Yeni başlayanlar için özel Çeviri
Özel Çeviri, işletmenize, sektörünüze ve etki alanına özgü terminolojinizi ve stilinizi yansıtan bir çeviri sistemi oluşturmanıza olanak tanır. Özel bir sistemi eğitip dağıtmak kolaydır ve herhangi bir programlama becerisi gerektirmez. Özelleştirilmiş çeviri sistemi mevcut uygulamalarınızla, iş akışlarınızla ve web sitelerinizle sorunsuz bir şekilde tümleştirilir ve her gün milyarlarca çeviriyi destekleyen bulut tabanlı Microsoft Metin Çevirisi API'sinin hizmeti aracılığıyla Azure'da kullanılabilir.
Platform, kullanıcıların İngilizceye ve İngilizceden özel çeviri sistemleri oluşturmasına ve yayımlamasına olanak tanır. Özel Çeviri, NMT için kullanılabilen dillerle doğrudan eşlenebilecek 60'tan fazla dili destekler. Tam liste için bkz. dil desteği Çeviri.
Özel çeviri modeli benim için doğru seçim mi?
İyi eğitilmiş özel çeviri modeli, daha doğru etki alanına özgü çeviriler sağlar çünkü tercih edilen çevirileri öğrenmek için daha önce çevrilmiş etki alanı içi belgeleri kullanır. Çeviri bu terimleri ve tümcecikleri bağlam içinde kullanarak hedef dilde akıcı çeviriler oluştururken bağlama bağımlı dil bilgisi dikkate alır.
Tam bir özel çeviri modelinin eğitimi için önemli miktarda veri gerekir. En az 10.000 cümle önceden eğitilmiş belgeniz yoksa, tam dil çeviri modeli eğitemezsiniz. Ancak, yalnızca sözlük modeli eğitebilir veya Metin Çevirisi API'si ile kullanılabilen yüksek kaliteli, kullanıma hazır çevirileri kullanabilirsiniz.
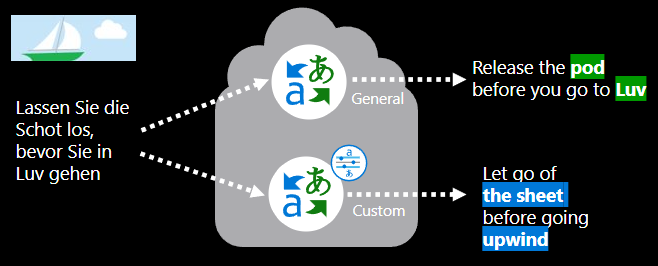
Özel çeviri modelinin eğitimi neleri içerir?
Özel çeviri modeli oluşturmak için şunlar gerekir:
Kullanım örneğinizi anlama.
Etki alanı içinde çevrilmiş verileri alma (tercihen insan tarafından çevrilmiş).
Çeviri kalitesini değerlendirme veya dil çevirilerini hedefleme.
Kullanım örneğimi Nasıl yaparım? değerlendirdim?
Kullanım örneğiniz ve başarınızın nasıl göründüğü konusunda netlik elde etmek, yetkin eğitim verilerini kaynak oluşturmanın ilk adımıdır. Dikkat edilmesi gereken birkaç nokta şunlardır:
İstediğiniz sonuç nedir ve bunu nasıl ölçebilirsiniz?
İşletmenizin etki alanı nedir?
Etki alanı içinde benzer terminoloji ve stil cümleleriniz var mı?
Kullanım örneğinde birden çok etki alanı var mı? Evet ise, bir çeviri sistemi mi yoksa birden çok sistem mi oluşturmanız gerekir?
Bekleyen ve aktarımdaki bölgesel veri yerleşimlerini etkileyen gereksinimleriniz var mı?
Hedef kullanıcılar bir veya birden çok bölgede mi?
Verilerimi nasıl kaynak edinmeliyim?
Etki alanı içi kalite verilerini bulmak genellikle kullanıcı sınıflandırmasına bağlı olarak değişen zorlu bir görevdir. Kullanabileceğiniz verileri değerlendirirken kendinize sorabileceğiniz bazı sorular şunlardır:
Kuruluşlar genellikle uzun yıllar boyunca insan çevirisi kullanan zengin çeviri verilerine sahiptir. Şirketinizde kullanabileceğiniz önceki çeviri verileri var mı?
Çok miktarda tek dilli veriniz mi var? Tek dilli veriler yalnızca bir dildeki verilerdir. Öyleyse, bu veriler için çeviri alabilir misiniz?
Kaynak cümleleri toplamak ve hedef cümleleri sentezlemek için çevrimiçi portallarda gezinebilir misiniz?
Eğitim malzemeleri için ne kullanmalıyım?
BLEU puanı nedir?
BLEU (İki Dilli Değerlendirme Yedeklisi), makinede bir dilden diğerine çevrilmiş metnin duyarlığını veya doğruluğunu değerlendirmek için bir algoritmadır. Özel Çeviri, çeviri doğruluğunu iletmenin bir yolu olarak BLEU ölçümünü kullanır.
BLEU puanı, sıfır ile 100 arasında bir sayıdır. Sıfır puanı, çevirideki hiçbir şeyin başvuruyla eşleşmediği düşük kaliteli bir çeviriyi gösterir. 100 puanı, başvuruyla aynı olan mükemmel bir çeviriyi gösterir. 100 puan almak gerekli değildir; 40 ile 60 arasında bir BLEU puanı yüksek kaliteli bir çeviriyi gösterir.
Ayarlama veya test verileri göndermezsem ne olur?
Ayarlama ve test cümleleri, gelecekte çevirmeyi planladığınız şeyi en iyi şekilde temsil eder. Herhangi bir ayarlama veya test verisi göndermezseniz, Özel Çeviri ayarlama ve test verileri olarak kullanmak üzere eğitim belgelerinizin tümcelerini otomatik olarak dışlar.
| Sistem tarafından oluşturulan | El ile seçim |
|---|---|
| Uygun. | Gelecekteki gereksinimleriniz için ince ayarlamayı etkinleştirir. |
| İyi, eğitim verilerinizin çevirmeyi planladığınız verileri temsil ettiğini biliyorsanız. | Eğitim verilerinizi oluşturmak için daha fazla özgürlük sağlar. |
| Etki alanını büyütürken veya küçülterek kolayca yineleyebilirsiniz. | Daha fazla veri ve daha iyi etki alanı kapsamı sağlar. |
| Her eğitim çalışmasını değiştirir. | Yinelenen eğitim çalıştırmaları üzerinde statik kalır |
Eğitim malzemeleri Özel Çeviri tarafından nasıl işlenir?
Eğitime hazırlanmak için belgeler bir dizi işleme ve filtreleme adımından geçer. Bu adımlar aşağıda açıklanmıştır. Filtreleme işlemi hakkında bilgi sahibi olmak, görüntülenen cümle sayısının yanı sıra Özel Çeviri ile eğitim belgeleri hazırlamak için uygulayabileceğiniz adımları anlamanıza yardımcı olabilir.
Tümce hizalama
Belgeniz XLIFF, XLSX, TMX veya ALIGN biçiminde değilse, Özel Çeviri kaynağınızın cümlelerini ve hedef belgeleri birbirine hizalar. Çeviri belge hizalaması gerçekleştirmez; belgelerin diğer dilde eşleşen bir belgeyi bulması için adlandırma kuralınıza uyar. Özel Çeviri, kaynak metinde karşılık gelen tümceyi hedef dilde bulmaya çalışır. Hizalamaya yardımcı olması için eklenmiş HTML etiketleri gibi belge işaretlemesi kullanır.
Kaynak ve hedef belgelerdeki tümce sayısı arasında büyük bir tutarsızlık görürseniz, kaynak belgeniz paralel olmayabilir veya hizalanamadı. Belge, her iki taraftaki cümlelerin büyük bir farkı (%>10) ile eşleşerek gerçekten paralel olduklarından emin olmak için ikinci bir görünüm sağlar.
Ayarlama ve test verilerini ayıklama
Verileri ayarlama ve test etme isteğe bağlıdır. Sağlamazsanız, sistem ayarlama ve test için kullanılacak eğitim belgelerinizden uygun bir yüzdeyi kaldırır. Kaldırma işlemi, eğitim sürecinin bir parçası olarak dinamik olarak gerçekleşir. Bu adım eğitimin bir parçası olarak gerçekleştiğinden, karşıya yüklenen belgeleriniz etkilenmez. Eğitim başarılı olduktan sonra model ayrıntıları sayfasında her veri kategorisi (eğitim, ayarlama, test ve sözlük) için son kullanılan tümce sayısını görebilirsiniz.
Uzunluk filtresi
- Her iki tarafında yalnızca bir sözcük bulunan tümceleri kaldırır.
- İki tarafında 100'den fazla sözcük bulunan tümceleri kaldırır. Çince, Japonca, Korece muaftır.
- Üçten az karakter içeren tümceleri kaldırır. Çince, Japonca, Korece muaftır.
- Çince, Japonca, Korece için 2000'den fazla karakter içeren cümleleri kaldırır.
- %1'den az alfasayısal karakter içeren cümleleri kaldırır.
- 50'den fazla sözcük içeren sözlük girdilerini kaldırır.
Boşluk
- Sekmeler ve CR/LF dizileri dahil olmak üzere herhangi bir boşluk karakteri dizisini tek bir boşluk karakteriyle değiştirir.
- Tümcedeki baştaki veya sondaki boşluğu kaldırır.
Cümle sonu noktalama işaretleri
Birden çok cümle sonu noktalama işaretini tek bir örnekle değiştirir. Japonca karakter normalleştirme.
Tam genişlikli harfleri ve basamakları yarım genişlikli karakterlere dönüştürür.
Manzarasız XML etiketleri
Ayarlanmamış etiketleri kaçış etiketlerine dönüştürür:
Etiket Olur < & Teğmen; > & Gt; & & Amp; Geçersiz karakterler
Özel Çeviri, Unicode karakter U+FFFD içeren tümceleri kaldırır. U+FFFD karakteri, başarısız olmuş bir kodlama dönüştürmesini gösterir.
Verileri karşıya yüklemeden önce hangi adımları izlemem gerekir?
- Geçersiz kodlamaya sahip tümceleri kaldırın.
- Unicode denetim karakterlerini kaldırın.
- Mümkünse, tümceleri hizalayın (kaynak-hedef).
- Kaynak ve hedef dillerle eşleşmeyen kaynak ve hedef tümceleri kaldırın.
- Kaynak ve hedef cümleler karışık dillere sahip olduğunda, çevrilmemiş sözcüklerin, örneğin kuruluşların ve ürünlerin adlarının kasıtlı olduğundan emin olun.
- Bu hataların modelinize öğretilmesini önlemek için dil bilgisi ve tipografi hatalarını düzeltin.
- Eğitim sürecimiz birden çok cümle içeren kaynak ve hedef satırları işlese de, bir kaynak cümlenin tek bir hedef cümleyle eşlenmesi daha iyi olur.
Sonuçları Nasıl yaparım? değerlendirin?
Modeliniz başarıyla eğitildikten sonra modelin BLEU puanını ve temel model BLEU puanını model ayrıntıları sayfasında görüntüleyebilirsiniz. Hem modelin BLEU puanını hem de temel BLEU puanını oluşturmak için aynı test verilerini kullanırız. Bu veriler, kullanım örneğiniz için hangi modelin daha iyi olacağına ilişkin bilinçli bir karar vermenize yardımcı olur.