Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Önemli
PostgreSQL için Azure Cosmos DB kullanımdan kaldırma yolundadır ve artık yeni projeler için önerilmez. Bunun yerine, şu iki hizmetlerden birini kullanın:
PostgreSQL iş yükleri için: Açık kaynak Citus uzantısında yer alan yatay ölçeği genişletme ve dağıtılmış PostgreSQL özelliklerini kullanmak için PostgreSQL için Azure Veritabanı'nın Elastik Kümeler özelliğini kullanın. Geçiş kılavuzu için bkz. Elastik Küme ile PostgreSQL için Azure Veritabanı'na geçiş.
NoSQL iş yükleri için, 99,999% kullanılabilirlik hizmet düzeyi sözleşmesi (SLA), anında otomatik ölçeklendirme ve birden çok bölgede otomatik yük devretme içeren dağıtılmış bir veritabanı çözümü için NoSQL için Azure Cosmos DB'yi kullanın.
Birlikte bulundurma, ilgili bilgileri aynı düğümlerde birlikte depolama anlamına gelir. Gerekli tüm veriler herhangi bir ağ trafiği olmadan kullanılabilir olduğunda sorgular hızla gerçekleştirilir. Farklı düğümlerde ilgili verilerin birlikte bulunması, sorguların her düğümde paralel olarak verimli bir şekilde çalışmasını sağlar.
Hash dağıtılmış tablolar için veri birlikte bulundurma
PostgreSQL için Azure Cosmos DB'de, dağıtım sütunundaki değerin karması dilimin karma aralığı içindeyse, bir satır o dilimde depolanır. Aynı karma aralığına sahip parçalar her zaman aynı düğüme yerleştirilir. Eşit dağıtım sütunu değerlerine sahip satırlar her zaman tablolar arasında aynı düğümdedir. Karma dağıtılmış tablolar kavramı satır tabanlı parçalama olarak da bilinir. Şema tabanlı parçalamada, dağıtılmış şema içindeki tablolar her zaman aynı yerde bulunur.
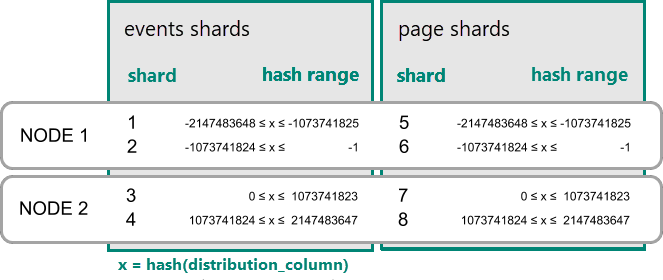
Kolokasyonun pratik bir örneği
Çok kiracılı bir web analizi SaaS'sinin parçası olabilecek aşağıdaki tabloları göz önünde bulundurun:
CREATE TABLE event (
tenant_id int,
event_id bigint,
page_id int,
payload jsonb,
primary key (tenant_id, event_id)
);
CREATE TABLE page (
tenant_id int,
page_id int,
path text,
primary key (tenant_id, page_id)
);
** Şimdi müşteri arayüzüne sahip bir pano tarafından verilebilen sorgulamaları yanıtlamak istiyoruz. Örnek bir sorgu: "Tenant Six'te '/blog' ile başlayan tüm sayfalar için geçen haftaki ziyaret sayısını döndürün."
Verilerimiz tek bir PostgreSQL sunucusundaysa SQL tarafından sunulan zengin ilişkisel işlemleri kullanarak sorgumuzu kolayca ifade edebiliriz:
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
Bu sorgunun çalışma kümesi belleğe sığdıkça, tek sunuculu bir tablo uygun bir çözümdür. PostgreSQL için Azure Cosmos DB ile veri modelini ölçeklendirme fırsatlarını ele alalım.
Tabloları kimliğine göre dağıt
Kiracı sayısı ve her kiracı için depolanan veriler arttıkça tek sunuculu sorgular yavaşlamaya başlar. Çalışma kümesi belleğe sığmayı durdurur ve CPU bir darboğaz haline gelir.
Bu durumda, PostgreSQL için Azure Cosmos DB'yi kullanarak verileri birçok düğüm arasında parçalayabiliriz. Karar verdiğimizde şardlama yapacağımızda, yapmamız gereken ilk ve en önemli seçim dağıtım sütunudur. Olay tablosu için event_id ve page_id tablosu için page kullanma gibi basit bir seçimle başlayalım:
-- naively use event_id and page_id as distribution columns
SELECT create_distributed_table('event', 'event_id');
SELECT create_distributed_table('page', 'page_id');
Veriler farklı çalışanlara dağıtıldığında, tek bir PostgreSQL düğümünde yaptığımız gibi birleştirme gerçekleştiremiyoruz. Bunun yerine iki sorgu yayınlamamız gerekir:
-- (Q1) get the relevant page_ids
SELECT page_id FROM page WHERE path LIKE '/blog%' AND tenant_id = 6;
-- (Q2) get the counts
SELECT page_id, count(*) AS count
FROM event
WHERE page_id IN (/*…page IDs from first query…*/)
AND tenant_id = 6
AND (payload->>'time')::date >= now() - interval '1 week'
GROUP BY page_id ORDER BY count DESC LIMIT 10;
Daha sonra, iki adımda elde edilen sonuçların uygulama tarafından birleştirilmesi gerekir.
Sorguları çalıştırmak, düğümlere dağılmış parçalardaki verilere başvurmalıdır.
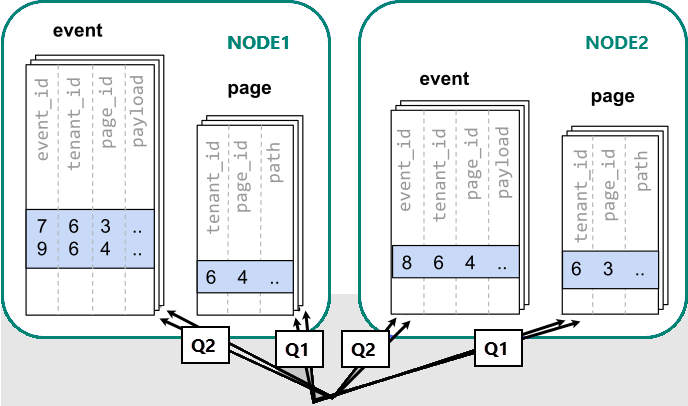
Bu durumda, veri dağıtımı önemli dezavantajlar oluşturur:
- Her bir parçanın sorgulanması ve birden çok sorgu çalıştırılmasının ek maliyeti.
- Q1'in istemciye birçok satır döndürmesinden kaynaklanan ek işlem yükü.
- Q2 büyük hale gelir.
- Birden çok adımda sorgu yazma gereksinimi, uygulamada değişiklik yapılmasını gerektirir.
Veriler dağıtıldığından sorgular paralel hale getirilebilir. Bu, yalnızca sorgunun yaptığı iş miktarının birçok parçanın sorgulanmasından önemli ölçüde fazla olması durumunda faydalıdır.
Tabloları kiracıya göre dağıtma
PostgreSQL için Azure Cosmos DB'de, aynı dağıtım sütunu değerine sahip satırların aynı düğümde olması garanti edilir. Baştan başlayarak tablolarımızı tenant_id dağıtım sütunu olarak oluşturabiliriz.
-- co-locate tables by using a common distribution column
SELECT create_distributed_table('event', 'tenant_id');
SELECT create_distributed_table('page', 'tenant_id', colocate_with => 'event');
Artık PostgreSQL için Azure Cosmos DB, özgün tek sunuculu sorguyu değiştirmeden yanıtlayabilir (Q1):
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
tenant_id üzerinde filtreleme ve birleştirme nedeniyle, PostgreSQL için Azure Cosmos DB, söz konusu kiracının verilerini içeren birlikte konumlandırılmış parça kümesini kullanarak sorgunun tamamının yanıtlanabileceğini bilir. Tek bir PostgreSQL düğümü sorguyu tek bir adımda yanıtlayabilir.
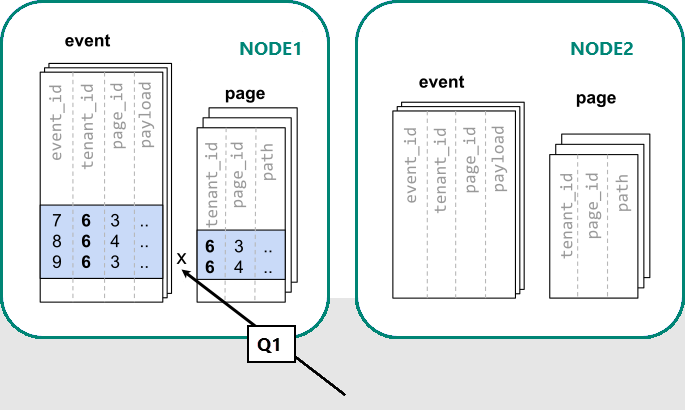
Bazı durumlarda, sorguların ve tablo şemalarının kiracı kimliğini benzersiz kısıtlamalara ve birleştirme koşullarına dahil etmek için değiştirilmesi gerekir. Bu değişiklik genellikle basittir.
Sonraki adımlar
- Çok kiracılı öğreticide kiracı verilerinin nasıl bir arada tutulduğunu görebilirsiniz.