Azure Databricks kullanarak MongoDB'den MongoDB için Azure Cosmos DB hesabına veri geçirme
ŞUNLAR IÇIN GEÇERLIDIR: ![]() MongoDB
MongoDB
Bu geçiş kılavuzu, veritabanlarını MongoDB'den MongoDB için Azure Cosmos DB API'sine geçirme serisinin bir parçasıdır. Kritik geçiş adımları aşağıda gösterildiği gibi geçiş öncesi, geçiş ve geçiş sonrası adımlarıdır.
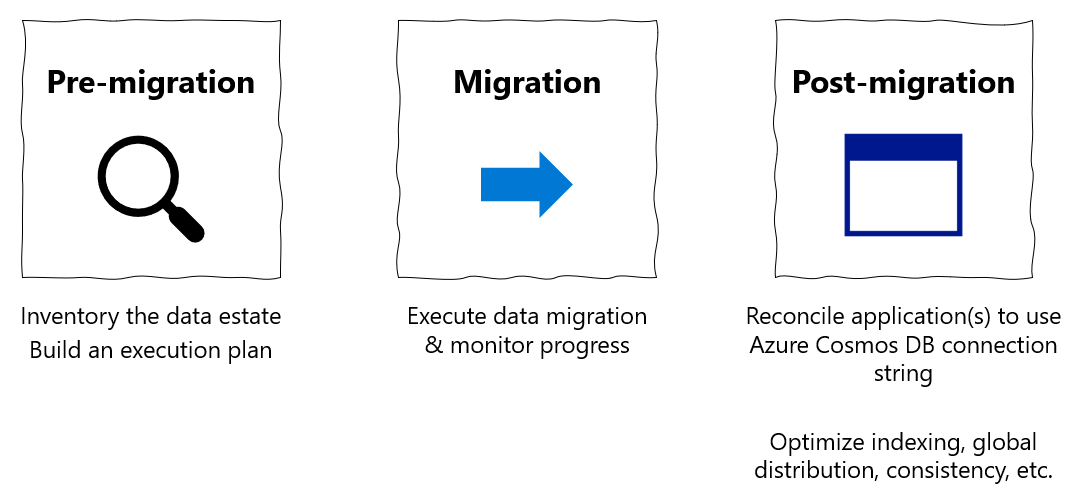
Azure Databricks kullanarak veri geçişi
Azure Databricks, Apache Spark için sunulan bir hizmet olarak platform (PaaS) teklifidir. Büyük ölçekli bir veri kümesinde çevrimdışı geçişler yapmak için bir yol sunar. Veritabanlarının MongoDB'den MongoDB için Azure Cosmos DB'ye çevrimdışı geçişini yapmak için Azure Databricks'i kullanabilirsiniz.
Bu öğreticide şunların nasıl yapıldığını öğrenirsiniz:
Azure Databricks kümesi sağlama
Bağımlılık ekleme
Scala veya Python not defteri oluşturma ve çalıştırma
Geçiş performansını iyileştirme
Geçiş sırasında gözlemlenebilen hız sınırlama hatalarını giderme
Önkoşullar
Bu öğreticiyi tamamlamak için aşağıdakileri yapmanız gerekir:
- Aktarım hızını tahmin etme ve parça anahtarı seçme gibi geçiş öncesi adımları tamamlayın.
- MongoDB için Azure Cosmos DB hesabı oluşturun.
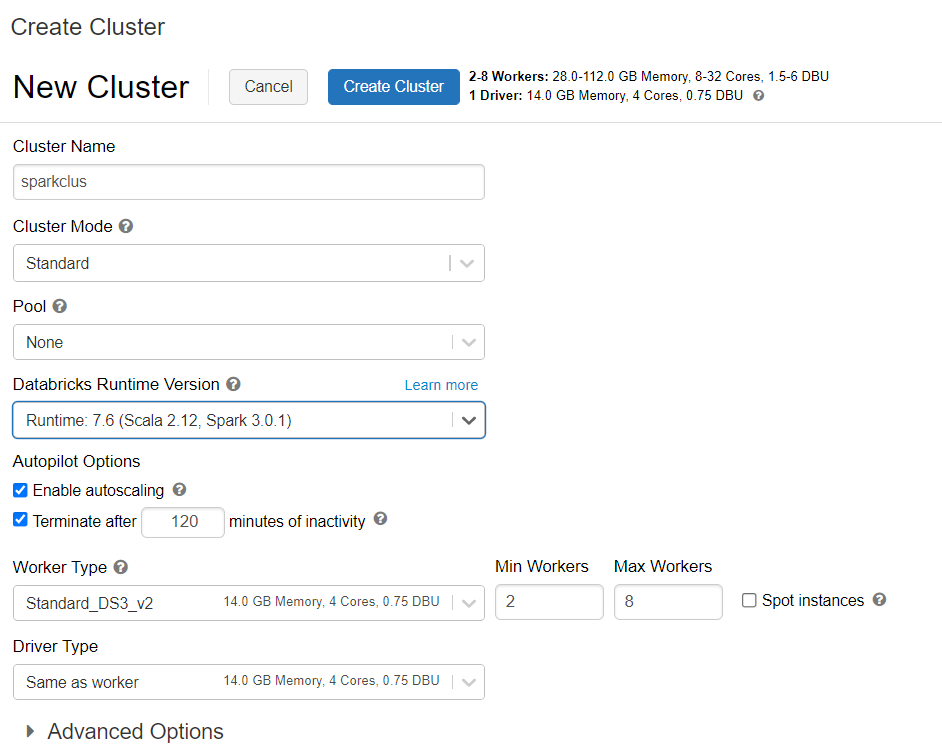
Azure Databricks kümesi sağlama
Azure Databricks kümesi sağlamak için yönergeleri izleyebilirsiniz. Spark 3.0'ı destekleyen Databricks çalışma zamanı sürüm 7.6'yı seçmenizi öneririz.
Bağımlılık ekleme
Hem yerel MongoDB hem de MongoDB için Azure Cosmos DB uç noktalarına bağlanmak üzere kümenize Spark kitaplığı için MongoDB Bağlan veya ekleyin. Kümenizde Kitaplıklar>Yeni Maven Yükle'yi>seçin ve ardından Maven koordinatları ekleyin.org.mongodb.spark:mongo-spark-connector_2.12:3.0.1
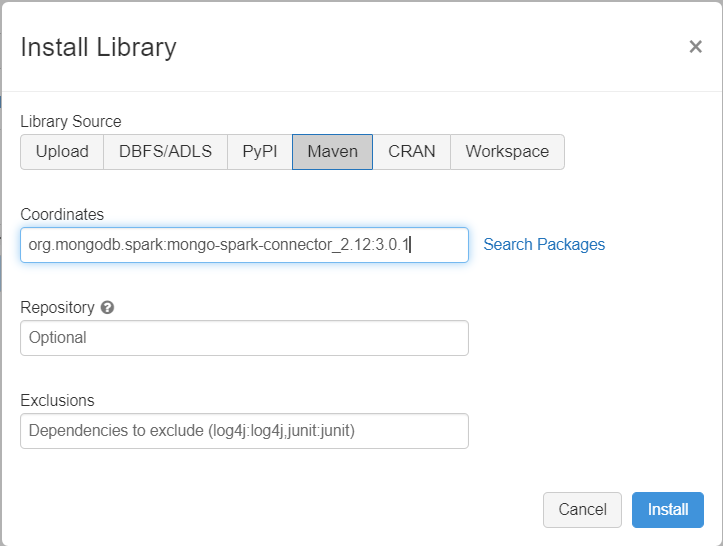
Yükle'yi seçin ve yükleme tamamlandığında kümeyi yeniden başlatın.
Dekont
MongoDB Bağlan veya Spark kitaplığı yüklendikten sonra Databricks kümesini yeniden başlattığınızdan emin olun.
Bundan sonra, geçiş için bir Scala veya Python not defteri oluşturabilirsiniz.
Geçiş için Scala not defteri oluşturma
Databricks'te Scala Not Defteri oluşturun. Aşağıdaki kodu çalıştırmadan önce değişkenler için doğru değerleri girdiğinizden emin olun:
import com.mongodb.spark._
import com.mongodb.spark.config._
import org.apache.spark._
import org.apache.spark.sql._
var sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
var sourceDb = "<DB NAME>"
var sourceCollection = "<COLLECTIONNAME>"
var targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
var targetDb = "<DB NAME>"
var targetCollection = "<COLLECTIONNAME>"
val readConfig = ReadConfig(Map(
"spark.mongodb.input.uri" -> sourceConnectionString,
"spark.mongodb.input.database" -> sourceDb,
"spark.mongodb.input.collection" -> sourceCollection,
))
val writeConfig = WriteConfig(Map(
"spark.mongodb.output.uri" -> targetConnectionString,
"spark.mongodb.output.database" -> targetDb,
"spark.mongodb.output.collection" -> targetCollection,
"spark.mongodb.output.maxBatchSize" -> "8000"
))
val sparkSession = SparkSession
.builder()
.appName("Data transfer using spark")
.getOrCreate()
val customRdd = MongoSpark.load(sparkSession, readConfig)
MongoSpark.save(customRdd, writeConfig)
Geçiş için Python not defteri oluşturma
Databricks'te bir Python Not Defteri oluşturun. Aşağıdaki kodu çalıştırmadan önce değişkenler için doğru değerleri girdiğinizden emin olun:
from pyspark.sql import SparkSession
sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
sourceDb = "<DB NAME>"
sourceCollection = "<COLLECTIONNAME>"
targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
targetDb = "<DB NAME>"
targetCollection = "<COLLECTIONNAME>"
my_spark = SparkSession \
.builder \
.appName("myApp") \
.getOrCreate()
df = my_spark.read.format("com.mongodb.spark.sql.DefaultSource").option("uri", sourceConnectionString).option("database", sourceDb).option("collection", sourceCollection).load()
df.write.format("mongo").mode("append").option("uri", targetConnectionString).option("maxBatchSize",2500).option("database", targetDb).option("collection", targetCollection).save()
Geçiş performansını iyileştirme
Geçiş performansı şu yapılandırmalar aracılığıyla ayarlanabilir:
Spark kümesindeki çalışan ve çekirdek sayısı: Daha fazla çalışan, görevleri yürütmek için daha fazla işlem parçası anlamına gelir.
maxBatchSize: Değer,
maxBatchSizeverilerin hedef Azure Cosmos DB koleksiyonuna kaydedilme hızını denetler. Ancak maxBatchSize değeri koleksiyon aktarım hızı için çok yüksekse hız sınırlama hatalarına neden olabilir.Spark kümesindeki yürütücü sayısına, yazılmakta olan her belgenin boyutuna (ve bu nedenle RU maliyetine) ve hedef koleksiyon aktarım hızı sınırlarına bağlı olarak çalışan sayısını ve maxBatchSize değerini ayarlamanız gerekir.
Bahşiş
maxBatchSize = Koleksiyon aktarım hızı / ( 1 belge için RU maliyeti * Spark çalışanlarının sayısı * çalışan başına CPU çekirdeği sayısı )
MongoDB Spark bölümleyicisi ve partitionKey: Kullanılan varsayılan bölümleyici MongoDefaultPartitioner ve varsayılan partitionKey _id. Bölümleyici, giriş yapılandırma özelliğine
spark.mongodb.input.partitionerdeğerMongoSamplePartitioneratanarak değiştirilebilir. Benzer şekilde partitionKey, giriş yapılandırma özelliğinespark.mongodb.input.partitioner.partitionKeyuygun alan adı atanarak değiştirilebilir. Right partitionKey, veri dengesizliğini önlemeye yardımcı olabilir (aynı parça anahtarı değeri için çok sayıda kayıt yazılması).Veri aktarımı sırasında dizinleri devre dışı bırakma: Büyük miktarda veri geçişi için dizinleri, özellikle hedef koleksiyonda joker karakter dizinini devre dışı bırakmayı göz önünde bulundurun. Dizinler, her belgeyi yazmanın RU maliyetini artırır. Bu RU'ları serbestleştirmek, veri aktarım hızını artırmaya yardımcı olabilir. Veriler geçirildikten sonra dizinleri etkinleştirebilirsiniz.
Sorun giderme
Zaman Aşımı Hatası (Hata kodu 50)
MongoDB için Azure Cosmos DB veritabanına yönelik işlemler için 50 hata kodu görebilirsiniz. Aşağıdaki senaryolar zaman aşımı hatalarına neden olabilir:
- Veritabanına ayrılan aktarım hızı düşük: Hedef koleksiyonun kendisine yeterli aktarım hızı atandığından emin olun.
- Büyük veri hacmine sahip aşırı veri dengesizliği. Belirli bir tabloya geçirilmesi gereken büyük miktarda veriniz varsa ancak verilerde önemli bir dengesizlik varsa, tablonuzda sağlanan birkaç istek birimi olsa bile hız sınırlaması yaşayabilirsiniz. İstek birimleri fiziksel bölümler arasında eşit olarak bölünür ve ağır veri dengesizliği tek bir parçaya yönelik isteklerde performans sorununa neden olabilir. Veri dengesizliği, aynı parça anahtarı değeri için çok sayıda kayıt anlamına gelir.
Hız sınırlama (Hata kodu 16500)
MongoDB için Azure Cosmos DB veritabanına yönelik işlemler için 16500 hata kodu görebilirsiniz. Bunlar hız sınırlama hatalarıdır ve sunucu tarafı yeniden deneme özelliğinin devre dışı bırakıldığı eski hesaplarda veya hesaplarda gözlemlenebilir.
- Sunucu tarafı yeniden denemesini etkinleştirme: Sunucu Tarafı Yeniden Deneme (SSR) özelliğini etkinleştirin ve sunucunun hız sınırlı işlemlerini otomatik olarak yeniden denemesine izin verin.
Geçiş sonrası iyileştirme
Verileri geçirdikten sonra Azure Cosmos DB'ye bağlanabilir ve verileri yönetebilirsiniz. Ayrıca, dizin oluşturma ilkesini iyileştirme, varsayılan tutarlılık düzeyini güncelleştirme veya Azure Cosmos DB hesabınız için genel dağıtımı yapılandırma gibi diğer geçiş sonrası adımlarını da izleyebilirsiniz. Daha fazla bilgi için Geçiş sonrası iyileştirme makalesine bakın.
Ek kaynaklar
- Azure Cosmos DB'ye geçiş için kapasite planlaması yapmaya mı çalışıyorsunuz?
- Tek bildiğiniz mevcut veritabanı kümenizdeki sanal çekirdek ve sunucu sayısıysa, sanal çekirdek veya vCPU kullanarak istek birimlerini tahmin etme hakkında bilgi edinin
- Geçerli veritabanı iş yükünüz için tipik istek oranlarını biliyorsanız Azure Cosmos DB kapasite planlayıcısı kullanarak istek birimlerini tahmin etme hakkında bilgi edinin