Spark bağlayıcısını kullanarak gerçek zamanlı büyük veri analizini hızlandırma
Şunlar için geçerlidir: ![]() Azure SQL Veritabanı Azure SQL Yönetilen Örneği
Azure SQL Veritabanı Azure SQL Yönetilen Örneği ![]()
Not
Eylül 2020 itibarıyla bu bağlayıcı etkin bir şekilde korunmaz. Bununla birlikte, SQL Server ve Azure SQL için Apache Spark Bağlayıcısı artık Python ve R bağlamaları desteği, toplu veri eklemek için kullanımı kolay bir arabirim ve diğer birçok geliştirmeyle kullanılabilir. Bunun yerine yeni bağlayıcıyı değerlendirmenizi ve kullanmanızı kesinlikle öneririz. Eski bağlayıcı (bu sayfa) hakkındaki bilgiler yalnızca arşivleme amacıyla saklanır.
Spark bağlayıcısı, Azure SQL Veritabanı, Azure SQL Yönetilen Örneği ve SQL Server'daki veritabanlarının Spark işleri için giriş veri kaynağı veya çıkış veri havuzu olarak davranmasını sağlar. Büyük veri analizinde gerçek zamanlı işlem verilerini kullanmanıza ve geçici sorgular veya raporlama için sonuçları kalıcı hale getirir. Yerleşik JDBC bağlayıcısı ile karşılaştırıldığında, bu bağlayıcı veritabanınıza toplu veri ekleme olanağı sağlar. 10x ile 20 kat daha hızlı performansla satır satır eklemeden daha iyi performansa sahip olabilir. Spark bağlayıcısı, Azure SQL Veritabanı ve Azure SQL Yönetilen Örneği bağlanmak için Microsoft Entra Id (eski adıYla Azure Active Directory) ile kimlik doğrulamasını destekler ve Microsoft Entra hesabınızı kullanarak Veritabanınızı Azure Databricks'ten bağlamanıza olanak sağlar. Yerleşik JDBC bağlayıcısı ile benzer arabirimler sağlar. Mevcut Spark işlerinizi bu yeni bağlayıcıyı kullanmak için kolayca geçirebilirsiniz.
Not
Microsoft Entra Id daha önce Azure Active Directory (Azure AD) olarak biliniyordu.
Spark bağlayıcısı indirme ve derleme
Bu sayfadan daha önce bağlanılan eski bağlayıcının GitHub deposu etkin olarak korunmaz. Bunun yerine, yeni bağlayıcıyı değerlendirmenizi ve kullanmanızı kesinlikle öneririz.
Desteklenen resmi sürümler
| Bileşen | Sürüm |
|---|---|
| Apache Spark | 2.0.2 veya üzeri |
| Scala | 2.10 veya üzeri |
| SQL Server için Microsoft JDBC sürücüsü | 6.2 veya üzeri |
| Microsoft SQL Server | SQL Server 2008 veya üzeri |
| Azure SQL Veritabanı | Desteklenir |
| Azure SQL Yönetilen Örnek | Desteklenir |
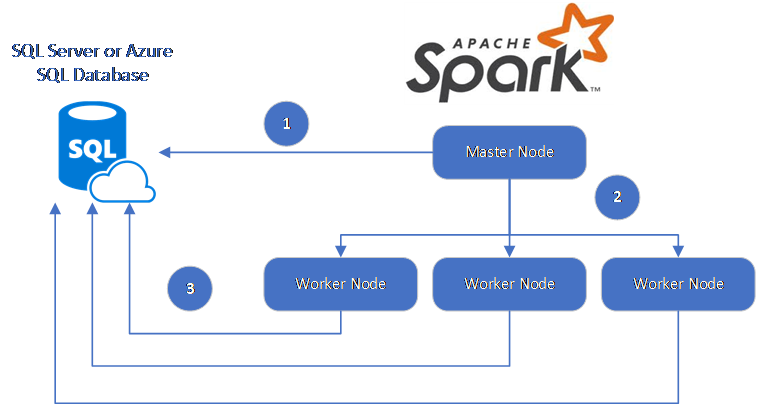
Spark bağlayıcısı, Spark çalışan düğümleri ile veritabanları arasında veri taşımak için SQL Server için Microsoft JDBC Sürücüsü'nden yararlanır:
Veri akışı aşağıdaki gibidir:
- Spark ana düğümü SQL Veritabanı veya SQL Server'daki veritabanlarına bağlanır ve belirli bir tablodan veya belirli bir SQL sorgusu kullanarak verileri yükler.
- Spark ana düğümü, dönüştürme için verileri çalışan düğümlerine dağıtır.
- Çalışan düğümü, SQL Veritabanı ve SQL Server'a bağlanan veritabanlarına bağlanır ve veritabanına veri yazar. Kullanıcı satır satır ekleme veya toplu ekleme kullanmayı seçebilir.
Aşağıdaki diyagramda veri akışı gösterilmektedir.
Spark bağlayıcısını oluşturma
Şu anda bağlayıcı projesi maven kullanmaktadır. Bağlayıcıyı bağımlılıklar olmadan oluşturmak için şunları çalıştırabilirsiniz:
- mvn clean package
- JAR'ın en son sürümlerini yayın klasöründen indirin
- Spark JAR SQL Veritabanı ekleme
Spark bağlayıcısını kullanarak verileri bağlama ve okuma
Verileri okumak veya yazmak için spark işinden SQL Veritabanı ve SQL Server'daki veritabanlarına bağlanabilirsiniz. SQL Veritabanı ve SQL Server'daki veritabanlarında da DML veya DDL sorgusu çalıştırabilirsiniz.
Azure SQL ve SQL Server'dan veri okuma
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********",
"connectTimeout" -> "5", //seconds
"queryTimeout" -> "5" //seconds
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Belirtilen SQL sorgusuyla Azure SQL ve SQL Server'dan veri okuma
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"queryCustom" -> "SELECT TOP 100 * FROM dbo.Clients WHERE PostalCode = 98074" //Sql query
"user" -> "username",
"password" -> "*********",
))
//Read all data in table dbo.Clients
val collection = sqlContext.read.sqlDB(config)
collection.show()
Azure SQL ve SQL Server'a veri yazma
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
// Aquire a DataFrame collection (val collection)
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********"
))
import org.apache.spark.sql.SaveMode
collection.write.mode(SaveMode.Append).sqlDB(config)
Azure SQL ve SQL Server'da DML veya DDL sorgusu çalıştırma
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.query._
val query = """
|UPDATE Customers
|SET ContactName = 'Alfred Schmidt', City = 'Frankfurt'
|WHERE CustomerID = 1;
""".stripMargin
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"queryCustom" -> query
))
sqlContext.sqlDBQuery(config)
Microsoft Entra kimlik doğrulamayı kullanarak Spark'tan bağlanma
Microsoft Entra kimlik doğrulamasını kullanarak SQL Veritabanı ve SQL Yönetilen Örneği bağlanabilirsiniz. Veritabanı kullanıcılarının kimliklerini merkezi olarak yönetmek ve SQL kimlik doğrulamasına alternatif olarak Microsoft Entra kimlik doğrulamasını kullanın.
ActiveDirectoryPassword Kimlik Doğrulama Modu kullanarak bağlanma
Kurulum gereksinimi
ActiveDirectoryPassword kimlik doğrulama modunu kullanıyorsanız, microsoft-authentication-library-for-java ve bağımlılıklarını indirmeniz ve bunları Java derleme yoluna eklemeniz gerekir.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"authentication" -> "ActiveDirectoryPassword",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Erişim belirteci kullanarak bağlanma
Kurulum gereksinimi
Erişim belirteci tabanlı kimlik doğrulama modunu kullanıyorsanız, microsoft-authentication-library-for-java ve bağımlılıklarını indirmeniz ve bunları Java derleme yoluna eklemeniz gerekir.
Azure SQL Veritabanı veya Azure SQL Yönetilen Örneği veritabanınıza erişim belirteci almayı öğrenmek için bkz. Microsoft Entra kimlik doğrulamasını kullanma.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"accessToken" -> "access_token",
"hostNameInCertificate" -> "*.database.windows.net",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Toplu ekleme kullanarak veri yazma
Geleneksel jdbc bağlayıcısı, satır satır ekleme kullanarak verileri veritabanınıza yazar. Spark bağlayıcısını kullanarak toplu ekleme kullanarak Azure SQL ve SQL Server'a veri yazabilirsiniz. Büyük veri kümelerini yüklerken veya verileri columnstore dizininin kullanıldığı tablolara yüklerken yazma performansını önemli ölçüde artırır.
import com.microsoft.azure.sqldb.spark.bulkcopy.BulkCopyMetadata
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
/**
Add column Metadata.
If not specified, metadata is automatically added
from the destination table, which may suffer performance.
*/
var bulkCopyMetadata = new BulkCopyMetadata
bulkCopyMetadata.addColumnMetadata(1, "Title", java.sql.Types.NVARCHAR, 128, 0)
bulkCopyMetadata.addColumnMetadata(2, "FirstName", java.sql.Types.NVARCHAR, 50, 0)
bulkCopyMetadata.addColumnMetadata(3, "LastName", java.sql.Types.NVARCHAR, 50, 0)
val bulkCopyConfig = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"dbTable" -> "dbo.Clients",
"bulkCopyBatchSize" -> "2500",
"bulkCopyTableLock" -> "true",
"bulkCopyTimeout" -> "600"
))
df.bulkCopyToSqlDB(bulkCopyConfig, bulkCopyMetadata)
//df.bulkCopyToSqlDB(bulkCopyConfig) if no metadata is specified.
Sonraki adımlar
Henüz yapmadıysanız azure-sqldb-spark GitHub deposundan Spark bağlayıcısını indirin ve depodaki ek kaynakları keşfedin:
Apache Spark SQL, DataFrames ve Veri Kümeleri Kılavuzu'nu ve Azure Databricks belgelerini de gözden geçirmek isteyebilirsiniz.
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin