Performans için Azure Data Lake Storage 1. Nesil'i ayarlama
Data Lake Storage 1. Nesil yoğun G/Ç analizi ve veri taşıma için yüksek aktarım hızını destekler. Data Lake Storage 1. Nesil,kullanılabilir tüm aktarım hızını (saniyede okunabilen veya yazılabilir veri miktarı) kullanmak, en iyi performansı elde etmek için önemlidir. Bu, mümkün olduğunca çok okuma ve yazma işlemini paralel olarak gerçekleştirerek elde edilir.

Data Lake Storage 1. Nesil tüm analiz senaryoları için gerekli aktarım hızını sağlamak üzere ölçeklendirilebilir. Varsayılan olarak, bir Data Lake Storage 1. Nesil hesabı geniş bir kullanım örneği kategorisinin gereksinimlerini karşılamak için otomatik olarak yeterli aktarım hızı sağlar. Müşterilerin varsayılan sınıra girdiği durumlarda, Data Lake Storage 1. Nesil hesabı Microsoft desteğine başvurarak daha fazla aktarım hızı sağlayacak şekilde yapılandırılabilir.
Veri alımı
Bir kaynak sistemden Data Lake Storage 1. Nesil veri alırken, Data Lake Storage 1. Nesil kaynak donanımının, kaynak ağ donanımının ve ağ bağlantısının performans sorunu olabileceğini göz önünde bulundurmak önemlidir.
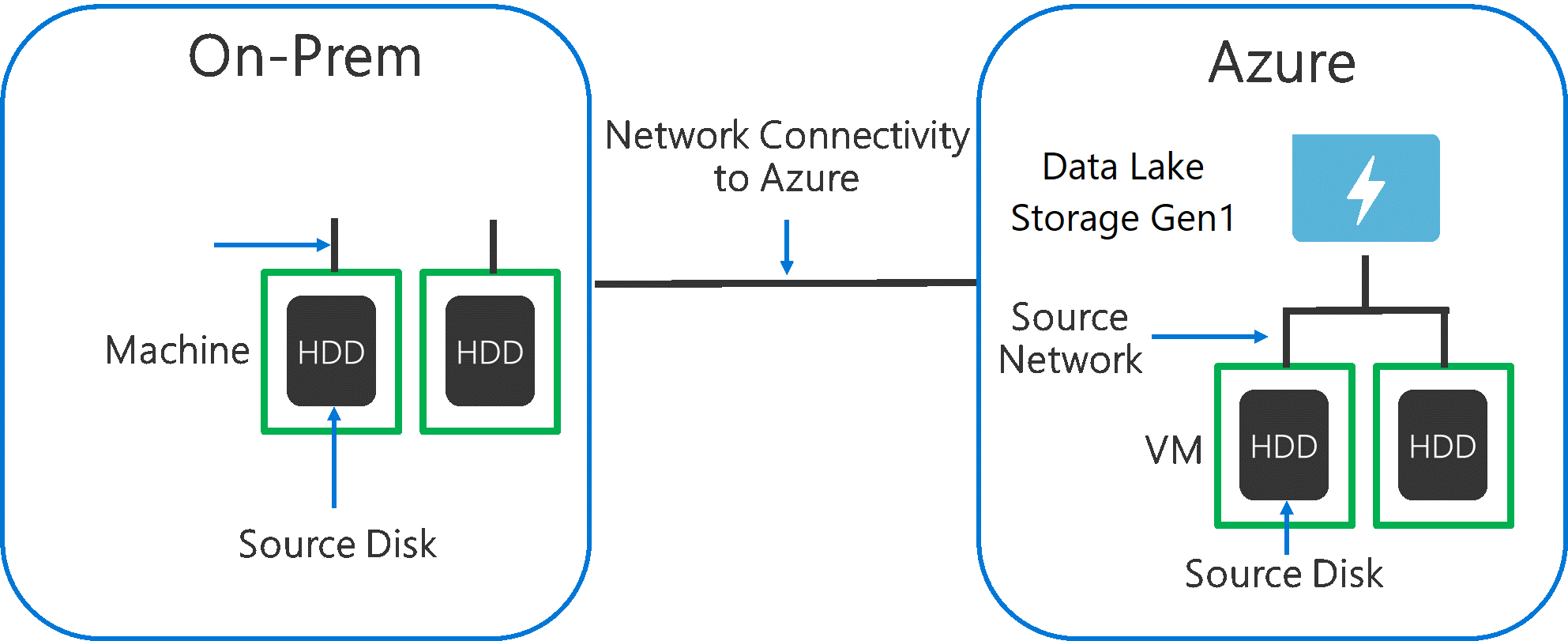
Veri hareketinin bu faktörlerden etkilenmediğinden emin olmak önemlidir.
Kaynak donanım
İster şirket içi makineleri ister Azure'daki VM'leri kullanıyor olun, uygun donanımı dikkatle seçmelisiniz. Kaynak Disk Donanımı için HDD'lere SSD'leri tercih edin ve daha hızlı spindle disk donanımı seçin. Kaynak Ağ Donanımı için mümkün olan en hızlı NIC'leri kullanın. Azure'da, uygun güçlü disk ve ağ donanımına sahip Azure D14 VM'leri önerilir.
Data Lake Storage 1. Nesil ağ bağlantısı
Kaynak verilerinizle Data Lake Storage 1. Nesil arasındaki ağ bağlantısı bazen performans sorunu olabilir. Kaynak verileriniz Şirket İçi olduğunda , Azure ExpressRoute ile ayrılmış bir bağlantı kullanmayı göz önünde bulundurun. Kaynak verileriniz Azure'daysa, veriler Data Lake Storage 1. Nesil hesabıyla aynı Azure bölgesinde olduğunda performans en iyi olacaktır.
Maksimum paralelleştirme için veri alımı araçlarını yapılandırma
Kaynak donanım ve ağ bağlantısı sorunlarını ele aldıktan sonra, alım araçlarınızı yapılandırmaya hazırsınız demektir. Aşağıdaki tabloda çeşitli popüler alım araçlarının temel ayarları özetlenmiştir ve bunlar için ayrıntılı performans ayarlama makaleleri sağlanmaktadır. Senaryonuzda hangi aracın kullanılacağı hakkında daha fazla bilgi edinmek için bu makaleyi ziyaret edin.
| Araç | Ayarlar | Diğer Ayrıntılar |
|---|---|---|
| PowerShell | PerFileThreadCount, ConcurrentFileCount | Bağlantı |
| AdlCopy | Azure Data Lake Analytics birimleri | Bağlantı |
| DistCp | -m (eşleştirici) | Bağlantı |
| Azure Data Factory | parallelCopies | Bağlantı |
| Sqoop | fs.azure.block.size, -m (eşleyici) | Bağlantı |
Veri kümenizi yapılandırma
Veriler Data Lake Storage 1. Nesil depolandığında, dosya boyutu, dosya sayısı ve klasör yapısı performansı etkiler. Aşağıdaki bölümde bu alanlardaki en iyi yöntemler açıklanmaktadır.
Dosya boyutu
Genellikle HDInsight ve Azure Data Lake Analytics gibi analiz altyapılarının dosya başına ek yükü vardır. Verilerinizi çok sayıda küçük dosya olarak depolarsanız, bu durum performansı olumsuz etkileyebilir.
Genel olarak, daha iyi performans için verilerinizi daha büyük boyutlu dosyalar halinde düzenleyin. Temel kural olarak, veri kümelerini 256 MB veya daha büyük dosyalarda düzenleyin. Görüntüler ve ikili veriler gibi bazı durumlarda bunları paralel olarak işlemek mümkün değildir. Böyle durumlarda, tek tek dosyaların 2 GB'ın altında tutulması önerilir.
Bazen veri işlem hatları, çok sayıda küçük dosya içeren ham veriler üzerinde sınırlı denetime sahiptir. Aşağı akış uygulamaları için kullanılacak daha büyük dosyalar oluşturan bir "pişirme" işlemine sahip olmanız önerilir.
Zaman serisi verilerini klasörlerde düzenleme
Hive ve ADLA iş yükleri için, zaman serisi verilerinin bölüm ayıklaması bazı sorguların verilerin yalnızca bir alt kümesini okumalarına yardımcı olabilir ve bu da performansı artırır.
Zaman serisi verilerini alanlar bu işlem hatları genellikle dosyalarını dosyalar ve klasörler için yapılandırılmış bir adlandırma ile yerleştirir. Tarihe göre yapılandırılmış veriler için gördüğümüz yaygın bir örnek aşağıda verilmiştir: \DataSet\YYYY\AA\DD\datafile_YYYY_MM_DD.tsv.
Tarih saat bilgilerinin hem klasör olarak hem de dosya adında göründüğüne dikkat edin.
Tarih ve saat için şu yaygın bir desendir: \DataSet\YYYY\MM\DD\HH\mm\datafile_YYYY_MM_DD_HH_mm.tsv.
Yine, klasör ve dosya kuruluşunda yaptığınız seçim, daha büyük dosya boyutları ve her klasördeki makul sayıda dosya için iyileştirilmelidir.
HDInsight'ta Hadoop ve Spark iş yüklerinde G/Ç yoğun işleri iyileştirme
İşler aşağıdaki üç kategoriden birine ayrılır:
- YOĞUN CPU kullanımı. Bu işler, en az G/Ç süresine sahip uzun hesaplama sürelerine sahiptir. Makine öğrenmesi ve doğal dil işleme işleri buna örnek olarak verilebilir.
- Yoğun bellek. Bu işler çok fazla bellek kullanır. Örnek olarak PageRank ve gerçek zamanlı analiz işleri verilebilir.
- G/Ç yoğun. Bu işler zamanlarının çoğunu G/Ç yaparak geçirir. Yaygın bir örnek, yalnızca okuma ve yazma işlemlerinin gerçekleştirildiği bir kopyalama işidir. Diğer örnekler arasında çok sayıda veri okuyan, veri dönüştürme gerçekleştiren ve ardından verileri depoya geri yazan veri hazırlama işleri yer alır.
Aşağıdaki kılavuz yalnızca G/Ç yoğunluklu işler için geçerlidir.
HDInsight kümesi için genel dikkat edilmesi gerekenler
- HDInsight sürümleri. En iyi performans için HDInsight'ın en son sürümünü kullanın.
- Bölge. Data Lake Storage 1. Nesil hesabını HDInsight kümesiyle aynı bölgeye yerleştirin.
HDInsight kümesi iki baş düğümden ve bazı çalışan düğümlerinden oluşur. Her çalışan düğümü, VM türü tarafından belirlenen belirli sayıda çekirdek ve bellek sağlar. bir işi çalıştırırken YARN, kapsayıcı oluşturmak için kullanılabilir belleği ve çekirdekleri ayıran kaynak anlaşma aracıdır. Her kapsayıcı, işi tamamlamak için gereken görevleri çalıştırır. Kapsayıcılar, görevleri hızlı bir şekilde işlemek için paralel olarak çalışır. Bu nedenle, mümkün olduğunca çok paralel kapsayıcı çalıştırılarak performans artırılır.
Bir HDInsight kümesinde kapsayıcı sayısını artırmak ve kullanılabilir tüm aktarım hızını kullanmak için ayarlanabilen üç katman vardır.
- Fiziksel katman
- YARN katmanı
- İş yükü katmanı
Fiziksel katman
Kümeyi daha fazla düğüm ve/veya daha büyük boyutlu VM'lerle çalıştırın. Daha büyük bir küme, aşağıdaki resimde gösterildiği gibi daha fazla YARN kapsayıcısı çalıştırmanızı sağlar.

Daha fazla ağ bant genişliğine sahip VM'leri kullanın. ağ bant genişliği miktarı, Data Lake Storage 1. Nesil aktarım hızına göre daha az ağ bant genişliği varsa bir performans sorunu olabilir. Farklı VM'lerin farklı ağ bant genişliği boyutları olacaktır. Mümkün olan en büyük ağ bant genişliğine sahip bir VM türü seçin.
YARN katmanı
Daha küçük YARN kapsayıcıları kullanın. Aynı miktarda kaynağa sahip daha fazla kapsayıcı oluşturmak için her YARN kapsayıcısının boyutunu azaltın.

İş yükünüz bağlı olarak, her zaman gereken en düşük YARN kapsayıcı boyutu olacaktır. Çok küçük bir kapsayıcı seçersensiniz, işleriniz yetersiz bellek sorunlarıyla karşılaşır. Genellikle YARN kapsayıcıları 1 GB'tan küçük olmamalıdır. Genellikle 3 GB YARN kapsayıcıları görülür. Bazı iş yükleri için daha büyük YARN kapsayıcılarına ihtiyacınız olabilir.
YARN kapsayıcısı başına çekirdek sayısını artırın. Her kapsayıcıda çalıştırılan paralel görevlerin sayısını artırmak için her kapsayıcıya ayrılan çekirdek sayısını artırın. Bu, spark gibi kapsayıcı başına birden çok görev çalıştıran uygulamalar için çalışır. Her kapsayıcıda tek bir iş parçacığı çalıştıran Hive gibi uygulamalar için kapsayıcı başına daha fazla çekirdek yerine daha fazla kapsayıcı olması daha iyidir.
İş yükü katmanı
Tüm kullanılabilir kapsayıcıları kullanın. Tüm kaynakların kullanılabilmesi için görev sayısını kullanılabilir kapsayıcı sayısından eşit veya daha büyük olacak şekilde ayarlayın.

Başarısız görevler maliyetlidir. Her görevin işlenmek üzere büyük miktarda verisi varsa, görevin başarısız olması pahalı bir yeniden denemeyle sonuçlanırsa. Bu nedenle, her biri az miktarda veriyi işleyen daha fazla görev oluşturmak daha iyidir.
Yukarıdaki genel yönergelere ek olarak, her uygulamanın belirli bir uygulamayı ayarlamak için kullanabileceği farklı parametreleri vardır. Aşağıdaki tabloda, her uygulama için performans ayarlamaya başlamak için bazı parametreler ve bağlantılar listelenmiştir.
| İş Yükü | Görevleri ayarlamak için parametre |
|---|---|
| HDInsight’ta Spark |
|
| HDInsight üzerinde Hive |
|
| HDInsight üzerinde MapReduce |
|
| HDInsight üzerinde Storm |
|