Azure SQL Veritabanı'ndaki veritabanları için dosya alanını yönetme
Şunlar için geçerlidir: ![]() Azure SQL Veritabanı
Azure SQL Veritabanı
Bu makalede, Azure SQL Veritabanı veritabanları için farklı depolama alanı türleri ve ayrılan dosya alanının açıkça yönetilmesi gerektiğinde izleyebileceğiniz adımlar açıklanmaktadır.
Genel bakış
Azure SQL Veritabanı, veritabanları için temel alınan veri dosyalarının ayrılmasının kullanılan veri sayfalarının sayısından daha fazla olabileceği iş yükü desenleri vardır. Kullanılan alan arttığında ve veriler daha sonra silindiğinde bu koşul oluşabilir. Bunun nedeni veriler silindiğinde ayrılan dosya alanının otomatik olarak geri kazanılmamasıdır.
Aşağıdaki senaryolarda dosya alanı kullanımının izlenmesi ve veri dosyalarının küçültülmesi gerekli olabilir:
- Bir elastik havuzun veritabanları için ayrılan dosya alanının maksimum havuz boyutuna erişmesi durumunda veri artışına izin verilmesi.
- Tek bir veritabanının veya elastik havuzun maksimum boyutunun küçülmesine izin verilmesi.
- Tek bir veritabanının veya elastik havuzun daha düşük maksimum boyuta sahip farklı bir hizmet katmanına veya performans katmanına geçmesine izin verilmesi.
Not
Küçültme işlemleri normal bir bakım işlemi olarak kabul edilmemelidir. Düzenli, yinelenen iş işlemleri nedeniyle büyüyen veri ve günlük dosyaları için küçültme işlemleri gerekmez.
Dosya alanı kullanımını izleme
Aşağıdaki API'lerde görüntülenen çoğu depolama alanı ölçümü yalnızca kullanılan veri sayfalarının boyutunu ölçer:
Ancak aşağıdaki API'ler veritabanları ve elastik havuzlar için ayrılan alan boyutunu da ölçer:
- T-SQL: sys.resource_stats
- T-SQL: sys.elastic_pool_resource_stats
Veritabanı için depolama alanı türlerini anlama
Aşağıdaki depolama alanı miktarlarını anlamak, veritabanının dosya alanını yönetmek için önemlidir.
| Veritabanı miktarı | Tanım | Yorumlar |
|---|---|---|
| Kullanılan veri alanı | Veritabanı verilerini depolamak için kullanılan alan miktarı. | Genel olarak, kullanılan alan eklemelerde (silmelerde) artar (azalır). Bazı durumlarda, işlemdeki verilerin miktarına ve düzenine ve herhangi bir parçalanmaya bağlı olarak eklemelerde veya silmelerde kullanılan alan değişmez. Örneğin her veri sayfasından bir satır silindiğinde kullanılan alan azalmayabilir. |
| Ayrılan veri alanı | Veritabanı verilerinin depolanması için kullanılabilir hale getirilen biçimlendirilmiş dosya alanı miktarı. | Ayrılan alan miktarı otomatik olarak artar ancak silme işlemlerinden sonra azalmaz. Bu davranış, alanın yeniden biçimlendirilmesi gerekmediğinden gelecekteki eklemelerin daha hızlı olmasını sağlar. |
| Ayrılan ancak kullanılmayan veri alanı | Ayrılan veri alanı miktarıyla kullanılan veri alanı arasındaki fark. | Bu miktar, veritabanı veri dosyalarının küçültülmesiyle geri kazanılabilecek maksimum boş alan miktarını temsil eder. |
| En büyük veri boyutu | Veritabanı verilerini depolamak için kullanılabilecek maksimum alan miktarı. | Ayrılan veri alanı miktarı, maksimum veri boyutunu aşamaz. |
Aşağıdaki diyagramda, veritabanı için farklı depolama alanı türleri arasındaki ilişki gösterilmektedir.
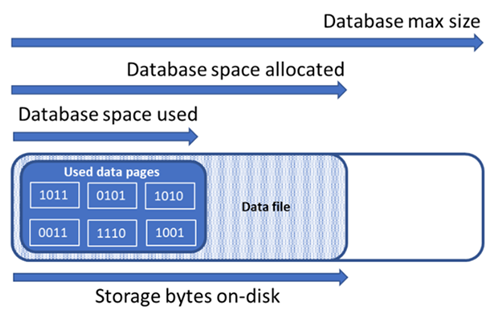
Dosya alanı bilgileri için tek bir veritabanını sorgulama
Ayrılan veritabanı dosya alanı miktarını ve ayrılan kullanılmayan alan miktarını döndürmek için sys.database_files aşağıdaki sorguyu kullanın. Sorgu sonucundaki değerler MB olarak döndürülür.
-- Connect to a user database
SELECT file_id, type_desc,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS decimal(19,4)) * 8 / 1024. AS space_used_mb,
CAST(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0 AS decimal(19,4)) AS space_unused_mb,
CAST(size AS decimal(19,4)) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS decimal(19,4)) * 8 / 1024. AS max_size_mb
FROM sys.database_files;
Elastik havuz için depolama alanı türlerini anlama
Aşağıdaki depolama alanı miktarlarını anlamak, elastik havuzun dosya alanını yönetmek için önemlidir.
| Elastik havuz miktarı | Tanım | Yorumlar |
|---|---|---|
| Kullanılan veri alanı | Elastik havuzdaki tüm veritabanları tarafından kullanılan veri alanının toplamı. | |
| Ayrılan veri alanı | Elastik havuzdaki tüm veritabanları tarafından ayrılan veri alanının toplamı. | |
| Ayrılan ancak kullanılmayan veri alanı | Ayrılan veri alanı miktarıyla elastik havuzdaki tüm veritabanları tarafından kullanılan veri alanı arasındaki fark. | Bu miktar, elastik havuz için veritabanı veri dosyalarının küçültülmesiyle geri kazanılabilecek maksimum ayrılan alan miktarını temsil eder. |
| En büyük veri boyutu | Elastik havuz tarafından tüm veritabanları için kullanılabilecek maksimum veri alanı miktarı. | Elastik havuz için ayrılan alan, elastik havuzun maksimum boyutunu aşmamalıdır. Bu koşul oluşursa, kullanılmayan ayrılan alan veritabanı veri dosyaları daraltılarak geri kazanılabilir. |
Not
"Elastik havuz depolama sınırına ulaştı" hata iletisi, veritabanı nesnelerinin elastik havuz depolama sınırını karşılamak için yeterli alan ayrıldığını, ancak veri alanı ayırmada kullanılmayan alan olabileceğini gösterir. Elastik havuzun depolama sınırını artırmayı veya kısa vadeli bir çözüm olarak kullanılmayan ayrılmış alanı geri kazanma içindeki örnekleri kullanarak veri alanı boşaltmayı göz önünde bulundurun. Ayrıca, daraltma veritabanı dosyalarının olası olumsuz performans etkisini de bilmeniz gerekir. Bkz . Küçültme sonrasında dizin bakımı.
Depolama alanı bilgileri için elastik havuzu sorgulama
Aşağıdaki sorguları kullanarak elastik havuzda ne kadar depolama alanı kaldığını öğrenebilirsiniz.
Kullanılan elastik havuz veri alanı
Kullanılan elastik havuz veri alanı miktarını döndürmek için aşağıdaki sorguyu değiştirin. Sorgu sonucundaki değerler MB olarak döndürülür.
-- Connect to master
-- Elastic pool data space used in MB
SELECT TOP 1 avg_storage_percent / 100.0 * elastic_pool_storage_limit_mb AS ElasticPoolDataSpaceUsedInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
Ayrılmış elastik havuz veri alanı ve kullanılmayan ayrılmış alan
Elastik havuzdaki her veritabanı için ayrılan ve kullanılmayan ayrılan alanı listeleyen bir tablo döndürmek için aşağıdaki örnekleri değiştirin. Tablo, veritabanlarını bu veritabanlarından en yüksek miktarda kullanılmayan ayrılmış alanla en az kullanılmayan ayrılmış alana sipariş eder. Sorgu sonucundaki değerler MB olarak döndürülür.
Havuzdaki her veritabanı için ayrılan alanı belirlemeye yönelik sorgu sonuçları, elastik havuz için ayrılan toplam alanı belirlemek üzere bir araya eklenebilir. Ayrılan elastik havuz alanı, elastik havuzun maksimum boyutunu aşmamalıdır.
Önemli
PowerShell Azure Resource Manager modülü Azure SQL Veritabanı tarafından hala desteklenmektedir, ancak gelecekteki tüm geliştirmeler Az.Sql modülüne yöneliktir. AzureRM modülü en az Aralık 2020'ye kadar hata düzeltmeleri almaya devam edecektir. Az modülündeki ve AzureRm modüllerindeki komutların bağımsız değişkenleri önemli ölçüde aynıdır. Uyumlulukları hakkında daha fazla bilgi için bkz . Yeni Azure PowerShell Az modülüne giriş.
PowerShell betiği için SQL Server PowerShell modülü gerekir. Yüklemek için bkz . PowerShell modülünü indirme.
$resourceGroupName = "<resourceGroupName>"
$serverName = "<serverName>"
$poolName = "<poolName>"
$userName = "<userName>"
$password = "<password>"
# get list of databases in elastic pool
$databasesInPool = Get-AzSqlElasticPoolDatabase -ResourceGroupName $resourceGroupName `
-ServerName $serverName -ElasticPoolName $poolName
$databaseStorageMetrics = @()
# for each database in the elastic pool, get space allocated in MB and space allocated unused in MB
foreach ($database in $databasesInPool) {
$sqlCommand = "SELECT DB_NAME() as DatabaseName, `
SUM(size/128.0) AS DatabaseDataSpaceAllocatedInMB, `
SUM(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0) AS DatabaseDataSpaceAllocatedUnusedInMB `
FROM sys.database_files `
GROUP BY type_desc `
HAVING type_desc = 'ROWS'"
$serverFqdn = "tcp:" + $serverName + ".database.windows.net,1433"
$databaseStorageMetrics = $databaseStorageMetrics +
(Invoke-Sqlcmd -ServerInstance $serverFqdn -Database $database.DatabaseName `
-Username $userName -Password $password -Query $sqlCommand)
}
# display databases in descending order of space allocated unused
Write-Output "`n" "ElasticPoolName: $poolName"
Write-Output $databaseStorageMetrics | Sort -Property DatabaseDataSpaceAllocatedUnusedInMB -Descending | Format-Table
Aşağıdaki ekran görüntüsü, betiğin çıktısının bir örneğidir:

Maksimum elastik havuz veri alanı
Kaydedilen son elastik havuz verisi maksimum boyutunu döndürmek için aşağıdaki T-SQL sorgusunu değiştirin. Sorgu sonucundaki değerler MB olarak döndürülür.
-- Connect to master
-- Elastic pools max size in MB
SELECT TOP 1 elastic_pool_storage_limit_mb AS ElasticPoolMaxSizeInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
Kullanılmayan ayrılan alanı geri kazanma
Önemli
Küçültme komutları çalışan veritabanlarının performansını etkiler ve mümkünse düşük kullanım dönemlerinde çalıştırılmalıdır.
Veri dosyalarını küçültme
Veritabanı performansı üzerindeki olası bir etki nedeniyle Azure SQL Veritabanı veri dosyalarını otomatik olarak küçültmez. Ancak müşteriler, kendi seçtikleri bir zamanda self servis aracılığıyla veri dosyalarını küçültebilir. Bu, düzenli olarak zamanlanmış bir işlem değil, kullanılan alan tüketiminde büyük bir azalmaya yanıt olarak tek seferlik bir olay olmalıdır.
İpucu
Normal uygulama iş yükü dosyaların yeniden aynı ayrılan boyuta kadar büyümesine neden olacaksa veri dosyalarını küçültmeniz önerilmez.
Azure SQL Veritabanı dosyaları küçültmek için veya DBCC SHRINKFILE komutlarını kullanabilirsinizDBCC SHRINKDATABASE:
DBCC SHRINKDATABASEtek bir komut kullanarak veritabanındaki tüm verileri ve günlük dosyalarını küçültür. komutu bir kerede bir veri dosyasını küçültür ve bu da daha büyük veritabanları için uzun sürebilir. Ayrıca günlük dosyasını küçültür; bu genellikle gereksizdir çünkü Azure SQL Veritabanı günlük dosyalarını gerektiği gibi otomatik olarak küçültür.DBCC SHRINKFILEkomutu daha gelişmiş senaryoları destekler:- Veritabanındaki tüm dosyaları küçültmek yerine gerektiğinde tek tek dosyaları hedefleyebilir.
- Her
DBCC SHRINKFILEkomut, birden çok dosyayı aynı anda küçültmek ve daha yüksek kaynak kullanımı ve küçültme sırasında yürütülüyorsa kullanıcı sorgularını engelleme olasılığının daha yüksek olması pahasına toplam küçültme süresini azaltmak için diğerDBCC SHRINKFILEkomutlarla paralel olarak çalışabilir.- Birden çok veri dosyasını aynı anda küçültmek, küçültme işlemini daha hızlı tamamlamanızı sağlar. Eşzamanlı veri dosyası küçültme kullanıyorsanız, bir küçültme isteğinin başka bir kişi tarafından geçici olarak engellenmesini gözlemleyebilirsiniz.
- Dosyanın kuyruğu veri içermiyorsa, bağımsız değişkenini belirterek
TRUNCATEONLYayrılmış dosya boyutunu çok daha hızlı küçültebilir. Bu, dosya içinde veri taşıma gerektirmez.
- Bu küçültme komutları hakkında daha fazla bilgi için bkz . DBCC SHRINKDATABASE ve DBCC SHRINKFILE.
- Veritabanı ve dosya küçültme işlemleri, Azure SQL Veritabanı Hiper Ölçek için önizlemede desteklenir. Daha fazla bilgi için bkz. Azure SQL Veritabanı Hiper Ölçek için küçültme.
Aşağıdaki örneklerin veritabanına değil master hedef kullanıcı veritabanına bağlıyken yürütülmesi gerekir.
Belirli bir veritabanındaki tüm verileri ve günlük dosyalarını küçültmek için kullanmak DBCC SHRINKDATABASE için:
-- Shrink database data space allocated.
DBCC SHRINKDATABASE (N'database_name');
Azure SQL Veritabanı'da, veriler büyüdükçe veritabanında otomatik olarak oluşturulan bir veya daha fazla veri dosyası olabilir. Her dosyanın kullanılan ve ayrılan boyutu da dahil olmak üzere veritabanınızın dosya düzenini belirlemek için aşağıdaki örnek betiği kullanarak katalog görünümünü sorgularsınız sys.database_files :
-- Review file properties, including file_id and name values to reference in shrink commands
SELECT file_id,
name,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_file_size_mb
FROM sys.database_files
WHERE type_desc IN ('ROWS','LOG');
Bir dosyaya göre bir küçültmeyi yalnızca komutuyla DBCC SHRINKFILE yürütebilirsiniz, örneğin:
-- Shrink database data file named 'data_0` by removing all unused at the end of the file, if any.
DBCC SHRINKFILE ('data_0', TRUNCATEONLY);
GO
Veritabanı dosyalarını küçültmenin olası olumsuz performans etkisinin farkında olun, bkz . Küçültme sonrasında dizin bakımı.
İşlem günlüğü dosyasını küçültme
Veri dosyalarından farklı Azure SQL Veritabanı, alan dolu hatalarına yol açacak aşırı alan kullanımından kaçınmak için işlem günlüğü dosyasını otomatik olarak küçültür. Genellikle müşterilerin işlem günlüğü dosyasını küçültmesi gerekmez.
Premium ve İş Açısından Kritik hizmet katmanlarında işlem günlüğü büyük olursa, en yüksek yerel depolama sınırına doğru yerel depolama tüketimine önemli ölçüde katkıda bulunabilirsiniz. Yerel depolama tüketimi sınıra yakınsa, müşteriler aşağıdaki örnekte gösterildiği gibi DBCC SHRINKFILE komutunu kullanarak işlem günlüğünü küçültmeyi seçebilir. Bu, düzenli otomatik küçültme işlemini beklemeden komut tamamlandığı anda yerel depolamayı serbest bırakır.
Aşağıdaki örnek, veritabanına değil master hedef kullanıcı veritabanına bağlıyken yürütülmelidir.
-- Shrink the database log file (always file_id 2), by removing all unused space at the end of the file, if any.
DBCC SHRINKFILE (2, TRUNCATEONLY);
Otomatik küçültme
Veri dosyalarını el ile küçültmeye alternatif olarak, veritabanı için otomatik küçültme etkinleştirilebilir. Ancak, otomatik küçültme dosya alanını geri kazanmada ve DBCC SHRINKFILEdeğerinden daha DBCC SHRINKDATABASE az etkili olabilir.
Varsayılan olarak, çoğu veritabanı için önerilen otomatik küçültme devre dışı bırakılır. Otomatik küçültmenin etkinleştirilmesi gerekirse, kalıcı olarak etkin tutmak yerine, alan yönetimi hedeflerine ulaşıldıktan sonra devre dışı bırakılması önerilir. Daha fazla bilgi için bkz AUTO_SHRINK ile ilgili önemli noktalar.
Örneğin, bir elastik havuzun kullanılan veri dosyası alanında önemli bir büyüme ve azalmayla karşılaşan ve havuzun boyut üst sınırına yaklaşmasına neden olan birçok veritabanının bulunduğu belirli senaryoda otomatik küçültme yararlı olabilir. Bu yaygın bir senaryo değildir.
Otomatik küçültmeyi etkinleştirmek için veritabanınıza (veritabanına değil) bağlıyken aşağıdaki komutu yürütebilirsiniz master .
-- Enable auto-shrink for the current database.
ALTER DATABASE CURRENT SET AUTO_SHRINK ON;
Bu komut hakkında daha fazla bilgi için bkz . DATABASE SET seçenekleri.
Küçültme sonrasında dizin bakımı
Veri dosyalarında bir küçültme işlemi tamamlandıktan sonra dizinler parçalanabilir. Bu, büyük taramalar kullanan sorgular gibi belirli iş yükleri için performans iyileştirme verimliliğini azaltır. Küçültme işlemi tamamlandıktan sonra performans düşüşü oluşursa dizinleri yeniden oluşturmak için dizin bakımını göz önünde bulundurun. Dizin yeniden derlemelerinin veritabanında boş alan gerektirdiğini ve bu nedenle ayrılan alanın artmasına neden olabileceğini ve bu nedenle küçültmenin etkisinin karşılandığını unutmayın.
Dizin bakımı hakkında daha fazla bilgi için bkz . Sorgu performansını geliştirmek ve kaynak tüketimini azaltmak için dizin bakımını iyileştirme.
Büyük veritabanlarını küçültme
Veritabanı ayrılmış alanı yüzlerce gigabayt veya daha yüksek olduğunda, küçültme işlemi tamamlanması için önemli bir süre gerektirebilir, genellikle saatler veya çok terabaytlı veritabanları için gün cinsinden ölçülür. Bu işlemi uygulama iş yüklerine daha verimli ve daha az etkili hale getirmek için kullanabileceğiniz süreç iyileştirmeleri ve en iyi yöntemler vardır.
Alan kullanım temeli yakalama
Küçültmeye başlamadan önce, aşağıdaki alan kullanım sorgusunu yürüterek her veritabanı dosyasında kullanılan ve ayrılan geçerli alanı yakalayın:
SELECT file_id,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
Küçültme işlemi tamamlandıktan sonra bu sorguyu yeniden yürütebilir ve sonucu ilk taban çizgisiyle karşılaştırabilirsiniz.
Veri dosyalarını kesme
Önce parametresiyle her veri dosyası için küçültme yürütmeniz TRUNCATEONLY önerilir. Bu şekilde, dosyanın sonunda ayrılmış ancak kullanılmayan bir alan varsa, hızlı bir şekilde ve veri taşıma olmadan kaldırılır. Aşağıdaki örnek komut, file_id 4 ile veri dosyasını kesilir:
DBCC SHRINKFILE (4, TRUNCATEONLY);
Bu komut her veri dosyası için yürütüldükten sonra, ayrılan alanın (varsa) azalmasını görmek için alan kullanımı sorgusunu yeniden çalıştırabilirsiniz. Veritabanı için ayrılan alanı Azure portalında da görüntüleyebilirsiniz.
Dizin sayfası yoğunluğu değerlendirme
Veri dosyalarının kesilmesi ayrılan alanda yeterli azalmaya neden olmadıysa, veri dosyalarını küçültmeniz gerekir. Ancak, isteğe bağlı ancak önerilen bir adım olarak, önce veritabanındaki dizinler için ortalama sayfa yoğunluğu belirlemeniz gerekir. Aynı miktarda veri için, sayfa yoğunluğu yüksekse küçültme işlemi daha hızlı tamamlanır çünkü daha az sayfa taşıması gerekir. Bazı dizinlerde sayfa yoğunluğu düşükse, veri dosyalarını küçültmeden önce sayfa yoğunluğunun artırılması için bu dizinlerde bakım yapmayı göz önünde bulundurun. Bu, küçültmenin ayrılan depolama alanında daha derin bir azalma elde etmesine de olanak sağlar.
Veritabanındaki tüm dizinler için sayfa yoğunluğu belirlemek için aşağıdaki sorguyu kullanın. Sayfa yoğunluğu sütunda avg_page_space_used_in_percent bildirilir.
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_page_space_used_in_percent,
ips.avg_fragmentation_in_percent,
ips.page_count,
ips.alloc_unit_type_desc,
ips.ghost_record_count
FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND
ips.index_id = i.index_id
ORDER BY page_count DESC;
Sayfa yoğunluğu %60-70'in altında olan yüksek sayfa sayısına sahip dizinler varsa, veri dosyalarını küçültmeden önce bu dizinleri yeniden oluşturmayı veya yeniden düzenlemeyi göz önünde bulundurun.
Not
Daha büyük veritabanlarında, sayfa yoğunluğunun belirlenmesi için yapılan sorgunun tamamlanması uzun zaman (saat) sürebilir. Ayrıca, büyük dizinleri yeniden oluşturmak veya yeniden düzenlemek için de önemli zaman ve kaynak kullanımı gerekir. Bir yandan sayfa yoğunluğunun artırılmasına ek zaman harcamanın, küçültme süresini azaltmanın ve diğer yandan daha yüksek alan tasarrufu elde etmenin bir dezavantajı vardır.
Düşük sayfa yoğunluğuna sahip birden çok dizin varsa, işlemi hızlandırmak için bunları birden çok veritabanı oturumunda paralel olarak yeniden derleyebilirsiniz. Ancak, bunu yaparak veritabanı kaynak sınırlarına yaklaşmadığınızdan emin olun ve çalışıyor olabilecek uygulama iş yükleri için yeterli kaynak alanı bırakın. Azure portalında kaynak tüketimini (CPU, Veri GÇ, Günlük GÇ) izleyin veya sys.dm_db_resource_stats görünümünü kullanın ve yalnızca bu boyutların her birinde kaynak kullanımı %100'ün çok altında kaldığında ek paralel yeniden derlemeler başlatın. CPU, Veri GÇ veya Günlük GÇ kullanımı %100'deyse, daha fazla CPU çekirdeğine sahip olmak ve GÇ aktarım hızını artırmak için veritabanının ölçeğini artırabilirsiniz. Bu, işlemi daha hızlı tamamlamak için ek paralel yeniden derlemeleri etkinleştirebilir.
Örnek dizin yeniden oluşturma komutu
Aşağıda ALTER INDEX deyimini kullanarak bir dizini yeniden derlemek ve sayfa yoğunluğunu artırmak için örnek bir komut verilmiştir:
ALTER INDEX [index_name] ON [schema_name].[table_name]
REBUILD WITH (FILLFACTOR = 100, MAXDOP = 8,
ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 5 MINUTES, ABORT_AFTER_WAIT = NONE)),
RESUMABLE = ON);
Bu komut, çevrimiçi ve devam ettirilebilen bir dizin yeniden derlemesi başlatır. Bu, yeniden oluşturma işlemi devam ederken eşzamanlı iş yüklerinin tabloyu kullanmaya devam etmesini sağlar ve herhangi bir nedenle kesintiye uğrarsa yeniden derlemeyi sürdürmenize olanak tanır. Ancak, bu tür yeniden derleme, tabloya erişimi engelleyen çevrimdışı yeniden derlemeden daha yavaştır. Yeniden oluşturma sırasında tabloya başka hiçbir iş yükünün erişmesi gerekmiyorsa ve RESUMABLE seçeneklerini olarak OFF ayarlayın ONLINE ve yan tümcesini WAIT_AT_LOW_PRIORITY kaldırın.
Dizin bakımı hakkında daha fazla bilgi edinmek için bkz . Sorgu performansını geliştirmek ve kaynak tüketimini azaltmak için dizin bakımını iyileştirme.
Birden çok veri dosyasını küçültme
Daha önce belirtildiği gibi, veri taşıma ile küçültme uzun süre çalışan bir işlemdir. Veritabanında birden çok veri dosyası varsa, birden çok veri dosyasını paralel olarak küçülterek işlemi hızlandırabilirsiniz. Bunu birden çok veritabanı oturumu açarak ve her oturumda farklı file_id bir değerle kullanarak DBCC SHRINKFILE yaparsınız. Daha önce dizinleri yeniden derlemeye benzer şekilde, her yeni paralel küçültme komutunu başlatmadan önce yeterli kaynak odanıza (CPU, Veri GÇ, Günlük GÇ) sahip olduğunuzdan emin olun.
Aşağıdaki örnek komut, file_id 4 içeren veri dosyasını küçültür ve dosya içindeki sayfaları taşıyarak ayrılan boyutunu 52.000 MB'a düşürmeye çalışır:
DBCC SHRINKFILE (4, 52000);
Dosya için ayrılan alanı mümkün olan en aza düşürmek istiyorsanız, hedef boyutu belirtmeden deyimini yürütün:
DBCC SHRINKFILE (4);
Bir iş yükü aynı anda küçültme ile çalışıyorsa, küçültme işlemi tamamlanmadan ve dosya kesilmeden önce küçültme tarafından boşaltılan depolama alanını kullanmaya başlayabilir. Bu durumda, küçültme işlemi belirtilen hedefe ayrılan alanı azaltamaz.
Her dosyayı daha küçük adımlarda küçülterek bunu azaltabilirsiniz. Bu, komutta DBCC SHRINKFILE temel alan kullanım sorgusunun sonuçlarında görüldüğü gibi dosya için ayrılan geçerli alandan biraz daha küçük olan hedefi ayarladığınız anlamına gelir. Örneğin, file_id 4 içeren dosya için ayrılan alan 200.000 MB ise ve 100.000 MB'a küçültmek istiyorsanız, önce hedefi 170.000 MB olarak ayarlayabilirsiniz:
DBCC SHRINKFILE (4, 170000);
Bu komut tamamlandıktan sonra dosyayı kesmiş ve ayrılmış boyutunu 170.000 MB'a düşürmüştür. Daha sonra bu komutu yineleyebilir, hedef önce 140.000 MB, ardından 110.000 MB vb. olarak ayarlanır ve dosya istenen boyuta küçülene kadar. Komut tamamlanırsa ancak dosya kesilmemişse, daha küçük adımlar kullanın; örneğin 30.000 MB yerine 15.000 MB.
Eşzamanlı olarak çalışan tüm küçültme oturumlarında küçültme ilerleme durumunu izlemek için aşağıdaki sorguyu kullanabilirsiniz:
SELECT command,
percent_complete,
status,
wait_resource,
session_id,
wait_type,
blocking_session_id,
cpu_time,
reads,
CAST(((DATEDIFF(s,start_time, GETDATE()))/3600) AS varchar) + ' hour(s), '
+ CAST((DATEDIFF(s,start_time, GETDATE())%3600)/60 AS varchar) + 'min, '
+ CAST((DATEDIFF(s,start_time, GETDATE())%60) AS varchar) + ' sec' AS running_time
FROM sys.dm_exec_requests AS r
LEFT JOIN sys.databases AS d
ON r.database_id = d.database_id
WHERE r.command IN ('DbccSpaceReclaim','DbccFilesCompact','DbccLOBCompact','DBCC');
Not
Küçültme ilerlemesi doğrusal olmayabilir ve küçültme işlemi devam ediyor olsa bile sütundaki percent_complete değer uzun süreler boyunca neredeyse değişmeden kalabilir.
Tüm veri dosyaları için küçültme işlemi tamamlandıktan sonra, ayrılan depolama boyutundaki azalmayı belirlemek için alan kullanım sorgusunu yeniden çalıştırın (veya Azure portalına bakın). Kullanılan alan ile ayrılan alan arasında hala büyük bir fark varsa, dizinleri daha önce açıklandığı gibi yeniden oluşturabilirsiniz. Bu, ayrılan alanı geçici olarak artırabilir, ancak dizinleri yeniden derledikten sonra veri dosyalarının yeniden küçültülmesi ayrılan alanda daha derin bir azalmaya neden olmalıdır.
Küçültme sırasında geçici hatalar
Bazen bir küçültme komutu zaman aşımları ve kilitlenmeler gibi çeşitli hatalarla başarısız olabilir. Genel olarak, bu hatalar geçicidir ve aynı komut yinelenirse bir daha oluşmaz. Küçültme bir hatayla başarısız olursa, veri sayfalarını taşırken şu ana kadar kaydettiği ilerleme korunur ve dosyayı küçültmeye devam etmek için aynı küçültme komutu yeniden yürütülebilir.
Aşağıdaki örnek betik, zaman aşımı hatası veya kilitlenme hatası oluştuğunda otomatik olarak yapılandırılabilir sayıda yeniden denemek için yeniden deneme döngüsünde küçültmeyi nasıl çalıştırabileceğinizi gösterir. Bu yeniden deneme yaklaşımı, küçültme sırasında oluşabilecek diğer birçok hata için geçerlidir.
DECLARE @RetryCount int = 3; -- adjust to configure desired number of retries
DECLARE @Delay char(12);
-- Retry loop
WHILE @RetryCount >= 0
BEGIN
BEGIN TRY
DBCC SHRINKFILE (1); -- adjust file_id and other shrink parameters
-- Exit retry loop on successful execution
SELECT @RetryCount = -1;
END TRY
BEGIN CATCH
-- Retry for the declared number of times without raising an error if deadlocked or timed out waiting for a lock
IF ERROR_NUMBER() IN (1205, 49516) AND @RetryCount > 0
BEGIN
SELECT @RetryCount -= 1;
PRINT CONCAT('Retry at ', SYSUTCDATETIME());
-- Wait for a random period of time between 1 and 10 seconds before retrying
SELECT @Delay = '00:00:0' + CAST(CAST(1 + RAND() * 8.999 AS decimal(5,3)) AS varchar(5));
WAITFOR DELAY @Delay;
END
ELSE -- Raise error and exit loop
BEGIN
SELECT @RetryCount = -1;
THROW;
END
END CATCH
END;
Zaman aşımlarına ve kilitlenmelere ek olarak, küçültme işlemi bilinen bazı sorunlardan dolayı hatalarla karşılaşabilir.
Döndürülen hatalar ve azaltma adımları aşağıdaki gibidir:
- Hata numarası: 49503, hata iletisi: %.*ls: Sayfa %d:%d, satır dışı kalıcı sürüm deposu sayfası olduğundan taşınamadı. Sayfa tutma nedeni: %ls. Sayfa bekletme zaman damgası: %I64d.
Bu hata, kalıcı sürüm deposunda (PVS) satır sürümleri oluşturan uzun süre çalışan etkin işlemler olduğunda oluşur. Bu satır sürümlerini içeren sayfalar küçülterek taşınamaz, bu nedenle ilerleme kaydedemez ve bu hatayla başarısız olur.
Hafifletmek için bu uzun süre çalışan işlemler tamamlanana kadar beklemeniz gerekir. Alternatif olarak, bu uzun süre çalışan işlemleri tanımlayıp sonlandırabilirsiniz, ancak işlem hatalarını düzgün bir şekilde işlemezse bu durum uygulamanızı etkileyebilir. Uzun süre çalışan işlemleri bulmanın bir yolu, shrink komutunu çalıştırdığınız veritabanında aşağıdaki sorguyu çalıştırmaktır:
-- Transactions sorted by duration
SELECT st.session_id,
dt.database_transaction_begin_time,
DATEDIFF(second, dt.database_transaction_begin_time, CURRENT_TIMESTAMP) AS transaction_duration_seconds,
dt.database_transaction_log_bytes_used,
dt.database_transaction_log_bytes_reserved,
st.is_user_transaction,
st.open_transaction_count,
ib.event_type,
ib.parameters,
ib.event_info
FROM sys.dm_tran_database_transactions AS dt
INNER JOIN sys.dm_tran_session_transactions AS st
ON dt.transaction_id = st.transaction_id
OUTER APPLY sys.dm_exec_input_buffer(st.session_id, default) AS ib
WHERE dt.database_id = DB_ID()
ORDER BY transaction_duration_seconds DESC;
komutunu kullanarak KILL ve sorgu sonucundan ilişkili session_id değeri belirterek işlemi sonlandırabilirsiniz:
KILL 4242; -- replace 4242 with the session_id value from query results
Dikkat
İşlemi sonlandırmak iş yüklerini olumsuz etkileyebilir.
Uzun süre çalışan işlemler sonlandırıldıktan veya tamamlandıktan sonra, bir iç arka plan görevi bir süre sonra artık gerekli satır sürümlerini temizlemez. Aşağıdaki sorguyu kullanarak temizleme ilerleme durumunu ölçmek için PVS boyutunu izleyebilirsiniz. Sorguyu, shrink komutunu çalıştırdığınız veritabanında çalıştırın:
SELECT pvss.persistent_version_store_size_kb / 1024. / 1024 AS persistent_version_store_size_gb,
pvss.online_index_version_store_size_kb / 1024. / 1024 AS online_index_version_store_size_gb,
pvss.current_aborted_transaction_count,
pvss.aborted_version_cleaner_start_time,
pvss.aborted_version_cleaner_end_time,
dt.database_transaction_begin_time AS oldest_transaction_begin_time,
asdt.session_id AS active_transaction_session_id,
asdt.elapsed_time_seconds AS active_transaction_elapsed_time_seconds
FROM sys.dm_tran_persistent_version_store_stats AS pvss
LEFT JOIN sys.dm_tran_database_transactions AS dt
ON pvss.oldest_active_transaction_id = dt.transaction_id
AND
pvss.database_id = dt.database_id
LEFT JOIN sys.dm_tran_active_snapshot_database_transactions AS asdt
ON pvss.min_transaction_timestamp = asdt.transaction_sequence_num
OR
pvss.online_index_min_transaction_timestamp = asdt.transaction_sequence_num
WHERE pvss.database_id = DB_ID();
Sütunda persistent_version_store_size_gb bildirilen PVS boyutu özgün boyutuna göre önemli ölçüde küçüldükten sonra, yeniden çalıştırma küçültme başarılı olmalıdır.
- Hata numarası: 5223, hata iletisi: %.*ls: Boş sayfa %d:%d serbest bırakılamadı.
gibi ALTER INDEXdevam eden dizin bakım işlemleri varsa bu hata oluşabilir. Bu işlemler tamamlandıktan sonra shrink komutunu yeniden deneyin.
Bu hata devam ederse, ilişkili dizinin yeniden oluşturulması gerekebilir. Yeniden derlenmesi gereken dizini bulmak için aşağıdaki sorguyu shrink komutunu çalıştırdığınız veritabanında yürütebilirsiniz:
SELECT OBJECT_SCHEMA_NAME(pg.object_id) AS schema_name,
OBJECT_NAME(pg.object_id) AS object_name,
i.name AS index_name,
p.partition_number
FROM sys.dm_db_page_info(DB_ID(), <file_id>, <page_id>, default) AS pg
INNER JOIN sys.indexes AS i
ON pg.object_id = i.object_id
AND
pg.index_id = i.index_id
INNER JOIN sys.partitions AS p
ON pg.partition_id = p.partition_id;
Bu sorguyu yürütmeden önce ve <page_id> yer tutucularını aldığınız hata iletisindeki gerçek değerlerle değiştirin<file_id>. Örneğin, ileti Boşsa sayfa 1:62669 serbest bırakılamazsa ve <page_id> <file_id> 1 olur.62669
Sorgu tarafından tanımlanan dizini yeniden derleyin ve shrink komutunu yeniden deneyin.
- Hata numarası: 5201, hata iletisi: DBCC SHRINKDATABASE: %d veritabanı kimliğinin %d dosya kimliği atlandı çünkü dosya geri kazanmak için yeterli boş alana sahip değil.
Bu hata, veri dosyasının daha fazla küçültülemeyeceği anlamına gelir. Sonraki veri dosyasına geçebilirsiniz.
İlgili içerik
Veritabanı en büyük boyutları hakkında bilgi için bkz:
- Tek bir veritabanı için sanal çekirdek tabanlı satın alma modeli sınırlarını Azure SQL Veritabanı
- DTU tabanlı satın alma modeli kullanıldığında tek veritabanları için kaynak sınırları
- Elastik havuzlar için sanal çekirdek tabanlı satın alma modeli sınırlarını Azure SQL Veritabanı
- DTU tabanlı satın alma modelini kullanan elastik havuzlar için kaynak sınırları