Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
ŞUNLAR IÇIN GEÇERLIDIR:
![]() NoSQL
NoSQL
![]() MongoDB
MongoDB
![]() Gremlin
Gremlin
Önemli
Microsoft Fabric'te Azure Cosmos DB'yi yansıtma özelliği artık NoSql API'sinde kullanılabilir. Bu özellik, Azure Synapse Link'in tüm özelliklerini daha iyi analiz performansı, Doku OneLake ile veri varlığınızı birleştirme ve verilerinize Delta Parquet biçiminde erişim açma olanağı sağlar. Azure Synapse Link'i düşünüyorsanız, kuruluşunuza genel uyumu değerlendirmek için yansıtmayı denemenizi öneririz. Microsoft Fabric'te yansıtmayı kullanmaya başlayın.
Azure Synapse Link'i kullanmaya başlamak için lütfen "Azure Synapse Link'i kullanmaya başlama" adresini ziyaret edin
Azure Cosmos DB analiz deposu, işlem iş yüklerinizi etkilemeden Azure Cosmos DB'nizdeki operasyonel verilere karşı büyük ölçekli analizler sağlayan tamamen yalıtılmış bir sütun deposudur.
Azure Cosmos DB işlem deposu şemadan bağımsızdır ve şema veya dizin yönetimiyle uğraşmak zorunda kalmadan işlem uygulamalarınızda yineleme yapmanızı sağlar. Bunun aksine, Azure Cosmos DB analiz deposu analitik sorgu performansı için en iyi duruma getirmek üzere şema haline getirilir. Bu makalede analiz depolaması hakkında ayrıntılı bilgi verilmektedir.
operasyonel veriler üzerinde büyük ölçekli analizlerle ilgili zorluklar
Azure Cosmos DB kapsayıcısında çok modelli işletimsel veriler, dizine alınmış satır tabanlı "işlem deposu" içinde depolanır. Satır deposu biçimi, milisaniye sırasına göre hızlı işlem okuma ve yazma işlemlerine ve işletimsel sorgulara izin verecek şekilde tasarlanmıştır. Veri kümeniz büyürse, karmaşık analitik sorgular bu biçimde depolanan veriler üzerinde sağlanan aktarım hızı açısından pahalı olabilir. Sağlanan aktarım hızının sırayla yüksek tüketimi, gerçek zamanlı uygulamalarınız ve hizmetleriniz tarafından kullanılan işlem iş yüklerinin performansını etkiler.
Geleneksel olarak, büyük miktarlardaki verileri analiz etmek için işletimsel veriler Azure Cosmos DB'nin işlem deposundan ayıklanır ve ayrı bir veri katmanında depolanır. Örneğin, veriler uygun bir biçimde bir veri ambarında veya veri gölünde depolanır. Bu veriler daha sonra büyük ölçekli analizler için kullanılır ve Apache Spark kümeleri gibi işlem altyapıları kullanılarak analiz edilir. Analiz verilerinin işletimsel verilerden ayrılması, en son verileri kullanmak isteyen analistler için gecikmelere neden olur.
ETL işlem hatları, yalnızca yeni alınan işletimsel verileri işlemeye kıyasla işletimsel verilerdeki güncelleştirmeleri işlerken de karmaşık hale gelir.
Sütun odaklı analiz deposu
Azure Cosmos DB analiz deposu, geleneksel ETL işlem hatlarında ortaya çıkan karmaşıklık ve gecikme süresi zorluklarını giderir. Azure Cosmos DB analiz deposu, işletimsel verilerinizi otomatik olarak ayrı bir sütun deposuna eşitleyebilir. Sütun deposu biçimi, büyük ölçekli analitik sorguların iyileştirilmiş bir şekilde gerçekleştirilmesi için uygundur ve bu da bu tür sorguların gecikme süresini artırır.
Azure Synapse Link'i kullanarak artık Azure Synapse Analytics'ten Azure Cosmos DB analiz deposuna doğrudan bağlanarak ETL olmayan HTAP çözümleri oluşturabilirsiniz. Operasyonel verileriniz üzerinde gerçek zamanlıya yakın büyük ölçekli analizler çalıştırmanızı sağlar.
Analiz deposunun özellikleri
Azure Cosmos DB kapsayıcısında analiz deposunu etkinleştirdiğinizde kapsayıcınızdaki işletimsel veriler temel alınarak dahili olarak yeni bir sütun deposu oluşturulur. Bu sütun deposu, bir iç abonelikte, Azure Cosmos DB tarafından tam olarak yönetilen bir depolama hesabında söz konusu kapsayıcı için satır odaklı işlem deposundan ayrı olarak kalıcı hale gelir. Müşterilerin depolama yönetimiyle zaman geçirmesi gerekmez. İşletimsel verilerinize yapılan eklemeler, güncelleştirmeler ve silme işlemleri analiz deposuyla otomatik olarak eşitlenir. Verileri eşitlemek için Değişiklik Akışına veya ETL'ye ihtiyacınız yoktur.
İşletimsel verilerdeki analitik iş yükleri için sütun deposu
Analitik iş yükleri genellikle seçili alanların toplamalarını ve sıralı taramalarını içerir. Veri analiz deposu sütun ana sırada depolanır ve her alanın değerlerinin uygun olduğunda birlikte seri hale getirilebilmesini sağlar. Bu biçim, belirli alanlar üzerinde istatistikleri taramak veya hesaplamak için gereken IOPS'yi azaltır. Büyük veri kümeleri üzerinde yapılan taramalar için sorgu yanıt sürelerini önemli ölçüde artırır.
Örneğin, işletimsel tablolarınız aşağıdaki biçimdeyse:
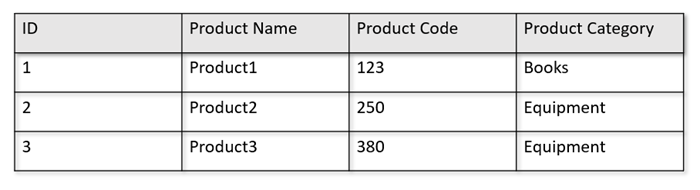
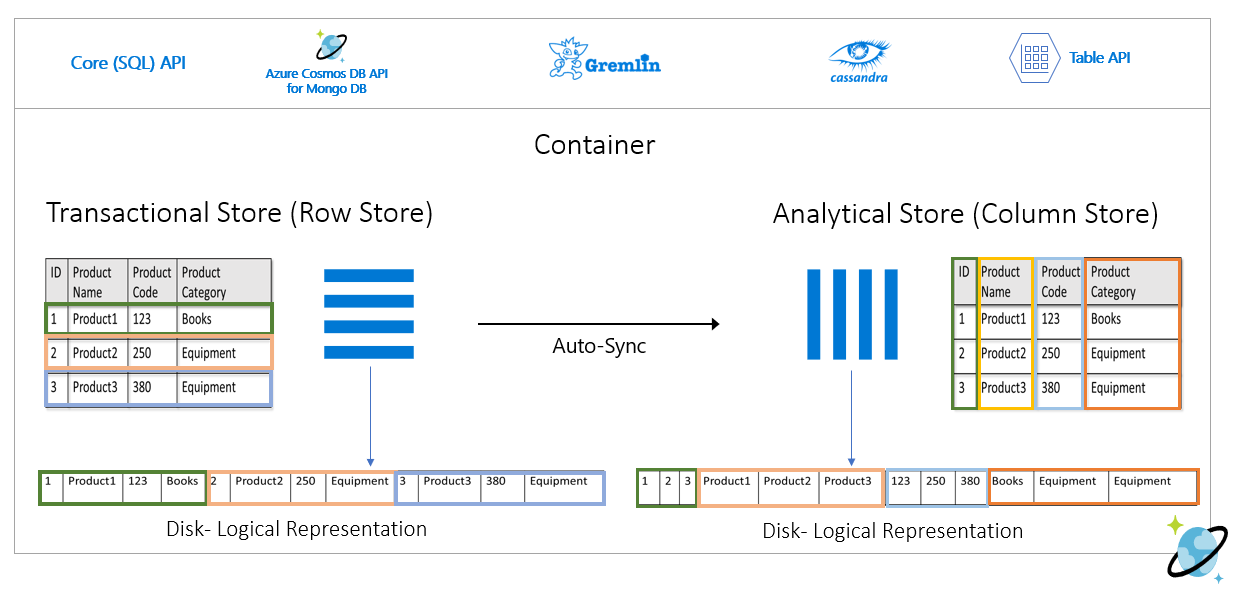
Satır deposu, yukarıdaki verileri diskte satır başına serileştirilmiş biçimde saklar. Bu biçim, "Ürün 1 hakkında bilgi döndürme" gibi işlemsel okuma, yazma ve işlem sorgularının daha hızlı yapılmasını sağlar. Ancak, veri kümesi büyüdükçe ve veriler üzerinde karmaşık analiz sorguları çalıştırmak istiyorsanız pahalı olabilir. Örneğin, "farklı iş birimlerinde ve aylarda 'Ekipman' adlı kategori altında bir ürünün satış eğilimlerini" almak istiyorsanız karmaşık bir sorgu çalıştırmanız gerekir. Bu veri kümesindeki büyük taramalar sağlanan aktarım hızı açısından pahalıya ulaşabilir ve gerçek zamanlı uygulama ve hizmetlerinizi destekleyen işlem iş yüklerinin performansını da etkileyebilir.
Bir sütun deposu olan analiz deposu, benzer veri alanlarını birlikte serileştirip disk IOPS'sini azalttığı için bu tür sorgular için daha uygundur.
Aşağıdaki görüntüde Azure Cosmos DB'deki işlem satır deposu ile analitik sütun deposu karşılaştırması gösterilmektedir:
Analitik iş yükleri için ayrılmış performans
Analiz deposu işlem deposundan ayrı olduğundan analiz sorguları nedeniyle işlem iş yüklerinizin performansını etkilemez. Analiz deposu için ayrı istek birimlerinin (RU) ayrılması gerekmez.
Otomatik Eşitleme
Otomatik Eşitleme, Azure Cosmos DB'nin işlem verilerine ekleme, güncelleştirme, silme işlemlerinin işlem deposundan analiz deposuna neredeyse gerçek zamanlı olarak otomatik olarak eşitlendiği tam olarak yönetilen özelliğini ifade eder. Otomatik eşitleme gecikme süresi genellikle 2 dakika içindedir. Çok sayıda kapsayıcı içeren paylaşılan aktarım hızı veritabanı söz diziminde, tek tek kapsayıcıların otomatik eşitleme gecikme süresi daha yüksek olabilir ve 5 dakikaya kadar sürebilir.
Otomatik eşitleme işleminin her yürütmesinin sonunda işlem verileriniz Azure Synapse Analytics çalışma zamanlarında hemen kullanılabilir hale gelir:
Azure Synapse Analytics Spark havuzları, en son güncelleştirmeler de dahil olmak üzere, otomatik olarak güncelleştirilen Spark tabloları aracılığıyla veya her zaman verilerin son durumunu okuyan komut aracılığıyla
spark.readtüm verileri okuyabilir.Azure Synapse Analytics SQL Sunucusuz havuzları, en son güncelleştirmeler de dahil olmak üzere, otomatik olarak güncelleştirilen görünümler aracılığıyla veya
SELECTher zaman verilerin en son durumunu okuyan komutlarlaOPENROWSETbirlikte tüm verileri okuyabilir.
Not
İşlemsel yaşam süreniz (TTL) 2 dakikadan kısa olsa bile işlem verileriniz analiz deposuyla eşitlenir.
Not
Kapsayıcınızı silerseniz analiz deposu da silinir.
Ölçeklenebilirlik ve esneklik
Azure Cosmos DB işlem deposu, depolamayı ve aktarım hızını kapalı kalma süresi olmadan esnek bir şekilde ölçeklendirmek için yatay bölümleme kullanır. İşlem deposundaki yatay bölümleme, verilerin analiz deposuna neredeyse gerçek zamanlı olarak eşitlendiğinden emin olmak için otomatik eşitlemede ölçeklenebilirlik ve esneklik sağlar. Veri eşitleme, işlem trafiği aktarım hızına bakılmaksızın 1000 işlem/sn veya 1 milyon işlem/sn olmasına bakılmaksızın gerçekleşir ve işlem deposunda sağlanan aktarım hızını etkilemez.
Şema güncelleştirmelerini otomatik olarak işleme
Azure Cosmos DB işlem deposu şemadan bağımsızdır ve şema veya dizin yönetimiyle uğraşmak zorunda kalmadan işlem uygulamalarınızda yineleme yapmanızı sağlar. Bunun aksine, Azure Cosmos DB analiz deposu analitik sorgu performansı için en iyi duruma getirmek üzere şema haline getirilir. Otomatik eşitleme özelliği sayesinde Azure Cosmos DB, işlem deposundaki en son güncelleştirmeler üzerinden şema çıkarımını yönetir. Ayrıca analiz deposundaki şema gösterimini yönetir ve iç içe veri türlerini işlemeyi de içerir.
Şemanız geliştikçe ve zaman içinde yeni özellikler eklendikçe analiz deposu işlem deposundaki tüm geçmiş şemalar arasında otomatik olarak birleştirilmiş bir şema sunar.
Not
Analiz deposu bağlamında, aşağıdaki yapıları özellik olarak değerlendiririz:
- JSON "elements" veya "string-value pair separated by a
:". - ve
{ile}sınırlandırılmış JSON nesneleri. - ve
[ile]sınırlandırılmış JSON dizileri.
Şema kısıtlamaları
Analiz deposunun şemayı otomatik olarak çıkarmasını ve doğru şekilde temsil etmesini etkinleştirdiğinizde Azure Cosmos DB'deki işletimsel verilerde aşağıdaki kısıtlamalar geçerlidir:
Belge şemasındaki tüm iç içe düzeylerde en fazla 1000 özelliğe ve en fazla 127 iç içe yerleştirme derinliğine sahip olabilirsiniz.
- Analiz deposunda yalnızca ilk 1000 özellik temsil edilir.
- Analiz deposunda yalnızca ilk 127 iç içe düzey temsil edilir.
- JSON belgesinin ilk düzeyi kök düzeyidir
/. - Belgenin ilk düzeyindeki özellikler sütun olarak gösterilir.
Örnek senaryolar:
- Belgenizin ilk düzeyinde 2000 özellik varsa, eşitleme işlemi bunların ilk 1000'ini temsil eder.
- Belgelerinizde her birinde 200 özellik bulunan beş düzey varsa, eşitleme işlemi tüm özellikleri temsil eder.
- Belgelerinizde her birinde 400 özellik bulunan 10 düzey varsa, eşitleme işlemi ilk iki düzeyi ve üçüncü düzeyin yalnızca yarısını tam olarak temsil eder.
Aşağıdaki varsayımsal belge dört özellik ve üç düzey içerir.
- Düzeyler ,
rootve içindeki iç içe yerleştirilmiş yapıdır.myArraymyArray - Özellikleri , ,
idmyArrayvemyArray.nested1' dırmyArray.nested2. - Analiz deposu gösteriminde , ve
idolmak üzeremyArrayiki sütun bulunur. Spark veya T-SQL işlevlerini kullanarak iç içe yapıları sütun olarak da kullanıma açabilirsiniz.
- Düzeyler ,
{
"id": "1",
"myArray": [
"string1",
"string2",
{
"nested1": "abc",
"nested2": "cde"
}
]
}
JSON belgeleri (ve Azure Cosmos DB koleksiyonları/kapsayıcıları) benzersizlik açısından büyük/küçük harfe duyarlı olsa da analiz deposu değildir.
-
Aynı belgede: Büyük/küçük harfe duyarsız olarak karşılaştırıldığında aynı düzeydeki özellik adları benzersiz olmalıdır. Örneğin, aşağıdaki JSON belgesinde aynı düzeyde "Ad" ve "ad" vardır. Geçerli bir JSON belgesi olsa da benzersizlik kısıtlamasını karşılamaz ve bu nedenle analiz deposunda tam olarak temsil edilmeyecektir. Bu örnekte, büyük/küçük harfe duyarsız bir şekilde karşılaştırıldığında "Ad" ve "ad" aynıdır. İlk oluşum olduğundan yalnızca
"Name": "fred"analiz deposunda temsil edilir. Ve"name": "john"hiç temsil edilmeyecek.
{"id": 1, "Name": "fred", "name": "john"}-
Farklı belgelerde: Aynı düzeydeki ve aynı ada sahip özellikler, ancak farklı durumlarda, ilk oluşumun ad biçimi kullanılarak aynı sütun içinde temsil edilir. Örneğin, aşağıdaki JSON belgelerinde
"Name"ve"name"aynı düzeydedir. İlk belge biçimi olduğundan"Name", analiz deposunda özellik adını temsil etmek için bu kullanılır. Başka bir deyişle analiz deposundaki sütun adı olacaktır"Name". Hem hem de"fred""john"sütununda gösterilir"Name".
{"id": 1, "Name": "fred"} {"id": 2, "name": "john"}-
Aynı belgede: Büyük/küçük harfe duyarsız olarak karşılaştırıldığında aynı düzeydeki özellik adları benzersiz olmalıdır. Örneğin, aşağıdaki JSON belgesinde aynı düzeyde "Ad" ve "ad" vardır. Geçerli bir JSON belgesi olsa da benzersizlik kısıtlamasını karşılamaz ve bu nedenle analiz deposunda tam olarak temsil edilmeyecektir. Bu örnekte, büyük/küçük harfe duyarsız bir şekilde karşılaştırıldığında "Ad" ve "ad" aynıdır. İlk oluşum olduğundan yalnızca
Koleksiyonun ilk belgesi ilk analiz deposu şemasını tanımlar.
- İlk şemadan daha fazla özelliğe sahip belgeler analiz deposunda yeni sütunlar oluşturur.
- Sütunlar kaldırılamaz.
- Koleksiyondaki tüm belgelerin silinmesi analiz deposu şemasını sıfırlamaz.
- Şema sürümü oluşturma yok. İşlem deposundan çıkardığınız son sürüm, analiz deposunda göreceğiniz sürümdür.
Şu anda Azure Synapse Spark, adlarında bazı özel karakterler bulunan ve aşağıda listelenen özellikleri okuyamaz. Azure Synapse SQL sunucusuz durumdan etkilenmez.
- :
- `
- ,
- ;
- {}
- ()
- \n
- \t
- =
- "
Not
Bu sınırlamaya ulaştığınızda döndürülen Spark hata iletisinde de boşluklar listelenir. Ancak beyaz alanlar için özel bir işlem ekledik, lütfen aşağıdaki öğelerde daha fazla ayrıntıya göz atın.
- Yukarıda listelenen karakterleri kullanan özellikler adlarınız varsa, alternatifler şunlardır:
- Bu karakterlerden kaçınmak için veri modelinizi önceden değiştirin.
- Şu anda şema sıfırlamayı desteklemediğimizden, uygulamanızı benzer ada sahip yedekli bir özellik ekleyecek şekilde değiştirebilir ve bu karakterleri önleyebilirsiniz.
- Özellik adlarında bu karakterler olmadan kapsayıcınızın gerçekleştirilmiş bir görünümünü oluşturmak için Değişiklik Akışı'nı kullanın.
-
dropColumnEtkilenen sütunları yoksaymak ve diğer tüm sütunları bir DataFrame'e yüklemek için Spark seçeneğini kullanın. Söz dizimi aşağıdaki gibidir:
# Removing one column:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName")\
.load()
# Removing multiple columns:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName;StreetName,StreetNumber")\
.option("spark.cosmos.dropMultiColumnSeparator", ";")\
.load()
- Azure Synapse Spark artık adlarında boşluklar bulunan özellikleri destekliyor. Bunun için, etkilenen sütunları bir DataFrame'e yüklemek ve özgün adı korumak için Spark seçeneğini kullanmanız
allowWhiteSpaceInFieldNamesgerekir. Söz dizimi aşağıdaki gibidir:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.allowWhiteSpaceInFieldNames", "true")\
.load()
Aşağıdaki BSON veri türleri desteklenmez ve analiz deposunda gösterilmez:
- Ondalık128
- Normal İfade
- VERITABANı İşaretçisi
- JavaScript
- Simge
- MinKey/MaxKey
ISO 8601 UTC standardına uyan DateTime dizelerini kullanırken aşağıdaki davranışı bekleyebilirsiniz:
- Azure Synapse'teki Spark havuzları bu sütunları olarak
stringtemsil edebilir. - Azure Synapse'teki SQL sunucusuz havuzları bu sütunları olarak
varchar(8000)temsil edebilir.
- Azure Synapse'teki Spark havuzları bu sütunları olarak
Türleri olan
UNIQUEIDENTIFIER (guid)özellikler analiz deposunda olarakstringtemsil edilir ve doğru görselleştirme için SQL'deVARCHARveya Spark'tastringolarak dönüştürülmelidir.Azure Synapse'deki SQL sunucusuz havuzlar, en fazla 1000 sütun içeren sonuç kümelerini destekler ve iç içe sütunların açığa çıkarılması da bu sınıra doğru sayılır. bu bilgileri işlemsel veri mimarinizde ve modellemenizde dikkate almak iyi bir uygulamadır.
Bir veya birden çok belgede bir özelliği yeniden adlandırırsanız, bu özellik yeni bir sütun olarak kabul edilir. Koleksiyondaki tüm belgelerde aynı yeniden adlandırmayı yürütürseniz, tüm veriler yeni sütuna geçirilir ve eski sütun değerlerle
NULLgösterilir.
Şema gösterimi
Analiz deposunda, veritabanı hesabındaki tüm kapsayıcılar için geçerli olan iki şema gösterimi yöntemi vardır. Sorgu deneyiminin basitliği ile çok biçimli şemalar için daha kapsayıcı sütunlu bir gösterimin kolaylığı arasında dengeleri vardır.
- NoSQL ve Gremlin hesapları için API için varsayılan seçenek olan iyi tanımlanmış şema gösterimi.
- MongoDB hesapları için API için varsayılan seçenek olan tam uygunluk şeması gösterimi.
İyi tanımlanmış şema gösterimi
İyi tanımlanmış şema gösterimi, işlem deposunda şemadan bağımsız verilerin basit bir tablosal gösterimini oluşturur. İyi tanımlanmış şema gösteriminde aşağıdaki noktalar vardır:
- İlk belge temel şemayı tanımlar ve özelliklerin tüm belgelerde her zaman aynı türe sahip olması gerekir. Tek özel durumlar şunlardır:
- Azure Synapse'teki SQL sunucusuz havuzlar için:
NULL'dan herhangi başka bir veri türüne. Null olmayan ilk oluşum, sütun veri türünü tanımlar. null olmayan ilk veri türünü takip eden hiçbir belge analiz deposunda temsil edilmeyecektir. - Spark havuzları ve Azure Data Factory için Azure Synapse'te Veri Yakalama Değişikliği:
NULL'danINT'e. Azure Synapse'te Spark havuzları ve Azure Data Factory Değişiklik Veri Yakalama için null özelliklerden INT dışındaki veri türlerine geçiş desteklenmez. null olmayan ilk değer bir tamsayı olmalıdır ve farklı veri türüne sahip herhangi bir belge analiz deposunda temsil edilmeyecektir. -
floatdeğerindenintegerdeğerine. Tüm belgeler analiz deposunda gösterilir. -
integerdeğerindenfloatdeğerine. Tüm belgeler analiz deposunda gösterilir. Ancak bu verileri Azure Synapse SQL sunucusuz havuzlarıyla okumak için, sütunuvarcharöğesine dönüştürmek için BIR WITH yan tümcesi kullanmanız gerekir. Bu ilk dönüştürmeden sonra yeniden bir sayıya dönüştürmek mümkündür. Lütfen aşağıdaki örneği kontrol edin; burada sayı ilk değeri tamsayı, ikinci değer ise kayan değerdir.
- Azure Synapse'teki SQL sunucusuz havuzlar için:
SELECT CAST (num as float) as num
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
)
WITH (num varchar(100)) AS [IntToFloat]
Temel şema veri türünü izlemeyen özellikler analiz deposunda temsil edilmeyecektir. Örneğin, aşağıdaki belgeleri göz önünde bulundurun: ilki analiz deposu temel şemasını tanımlamıştı. özelliği
idbir dize olduğundan"2". Bu durumda analiz deposu, veri türünü"code"kapsayıcının kullanım ömrü için olarakintegerkaydeder. İkinci belge analiz deposuna dahil edilmeye"code"devam eder, ancak özelliği eklenmez.{"id": "1", "code":123}{"id": "2", "code": "123"}
Not
Yukarıdaki koşul özellikler için NULL geçerli değildir. Örneğin, {"a":123} and {"a":NULL} hala iyi tanımlanmıştır.
Not
Belgeyi "code" işlem deponuzdaki bir dizeye güncelleştirirseniz "1" yukarıdaki koşul değişmez. Şu anda şema sıfırlamayı desteklemediğimiz için analiz deposunda "code" olduğu gibi integer tutulacaktır.
- Dizi türleri tek bir yinelenen tür içermelidir. Örneğin,
{"a": ["str",12]}dizi tamsayı ve dize türlerinin bir karışımını içerdiğinden iyi tanımlanmış bir şema değildir.
Not
Azure Cosmos DB analiz deposu iyi tanımlanmış şema gösterimini izlerse ve yukarıdaki belirtim belirli öğeler tarafından ihlal edilirse, bu öğeler analiz deposuna dahil edilmez.
İyi tanımlanmış şemadaki farklı türlere göre farklı davranışlar bekleyebilirsiniz:
- Azure Synapse'teki Spark havuzları bu değerleri olarak
undefinedtemsil eder. - Azure Synapse'teki SQL sunucusuz havuzları bu değerleri olarak
NULLtemsil eder.
- Azure Synapse'teki Spark havuzları bu değerleri olarak
Açık
NULLdeğerlerle ilgili olarak farklı davranışlar bekleyebilirsiniz:- Azure Synapse'teki Spark havuzları bu değerleri
0(sıfır) veundefinedsütun null olmayan bir değere sahip olduğu anda okur. - Azure Synapse'teki SQL sunucusuz havuzları bu değerleri olarak
NULLokur.
- Azure Synapse'teki Spark havuzları bu değerleri
Eksik sütunlarda farklı davranışlar bekleyebilirsiniz:
- Azure Synapse'teki Spark havuzları bu sütunları olarak
undefinedtemsil edebilir. - Azure Synapse'teki SQL sunucusuz havuzları bu sütunları olarak
NULLtemsil edebilir.
- Azure Synapse'teki Spark havuzları bu sütunları olarak
Temsil zorluklarına geçici çözümler
Kapsayıcınızın analiz deposu temel şemasını oluşturmak için yanlış şemaya sahip eski bir belge kullanılmış olabilir. Yukarıda sunulan tüm kurallara bağlı olarak, Azure Synapse Link kullanarak analiz deponuzu sorgularken belirli özellikleri alıyor NULL olabilirsiniz. Temel şema sıfırlama şu anda desteklenmediğinden sorunlu belgeleri silmek veya güncelleştirmek yardımcı olmaz. Olası çözümler şunlardır:
- Verileri yeni bir kapsayıcıya geçirmek için tüm belgelerin doğru şemaya sahip olduğundan emin olun.
- Özelliği yanlış şemayla bırakmak ve tüm belgelerde doğru şemaya sahip başka bir ada sahip yeni bir ad eklemek için. Örnek: Orders kapsayıcısında durum özelliğinin bir dize olduğu milyarlarca belgeniz var. Ancak bu kapsayıcıdaki ilk belgenin durumu tamsayı ile tanımlanmıştır. Bu nedenle, bir belgenin durumu doğru şekilde gösterilir ve diğer tüm belgelerde olur
NULL. Status2 özelliğini tüm belgelere ekleyebilir ve özgün özellik yerine kullanmaya başlayabilirsiniz.
Tam uygunluk şeması gösterimi
Tam uygunluk şeması gösterimi, şemadan bağımsız işletim verilerindeki çok biçimli şemaların tamamını işlemek için tasarlanmıştır. Bu şema gösteriminde, iyi tanımlanmış şema kısıtlamaları (karma veri türü alanları veya karma veri türü dizileri değildir) ihlal edilmiş olsa bile analiz deposundan hiçbir öğe bırakılmaz.
Bu, işlemsel verilerin yaprak özelliklerinin JSON key-value çiftleri olarak analiz deposuna çevrilmesiyle elde edilir; burada veri türü ve key özellik içeriği olur value. Bu JSON nesne gösterimi belirsizliği olmayan sorgulara olanak tanır ve her veri türünü ayrı ayrı analiz edebilirsiniz.
Başka bir deyişle, tam uygunluk şeması gösteriminde, her belgenin her özelliğinin her veri türü bu özellik için bir key-valueJSON nesnesinde bir çift oluşturur. Her biri en fazla 1000 özellik sınırından biri olarak sayılır.
Örneğin, işlem deposunda aşağıdaki örnek belgeyi alalım:
{
name: "John Doe",
age: 32,
profession: "Doctor",
address: {
streetNo: 15850,
streetName: "NE 40th St.",
zip: 98052
},
salary: 1000000
}
İç içe nesne address , belgenin kök düzeyindeki bir özelliktir ve sütun olarak temsil edilir. Nesnedeki address her yaprak özelliği bir JSON nesnesi olarak temsil edilir: {"object":{"streetNo":{"int32":15850},"streetName":{"string":"NE 40th St."},"zip":{"int32":98052}}}.
İyi tanımlanmış şema gösteriminden farklı olarak, tam uygunluk yöntemi veri türlerinde çeşitleme sağlar. Yukarıdaki örneğin bu koleksiyonundaki bir sonraki belge bir dize olarak varsa streetNo , analiz deposunda olarak "streetNo":{"string":15850}temsil edilir. İyi tanımlanmış şema yönteminde temsil edilmeyecektir.
Tam uygunluk şeması için veri türleri eşlemesi
MongoDB veri türlerinin ve bunların analiz deposundaki gösterimlerinin tam uygunluk şeması gösteriminin bir haritası aşağıdadır. Aşağıdaki harita NoSQL API hesapları için geçerli değildir.
| Özgün veri türü | Sonek | Örnek |
|---|---|---|
| Çift | ".float64" | ₺24.99 |
| Dizi | ".dizi" | ["a", "b"] |
| İkilik | ".binary" | 0 |
| Boolean (Boole Mantığı) | ".bool" | Doğru |
| Int32 | ".int32" | 123 |
| Int64 | ".int64" | 255486129307 |
| null | ". NULL" | null |
| Dize | ".string" | "ABC" |
| Zaman damgası | .zamandamgasi | Zaman damgası(0, 0) |
| Nesne Kimliği | ".objectId" | ObjectId("5f3f7b59330ec25c132623a2") |
| Belge | ".object" | {"a": "a"} |
Açık
NULLdeğerlerle ilgili olarak farklı davranışlar bekleyebilirsiniz:- Azure Synapse'teki Spark havuzları bu değerleri (sıfır) olarak
0okur. - Azure Synapse'teki SQL sunucusuz havuzlar bu değerleri olarak
NULLokur.
- Azure Synapse'teki Spark havuzları bu değerleri (sıfır) olarak
Eksik sütunlarda farklı davranışlar bekleyebilirsiniz:
- Azure Synapse'teki Spark havuzları bu sütunları olarak
undefinedtemsil eder. - Azure Synapse'teki SQL sunucusuz havuzları bu sütunları olarak
NULLtemsil eder.
- Azure Synapse'teki Spark havuzları bu sütunları olarak
Değerlerle ilgili
timestampfarklı davranışlar bekleyebilirsiniz:- Azure Synapse'teki Spark havuzları bu değerleri ,
TimestampTypeveyaDateTypeolarakFloatokur. Aralığa ve zaman damgasının nasıl oluşturulduğuna bağlıdır. - Azure Synapse'teki SQL Sunucusuz havuzları bu değerleri ile arasında değişen
DATETIME20001-01-01olarak9999-12-31okur. Bu aralığın dışındaki değerler desteklenmez ve sorgularınız için yürütme hatasına neden olur. Bu sizin durumunuzsa şunları yapabilirsiniz:- Sütunu sorgudan kaldırın. Gösterimi korumak için, bu sütunu yansıtan ancak desteklenen aralık içinde yeni bir özellik oluşturabilirsiniz. Sorgularınızda da kullanabilirsiniz.
- Verileri desteklenen havuzlardan birinde yeni bir biçime dönüştürmek ve yüklemek için analiz deposundan Ru maliyeti olmadan Veri Yakalamayı Değiştir'i kullanın.
- Azure Synapse'teki Spark havuzları bu değerleri ,
Spark ile tam uygunluk şeması kullanma
Spark, bir içine DataFrameyüklenirken her veri türünü bir sütun olarak yönetir. Aşağıdaki belgeleri içeren bir koleksiyon olduğunu varsayalım.
{
"_id" : "1" ,
"item" : "Pizza",
"price" : 3.49,
"rating" : 3,
"timestamp" : 1604021952.6790195
},
{
"_id" : "2" ,
"item" : "Ice Cream",
"price" : 1.59,
"rating" : "4" ,
"timestamp" : "2022-11-11 10:00 AM"
}
İlk belge bir sayı ve rating utc biçiminde olsa timestamp da, ikinci belgede dize olarak ve rating bulunurtimestamp. Bu koleksiyonun herhangi bir veri dönüştürmesi olmadan içine DataFrame yüklendiğini varsayarsak, çıkışı df.printSchema() şöyle olur:
root
|-- _rid: string (nullable = true)
|-- _ts: long (nullable = true)
|-- id: string (nullable = true)
|-- _etag: string (nullable = true)
|-- _id: struct (nullable = true)
| |-- objectId: string (nullable = true)
|-- item: struct (nullable = true)
| |-- string: string (nullable = true)
|-- price: struct (nullable = true)
| |-- float64: double (nullable = true)
|-- rating: struct (nullable = true)
| |-- int32: integer (nullable = true)
| |-- string: string (nullable = true)
|-- timestamp: struct (nullable = true)
| |-- float64: double (nullable = true)
| |-- string: string (nullable = true)
|-- _partitionKey: struct (nullable = true)
| |-- string: string (nullable = true)
İyi tanımlanmış şema gösteriminde, ikinci belgenin her ikisi de ratingtimestamp temsil edilmeyecek. Tam uygunluk şemasında, her veri türünün her değerine tek tek erişmek için aşağıdaki örnekleri kullanabilirsiniz.
Aşağıdaki örnekte, bir toplama çalıştırmak için kullanabiliriz PySpark :
df.groupBy(df.item.string).sum().show()
Aşağıdaki örnekte, başka bir toplama çalıştırmak için kullanabiliriz PySQL :
df.createOrReplaceTempView("Pizza")
sql_results = spark.sql("SELECT sum(price.float64),count(*) FROM Pizza where timestamp.string is not null and item.string = 'Pizza'")
sql_results.show()
SQL ile tam uygunluk şeması kullanma
Yukarıdaki Spark örneğinin belgeleriyle aşağıdaki söz dizimi örneğini kullanabilirsiniz:
SELECT rating,timestamp_string,timestamp_utc
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) WITH (
rating integer '$.rating.int32',
timestamp varchar(50) '$.timestamp.string',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp is not null or timestamp_utc is not null
Verilerinizi işlemek için kullanarak cast veya başka bir T-SQL işlevi kullanarak convertdönüşümler uygulayabilirsiniz. Ayrıca görünümleri kullanarak karmaşık veri türü yapılarını gizleyebilirsiniz.
create view MyView as
SELECT MyRating=rating,MyTimestamp = convert(varchar(50),timestamp_utc)
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) (
rating integer '$.rating.int32',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp_utc is not null
union all
SELECT MyRating=convert(integer,rating_string),MyTimestamp = timestamp_string
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) WITH (
rating_string varchar(50) '$.rating.string',
timestamp_string varchar(50) '$.timestamp.string'
) as HTAP
WHERE timestamp_string is not null
MongoDB _id alanıyla çalışma
MongoDB _id alanı MongoDB'deki her koleksiyon için temeldir ve başlangıçta onaltılık bir temsile sahiptir. Yukarıdaki tabloda görebileceğiniz gibi, tam uygunluk şeması özelliklerini koruyarak Azure Synapse Analytics'te görselleştirmesi için bir zorluk oluşturur. Doğru görselleştirme için veri türünü aşağıdaki gibi dönüştürmeniz _id gerekir:
Spark'ta MongoDB _id alanıyla çalışma
Aşağıdaki örnek Spark 2.x ve 3.x sürümlerinde çalışır:
val df = spark.read.format("cosmos.olap").option("spark.synapse.linkedService", "xxxx").option("spark.cosmos.container", "xxxx").load()
val convertObjectId = udf((bytes: Array[Byte]) => {
val builder = new StringBuilder
for (b <- bytes) {
builder.append(String.format("%02x", Byte.box(b)))
}
builder.toString
}
)
val dfConverted = df.withColumn("objectId", col("_id.objectId")).withColumn("convertedObjectId", convertObjectId(col("_id.objectId"))).select("id", "objectId", "convertedObjectId")
display(dfConverted)
SQL'de MongoDB _id alanıyla çalışma
SELECT TOP 100 id=CAST(_id as VARBINARY(1000))
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
HTAP) WITH (_id VARCHAR(1000)) as HTAP
MongoDB id alanıyla çalışma
id MongoDB kapsayıcılarındaki özellik, analiz deposundaki "_id" özelliğinin Base64 gösterimiyle otomatik olarak geçersiz kılınır. "id" alanı MongoDB uygulamaları tarafından iç kullanıma yöneliktir. Şu anda tek geçici çözüm, "id" özelliğini "id" dışında bir değerle yeniden adlandırmaktır.
NoSQL veya Gremlin hesapları için API için tam uygunluk şeması
Azure Cosmos DB hesabında Synapse Link'i ilk kez etkinleştirirken şema türünü ayarlayarak, varsayılan seçenek yerine NoSQL hesapları için API için tam uygunluk Şemasını kullanmak mümkündür. Varsayılan şema gösterimi türünü değiştirmeyle ilgili dikkat edilmesi gerekenler şunlardır:
- Şu anda Azure portalını kullanarak NoSQL API hesabınızda Synapse Link'i etkinleştirirseniz, iyi tanımlanmış şema olarak etkinleştirilir.
- Şu anda, NoSQL veya Gremlin API hesaplarıyla tam uygunluk şeması kullanmak istiyorsanız, synapse Link'i hesap düzeyinde etkinleştirecek aynı CLI veya PowerShell komutunda hesap düzeyinde ayarlamanız gerekir.
- Şu anda MongoDB için Azure Cosmos DB, şema gösterimini değiştirme olasılığıyla uyumlu değildir. Tüm MongoDB hesapları tam uygunluk şeması gösterimi türüne sahiptir.
- Yukarıda bahsedilen Tam Uygunluk şeması veri türleri eşlemesi, JSON veri türlerini kullanan NoSQL API hesapları için geçerli değildir. Örnek
floatolarak veintegerdeğerler analiz deposunda olaraknumtemsil edilir. - Şema gösterimi türünü, iyi tanımlanmıştan tam uygunluk düzeyine (veya tam tersi) sıfırlamak mümkün değildir.
- Şu anda, synapse Link veritabanı hesabında etkinleştirilmemiş olsa bile kapsayıcı oluşturulduğunda analiz deposundaki kapsayıcı şemaları tanımlanır.
- Synapse Link etkinleştirilmeden önce oluşturulan kapsayıcılar veya grafikler, hesap düzeyinde tam uygunluk şemasıyla iyi tanımlanmış şemaya sahip olacaktır.
- Synapse Link etkinleştirildikten sonra hesap düzeyinde tam uygunluk şemasıyla oluşturulan kapsayıcılar veya grafikler tam uygunluk şemasına sahip olur.
Şema gösterimi türü kararı, Azure CLI veya PowerShell kullanılarak Synapse Link'in hesapta etkinleştirildiği anda yapılmalıdır.
Azure CLI ile:
az cosmosdb create --name MyCosmosDBDatabaseAccount --resource-group MyResourceGroup --subscription MySubscription --analytical-storage-schema-type "FullFidelity" --enable-analytical-storage true
Not
Yukarıdaki komutta, öğesini mevcut hesaplar için ile create değiştirinupdate.
PowerShell ile:
New-AzCosmosDBAccount -ResourceGroupName MyResourceGroup -Name MyCosmosDBDatabaseAccount -EnableAnalyticalStorage true -AnalyticalStorageSchemaType "FullFidelity"
Not
Yukarıdaki komutta, öğesini mevcut hesaplar için ile New-AzCosmosDBAccount değiştirinUpdate-AzCosmosDBAccount.
Analitik Yaşam Süresi (TTL)
Analitik TTL (ATTL), bir kapsayıcı için analiz deponuzda verilerin ne kadar süreyle saklanması gerektiğini gösterir.
ATTL ve NULLdışında 0 bir değerle ayarlandığında analiz deposu etkinleştirilir. Etkinleştirildiğinde işlemsel depodan analiz deposuna işlem TTL (TTTL) yapılandırmasından bağımsız olarak eklemeler, güncelleştirmeler, silmeler otomatik olarak eşitlenir. Bu işlem verilerinin analiz deposunda saklanması, kapsayıcı düzeyinde özelliği tarafından AnalyticalStoreTimeToLiveInSeconds denetlenebilir.
Olası ATTL yapılandırmaları şunlardır:
Değer olarak ayarlanırsa
0: analiz deposu devre dışı bırakılır ve işlem deposundan analiz deposuna hiçbir veri çoğaltılır. Kapsayıcılarınızdaki analiz deposunu devre dışı bırakmak için lütfen bir destek olayı açın.Alan atlanırsa hiçbir şey olmaz ve önceki değer korunur.
Değer olarak ayarlanırsa
-1: analiz deposu, verilerin işlem deposunda tutulmasından bağımsız olarak tüm geçmiş verilerini korur. Bu ayar analiz deposunun işletimsel verilerinizi sonsuz saklamaya sahip olduğunu gösterirDeğer herhangi bir pozitif tamsayı
nsayısına ayarlanırsa: öğelerin işlem deposundaki son değiştirme süresinden saniyeler sonra analiz deposundannsüresi dolar. İşlemsel verilerinizi işlem deposundaki verilerin tutulmasından bağımsız olarak analiz deposunda sınırlı bir süre saklamak istiyorsanız bu ayardan yararlanabilirsiniz
Dikkat edilmesi gereken bazı noktalar:
- Analiz deposu ATTL değeriyle etkinleştirildikten sonra daha sonra farklı bir geçerli değere güncelleştirilebilir.
- TTTL kapsayıcı veya öğe düzeyinde ayarlanabilirken, ATTL şu anda yalnızca kapsayıcı düzeyinde ayarlanabilir.
- ATTL >= TTTL'yi kapsayıcı düzeyinde ayarlayarak analiz deposunda operasyonel verilerinizin daha uzun süre saklanmasını sağlayabilirsiniz.
- Analiz deposu, ATTL = TTTL ayarıyla işlem deposunu yansıtmak için yapılabilir.
- TTTL'den büyük ATTL'niz varsa, belirli bir noktada yalnızca analiz deposunda bulunan verileriniz olur. Bu veriler salt okunur.
- Şu anda analiz deposundan veri silmiyoruz. ATTL'nizi herhangi bir pozitif tamsayıya ayarlarsanız, veriler sorgularınıza dahil olmaz ve bunun için faturalandırılamazsınız. Ancak ATTL'yi
-1olarak değiştirirseniz tüm veriler yeniden gösterilir ve tüm veri hacmi için faturalandırılmaya başlarsınız.
Bir kapsayıcıda analiz deposunu etkinleştirme:
Azure portalında, açık olduğunda ATTL seçeneği varsayılan -1 değerine ayarlanır. Veri Gezgini altındaki kapsayıcı ayarlarına giderek bu değeri 'n' saniye olarak değiştirebilirsiniz.
Azure Yönetim SDK'sı, Azure Cosmos DB SDK'ları, PowerShell veya Azure CLI'dan ATTL seçeneği -1 veya 'n' saniye olarak ayarlanarak etkinleştirilebilir.
Daha fazla bilgi edinmek için bkz . Kapsayıcıda analiz TTL'sini yapılandırma.
Geçmiş veriler üzerinde uygun maliyetli analiz
Veri katmanlama, farklı senaryolar için iyileştirilmiş depolama altyapıları arasında veri ayrımını ifade eder. Böylece uçtan uca veri yığınının genel performansını ve uygun maliyetliliğini geliştirin. Analiz deposu sayesinde Azure Cosmos DB artık farklı veri düzenleriyle işlem deposundan analiz deposuna verilerin otomatik olarak katmanlanması desteğine sahip. İşlem deposuna kıyasla depolama maliyeti açısından iyileştirilmiş analiz deposu sayesinde geçmiş analiz için çok daha uzun operasyonel veri ufuklarını korumanıza olanak tanır.
Analiz deposu etkinleştirildikten sonra, işlem iş yüklerinin veri saklama gereksinimlerine bağlı olarak, belirli bir zaman aralığından sonra kayıtların işlem deposundan otomatik olarak silinmesini sağlamak için özelliği yapılandırabilirsiniz transactional TTL . Benzer şekilde, analytical TTL analiz deposunda tutulan verilerin yaşam döngüsünü işlem deposundan bağımsız olarak yönetmenize olanak tanır. Analiz deposunu etkinleştirerek ve işlemsel ve analitik TTL özellikleri yapılandırarak, iki depo için veri saklama süresini sorunsuz bir şekilde katmanlayabilir ve tanımlayabilirsiniz.
Not
analytical TTL Değerden transactional TTL daha büyük bir değere ayarlandığında kapsayıcınızda yalnızca analiz deposunda bulunan veriler bulunur. Bu veriler salt okunurdur ve şu anda analiz deposunda belge düzeyini TTL desteklemiyoruz. Kapsayıcı verilerinizin gelecekte belirli bir noktada bir güncelleştirmeye veya silmeye ihtiyacı olabilirse, değerinden analytical TTLbüyük kullanmayıntransactional TTL. Bu özellik, gelecekte güncelleştirmelere veya silmelere gerek duymayacak veriler için önerilir.
Not
Senaryonuz fiziksel silmeleri talep etmiyorsa, mantıksal silme/güncelleştirme yaklaşımını benimseyebilirsiniz. İşlem deposuna, aynı belgenin yalnızca analiz deposunda bulunan ancak mantıksal silme/güncelleştirme gerektiren başka bir sürümünü ekleyin. Belki de süresi dolmuş bir belgenin silindiğini veya güncelleştirildiğini belirten bir bayrakla. Aynı belgenin her iki sürümü de analiz deposunda birlikte bulunur ve uygulamanız yalnızca sonuncuyu dikkate almalıdır.
Dayanıklılık
Analiz deposu Azure Depolama'ya dayanır ve fiziksel hatalara karşı aşağıdaki korumayı sunar:
- Varsayılan olarak, Azure Cosmos DB veritabanı hesapları analiz deposunu Yerel Olarak Yedekli Depolama (LRS) hesaplarında ayırır. LRS, belirli bir yıl boyunca nesnelerin en az %99,99999999999 (11 dokuz) dayanıklılığını sağlar.
- Veritabanı hesabının herhangi bir coğrafi bölgesi alanlar arası yedeklilik için yapılandırılmışsa, alanlar arası yedekli Depolama (ZRS) hesaplarında ayrılır. Azure Cosmos DB veritabanı hesabının bir bölgesinde Kullanılabilirlik Alanları etkinleştirmeniz ve bu bölgenin analitik verilerinin Alanlar arası yedekli Depolama'da depolanması gerekir. ZRS, belirli bir yıl boyunca en az %99,99999999999 (12 9) depolama kaynakları için dayanıklılık sunar.
Azure Depolama dayanıklılığı hakkında daha fazla bilgi için bu bağlantıya bakın .
Yedekleme
Analiz deposunda fiziksel hatalara karşı yerleşik koruma olsa da, işlem deposunda yanlışlıkla silmeler veya güncelleştirmeler için yedekleme gerekebilir. Bu gibi durumlarda, bir kapsayıcıyı geri yükleyebilir ve geri yüklenen kapsayıcıyı kullanarak özgün kapsayıcıdaki verileri yedekleyebilir veya gerekirse analiz deposunu tamamen yeniden oluşturabilirsiniz.
Not
Şu anda analiz deposu yedeklenmediğinden geri yüklenemez. Yedekleme ilkeniz buna bağlı olarak planlanamaz.
Synapse Link ve sonuç olarak analiz deposu, Azure Cosmos DB yedekleme modlarıyla farklı uyumluluk düzeylerine sahiptir:
- Düzenli yedekleme modu Synapse Link ile tamamen uyumludur ve bu 2 özellik aynı veritabanı hesabında kullanılabilir.
- Sürekli yedekleme modunu kullanan veritabanı hesapları için Synapse Link GA'dır.
- Synapse Link özellikli hesaplar için sürekli yedekleme modu genel önizleme aşamasındadır. Şu anda Cosmos DB hesabındaki koleksiyonlarınızdan herhangi birinde Synapse Link'i devre dışı bırakdıysanız sürekli yedeklemeye geçiş yapamazsınız.
Yedekleme ilkeleri
İki olası yedekleme ilkesi vardır ve bunların nasıl kullanılacağını anlamak için Azure Cosmos DB yedeklemeleri hakkında aşağıdaki ayrıntılar çok önemlidir:
- Özgün kapsayıcı her iki yedekleme modunda analiz deposu olmadan geri yüklenir.
- Azure Cosmos DB, bir geri yüklemeden üzerine yazan kapsayıcıları desteklemez.
Şimdi analiz deposu perspektifinden yedekleme ve geri yüklemelerin nasıl kullanılacağını görelim.
TTTL >= ATTL ile kapsayıcıyı geri yükleme
değerinden eşit veya daha transactional TTLbüyük olduğunda analytical TTL analiz deposundaki tüm veriler işlem deposunda hala var olur. Geri yükleme durumunda iki olası durumunuz vardır:
- Geri yüklenen kapsayıcıyı özgün kapsayıcının yerine kullanmak için. Analiz deposunu yeniden derlemek için Synapse Link'i hesap düzeyinde ve kapsayıcı düzeyinde etkinleştirmeniz yeter.
- Geri yüklenen kapsayıcıyı veri kaynağı olarak kullanarak özgün kapsayıcıdaki verileri doldurmak veya güncelleştirmek için. Bu durumda analiz deposu otomatik olarak veri işlemlerini yansıtır.
TTTL < ATTL ile kapsayıcıyı geri yükleme
değerinden transactional TTLküçük olduğundaanalytical TTL, bazı veriler yalnızca analiz deposunda bulunur ve geri yüklenen kapsayıcıda olmaz. Yine iki olası durumla karşınıza geçecektir:
- Geri yüklenen kapsayıcıyı özgün kapsayıcının yerine kullanmak için. Bu durumda Synapse Link'i kapsayıcı düzeyinde etkinleştirdiğinizde, yeni analiz deposuna yalnızca işlem deposundaki veriler eklenir. Ancak özgün kapsayıcının analiz deposunun, özgün kapsayıcı mevcut olduğu sürece sorgular için kullanılabilir durumda kaldığını lütfen unutmayın. Her ikisini de sorgulamak için uygulamanızı değiştirmek isteyebilirsiniz.
- Geri yüklenen kapsayıcıyı veri kaynağı olarak kullanarak özgün kapsayıcıdaki verileri doldurmak veya güncelleştirmek için:
- Analiz deposu, işlem deposundaki verilerin veri işlemlerini otomatik olarak yansıtır.
- nedeniyle
transactional TTLdaha önce işlem deposundan kaldırılan verileri yeniden eklerseniz, bu veriler analiz deposunda yinelenir.
Örnek:
- Kapsayıcının
OnlineOrdersTTTL değeri bir ay, ATTL ise bir yıl olarak ayarlanmıştır. - Bunu öğesine
OnlineOrdersNewgeri yükleyip analiz deposunu yeniden derlemek için açtığınızda, hem işlem deposunda hem de analiz deposunda yalnızca bir aylık veri olur. - Özgün kapsayıcı
OnlineOrderssilinmez ve analiz deposu hala kullanılabilir durumdadır. - Yeni veriler yalnızca içine
OnlineOrdersNewalınır. - Analiz sorguları analiz depolarından UNION ALL işlemi yaparken özgün veriler hala uygun olacaktır.
Özgün kapsayıcıyı silmek istiyor ancak analiz deposu verilerini kaybetmek istemiyorsanız, özgün kapsayıcının analiz deposunu başka bir Azure veri hizmetinde kalıcı hale gelebilirsiniz. Synapse Analytics, farklı konumlarda depolanan veriler arasında birleştirme gerçekleştirme özelliğine sahiptir. Örnek: Synapse Analytics sorgusu analiz deposu verilerini Azure Blob Depolama, Azure Data Lake Store gibi dış tablolarla birleştirir.
Analiz deposundaki verilerin işlem deposundaki şemadan farklı bir şemaya sahip olduğunu unutmayın. Analiz deposu verilerinizin anlık görüntülerini oluşturup herhangi bir Azure Veri hizmetine aktarabilirsiniz ancak ru maliyeti olmadan işlem deposunu geri beslemek için bu anlık görüntünün kullanılmasını garanti edebiliriz. Bu işlem desteklenmez.
Genel dağıtım
Genel olarak dağıtılmış bir Azure Cosmos DB hesabınız varsa, bir kapsayıcı için analiz deposunu etkinleştirdikten sonra bu hesabın tüm bölgelerinde kullanılabilir. İşletimsel verilerde yapılan tüm değişiklikler tüm bölgelerde genel olarak çoğaltılır. Azure Cosmos DB'de verilerinizin en yakın bölgesel kopyasında analitik sorguları etkili bir şekilde çalıştırabilirsiniz.
Bölümleme
Analiz deposu bölümleme işlemi, işlem deposundaki bölümlemeden tamamen bağımsızdır. Varsayılan olarak analiz deposundaki veriler bölümlenmez. Analiz sorgularınızın sık kullanılan filtreleri varsa, daha iyi sorgu performansı için bu alanları temel alarak bölümleme seçeneğiniz vardır. Daha fazla bilgi edinmek için bkz . Özel bölümlemeye giriş ve özel bölümlemeyi yapılandırma.
Güvenlik
Analiz deposuyla kimlik doğrulaması - Desteklenen kimlik doğrulama yöntemleri, ağ özelliklerinin etkinleştirilip etkinleştirilmediğine bağlı olarak değişir.
Anahtar tabanlı kimlik doğrulaması: Bu senaryo, Özel Uç Noktaları veya sanal ağ etkin olmayanlar da dahil olmak üzere tüm senaryolardaki tüm hesaplar için desteklenir.
Hizmet Sorumlusu veya Yönetilen Kimlik: Entra Kimliği veya yönetilen kimlik kimlik doğrulamasının kullanılması yalnızca Özel Uç Noktaları kullanmayan veya sanal ağ erişimini etkinleştirmeyen hesaplar için desteklenir. Bu kimlik doğrulama türünü kullanmak için kullanıcıların veri düzlemi RBAC uygulaması ve aşağıdaki veri eylemleriyle yeni bir salt okunur rol oluşturması gerekir.
- PowerShell kullanarak özel bir MyAnalyticsReadOnlyRole ekleyin ve "readMetadata" ve "readAnalytics" RBAC eylemlerini Rol'e eşleştirin.
$resourceGroupName = "<myResourceGroup>" $accountName = "<myCosmosAccount>" New-AzCosmosDBSqlRoleDefinition -AccountName $accountName ` -ResourceGroupName $resourceGroupName ` -Type CustomRole -RoleName 'MyAnalyticsReadOnlyRole' ` -DataAction @( ` 'Microsoft.DocumentDB/databaseAccounts/readMetadata', 'Microsoft.DocumentDB/databaseAccounts/readAnalytics' ) ` -AssignableScope "/"- Yeni rol tanımı kimliğini almak için hesabın rol tanımlarını listeleyin.
$roleDefinitionId = Get-AzCosmosDBSqlRoleDefinition -AccountName $accountName ` -ResourceGroupName $resourceGroupName- Yeni rolü Synapse MSI Sorumlusuna atayarak rol atamasını oluşturun.
$synapsePrincipalId = "<Synapse MSI Principal>" New-AzCosmosDBSqlRoleAssignment -AccountName $accountName ` -ResourceGroupName $resourceGroupName ` -RoleDefinitionId $readOnlyRoleDefinitionId ` -Scope "/" ` -PrincipalId $synapsePrincipalId
Özel uç noktaları kullanarak ağ yalıtımı - İşlem ve analiz depolarındaki verilere ağ erişimini bağımsız olarak denetleyebilirsiniz. Ağ yalıtımı, Azure Synapse çalışma alanlarındaki yönetilen sanal ağlar içinde her depo için ayrı yönetilen özel uç noktalar kullanılarak gerçekleştirilir. Daha fazla bilgi edinmek için Analiz deposu için özel uç noktaları yapılandırma makalesine bakın. Not: Bunu etkinleştirirken anahtar tabanlı kimlik doğrulaması kullanmanız gerekir. Önceki bölüme bakın.
Bekleyen veri şifrelemesi - Analiz deposu şifrelemeniz varsayılan olarak etkindir.
Müşteri tarafından yönetilen anahtarlarla veri şifreleme - Aynı müşteri tarafından yönetilen anahtarları otomatik ve saydam bir şekilde kullanarak işlem ve analiz depolarında verileri sorunsuz bir şekilde şifreleyebilirsiniz. Azure Synapse Link yalnızca Azure Cosmos DB hesabınızın yönetilen kimliğini kullanarak müşteri tarafından yönetilen anahtarları yapılandırmayı destekler. Hesabınızda Azure Synapse Link'i etkinleştirmeden önce Azure Key Vault erişim ilkenizde hesabınızın yönetilen kimliğini yapılandırmanız gerekir. Daha fazla bilgi edinmek için Azure Cosmos DB hesaplarının yönetilen kimliklerini kullanarak müşteri tarafından yönetilen anahtarları yapılandırma makalesine bakın.
Not
Veritabanı hesabınızı Birinci Taraf yerine Sistem veya Kullanıcı Tarafından Atanan Kimlik olarak değiştirir ve veritabanı hesabınızda Azure Synapse Link'i etkinleştirirseniz, veritabanı hesabınızdan Synapse Link'i devre dışı bırakamadığınızdan Birinci Taraf kimliğine geri dönemezsiniz.
Birden çok Azure Synapse Analytics çalışma zamanı desteği
Analiz deposu, işlem çalışma sürelerine bağımlılık olmadan analitik iş yükleri için ölçeklenebilirlik, esneklik ve performans sağlayacak şekilde iyileştirilmiştir. Depolama teknolojisi, analiz iş yüklerinizi el ile çalışmadan iyileştirmek için kendi kendine yönetilir.
Azure Cosmos DB analiz deposundaki veriler, Azure Synapse Analytics tarafından desteklenen farklı analiz çalışma zamanlarından aynı anda sorgulanabilir. Azure Synapse Analytics, Azure Cosmos DB analiz deposu ile Apache Spark ve sunucusuz SQL havuzunu destekler.
Not
Analiz deposundan yalnızca Azure Synapse Analytics çalışma zamanlarını kullanarak okuyabilirsiniz. Tam tersi de geçerlidir. Azure Synapse Analytics çalışma zamanları yalnızca analiz deposundan okuyabilir. Analiz deposundaki verileri yalnızca otomatik eşitleme işlemi değiştirebilir. Yerleşik Azure Cosmos DB OLTP SDK'sını kullanarak Azure Synapse Analytics Spark havuzunu kullanarak Verileri Azure Cosmos DB işlem deposuna geri yazabilirsiniz.
Fiyatlandırma
Analiz deposu, aşağıdakiler için ücretlendirildiğiniz tüketim tabanlı fiyatlandırma modelini izler:
Depolama: Analiz TTL tarafından tanımlanan geçmiş veriler de dahil olmak üzere her ay analiz deposunda tutulan verilerin hacmi.
Analitik yazma işlemleri: İşlemsel veri güncelleştirmelerinin işlem deposundan analiz deposuna tam olarak yönetilen eşitlemesi (otomatik eşitleme)
Analitik okuma işlemleri: Azure Synapse Analytics Spark havuzundan ve sunucusuz SQL havuzu çalışma sürelerinden analiz deposuna karşı gerçekleştirilen okuma işlemleri.
Analiz deposu fiyatlandırması, işlem deposu fiyatlandırma modelinden ayrıdır. Analiz deposunda sağlanan RU kavramı yoktur. Analiz deposu fiyatlandırma modeliyle ilgili tüm ayrıntılar için bkz . Azure Cosmos DB fiyatlandırma sayfası .
Analiz deposundaki verilere yalnızca Azure Synapse Analytics çalışma zamanlarında yapılan Azure Synapse Link üzerinden erişilebilir: Azure Synapse Apache Spark havuzları ve Azure Synapse sunucusuz SQL havuzları. Analiz deposundaki verilere erişmek için fiyatlandırma modeliyle ilgili tüm ayrıntılar için Bkz . Azure Synapse Analytics fiyatlandırma sayfası .
Analiz deposu perspektifinden, Bir Azure Cosmos DB kapsayıcısında analiz deposunu etkinleştirmek üzere üst düzey maliyet tahmini elde etmek için Azure Cosmos DB Kapasite planlayıcısını kullanabilir ve analiz depolama ve yazma işlemleri maliyetlerinizle ilgili bir tahmin alabilirsiniz.
Analiz iş yükünüzün bir işlevi olduğundan analiz deposu okuma işlemleri tahminleri Azure Cosmos DB maliyet hesaplayıcısına dahil değildir. Ancak üst düzey bir tahmin olarak analiz deposundaki 1 TB verinin taranmasının sonucunda genellikle 130.000 analitik okuma işlemi yapılır ve 0,065 ABD doları maliyet elde edilebilir. Örneğin, 1 TB'lık bu taramayı gerçekleştirmek için Azure Synapse sunucusuz SQL havuzları kullanırsanız, Azure Synapse Analytics fiyatlandırma sayfasına göre 5,00 ABD doları ücrete mal olur. Bu 1 TB taramanın toplam maliyeti 5,065 ABD doları olacaktır.
Yukarıdaki tahmin analiz deposundaki 1 TB'lık verileri taramak için olsa da, filtrelerin uygulanması taranan veri hacmini azaltır ve bu, tüketim fiyatlandırma modeline göre analiz okuma işlemlerinin tam sayısını belirler. Analitik iş yüküyle ilgili kavram kanıtı, analiz okuma işlemleri için daha ayrıntılı bir tahmin sağlar. Bu tahmin, Azure Synapse Analytics maliyetini içermez.
Sonraki adımlar
Daha fazla bilgi edinmek için aşağıdaki belgelere bakın:
Azure Synapse Analytics kullanarak karma işlem ve analitik işleme tasarlama hakkında eğitim modülünü gözden geçirin
Azure Cosmos DB için Azure Synapse Link'i kullanmaya başlama
Azure Cosmos DB için Synapse Link hakkında sık sorulan sorular