Kök neden analizi için anomali tanılaması
Kusto Sorgu Dili (KQL), anormal davranışları denetlemek için yerleşik anomali algılama ve tahmin işlevlerine sahiptir. Böyle bir desen algılandıktan sonra, anomaliyi azaltmak veya çözmek için bir Kök Neden Analizi (RCA) çalıştırılabilir.
Tanılama işlemi karmaşık ve uzundur ve etki alanı uzmanları tarafından gerçekleştirilir. İşlem şunları içerir:
- Aynı zaman çerçevesi için farklı kaynaklardan daha fazla veri getirme ve birleştirme
- Birden çok boyuttaki değerlerin dağılımında değişiklik aranıyor
- Daha fazla değişken grafik oluşturma
- Etki alanı bilgi ve sezgiye dayalı diğer teknikler
Bu tanılama senaryoları yaygın olduğundan, tanılama aşamasını kolaylaştırmak ve RCA süresini kısaltmak için makine öğrenmesi eklentileri kullanılabilir.
Aşağıdaki Machine Learning eklentilerinin üçü de kümeleme algoritmaları uygular: autocluster, basketve diffpatterns. autocluster ve basket eklentileri tek bir kayıt kümesini kümeler ve diffpatterns eklenti iki kayıt kümesi arasındaki farkları kümeler.
Tek bir kayıt kümesini kümeleme
Yaygın bir senaryo, aşağıdakiler gibi belirli ölçütler tarafından seçilen bir veri kümesini içerir:
- Anormal davranışı gösteren zaman penceresi
- Yüksek sıcaklık cihaz okumaları
- Uzun süre komutları
- En çok harcama yapılan kullanıcılar
Verilerde ortak desenleri (segmentler) bulmanın hızlı ve kolay bir yolunu istiyorsunuz. Desenler, kayıtları birden çok boyutta (kategorik sütunlar) aynı değerleri paylaşan veri kümesinin bir alt kümesidir.
Aşağıdaki sorgu, on dakikalık bölmeler halinde bir hafta içindeki hizmet özel durumlarının zaman serisini oluşturur ve gösterir:
let min_t = toscalar(demo_clustering1 | summarize min(PreciseTimeStamp));
let max_t = toscalar(demo_clustering1 | summarize max(PreciseTimeStamp));
demo_clustering1
| make-series num=count() on PreciseTimeStamp from min_t to max_t step 10m
| render timechart with(title="Service exceptions over a week, 10 minutes resolution")
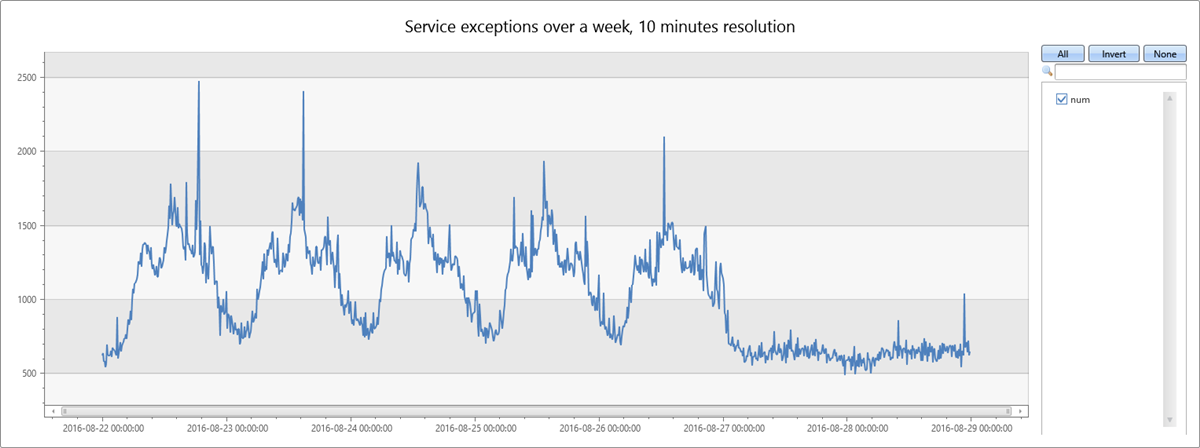
Hizmet özel durum sayısı, genel hizmet trafiğiyle ilişkilidir. pazartesiden cumaya iş günleri için günlük düzeni net bir şekilde görebilirsiniz. Gün ortasında hizmet özel durum sayılarında artış ve gece boyunca sayılarda düşüşler yaşanıyor. Düz düşük sayımlar hafta sonunda görünür. Zaman serisi anomali algılama kullanılarak özel durum ani artışları algılanabilir.
Verilerdeki ikinci ani artış Salı öğleden sonra gerçekleşir. Aşağıdaki sorgu, keskin bir ani artış olup olmadığını daha fazla tanılamak ve doğrulamak için kullanılır. Sorgu, grafiği bir dakikalık bölmelerde sekiz saatlik daha yüksek bir çözünürlükte ani artış etrafında yeniden çizer. Daha sonra kenarlıklarını inceleyebilirsiniz.
let min_t=datetime(2016-08-23 11:00);
demo_clustering1
| make-series num=count() on PreciseTimeStamp from min_t to min_t+8h step 1m
| render timechart with(title="Zoom on the 2nd spike, 1 minute resolution")
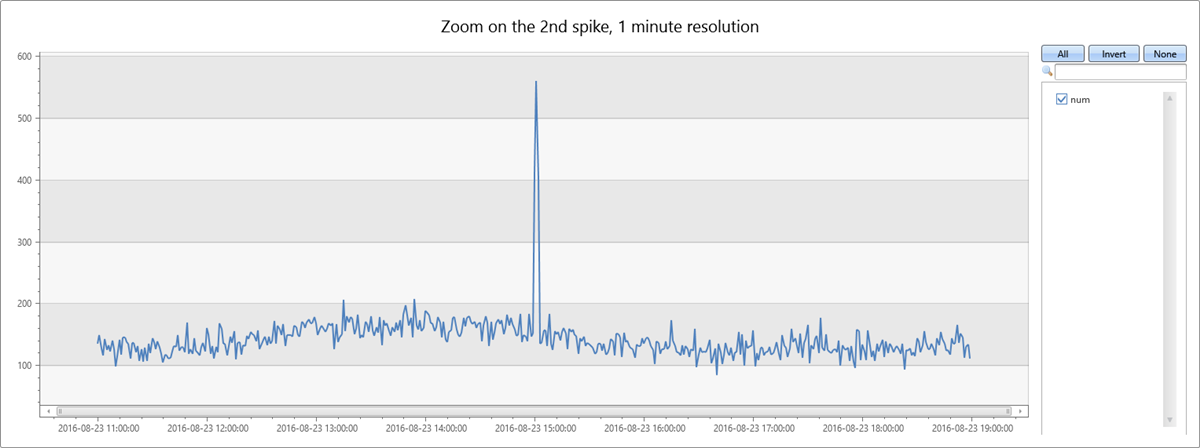
15:00 ile 15:02 arası iki dakikalık dar bir artış görürsünüz. Aşağıdaki sorguda, bu iki dakikalık pencerede özel durumları sayın:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| count
| Sayı |
|---|
| 972 |
Aşağıdaki sorguda, 972'de 20 özel durum örneği:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| take 20
| PreciseTimeStamp | Bölge | ScaleUnit | DeploymentId | İzleme noktası | ServiceHost |
|---|---|---|---|---|---|
| 2016-08-23 15:00:08.7302460 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 100005 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:09.9496584 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 8d257da1-7a1c-44f5-9acd-f9e02ff507fd |
| 2016-08-23 15:00:10.5911748 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 100005 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:12.2957912 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007007 | f855fcef-ebfe-405d-aaf8-9c5e2e43d862 |
| 2016-08-23 15:00:18.5955357 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 9d390e07-417d-42eb-bebd-793965189a28 |
| 2016-08-23 15:00:20.7444854 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 6e54c1c8-42d3-4e4e-8b79-9bb076ca71f1 |
| 2016-08-23 15:00:23.8694999 | eus2 | su2 | 89e2f62a73bb4efd8f545aeae40d7e51 | 36109 | 19422243-19b9-4d85-9ca6-bc961861d287 |
| 2016-08-23 15:00:26.4271786 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | 36109 | 3271bae4-1c5b-4f73-98ef-cc117e9be914 |
| 2016-08-23 15:00:27.8958124 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 904498 | 8cf38575-fca9-48ca-bd7c-21196f6d6765 |
| 2016-08-23 15:00:32.9884969 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007007 | d5c7c825-9d46-4ab7-a0c1-8e2ac1d83ddb |
| 2016-08-23 15:00:34.5061623 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 1002110 | 55a71811-5ec4-497a-a058-140fb0d611ad |
| 2016-08-23 15:00:37.4490273 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007006 | f2ee8254-173c-477d-a1de-4902150ea50d |
| 2016-08-23 15:00:41.2431223 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 103200 | 8cf38575-fca9-48ca-bd7c-21196f6d6765 |
| 2016-08-23 15:00:47.2983975 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | 423690590 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:50.5932834 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 2a41b552-aa19-4987-8cdd-410a3af016ac |
| 2016-08-23 15:00:50.8259021 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 1002110 | 0d56b8e3-470d-4213-91da-97405f8d005e |
| 2016-08-23 15:00:53.2490731 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 36109 | 55a71811-5ec4-497a-a058-140fb0d611ad |
| 2016-08-23 15:00:57.0000946 | eus2 | su2 | 89e2f62a73bb4efd8f545aeae40d7e51 | 64038 | cb55739e-4afe-46a3-970f-1b49d8ee7564 |
| 2016-08-23 15:00:58.2222707 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007007 | 8215dcf6-2de0-42bd-9c90-181c70486c9c |
| 2016-08-23 15:00:59.9382620 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007006 | 451e3c4c-0808-4566-a64d-84d85cf30978 |
Tek kayıt kümesi kümelemesi için autocluster() kullanma
Binden az özel durum olsa da, her sütunda birden çok değer bulunduğundan ortak segmentleri bulmak yine de zordur. Eklentiyi autocluster() kullanarak ortak segmentlerin kısa bir listesini anında ayıklayabilir ve aşağıdaki sorguda görüldüğü gibi ani artışın iki dakika içinde ilginç kümeleri bulabilirsiniz:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| evaluate autocluster()
| SegmentKimliği | Sayı | Yüzde | Bölge | ScaleUnit | DeploymentId | ServiceHost |
|---|---|---|---|---|---|---|
| 0 | 639 | 65.7407407407407 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 1 | 94 | 9.67078189300411 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | |
| 2 | Kategori 82 | 8.43621399176955 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | |
| 3 | 68 | 6.99588477366255 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | |
| 4 | 55 | 5.65843621399177 | weu | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc |
Yukarıdaki sonuçlardan en baskın segmentin toplam özel durum kayıtlarının %65,74'ünün bulunduğunu ve dört boyutu paylaştığını görebilirsiniz. Sonraki segment çok daha az yaygındır. Kayıtların yalnızca %9,67'sini içerir ve üç boyutu paylaşır. Diğer segmentler daha da az yaygındır.
Autocluster, birden çok boyutu araştırmak ve ilginç segmentleri ayıklamak için özel bir algoritma kullanır. "İlginç", her segmentin hem kayıt kümesinin hem de ayarlanan özelliklerin önemli bir kapsamı olduğu anlamına gelir. Segmentler de birbirinden ayrılmıştır, yani her biri diğerlerinden farklıdır. Bu segmentlerden biri veya daha fazlası RCA işlemiyle ilgili olabilir. Segment gözden geçirmesini ve değerlendirmesini en aza indirmek için, otomatik küme yalnızca küçük bir segment listesini ayıklar.
Tek kayıt kümesi kümeleme için basket() kullanma
Eklentiyi basket() aşağıdaki sorguda görüldüğü gibi de kullanabilirsiniz:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| evaluate basket()
| SegmentKimliği | Sayı | Yüzde | Bölge | ScaleUnit | DeploymentId | İzleme noktası | ServiceHost |
|---|---|---|---|---|---|---|---|
| 0 | 639 | 65.7407407407407 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | e7f60c5d-4944-42b3-922a-92e98a8e7dec | |
| 1 | 642 | 66.0493827160494 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | ||
| 2 | 324 | 33.3333333333333 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | 0 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 3 | 315 | 32.4074074074074 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | 16108 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 4 | 328 | 33.7448559670782 | 0 | ||||
| 5 | 94 | 9.67078189300411 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | ||
| 6 | Kategori 82 | 8.43621399176955 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | ||
| 7 | 68 | 6.99588477366255 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | ||
| 8 | 167 | 17.1810699588477 | scus | ||||
| 9 | 55 | 5.65843621399177 | weu | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc | ||
| 10 | 92 | 9.46502057613169 | 10007007 | ||||
| 11 | 90 | 9.25925925925926 | 10007006 | ||||
| 12 | 57 | 5.8641975308642 | 00000000-0000-0000-0000-000000000000 |
Sepet, öğe kümesi madenciliği için "Apriori" algoritmasını uygular. Kayıt kümesinin kapsamı eşiğin (varsayılan %5) üzerinde olan tüm kesimleri ayıklar. 0, 1 veya 2, 3 segmentleri gibi benzer segmentlerle daha fazla segmentin ayıklandığını görebilirsiniz.
Her iki eklenti de güçlü ve kullanımı kolaydır. Sınırlamaları, tek bir kayıt kümesini hiçbir etiket olmadan denetimsiz bir şekilde kümelemesidir. Ayıklanan desenlerin seçili kayıt kümesini mi, anormal kayıtları mı yoksa genel kayıt kümesini mi nitelediği belirsizdir.
İki kayıt kümesi arasındaki farkı kümeleme
diffpatterns() Eklenti ve basketsınırlamasını autocluster aşıyor. Diffpatterns iki kayıt kümesi alır ve farklı olan ana segmentleri ayıklar. Bir küme genellikle araştırılmakta olan anormal kayıt kümesini içerir. Biri ve baskettarafından autocluster analiz edilir. Diğer küme, başvuru kayıt kümesini, temeli içerir.
Aşağıdaki sorguda, diffpatterns ani artışın iki dakika içinde temeldeki kümelerden farklı olan ilginç kümeleri bulur. Temel pencere, ani artışın başladığı saat 15:00'in sekiz dakika öncesi olarak tanımlanır. İkili sütuna (AB) göre genişletir ve belirli bir kaydın taban çizgisine mi yoksa anormal kümeye mi ait olduğunu belirtirsiniz. Diffpatterns , iki sınıf etiketinin anormal ve taban çizgisi bayrağı (AB) tarafından oluşturulduğu denetimli bir öğrenme algoritması uygular.
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
let min_baseline_t=datetime(2016-08-23 14:50);
let max_baseline_t=datetime(2016-08-23 14:58); // Leave a gap between the baseline and the spike to avoid the transition zone.
let splitime=(max_baseline_t+min_peak_t)/2.0;
demo_clustering1
| where (PreciseTimeStamp between(min_baseline_t..max_baseline_t)) or
(PreciseTimeStamp between(min_peak_t..max_peak_t))
| extend AB=iff(PreciseTimeStamp > splitime, 'Anomaly', 'Baseline')
| evaluate diffpatterns(AB, 'Anomaly', 'Baseline')
| SegmentKimliği | CountA | SayıB | YüzdeA | YüzdeB | PercentDiffAB | Bölge | ScaleUnit | DeploymentId | İzleme noktası |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 639 | 21 | 65.74 | 1.7 | 64.04 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | |
| 1 | 167 | 4 milyon TL | 17.18 | 44.16 | 26.97 | scus | |||
| 2 | 92 | 356 | 9.47 | 28.9 | 19.43 | 10007007 | |||
| 3 | 90 | 336 | 9.26 | 27.27 | 18.01 | 10007006 | |||
| 4 | Kategori 82 | 318 | 8.44 | 25.81 | 17.38 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | |
| 5 | 55 | 252 | 5.66 | 20.45 | 14.8 | weu | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc | |
| 6 | 57 | 204 | 5.86 | 16.56 | 10.69 |
En baskın segment, tarafından autoclusterayıklanan kesimdir. İki dakikalık anormal penceredeki kapsamı da %65,74'dür. Ancak sekiz dakikalık taban çizgisi penceresindeki kapsamı yalnızca %1,7'dir. Fark %64,04'dür. Bu fark anormal ani artışla ilgili gibi görünüyor. Bu varsayımı doğrulamak için, aşağıdaki sorgu özgün grafiği bu sorunlu segmente ait kayıtlara ve diğer segmentlerden kayıtlara böler.
let min_t = toscalar(demo_clustering1 | summarize min(PreciseTimeStamp));
let max_t = toscalar(demo_clustering1 | summarize max(PreciseTimeStamp));
demo_clustering1
| extend seg = iff(Region == "eau" and ScaleUnit == "su7" and DeploymentId == "b5d1d4df547d4a04ac15885617edba57"
and ServiceHost == "e7f60c5d-4944-42b3-922a-92e98a8e7dec", "Problem", "Normal")
| make-series num=count() on PreciseTimeStamp from min_t to max_t step 10m by seg
| render timechart
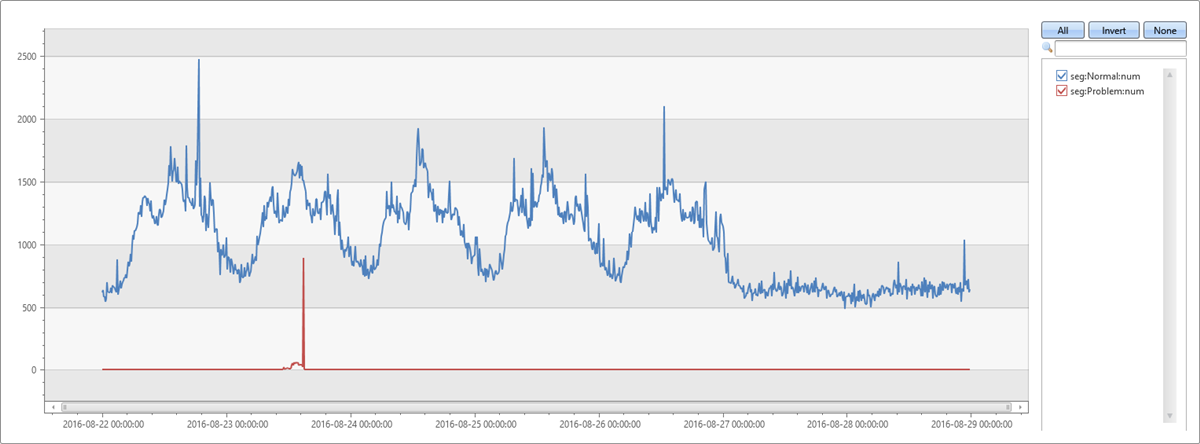
Bu grafik, Salı öğleden sonra ani artışın eklenti kullanılarak diffpatterns keşfedilen bu belirli segmentten gelen özel durumlar nedeniyle olduğunu görmemizi sağlar.
Özet
Machine Learning eklentileri birçok senaryo için yararlıdır. autocluster ve basket denetimsiz bir öğrenme algoritması uygular ve kullanımı kolaydır. Diffpatterns denetimli bir öğrenme algoritması uygular ve daha karmaşık olsa da RCA için farklılaştırma segmentlerini ayıklamak için daha güçlü bir yöntemdir.
Bu eklentiler geçici senaryolarda ve otomatik yakın gerçek zamanlı izleme hizmetlerinde etkileşimli olarak kullanılır. Zaman serisi anomali algılaması bir tanılama süreciyle takip edilir. Bu süreç, gerekli performans standartlarını karşılamak için yüksek oranda iyileştirilmiştir.
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin