UTF-8'in zorunlu tutulmadığı senaryolarda Azure NetApp Files'da desteklenir: UTF-16 kodlaması kullanan Windows istemcileri veya UTF-8'i zorlamayan NFSv3 gibi. NFSv4.x, UTF-8'i zorlayarak vekil çift karakterlerin NFSv4.x kullanılırken düzgün görüntülenmemesine neden olur.
Shift-JIS ve daha az yaygın CJK karakterleri gibi standart olmayan kodlama, Azure NetApp Files'da UTF-8 uygulandığında da düzgün görüntülenmez.
Tavsiye
Karakterlerin düzgün çevrilememesi ve bu durumların dosya oluşturma/yeniden adlandırma veya kopyalama hata senaryolarına neden olabileceği durumlardan kaçınmak için UTF-8 kullanarak metin gönderip almanız gerekir.
Birim dil ayarları şu anda Azure NetApp Files'da değiştirilemez. Daha fazla bilgi için bkz . Özel karakter kümeleriyle protokol davranışları.
En iyi yöntemler için bkz. Karakter kümesi en iyi yöntemleri.
Azure NetApp Files NFS ve SMB birimlerinde karakter kodlaması
Azure NetApp Files dosya paylaşımı ortamında, dosya ve klasör adları son kullanıcıların okuyup yorumladığı bir dizi karakterle temsil edilir. Bu karakterlerin görüntülenme şekli, istemcinin bu karakterlerin kodlamasını nasıl gönderip aldığına bağlıdır. Örneğin, bir istemci erişirken Azure NetApp Files birimine eski Amerikan Bilgi Değişimi için Standart Kod (ASCII) kodlaması gönderiyorsa, yalnızca ASCII biçiminde desteklenen karakterleri görüntülemekle sınırlıdır.
Örneğin, verilerin Japonca karakteri 資 şeklindedir. Bu karakter ASCII'de temsil edilemediğinden, ASCII kodlaması kullanan bir istemcide "?" gösterilir. yerine 資.
ASCII yalnızca 95 yazdırılabilir karakteri destekler. Bu karakter, İngilizce dilinde bulunan karakterlerdir. Bu karakterlerin her biri, Bir Azure NetApp Files birimindeki toplam dosya yolu uzunluğuna hesaba katılmış olan 1 bayt kullanır. Dosya adları Japonca'dan Kiril'e ve emojiye kadar ASCII tarafından tanınmayan çeşitli karakterlere sahip olabileceğinden bu, veri kümelerinin uluslararasılaştırılmasını sınırlar. Uluslararası bir standart (ISO/IEC 8859) daha fazla uluslararası karakteri desteklemeye çalıştı, ancak sınırlamaları da vardı. Modern istemcilerin çoğu, bir tür Unicode kullanarak karakter gönderir ve alır.
Unicode
ASCII ve ISO/IEC 8859 kodlamalarının sınırlamalarının bir sonucu olarak, herkesin kendi ana bölgesinin dilini cihazlarından görüntüleyebilmesi için Unicode standardı oluşturulmuştur.
- Unicode, ASCII gibi eski kodlamaların aksine hem izin verilen karakter başına bayt sayısını (en çok 4 bayt) hem de dosya yolunda izin verilen toplam bayt sayısını artırarak bir milyondan fazla karakter kümesini destekler.
- Unicode, ASCII için ilk 128 karakteri ayırarak geriye dönük uyumluluğu desteklerken, ayrıca ilk 256 kod noktası ISO/IEC 8859 standartlarıyla aynı olduğundan emin olur.
- Unicode standardında karakter kümeleri düzlemlere ayrılır. Düzlem, 65.536 kod noktasından oluşan sürekli bir grupdur. Toplamda Unicode standardında 17 düzlem (0-16) vardır. UTF-16 sınırlamaları nedeniyle sınır 17'dir.
- Düzlem 0, Temel Çok Dilli Düzlemdir (BMP). Bu düzlem, birden çok dilde en yaygın kullanılan karakterleri içerir.
- 17 düzlemden yalnızca beşi Unicode sürüm 15.1 itibarıyla karakter kümelerine atanmış durumda.
- Düzlemler 1-17 Ek Çok Dilli Düzlemler (SMP) olarak bilinir ve daha az kullanılan karakter kümeleri içerir, örneğin cuneiform ve hiyeroglifler gibi eski yazı sistemlerinin yanı sıra özel Çince/Japonca/Korece (CJK) karakterleri içerir.
- Karakter uzunluklarını ve yol boyutlarını görme ve bir sisteme gönderilen kodlamayı denetleme yöntemleri için bkz. Dosyaları farklı kodlamalara dönüştürme.
Unicode, standart olarak Unicode Dönüştürme Biçimi kullanır; UTF-8 ve UTF-16 iki ana biçimdir.
Unicode düzlemleri
Unicode, 65.536 karakterlik 17 düzlemden (256 kod noktası düzlemde 256 kutuyla çarpılır) ve Temel Çok Dilli Düzlem (BMP) olarak Düzlem 0'ı kullanır. Bu düzlem, birden çok dilde en yaygın kullanılan karakterleri içerir. Dünyanın dilleri ve karakter kümeleri 65536 karakteri aştığından, daha az kullanılan karakter kümelerini desteklemek için daha fazla düzlem gerekir.
Örneğin, Düzlem 1 (Ek Çok Dilli Düzlemler (SMP)), çivi yazısı ve Mısır hiyeroglifleri gibi tarihi yazı sistemlerinin yanı sıra bazı Osage, Warang Citi, Adlam, Wancho ve Toto alfabelerini içerir. Düzlem 1 ayrıca bazı semboller ve emotikon karakterleri içerir.
Düzlem 2 – Tamamlayıcı İdeografik Düzlem (SIP) – Çince/Japonca/Korece (CJK) Birleşik İdeograflar içerir. 1 ve 2. düzlemlerdeki karakterler genellikle 4 bayt boyutundadır.
Örneğin:
- Düzlem 1'deki "büyük gözlü sırıtan yüz" ifadesi😃 4 bayt boyutundadır.
- 1. düzlemdeki Mısır hiyeroglifi "𓀀" 4 bayt boyutundadır.
- 1. düzlemdeki Osage karakteri "𐒸" boyutu 4 bayttır.
- 2. düzlemdeki CJK karakteri "𫝁" boyutu 4 bayttır.
Bu karakterlerin tümü >3 bayt boyutunda olduğundan, düzgün çalışması için vekil çiftlerin kullanılmasını gerektirir. Azure NetApp Files yedek çiftleri yerel olarak destekler, ancak karakterlerin görüntülenmesi kullanımdaki protokole, istemcinin yerel ayar ayarlarına ve uzak istemci erişim uygulamasının ayarlarına bağlı olarak değişir.
UTF-8
UTF-8, 8 bit kodlama kullanır ve en çok 1.112.064 kod noktasına (veya karaktere) sahip olabilir. UTF-8, Linux tabanlı işletim sistemlerindeki tüm dillerde standart kodlamadır. UTF-8 8 bit kodlama kullandığından, mümkün olan en fazla işaretsiz tamsayı 255 'tir (2^8 – 1), bu da bu kodlama için en fazla dosya adı uzunluğudur. UTF-8, İnternet'te 98%'den fazla sayfada kullanıldığından, açık arayla en çok benimsenen kodlama standardı haline gelir. Web Köprü Metni Uygulama Teknolojisi Çalışma Grubu (WHATWG), UTF-8'i "tüm [metinler] için zorunlu kodlama" olarak kabul eder ve güvenlik nedeniyle tarayıcı uygulamalarının UTF-16 kullanmaması gerekir.
UTF-8 biçimindeki karakterlerin her birinde 1 ila 4 bayt kullanılır, ancak tüm dillerdeki karakterlerin neredeyse tümü 1 ile 3 bayt arasında kullanır. Örneğin:
- Latin alfabesinde "A" harfi 1 bayt kullanır. (128 ayrılmış ASCII karakterden biri)
- "©" telif hakkı simgesi 2 bayt kullanır.
- "ä" karakteri 2 bayt kullanır. ("a" için 1 bayt + umlaut için 1 bayt)
- Veriler için Japonca Kanji simgesi (資) 3 bayt kullanır.
- Sırıtan yüz emojisi (😃) 4 bayt kullanır.
Dil yerel ayarları, bilgisayar standart UTF-8 (C.UTF-8) veya en_US gibi daha bölgeye özgü bir biçim kullanabilir. UTF-8, ja. UTF-8 vb. Mümkün olduğunda Azure NetApp Files'a erişirken Linux istemcileri için UTF-8 kodlaması kullanmalısınız. OS X'den itibaren macOS istemcileri de varsayılan kodlama olarak UTF-8'i kullanır ve ayarlanmamalıdır.
Windows istemcileri UTF-16 kullanır. Çoğu durumda, bu ayar işletim sistemi yerel ayarı için varsayılan olarak bırakılmalıdır, ancak daha yeni istemciler onay kutusu aracılığıyla UTF-8 karakterleri için beta desteği sunar. Windows'daki terminal istemcileri gerektiğinde PowerShell veya CMD'de UTF-8 kullanacak şekilde de ayarlanabilir. Daha fazla bilgi için bkz. Özel karakter kümeleriyle çift protokol davranışları.
UTF-16
UTF-16, 16 bit kodlama kullanır ve Unicode'un 1.112.064 kod noktalarının tümünü kodlama özelliğine sahiptir. UTF-16 kodlaması, her biri 2 bayt boyutunda bir veya iki 16 bit kod birimi kullanabilir. UTF-16'daki tüm karakterler 2 veya 4 baytlık boyutları kullanır. UTF-16'da 4 bayt kullanan karakterler, yeni bir karakter oluşturmak için iki ayrı 2 baytlık karakteri birleştiren vekil çiftlerden yararlanıyor. Bu tamamlayıcı karakterler standart BMP düzleminin dışında olup diğer çok dilli düzlemlerden birine düşer.
UTF-16, Windows işletim sistemlerinde ve API'lerde, Java'da ve JavaScript'te kullanılır. ASCII biçimleriyle geriye dönük uyumluluğu desteklemediğinden web'de hiçbir zaman popülerlik kazanmadı. UTF-16, internet üzerindeki tüm sayfaların yalnızca 0,002% oluşur. Web Köprü Metni Uygulama Teknolojisi Çalışma Grubu (WHATWG), UTF-8'i "tüm metinler için zorunlu kodlama" olarak kabul eder ve uygulamaların tarayıcı güvenliği için UTF-16 kullanmamalarını önerir.
Azure NetApp Files, vekil çiftler de dahil olmak üzere çoğu UTF-16 karakterini destekler. Karakterin desteklenmediği durumlarda, Windows istemcileri "belirttiğiniz dosya adı geçerli değil veya çok uzun" hatasını bildirir.
Uzak istemciler üzerinde karakter kümesi işleme
Azure NetApp Files birimlerini (NFS bağlamalarına erişmek için Linux istemcilerine SSH bağlantıları gibi) takan istemcilere yönelik uzak bağlantılar, belirli birim dili kodlamalarını gönderecek ve alacak şekilde yapılandırılabilir. Uzak bağlantı yardımcı programı aracılığıyla istemciye gönderilen dil kodlaması, karakter kümelerinin nasıl oluşturulup görüntülendiğini denetler. Sonuç olarak, başka bir uzak bağlantıdan (iki farklı PuTTY penceresi gibi) farklı bir dil kodlaması kullanan uzak bağlantı, Azure NetApp Files biriminde dosya ve klasör adlarını listelerken karakterler için farklı sonuçlar gösterebilir. Çoğu durumda, bu tutarsızlıklar oluşturmaz (Örneğin, Latin/İngilizce karakterler için), ancak emojiler gibi özel karakterler söz konusu olduğunda sonuçlar farklılık gösterebilir.
Örneğin, uzak bağlantı için UTF-8 kodlaması kullanıldığında, C.UTF-8 birim dili olduğundan Azure NetApp Files birimlerindeki karakterler için tahmin edilebilir sonuçlar gösterilir. "Data" (資) için Japonca karakter, terminal tarafından gönderilen kodlamaya bağlı olarak farklı şekilde görüntülenir.
PuTTY'de karakter kodlama
PuTTY penceresinde UTF-8 kullanıldığında (Windows'un çeviri ayarlarında bulunur), karakter Azure NetApp Files'da NFSv3'e bağlı bir birim için düzgün bir şekilde gösterilir:

PuTTY penceresi ISO-8859-1:1998 (Latin-1, Batı Avrupa) gibi farklı bir kodlama kullanıyorsa, dosya adı aynı olsa bile aynı karakter farklı görüntülenir.

PuTTY varsayılan olarak CJK kodlamaları içermez. Bu dil kümelerini PuTTY'ye eklemek için kullanılabilen düzeltme ekleri vardır.
Bastion'da karakter kodlamaları
Microsoft Azure, Azure'daki sanal makinelere (VM) uzaktan bağlantı için Bastion kullanılmasını önerir. Bastion kullanılırken, gönderilen ve alınan dil kodlaması yapılandırmada gösterilmez, ancak standart UTF-8 kodlamasını kullanır. Sonuç olarak, puTTY'de UTF-8 kullanılarak görülen karakter kümelerinin çoğu, kullanılan protokolde karakter kümelerinin desteklenmesi koşuluyla Bastion'da da görünür olmalıdır.

Tavsiye
TeraTerm gibi diğer SSH terminalleri kullanılabilir. TeraTerm, CJK kodlamaları ve Shift-JIS gibi standart olmayan kodlamalar dahil olmak üzere varsayılan olarak desteklenen daha geniş bir karakter kümesi aralığı sağlar.
Özel karakter kümeleriyle protokol davranışları
Azure NetApp Files birimleri UTF-8 kodlaması kullanır ve 3 bayt'ı geçmeyen karakterleri yerel olarak destekler. ASCII ve UTF-8 kümesindeki tüm karakterler, 1 ila 3 bayt aralığında olduklarından düzgün görüntülenir. Örneğin:
- Latin alfabesi karakteri "A" 1 bayt (128 ayrılmış ASCII karakterden biri) kullanır.
- Telif hakkı simgesi © 2 bayt kullanır.
- "ä" karakteri 2 bayt ("a" için 1 bayt ve umlaut için 1 bayt) kullanır.
- Veriler için Japonca Kanji simgesi (資) 3 bayt kullanır.
Azure NetApp Files, istemci kodlaması ve protokol sürümünün bunları desteklemesi koşuluyla vekil çift mantığı (emoji gibi) aracılığıyla 3 bayt'ı aşan bazı karakterleri de destekler. Protokol davranışları hakkında daha fazla bilgi için bkz:
SMB davranışları
SMB birimlerinde, Azure NetApp Files bir SMB istemcisinden erişimi olan herhangi bir dizindeki dosyalar veya dizinler için iki ad oluşturur ve korur: özgün uzun ad ve 8,3 biçiminde bir ad.
Azure NetApp Files ile SMB'deki dosya adları
Dosya veya dizin adları izin verilen karakter baytlarını aştığında veya desteklenmeyen karakterler kullandığında, Azure NetApp Files aşağıdaki gibi 8,3 biçimli bir ad oluşturur:
- Özgün dosya veya dizin adını kesilir.
- Kesildikten sonra artık benzersiz olmayan dosya veya dizin adlarına bir tilde (~) ve bir sayı (1-5) ekler. Adsız adlara sahip beşten fazla dosya varsa, Azure NetApp Files özgün adla ilişkisi olmayan benzersiz bir ad oluşturur. Azure NetApp Files, dosyalar için dosya adı uzantısını üç karaktere kısaltıyor.
Örneğin, bir NFS istemcisi adlı specifications.htmlbir dosya oluşturursa, Azure NetApp Files dosya adını specif~1.htm 8.3 biçiminden sonra oluşturur. Bu ad zaten varsa, Azure NetApp Files dosya adının sonunda farklı bir sayı kullanır. Örneğin, bir NFS istemcisi daha sonra adlı specifications\_new.htmlbaşka bir dosya oluşturursa, 8,3 biçimi specifications\_new.html olur specif~2.htm.
Azure NetApp Files ile SMB'de özel karakter
Azure NetApp Files birimleriyle SMB kullanılırken, vekil çift desteği nedeniyle dosya ve klasör adlarında (ifadeler dahil) kullanılan 3 bayt'ı aşan karakterlere izin verilir. Windows Gezgini, varsayılan UTF-16 kodlamasıyla İngilizce kullanırken bir Windows istemcisinden oluşturulan bir klasördeki BMP dışındaki karakterler için aşağıdakileri görür.
Uyarı
Windows Gezgini'nde varsayılan yazı tipi Segoe UI'dır. Yazı tipi değişiklikleri bazı karakterlerin istemcilerde nasıl görüntüleneceğini etkileyebilir.

karakterlerin istemcide nasıl görüntüleneceği, sistem yazı tipine ve dil ve yerel ayar ayarlarına bağlıdır. Genel olarak BMP'ye giren karakterler, kodlama UTF-8 veya UTF-16 olmasına bakılmaksızın tüm protokollerde desteklenir.
CMD veya PowerShell kullanırken, karakter kümesi görüntüsü yazı tipi ayarlarına bağlıdır. Bu yardımcı programlar varsayılan olarak sınırlı yazı tipi seçeneklerine sahiptir. CMD, varsayılan yazı tipi olarak Consolas kullanır.
Bazı konsollar Segoe UI'yi veya özel karakterleri düzgün işleyen diğer yazı tiplerini yerel olarak desteklemediğinden dosya adları, kullanılan yazı tipine bağlı olarak beklendiği gibi görüntülenmeyebilir.
Bu sorun, Daha sağlam yazı tipi desteği sağlayan PowerShell ISE kullanılarak Windows istemcilerinde giderilebilir. Örneğin, PowerShell ISE'yi Segoe UI olarak ayarlamak, desteklenen karakterlerle dosya adlarını düzgün bir şekilde görüntüler.

Ancak PowerShell ISE, paylaşımları yönetmek yerine betik oluşturma için tasarlanmıştır. Daha yeni Windows sürümleri, yazı tipleri ve kodlama değerleri üzerinde denetim sağlayan Windows Terminali'ni sunar.
Uyarı
Terminalin chcp kodlamasını görüntülemek için komutunu kullanın. Kod sayfalarının tam listesi için bkz. Kod sayfası tanımlayıcıları.

Birim çift protokol (hem NFS hem de SMB) için etkinleştirildiyse, farklı davranışlar gözlemleyebilirsiniz. Daha fazla bilgi için bkz. Özel karakter kümeleriyle çift protokol davranışları.
NFS davranışları
NFS'nin özel karakterleri nasıl görüntülediği kullanılan NFS sürümüne, istemcinin yerel ayar ayarlarına, yüklü yazı tiplerine ve kullanılan uzak bağlantı istemcisinin ayarlarına bağlıdır. Örneğin, Ubuntu istemcisine erişmek için Bastion kullanıldığında karakter biçimlendirmeleri, aynı VM'de farklı bir yerel ayara ayarlanmış olan PuTTY istemcisine göre farklı şekilde ele alınır. NFS örnekleri, Ubuntu VM için şu yerel ayar ayarlarını kullanır:
~$ locale
LANG=C.UTF-8
LANGUAGE=
LC\_CTYPE="C.UTF-8"
LC\_NUMERIC="C.UTF-8"
LC\_TIME="C.UTF-8"
LC\_COLLATE="C.UTF-8"
LC\_MONETARY="C.UTF-8"
LC\_MESSAGES="C.UTF-8"
LC\_PAPER="C.UTF-8"
LC\_NAME="C.UTF-8"
LC\_ADDRESS="C.UTF-8"
LC\_TELEPHONE="C.UTF-8"
LC\_MEASUREMENT="C.UTF-8"
LC\_IDENTIFICATION="C.UTF-8"
LC\_ALL=
NFSv3 davranışı
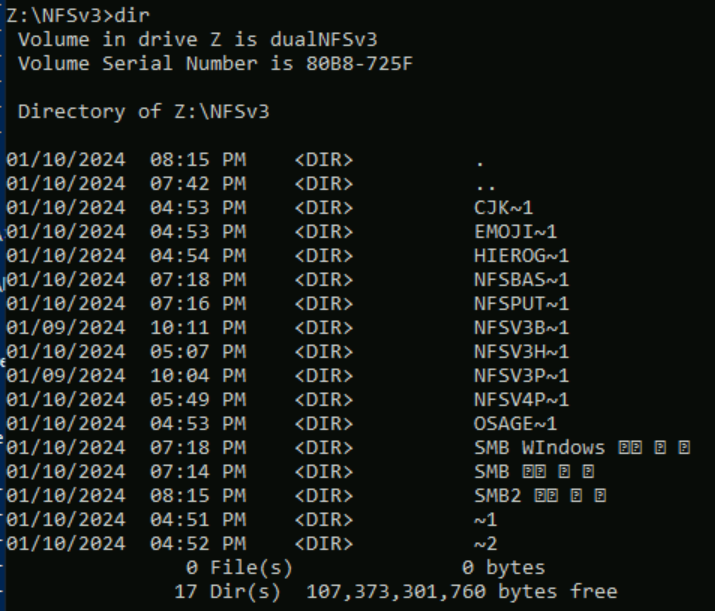
NFSv3, dosya ve klasörlerde UTF kodlaması uygulamaz. Çoğu durumda, özel karakter kümelerinde sorun olmamalıdır. Ancak, kullanılan bağlantı istemcisi karakterlerin gönderilme ve alınma şeklini etkileyebilir. Örneğin, Azure bağlantı istemcisi Bastion'da bir klasör adı için BMP'nin dışındaki Unicode karakterleri kullanmak, istemci kodlamasının çalışma biçiminden dolayı beklenmeyen davranışlara neden olabilir.
Aşağıdaki ekran görüntüsünde Bastion, NFSv3 üzerinden bir dizini adlandırırken değerleri tarayıcının dışından CLI istemine kopyalayıp yapıştıramıyor. değerini NFSv3Bastion𓀀𫝁😃𐒸kopyalayıp yapıştırmaya çalışırken, özel karakterler girişte tırnak işaretleri olarak görüntülenir.

Kopyala-yapıştır komutuna NFSv3 üzerinden izin verilir, ancak karakterler sayısal değerleri olarak oluşturulur ve bu da ekranlarını etkiler:
NFSv3Bastion'$'\262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355
Bu görüntü, Bastion tarafından kopyalama ve yapıştırma sırasında metin değerleri göndermek için kullanılan kodlamadan kaynaklanır.
PuTTY kullanarak NFSv3 üzerinde aynı karakterlere sahip bir klasör oluştururken, klasör adı Bastion'da, Bastion'ın bunu oluşturmak için kullanıldığından farklı bir şekilde kullanılır. İfade, yüklü yazı tipleri ve yerel ayar nedeniyle beklendiği gibi görünüyor, ancak diğer karakterler (örneğin, Osage '𐒸') görünmüyor.

PuTTY penceresinde karakterler doğru şekilde görüntülenir:

NFSv4.x davranışı
NFSv4.x, RFC-8881 uluslararasılaştırma belirtimlerine göre dosya ve klasör adlarında UTF-8 kodlamasını zorlar.
Sonuç olarak, UTF-8 olmayan kodlama ile özel bir karakter gönderilirse, NFSv4.x değere izin vermeyebilir.
Bazı durumlarda, bir komutun Temel Çok Dilli Düzlem (BMP) dışında bir karakter kullanılarak verilebilmesi mümkündür. Ancak oluşturulduktan sonra, değeri görüntülenmeyebilir.
Örneğin, "𓀀𫝁𐒸mkdir" karakterleri (😃 ve Tamamlayıcı İdeografik Düzlem (SIP) karakterleri) içeren bir klasör adıyla verme işlemi NFSv4.x dosyasında başarılı görünüyor. komutu çalıştırılırken ls klasör görünmez.
root@ubuntu:/NFSv4/NFS$ mkdir "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS$ ls -la
total 8
drwxrwxr-x 3 nobody 4294967294 4096 Jan 10 17:15 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
root@ubuntu:/NFSv4/NFS$
Klasör, birimde mevcut. Bu gizli dizin adına geçmek PuTTY istemcisinden çalışır ve bu dizinin içinde bir dosya oluşturulabilir.
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ sudo touch Unicode.txt
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ ls -la
-rw-r--r-- 1 root root 0 Jan 10 17:31 Unicode.txt
PuTTY'den alınan bir istatistik komutu da klasörün mevcut olduğunu onaylar:
root@ubuntu:/NFSv4/NFS$ stat "NFSv4 Putty 𓀀𫝁😃𐒸"
**File: NFSv4 Putty** **𓀀**** 𫝁 ****😃**** 𐒸**
Size: 4096 Blocks: 8 IO Block: 262144 **directory**
Device: 3ch/60d Inode: 101 Links: 2
Access: (0775/drwxrwxr-x) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2024-01-10 17:15:44.860775000 +0000
Modify: 2024-01-10 17:31:35.049770000 +0000
Change: 2024-01-10 17:31:35.049770000 +0000
Birth: -
Klasörün mevcut olduğu doğrulanmış olsa da, istemci görüntüdeki klasörü resmi olarak "göremediğinden" joker karakter komutları çalışmaz.
root@ubuntu:/NFSv4/NFS$ cp \* /NFSv3/
cp: can't stat '\*': No such file or directory
NFSv4.1, UTF-8 kodlamasına bağlı olmayan bir karakterle karşılaştığında istemciye bir hata gönderir.
Örneğin, Bastion'ı kullanarak NFSv4.1 üzerinden PuTTY kullanarak oluşturduğumuz dizine erişmeye çalışırken şu sonuç elde edilir:
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃�"
-bash: cd: $'NFSv4 Putty \262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355': Invalid argument
The "invalid argument" error message doesn't help diagnose the root cause, but a packet capture shines a light on the problem:
78 1.704856 y.y.y.y x.x.x.x NFS 346 V4 Call (Reply In 79) LOOKUP DH: 0x44caa451/NFSv4 Putty ��������
79 1.705058 x.x.x.x y.y.y.y NFS 166 V4 Reply (Call In 25) OPEN Status: NFS4ERR\_INVAL
NFS4ERR_INVAL RFC-8881 kapsamındadır.
Klasöre PuTTY'den erişilebildiği için (gönderilen ve alınan kodlama nedeniyle), ad belirtilirse kopyalanabilir. Bu klasörü NFSv4.1 Azure NetApp Files biriminden NFSv3 Azure NetApp Files birimine kopyaladıktan sonra klasör adı görüntülenir:
root@ubuntu:/NFSv4/NFS$ cp -r /NFSv4/NFS/"NFSv4 Putty 𓀀𫝁😃𐒸" /NFSv3/NFSv3/
root@ubuntu:/NFSv4/NFS$ ls -la /NFSv3/NFSv3 | grep v4
drwxrwxr-x 2 root root 4096 Jan 10 17:49 NFSv4 Putty 𓀀𫝁😃𐒸
Shift-JIS gibi UTF-8 olmayan bir biçime dosya dönüştürme ('NFS4ERR\_INVAL' kullanılarak) denenirse aynı hata görülebilir.
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
Daha fazla bilgi için bkz. Dosyaları farklı kodlamalara dönüştürme.
İkili protokol davranışları
Azure NetApp Files, birimlere çift protokollü erişim aracılığıyla hem NFS hem de SMB tarafından erişilmesine olanak tanır. NFS (UTF-8) ve SMB (UTF-16) tarafından kullanılan dil kodlaması arasındaki büyük farklılıklar nedeniyle, karakter kümeleri, dosya ve klasör adları ve yol uzunlukları protokoller arasında çok farklı davranışlara sahip olabilir.
SMB'den NFS tarafından oluşturulan dosya ve klasörleri görüntüleme
İkili protokol erişimi (SMB ve NFS) için Azure NetApp Files kullanıldığında, UTF-16 tarafından desteklenmeyen bir karakter kümesi NFS aracılığıyla UTF-8 kullanılarak oluşturulan bir dosya adında kullanılabilir. Bu senaryolarda, SMB desteklenmeyen karakterler içeren bir dosyaya eriştiğinde, 8.3 kısa dosya adı kuralı kullanılarak SMB'de ad kesilir.
Karakter kümeleriyle NFSv3 tarafından oluşturulan dosyalar ve SMB davranışları
NFSv3, UTF-8 kodlaması uygulamaz. Standart olmayan dil kodlamaları (Shift-JISgibi) kullanan karakterler, NFSv3 kullanırken Azure NetApp Files ile birlikte çalışır.
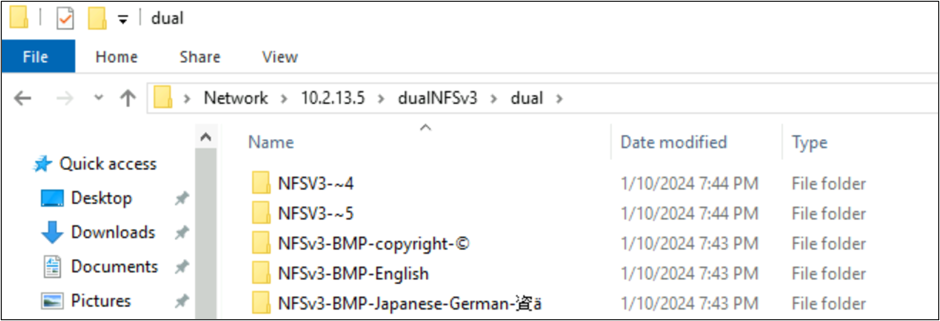
Aşağıdaki örnekte, NFSv3 kullanılarak bir Azure NetApp Files biriminde Unicode'daki çeşitli düzlemlerden farklı karakter kümeleri kullanan bir dizi klasör adı oluşturulmuştur. NFSv3'ten görüntülendiğinde, bunlar doğru şekilde gösterilir.
root@ubuntu:/NFSv3/dual$ ls -la
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-English
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-Japanese-German-資ä
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-copyright-©
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-CJK-plane2-𫝁
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-emoji-plane1-😃
Windows SMB'den, BMP'de karakterler bulunan klasörler düzgün görüntülenir, ancak UTF-8/UTF-16 dönüştürmesinin bu karakterler için uyumsuz olması nedeniyle bu düzlemin dışındaki karakterler 8,3 ad biçimiyle görüntülenir.
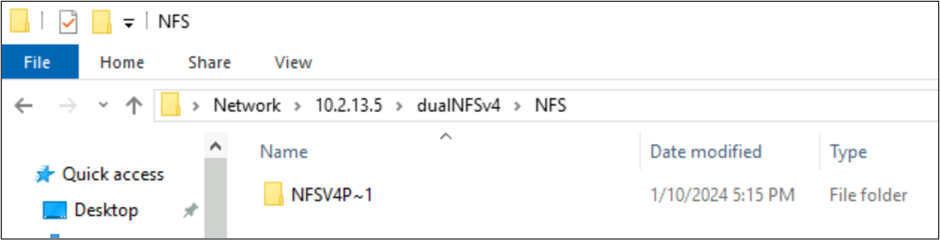
Karakter kümeleriyle NFSv4.1 tarafından oluşturulan dosyalar ve SMB davranışları
Önceki örneklerde, NFSv4.1 üzerinden Azure NetApp Files biriminde adlı NFSv4 Putty 𓀀𫝁😃𐒸 bir klasör oluşturulmuş, ancak NFSv4.1 kullanılarak görüntülenemedi. Ancak, SMB kullanılarak görülebilir. Ad, NFS istemcisi tarafından oluşturulan desteklenmeyen karakter kümeleri ve farklı Unicode düzlemlerindeki karakterlerin uyumsuz olan UTF-8/UTF-16 dönüştürmeleri nedeniyle, SMB'de desteklenen 8.3 formatında kısaltılır.
Bir klasör adı BMP'de (İngilizce veya başka bir şekilde) bulunan standart UTF-8 karakterlerini kullandığında, SMB adları düzgün bir şekilde çevirir.
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-English
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-資ä
root@ubuntu:/NFSv4/NFS$ ls -la
total 16
drwxrwxr-x 5 nobody 4294967294 4096 Jan 10 18:26 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
**drwxrwxr-x 2 root root 4096 Jan 10 18:21 NFS-created-English**
**drwxrwxr-x 2 root root 4096 Jan 10 18:26 NFS-created-**** 資 ****ä**
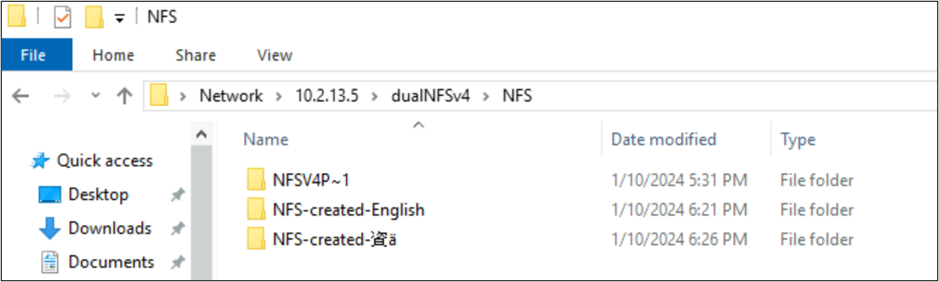
NFS üzerinden SMB tarafından oluşturulan dosya ve klasörler
Windows istemcileri, SMB paylaşımlarına erişmek için kullanılan birincil istemci türüdür. Bu istemciler varsayılan olarak UTF-16 kodlamasına sahiptir. Bölge ayarlarında etkinleştirerek Windows'ta UTF-8 ile kodlanmış bazı karakterleri desteklemek mümkündür:
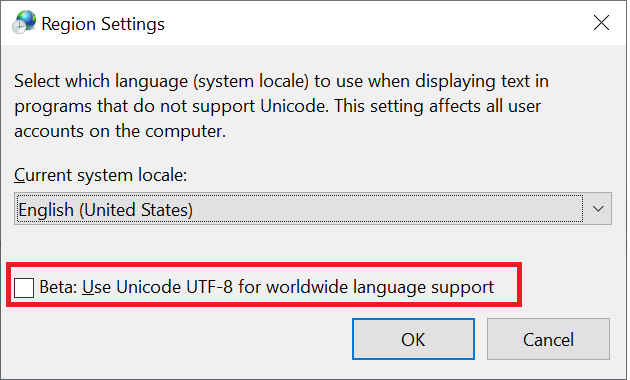
Azure NetApp Files'da bir SMB paylaşımı üzerinden bir dosya veya klasör oluşturulduğunda, karakter kümesi UTF-16 olarak kodlanır. Sonuç olarak, UTF-8 kodlaması kullanan istemciler (Linux tabanlı NFS istemcileri gibi), özellikle Temel Çok Dilli Düzlemin (BMP) dışında kalan karakterler olmak üzere bazı karakter kümelerini düzgün bir şekilde çeviremeyebilir.
Desteklenmeyen karakter davranışı
Bu senaryolarda, bir NFS istemcisi desteklenmeyen karakterlerle SMB kullanılarak oluşturulan bir dosyaya eriştiğinde, ad karakterin Unicode değerlerini temsil eden bir dizi sayısal değer olarak görüntülenir.
Örneğin, bu klasör BMP dışındaki karakterler kullanılarak Windows Gezgini'nde oluşturulmuştur.
PS Z:\SMB\> dir
Directory: Z:\SMB
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/9/2024 9:53 PM SMB𓀀𫝁😃𐒸
NFSv3 üzerinde SMB tarafından oluşturulan klasör gösterilir:
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 9 21:53 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
NFSv4.1 üzerinde, SMB tarafından oluşturulan klasör aşağıdaki gibi görünür:
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 4 17:09 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
Desteklenen karakter davranışı
Karakterler BMP'de olduğunda, SMB ve NFS protokolleri ile bunların sürümleri arasında sorun olmaz.
Örneğin, Azure NetApp Files biriminde SMB kullanılarak oluşturulan ve BMP'de birden çok dilde (İngilizce, Almanca, Kiril, Runic) karakterler bulunan bir klasör adı tüm protokollerde ve sürümlerde düzgün görünür.
- Temel Latin "SMB"
- Yunanca "ͶΘΩ"
- Kiril "ЁЄЊ"
- Runik "ᚠᚱᛯ"
- CJK Uyumluluk İdeografları "豈滑虜"
Ad SMB'de şu şekilde görünür:
PS Z:\SMB\> mkdir SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/11/2024 8:00 PM SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Ad NFSv3'ten şu şekilde görünür:
$ ls | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Ad NFSv4.1'den şu şekilde görünür:
$ ls /NFSv4/SMB | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Dosyaları farklı kodlamalara dönüştürme
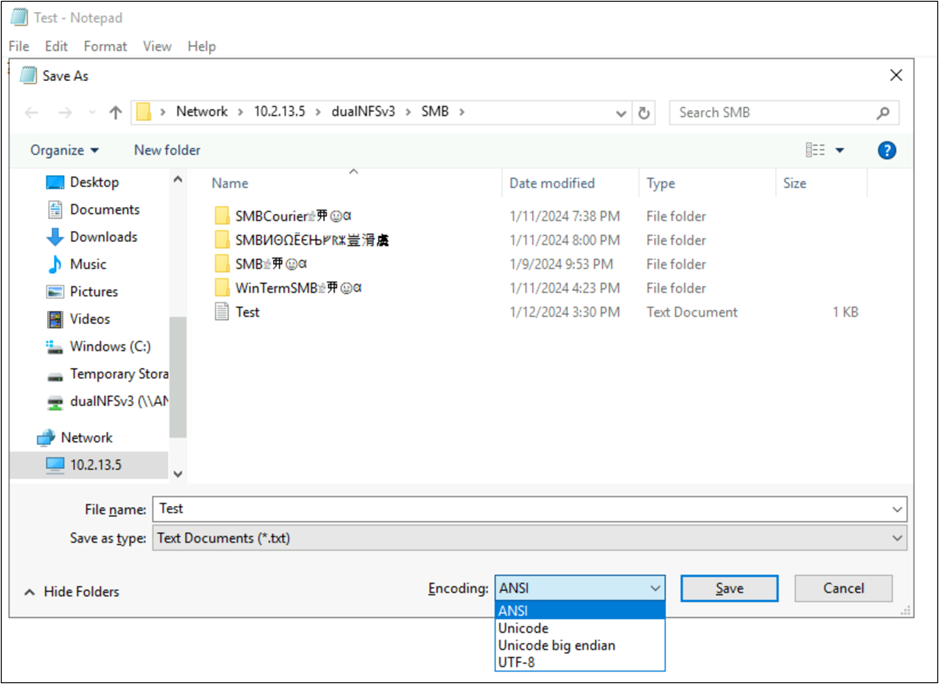
Dosya ve klasör adları, dosya sistemi nesnelerinin dil kodlamalarını kullanan tek bölümleri değildir. Dosya içeriği (örneğin, bir metin dosyasının içindeki özel karakterler) bir rol oynayabilir. Örneğin, bir dosya uyumsuz biçimde özel karakterlerle kaydedilmeye çalışılırsa bir hata iletisi görülebilir. Bu durumda Katagana karakterleri içeren bir dosya ANSI'ye kaydedilemez çünkü bu karakterler bu kodlamada mevcut değildir.
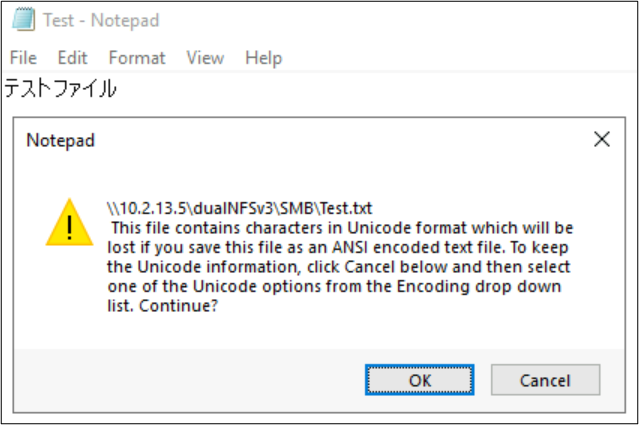
Bu dosya bu biçimde kaydedildikten sonra karakterler soru işaretlerine dönüştürülür:
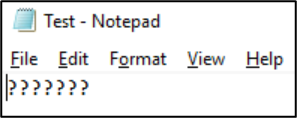
Dosya kodlamaları NAS istemcilerinden görüntülenebilir. Windows istemcilerinde, bir dosyanın kodlamasını görüntülemek için Not Defteri veya Not Defteri++ gibi bir uygulama kullanabilirsiniz.
İstemcide Linux için Windows Alt Sistemi (WSL) veya Git yüklüyse, file komut kullanılabilir.
Bu uygulamalar, farklı kodlama türleri olarak kaydederek dosyanın kodlamasını değiştirmenize de olanak tanır. Ayrıca PowerShell, ve Get-Content cmdlet'leri ile dosyalarda kodlamayı Set-Content dönüştürmek için kullanılabilir.
Örneğin, dosya utf8-text.txt UTF-8 olarak kodlanır ve BMP dışında karakterler içerir. UTF-8 kullanıldığından, karakterler düzgün görüntülenir.
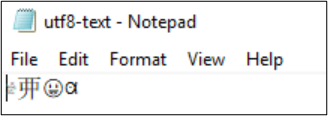
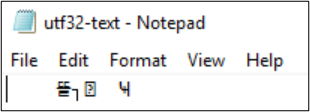
Kodlama UTF-32'ye dönüştürülürse, karakterler düzgün görüntülenmez.
PS Z:\SMB\> Get-Content .\utf8-text.txt |Set-Content -Encoding UTF32 -Path utf32-text.txt
Get-Content dosya içeriğini görüntülemek için de kullanılabilir. PowerShell varsayılan olarak UTF-16 kodlamasını (Kod sayfası 437) kullanır ve konsolun yazı tipi seçimleri sınırlıdır, bu nedenle özel karakterler içeren UTF-8 biçimli dosya düzgün görüntülenemez:
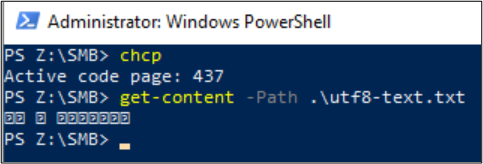
Linux istemcileri, dosyanın kodlamasını görüntülemek için komutunu kullanabilir file . Çift protokollü ortamlarda, SMB kullanılarak bir dosya oluşturulursa, NFS kullanan Linux istemcisi dosya kodlamasını denetleyebilir.
$ file -i utf8-text.txt
utf8-text.txt: text/plain; charset=utf-8
$ file -i utf32-text.txt
utf32-text.txt: text/plain; charset=utf-32le
Dosya kodlama dönüştürme işlemi Linux istemcilerinde komutu kullanılarak iconv gerçekleştirilebilir. Desteklenen kodlama biçimlerinin listesini görmek için kullanın iconv -l.
Örneğin UTF-8 kodlanmış dosyası UTF-16'ya dönüştürülebilir.
$ iconv -t UTF16 utf8-text.txt \> utf16-text.txt
$ file -i utf8-text.txt
utf8-text.txt: text/plain; **charset=utf-8**
$ file -i utf16-text.txt
utf16-text.txt: text/plain; **charset=utf-16le**
Dosya adında veya dosya içeriğinde ayarlanan karakter hedef kodlama tarafından desteklenmiyorsa dönüştürmeye izin verilmez. Örneğin, Shift-JIS dosyanın içeriğindeki karakterleri destekleyemez.
$ iconv -t SJIS utf8-text.txt SJIS-text.txt
iconv: illegal input sequence at position 0
Bir dosyada kodlama tarafından desteklenen karakterler varsa dönüştürme başarılı olur. Örneğin, dosya テストファイル Katagana karakterlerini içeriyorsa, Shift-JIS dönüştürme NFS üzerinde başarılı olur. Burada kullanılan NFS istemcisi yerel ayar ayarlarından dolayı Shift-JIS anlamadığından kodlamada "unknown-8bit" gösterilir.
$ cat SJIS.txt
テストファイル
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
$ iconv -t SJIS SJIS.txt \> SJIS2.txt
$ file -i SJIS.txt
SJIS.txt: text/plain; **charset=utf-8**
$ file -i SJIS2.txt
SJIS2.txt: text/plain; **charset=unknown-8bit**
Azure NetApp Files birimleri yalnızca UTF-8 uyumlu biçimlendirmeyi desteklediğinden Katagana karakterleri okunamayan biçime dönüştürülür.
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
NFSv4.x kullanılırken, NFSv4.x UTF-8 kodlamasını zorlasa bile dosyanın içeriğinin içinde uyumsuz karakterler bulunduğunda dönüştürmeye izin verilir. Bu örnekte, Azure NetApp Files biriminde bulunan Katagana karakterleri içeren UTF-8 kodlu bir dosya, dosyanın içeriğini düzgün şekilde gösterir.
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
S$ cat SJIS.txt
テストファイル
Ancak dönüştürüldükten sonra, dosyadaki karakterler uyumsuz kodlama nedeniyle yanlış görüntüleniyor.
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
Dosyanın adı UTF-8 için desteklenmeyen karakterler içeriyorsa, dönüştürme NFSv3 üzerinden başarılı olur, ancak protokol sürümünün UTF-8 zorlaması nedeniyle NFSv4.x üzerinde başarısız olur.
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
Karakter kümesi en iyi uygulamalar
Azure NetApp Files birimlerinde standart Temel Çok Dilli Düzlem (BMP) dışında özel karakterler veya karakterler kullanılırken, bazı en iyi yöntemler dikkate alınmalıdır.
- Azure NetApp Files birimleri UTF-8 birim dili kullandığından, NFS istemcileri için dosya kodlaması tutarlı sonuçlar için UTF-8 kodlamasını da kullanmalıdır.
- Dosya adlarındaki veya dosya içeriklerindeki karakter kümeleri, düzgün görüntü ve işlevsellik için UTF-8 uyumlu olmalıdır.
- SMB UTF-16 karakter kodlaması kullandığından, BMP dışındaki karakterler çift protokollü birimlerde NFS üzerinden düzgün görüntülenmeyebilir. Dosya içeriğinde özel karakterlerin kullanımını mümkün olduğunca en aza indirin.
- Özellikle NFSv4.1 veya çift protokollü birimleri kullanırken dosya adlarında BMP dışında özel karakterler kullanmaktan kaçının.
- BMP'de olmayan karakter kümeleri için UTF-8 kodlaması, tek bir dosya protokolü kullanılırken Azure NetApp Files'da karakterlerin görüntülenmesine izin vermelidir (yalnızca SMB veya yalnızca NFS). Ancak çift protokollü birimler çoğu durumda bu karakter kümelerini barındıramaz.
- Standart olmayan kodlama (Shift-JISgibi) Azure NetApp Files birimlerinde desteklenmez.
- Vekil çift karakterleri (emoji gibi) Azure NetApp Files birimlerinde desteklenir.