Apache Cassandra için Azure Cosmos DB'de bölümleme
ŞUNLAR IÇIN GEÇERLIDIR: ![]() Cassandra
Cassandra
Bu makalede Apache Cassandra için Azure Cosmos DB'de bölümlemenin nasıl çalıştığı açıklanmaktadır.
Cassandra için API, uygulamanızın performans gereksinimlerini karşılamak üzere tek tek tabloları bir anahtar alanında ölçeklendirmek için bölümleme kullanır. Bölümler, bir tablodaki her kayıtla ilişkili bir bölüm anahtarının değerine göre oluşturulur. Bir bölümdeki tüm kayıtlar aynı bölüm anahtarı değerine sahiptir. Azure Cosmos DB, tablonun ölçeklenebilirlik ve performans gereksinimlerini verimli bir şekilde karşılamak için fiziksel kaynaklar genelinde bölümlerin yerleştirilmesini saydam ve otomatik olarak yönetir. Bir uygulamanın aktarım hızı ve depolama gereksinimleri arttıkça Azure Cosmos DB, verileri daha fazla sayıda fiziksel makine arasında taşır ve dengeler.
Geliştirici açısından bakıldığında bölümleme, Apache Cassandra için Azure Cosmos DB için yerel Apache Cassandra ile aynı şekilde davranır. Ancak, arka planda bazı farklılıklar vardır.
Apache Cassandra ile Azure Cosmos DB arasındaki farklar
Azure Cosmos DB'de bölümlerin depolandığı her makine fiziksel bölüm olarak adlandırılır. Fiziksel bölüm bir Sanal Makineye benzilir; ayrılmış bir işlem birimi veya fiziksel kaynak kümesi. Bu işlem biriminde depolanan her bölüm, Azure Cosmos DB'de mantıksal bölüm olarak adlandırılır. Apache Cassandra'yı zaten biliyorsanız, mantıksal bölümleri Cassandra'daki normal bölümler gibi düşünebilirsiniz.
Apache Cassandra, bir bölümde depolanabilecek verilerin boyutu üzerinde 100 MB'lık bir sınır önerir. Azure Cosmos DB için Cassandra API'si mantıksal bölüm başına 20 GB'a kadar ve fiziksel bölüm başına 30 GB'a kadar veri sağlar. Azure Cosmos DB'de, Apache Cassandra'dan farklı olarak fiziksel bölümde kullanılabilen işlem kapasitesi istek birimleri olarak adlandırılan tek bir ölçüm kullanılarak ifade edilir ve bu sayede iş yükünüzü çekirdek, bellek veya IOPS yerine saniye başına istek (okuma veya yazma) açısından düşünebilirsiniz. Bu, her isteğin maliyetini anladıktan sonra kapasite planlamasının daha açık bir şekilde yapılmasına neden olabilir. Her fiziksel bölümde en fazla 10000 RU işlem kullanılabilir. Cassandra için API'de elastik ölçekle ilgili makalemizi okuyarak ölçeklenebilirlik seçenekleri hakkında daha fazla bilgi edinebilirsiniz.
Azure Cosmos DB'de her fiziksel bölüm, bölüm başına en az 4 çoğaltma içeren çoğaltma kümeleri olarak da bilinen bir çoğaltma kümesinden oluşur. Bu, 1 çoğaltma faktörü ayarlamanın mümkün olduğu Apache Cassandra'nın aksinedir. Ancak bu, veri içeren tek düğümün kapanması durumunda düşük kullanılabilirliğe yol açar. Cassandra için API'de her zaman 4 çoğaltma faktörü vardır (çekirdek 3). Azure Cosmos DB çoğaltma kümelerini otomatik olarak yönetirken, bunların Apache Cassandra'daki çeşitli araçlar kullanılarak korunması gerekir.
Apache Cassandra,bölüm anahtarlarının karmaları olan belirteç kavramına sahiptir. Belirteçler, -2^63 ile -2^63 - 1 arasında değerler içeren bir murmur3 64 bayt karması temel alır. Bu aralık genellikle Apache Cassandra'da "belirteç halkası" olarak adlandırılır. Belirteç halkası belirteç aralıklarına dağıtılır ve bu aralıklar yerel apache Cassandra kümesinde bulunan düğümler arasında bölünür. Azure Cosmos DB için bölümleme, farklı bir karma algoritması kullanması ve daha büyük bir iç belirteç halkası olması dışında benzer bir şekilde uygulanır. Ancak, dışarıdan Apache Cassandra ile aynı belirteç aralığını kullanıma sunarız; örneğin- -2^63 - -2^63 - 1.
Birincil anahtar
Cassandra için API'deki tüm tablolarda tanımlı bir primary key tablo olmalıdır. Birincil anahtarın söz dizimi aşağıda gösterilmiştir:
column_name cql_type_definition PRIMARY KEY
Farklı kullanıcıların iletilerini depolayan bir kullanıcı tablosu oluşturmak istediğimizi varsayalım:
CREATE TABLE uprofile.user (
id UUID PRIMARY KEY,
user text,
message text);
Bu tasarımda, alanı birincil anahtar olarak tanımladık id . Birincil anahtar, tablodaki kaydın tanımlayıcısı olarak çalışır ve Azure Cosmos DB'de bölüm anahtarı olarak da kullanılır. Birincil anahtar daha önce açıklanan şekilde tanımlanmışsa, her bölümde yalnızca tek bir kayıt olacaktır. Bu, veritabanına veri yazarken mükemmel yatay ve ölçeklenebilir bir dağıtıma neden olur ve anahtar-değer arama kullanım örnekleri için idealdir. Uygulama, okuma performansını en üst düzeye çıkarmak için tablodan veri okurken birincil anahtarı sağlamalıdır.
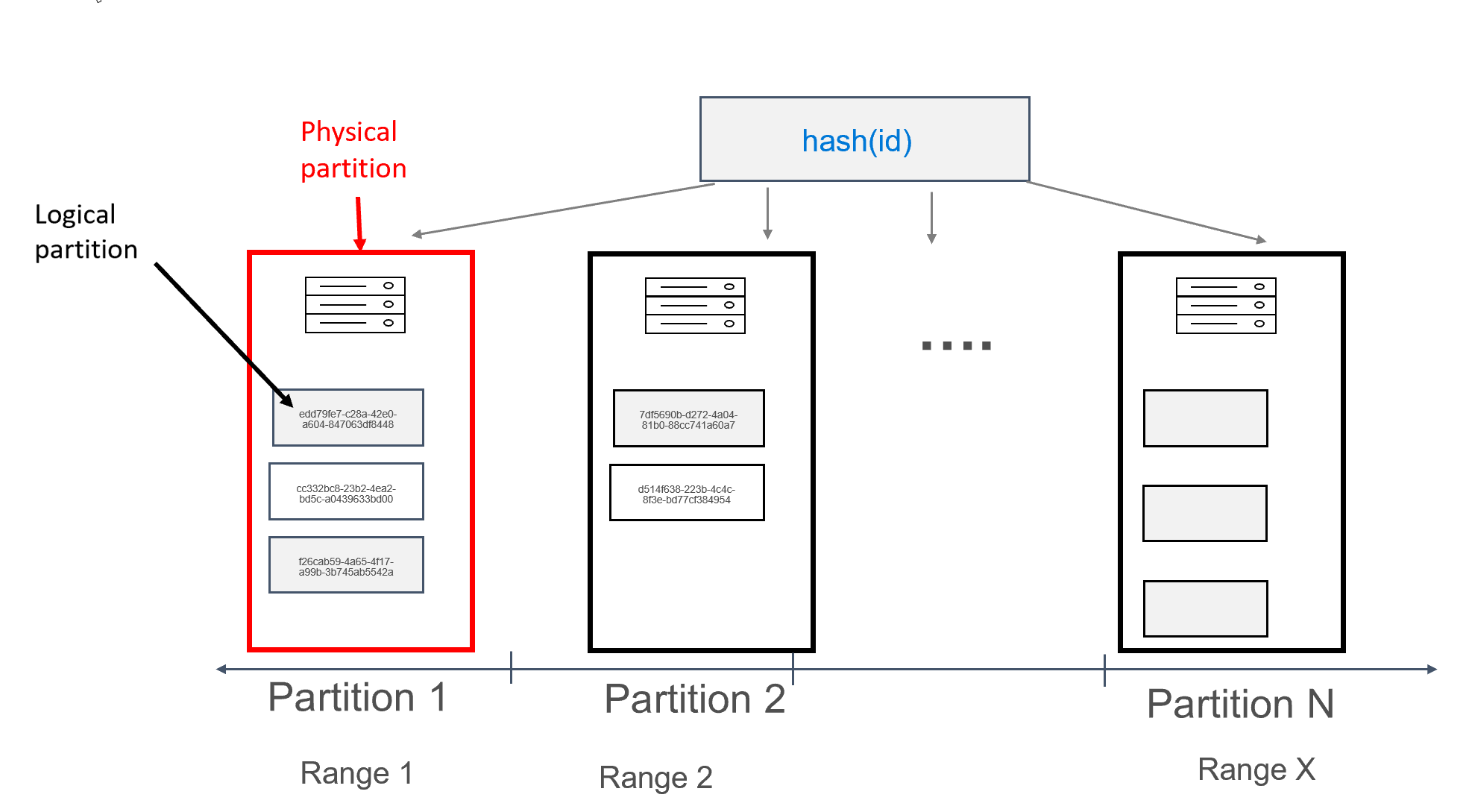
Bileşik birincil anahtar
Apache Cassandra'nın da bir kavramı compound keysvardır. Bileşik primary key birden fazla sütundan oluşur; ilk sütun , partition keyve ek sütunlar ise olur clustering keys. için söz dizimi compound primary key aşağıda gösterilmiştir:
PRIMARY KEY (partition_key_column_name, clustering_column_name [, ...])
Yukarıdaki tasarımı değiştirmek ve belirli bir kullanıcı için iletileri verimli bir şekilde almayı mümkün kılmak istediğimizi varsayalım:
CREATE TABLE uprofile.user (
user text,
id int,
message text,
PRIMARY KEY (user, id));
Bu tasarımda şimdi bölüm anahtarı olarak ve id kümeleme anahtarı olarak tanımlıyoruzuser. İstediğiniz kadar kümeleme anahtarı tanımlayabilirsiniz, ancak aynı bölüme birden çok kaydın eklenmesine neden olmak için kümeleme anahtarı için her değerin (veya değerlerin birleşiminin) benzersiz olması gerekir, örneğin:
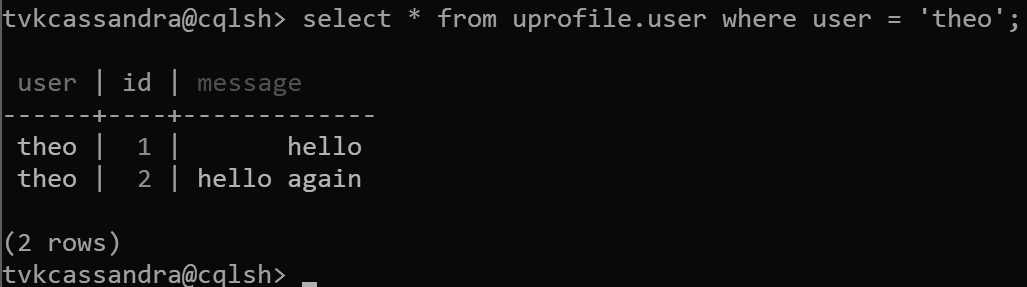
insert into uprofile.user (user, id, message) values ('theo', 1, 'hello');
insert into uprofile.user (user, id, message) values ('theo', 2, 'hello again');
Veriler döndürülürken, Apache Cassandra'da beklendiği gibi kümeleme anahtarına göre sıralanır:
Uyarı
Bileşik birincil anahtarı olan bir tablodaki verileri sorgularken, kümeleme anahtarı dışında bölüm anahtarına ve dizine eklenmemiş diğer alanlara filtre uygulamak istiyorsanız, bölüm anahtarına açıkça ikincil dizin eklediğinizden emin olun:
CREATE INDEX ON uprofile.user (user);
Apache Cassandra için Azure Cosmos DB, bölüm anahtarları için dizinleri varsayılan olarak uygulamaz ve bu senaryodaki dizin sorgu performansını önemli ölçüde artırabilir. Daha fazla bilgi için ikincil dizin oluşturma makalemizi gözden geçirin.
Veriler bu şekilde modellenmişken, her bölüme kullanıcıya göre gruplandırılmış birden çok kayıt atanabilir. Bu nedenle, belirli bir kullanıcının tüm iletilerini almak için (bu örnekte) usertarafından partition key verimli bir şekilde yönlendirilen bir sorgu verebiliriz.
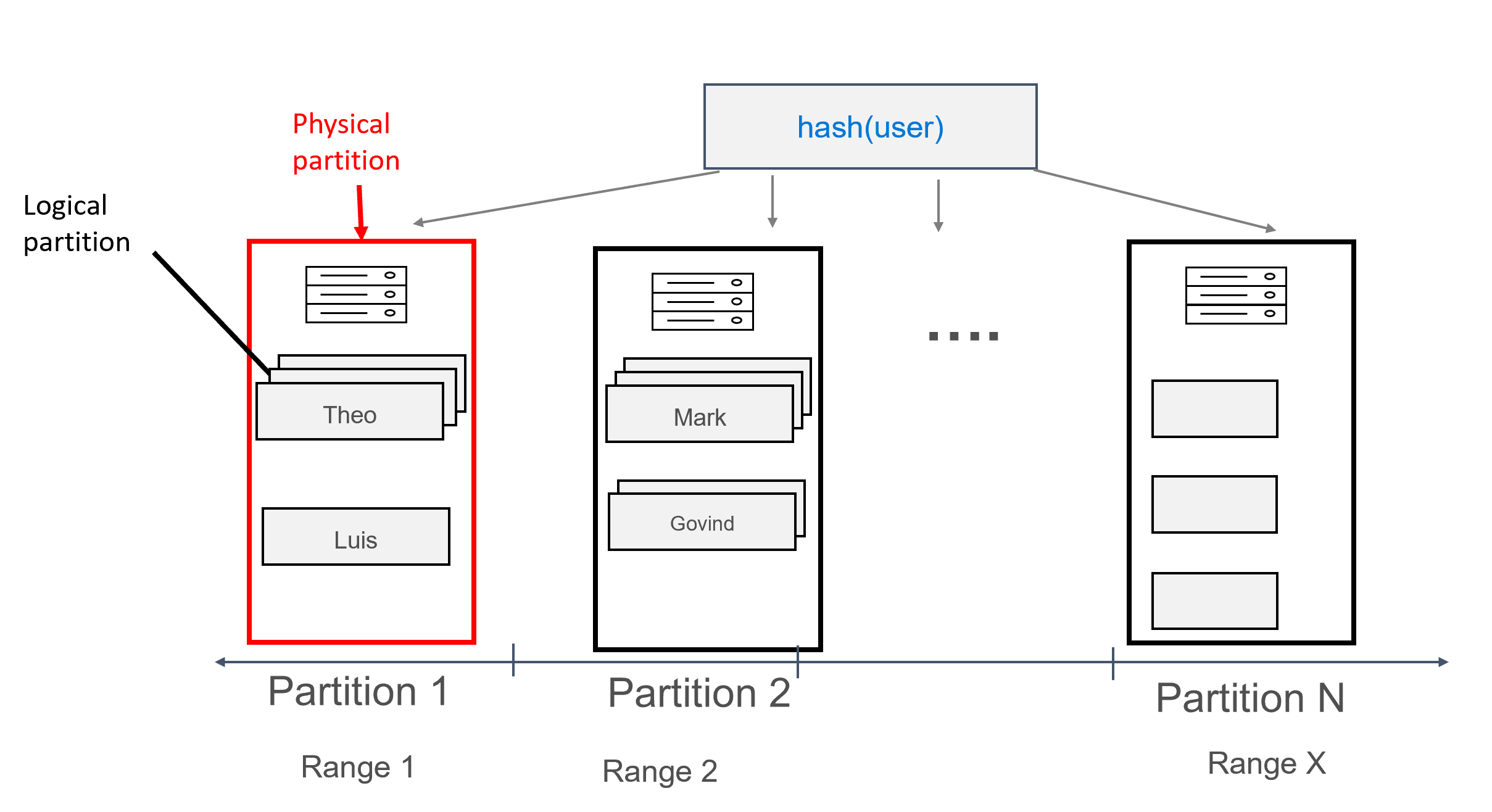
Bileşik bölüm anahtarı
Bileşik bölüm anahtarları, bileşik anahtarlar ile temelde aynı şekilde çalışır, ancak bileşik bölüm anahtarı olarak birden çok sütun belirtebilirsiniz. Bileşik bölüm anahtarlarının söz dizimi aşağıda gösterilmiştir:
PRIMARY KEY (
(partition_key_column_name[, ...]),
clustering_column_name [, ...]);
Örneğin, benzersiz ve bileşiminin firstname bölüm anahtarını oluşturacağı ve lastname id kümeleme anahtarı olduğu aşağıdakilere sahip olabilirsiniz:
CREATE TABLE uprofile.user (
firstname text,
lastname text,
id int,
message text,
PRIMARY KEY ((firstname, lastname), id) );
Sonraki adımlar
- Azure Cosmos DB'de bölümleme ve yatay ölçeklendirme hakkında bilgi edinin.
- Azure Cosmos DB'de sağlanan aktarım hızı hakkında bilgi edinin.
- Azure Cosmos DB'de genel dağıtım hakkında bilgi edinin.
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin