Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Azure Databricks gibi bulutta yerel veri analizi platformu için net bir olağanüstü durum kurtarma düzeni kritik önem taşır. İster kasırga, ister deprem gibi bölgesel bir olağanüstü durum veya başka bir kaynaktan kaynaklanan bölgesel hizmet genelinde bulut hizmeti sağlayıcısı kesintisi nadir durumlarda bile veri ekiplerinizin Azure Databricks platformunu kullanabilmesi kritik önem taşır.
Azure Databricks, genellikle üst akış veri alımı hizmetleri (toplu/akış), ADLS gibi bulut yerel depolama (6 Mart 2023'ten önce oluşturulan çalışma alanları için Azure Blob Depolama), iş zekası uygulamaları gibi aşağı akış araçları ve hizmetleri ve düzenleme araçları da dahil olmak üzere birçok hizmeti içeren genel veri ekosisteminin önemli bir parçasıdır. Bazı kullanım örnekleriniz, bölgesel hizmet genelindeki kesintilere karşı özellikle hassas olabilir.
Bu makalede Databricks platformu için başarılı bir bölgeler arası olağanüstü durum kurtarma çözümüne yönelik kavramlar ve en iyi yöntemler açıklanmaktadır.
Bölge içi yüksek kullanılabilirlik garantileri
Bu konunun geri kalanı bölgeler arası olağanüstü durum kurtarmanın uygulanmasına odaklansa da, Azure Databricks'in tek bölgede sağladığı yüksek kullanılabilirlik garantilerini anlamak önemlidir. bölge içinde yüksek kullanılabilirlik garantileri aşağıdaki bileşenleri kapsar:
Databricks denetim düzleminin kullanılabilirliği
Databricks denetim düzlemi bölge hatalarına dayanıklıdır ve bölge hatasından yaklaşık 15 dakika sonra otomatik olarak kurtarılmalıdır. Rutin bölge hatası testi bunu doğrular.
Durumsuz tüm denetim düzlemi hizmetleri, tek tek VM'lerin yanı sıra tüm bölgedeki tüm VM'lerin kayıplarını otomatik olarak yönetebilir. Çalışma alanı verileri, bölgedeki bölgeler arasında çoğaltılan veritabanlarında depolanır. Databricks Runtime görüntülerine hizmet vermek için kullanılan depolama hesapları, bölge içinde de yedeklidir ve birincil hesap devre dışı olduğunda her bölge, ikincil depolama hesaplarını kullanır. Bazı bölgeler, eşleştirilmiş bir bölgede dağıtılmış olan bir denetim düzlemi kullanabilir. Daha fazla bilgi için bkz. Azure Databricks bölgeleri .
Bölge hatası dayanıklılığı yalnızca en fazla bir bölgenin kapanmasını destekler ve yalnızca birden çok bölgeyi destekleyen Azure bölgelerinde kullanılabilir.
Önemli
Databricks HA, kullanılabilirlik alanı (AZ) yedekliliği ile bölge içi çalışma süresi sağlar. Bir bölgede kesinti varsa, hizmetler bölgede çalışmaya devam eder.
DR, bölgeler arası çoğaltma kullanır ve başka bir bölgeye yük devretmenizi sağlar. Başka bir bölgede ikincil Databricks çalışma alanlarını yapılandırıp kurtarmayı etkinleştirmek için verileri ve yapılandırmaları çoğaltabilirsiniz.
Çok bölgeli DR'ye ihtiyacınız yoksa Databricks HA yeterli olabilir ve bölgeler arası karmaşıklığı önler. Ancak veriler özgün bölgede kaldığından tam bölge kesintisine karşı koruma sağlamaz.
DR için Databricks HA'ya güveniyorsanız bulut bölgenizin ayrımını ve yedekliliğini doğrulayın.
Çoklu AZ desteğini onaylamak için Bkz. Azure bölgeleri listesi. İşlem düzlemi çoklu AZ dayanıklılığı için bölgeye bağlı yedekli depolamayı kullanın.
İşlem düzleminin kullanılabilirliği
Çalışma alanı kullanılabilirliği, kontrol düzleminin kullanılabilirliğine bağlıdır (yukarıda açıklandığı gibi). DBFS Kökü için depolama hesabı Alanlar arası yedekli depolama (ZRS) veya Coğrafi alanlar arası yedekli depolama (GZRS) (varsayılan olarak Coğrafi olarak yedekli depolama (GRS) ile yapılandırılmışsa DBFS Kökündeki veriler etkilenmez.
Kümeler için düğümler, Azure işlem sağlayıcısından düğümler istenerek (isteği yerine getirmek için kalan bölgelerde yeterli kapasite olduğu varsayılarak) farklı kullanılabilirlik alanlarından çekilir. Bir düğüm kaybolursa, küme yöneticisi, kullanılabilir AZ'lerden çektikleri yedek düğümleri Azure işlem sağlayıcısından talep eder. Tek özel durum, sürücü düğümünün kaybolmasıdır. Bu durumda, küme yöneticisi işi ve kümeyi yeniden başlatır.
Afet kurtarmaya genel bakış
Olağanüstü durum kurtarma, doğal veya insan kaynaklı bir olağanüstü durum sonrasında yaşamsal teknoloji altyapısının ve sistemlerinin kurtarılmasını veya devamını sağlayan bir dizi ilke, araç ve yordam içerir. Azure gibi büyük bir bulut hizmeti birçok müşteriye hizmet eder ve tek bir hataya karşı yerleşik korumalara sahiptir. Örneğin, bölge, tek bir güç kaybının bölgeyi kapatmayacağını garanti etmek için farklı güç kaynaklarına bağlı bir bina grubudur. Ancak bulut bölgesi hataları oluşabilir ve kesinti derecesi ve bunun kuruluşunuz üzerindeki etkisi farklılık gösterebilir.
Olağanüstü durum kurtarma planı uygulamadan önce olağanüstü durum kurtarma (DR) ile yüksek kullanılabilirlik (HA) arasındaki farkı anlamak önemlidir.
Yüksek kullanılabilirlik, bir sistemin dayanıklılık özelliğidir. Yüksek kullanılabilirlik, genellikle tutarlı çalışma süresi veya çalışma süresi yüzdesi açısından tanımlanan en düşük operasyonel performans düzeyini sağlar. Yüksek kullanılabilirlik, birincil sistemin bir özelliği olarak tasarlanarak yerinde (birincil sisteminizle aynı bölgede) uygulanır. Örneğin, Azure gibi bulut hizmetleri, ADLS ve 6 Mart 2023'ten önce oluşturulan çalışma alanları için Azure Blob Depolama gibi yüksek kullanılabilirlik hizmetlerine sahiptir. Yüksek kullanılabilirlik, Azure Databricks müşterisinden önemli bir açık hazırlık gerektirmez.
Buna karşılık, olağanüstü durum kurtarma planı, kritik sistemlerde daha büyük bir bölgesel kesintiyi işlemek için kuruluşunuza uygun kararlar ve çözümler gerektirir. Bu makalede Azure Databricks ile olağanüstü durum kurtarma planlarına yönelik yaygın olağanüstü durum kurtarma terminolojisi, yaygın çözümler ve bazı en iyi yöntemler ele alınmaktadır.
Terminoloji
Bölge terminolojisi
Bu makalede bölgeler için aşağıdaki tanımlar kullanılır:
Birincil bölge: Kullanıcıların tipik günlük etkileşimli ve otomatik veri analizi iş yüklerini çalıştırdığı coğrafi bölge.
İkincil bölge: BT ekiplerinin birincil bölgedeki bir kesinti sırasında veri analizi iş yüklerini geçici olarak taşıdığı coğrafi bölge.
Coğrafi olarak yedekli depolama: Azure, zaman uyumsuz bir depolama çoğaltma işlemi kullanarak kalıcı depolama için bölgeler arasında coğrafi olarak yedekli depolamaya sahiptir.
Önemli
Olağanüstü durum kurtarma işlemleri için Databricks, AZURE Databricks'in Azure aboneliğinizdeki her çalışma alanı için oluşturduğu ADLS'niz (6 Mart 2023'te oluşturulan çalışma alanları için Azure Blob Depolama) gibi verilerin bölgeler arası çoğaltılması için coğrafi olarak yedekli depolamaya güvenmemenizi önerir. Genel olarak, Delta Tabloları için Derin Klonlama'yı kullanın ve diğer veri biçimlerinde mümkünse Derin Kopya kullanmak üzere verileri Delta biçimine dönüştürün.
Dağıtım durumu terminolojisi
Bu makalede, dağıtım durumunun aşağıdaki tanımları kullanılır:
Etkin dağıtım: Kullanıcılar Azure Databricks çalışma alanının etkin dağıtımına bağlanabilir ve iş yüklerini çalıştırabilir. İşler, Azure Databricks zamanlayıcı veya diğer mekanizmalar kullanılarak düzenli aralıklarla zamanlanır. Veri akışları bu dağıtımda da yürütülebilir. Bazı belgeler etkin dağıtımı sıcak dağıtım olarak adlandırabilir.
Pasif dağıtım: İşlemler pasif dağıtımda çalışmaz. BT ekipleri, pasif dağıtıma kod, yapılandırma ve diğer Azure Databricks nesnelerini dağıtmak için otomatik yordamlar ayarlayabilir. Bir dağıtım yalnızca geçerli bir etkin dağıtımın devre dışı olması durumunda etkin hale gelir. Bazı belgelerde pasif dağıtım, soğuk dağıtım olarak anılabilir.
Önemli
Bir proje isteğe bağlı olarak, bölgesel kesintileri çözmek için ek seçenekler sağlamak üzere farklı bölgelerde birden çok pasif dağıtım içerebilir.
Tipik olarak, bir ekipte aynı anda yalnızca bir etkin dağıtım vardır, bu da etkin-pasif olağanüstü durum kurtarma stratejisi olarak adlandırılır. Etkin-etkin adlı daha az yaygın bir olağanüstü durum kurtarma çözümü stratejisi vardır ve bu stratejide iki eşzamanlı etkin dağıtım vardır.
Olağanüstü durum kurtarma sektörü terminolojisi
Ekibiniz için anlamanız ve tanımlamanız gereken iki önemli sektör terimi vardır:
Kurtarma noktası hedefi: Kurtarma noktası hedefi (RPO), bir BT hizmetinden önemli bir olay nedeniyle verilerin (işlemlerin) kaybedilebileceği maksimum hedeflenen dönemdir. Azure Databricks dağıtımınız ana müşteri verilerinizi depolamaz. Bu, ADLS veya 6 Mart 2023'ten önce oluşturulmuş çalışma alanları için Azure Blob Depolama ya da denetiminiz altındaki diğer veri kaynakları gibi ayrı sistemlerde depolanır. Azure Databricks denetim düzlemi, işler ve not defterleri gibi bazı nesneleri kısmen veya tamamen depolar. Azure Databricks için RPO, işler ve not defteri değişiklikleri gibi nesnelerin kaybedilebileceği hedeflenen maksimum süre olarak tanımlanır. Buna ek olarak, ADLS'deki (6 Mart 2023'e kadar oluşturulan çalışma alanları, Azure Blob Depolama) veya denetiminizdeki diğer veri kaynakları için kendi müşteri verileriniz için RPO tanımlamak sizin sorumluluğunuzdadır.
Kurtarma süresi hedefi: Kurtarma süresi hedefi (RTO), hedeflenen süre ve olağanüstü durumdan sonra bir iş sürecinin geri yüklenmesi gereken hizmet düzeyidir.
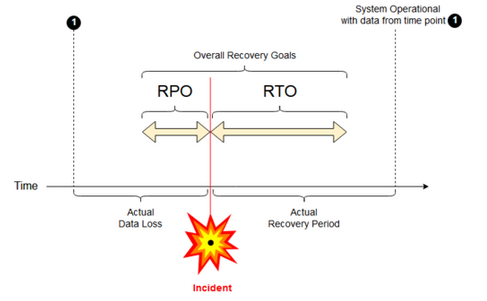
Olağanüstü durum kurtarma ve veri bozulması
Olağanüstü durum kurtarma çözümü veri bozulmalarını azaltmaz. Birincil bölgedeki bozuk veriler birincil bölgeden ikincil bölgeye çoğaltılır ve her iki bölgede de bozulur. Bu tür hataları azaltmanın başka yolları da vardır, örneğin Delta zaman yolculuğu.
Tipik kurtarma iş akışı
Azure Databricks olağanüstü durum kurtarma senaryosu genellikle aşağıdaki şekilde yürütülür:
Birincil bölgenizde kullandığınız kritik bir hizmette hata oluşur. Bu bir veri kaynağı hizmeti veya Azure Databricks dağıtımını etkileyen bir ağ olabilir.
Bulut sağlayıcısıyla ilgili durumu araştırırsınız.
Şirketinizin birincil bölgede sorunun düzeltilmesi için bekleyemeyeceğine karar verirseniz, ikincil bölgeye yük devretmeyi tercih edebilirsiniz.
Aynı sorunun ikincil bölgenizi de etkilemediğini doğrulayın.
Yedek bir bölgeye geçiş yapma.
- Çalışma alanında tüm etkinlikleri durdurun. Kullanıcılar iş yüklerini durdurur. Kullanıcılara veya yöneticilere mümkünse son değişiklikleri yedeklemeleri istenir. İşler kesinti nedeniyle henüz başarısız olmadıysa kapatılır.
- kurtarma yordamını ikincil bölgede başlatın. Kurtarma yordamı yönlendirmeyi güncelleştirir ve bağlantıları ve ağ trafiğini ikincil bölgeye yeniden adlandırır.
- Test ettikten sonra ikincil bölgeyi çalışır durumda bildirin. Üretim iş yükleri artık devam edebilir. Kullanıcılar artık etkin olan dağıtımda oturum açabilir. Zamanlanmış veya gecikmiş işleri yeniden tetikleyebilirsiniz.
Azure Databricks bağlamındaki ayrıntılı adımlar için bkz. Testi yük devretme.
Bir noktada birincil bölgedeki sorun giderilir ve bu gerçeği doğrularsınız.
Birincil bölgenize geri yükleme (yeniden çalışma).
- İkincil bölgedeki tüm çalışmaları durdurun.
- Kurtarma yordamını birincil bölgede başlatın. Kurtarma yordamı, bağlantının ve ağ trafiğinin birincil bölgeye geri yönlendirilip yeniden adlandırılmasını işler.
- Gerektiğinde verileri birincil bölgeye yeniden çoğaltın. Karmaşıklığı azaltmak için, çoğaltılması gereken veri miktarını en aza indirin. Örneğin, bazı işler ikincil dağıtımda çalıştırıldığında salt okunur durumdaysa, bu verileri birincil bölgedeki birincil dağıtımınıza çoğaltmanız gerekmeyebilir. Ancak, çalıştırılması gereken bir üretim işiniz olabilir ve aynı zamanda verilerin birincil bölgeye çoğaltılması gerekiyor olabilir.
- Dağıtımı birincil bölgede test edin.
- Birincil bölgenizin çalışır durumda olduğunu ve etkin dağıtımınız olduğunu bildirin. Üretim iş yüklerini sürdürme.
Birincil bölgenize geri yükleme hakkında daha fazla bilgi için Geri yükleme testini (geri dönüş) kontrol edin.
Önemli
Bu adımlar sırasında bazı veri kayıpları oluşabilir. Kuruluşunuz ne kadar veri kaybının kabul edilebilir olduğunu ve bu kaybı azaltmak için neler yapabileceğinizi tanımlamalıdır.
1. Adım: İş gereksinimlerinizi anlama
İlk adımınız iş gereksinimlerinizi tanımlamak ve anlamaktır. Hangi veri hizmetlerinin kritik olduğunu ve beklenen RPO ve RTO'larının ne olduğunu tanımlayın.
Her sistemin gerçek dünya toleransını araştırın. Olağanüstü durum kurtarma, yük devretme ve yeniden çalışmanın maliyetli olabileceğini ve başka riskler taşıyabileceğini unutmayın. Diğer riskler arasında veri bozulması, veri yineleme (yanlış depolama konumuna yazarsanız) ve oturum açan ve yanlış yerlerde değişiklik yapan kullanıcılar yer alabilir.
İşletmenizi etkileyen tüm Azure Databricks tümleştirme noktalarını eşleyin:
- Olağanüstü durum kurtarma çözümünüzün etkileşimli işlemleri, otomatik işlemleri veya her ikisini birden barındırması gerekiyor mu?
- Hangi veri hizmetlerini kullanıyorsunuz? Bazıları kurum içi olabilir.
- Giriş verileri buluta nasıl ulaşıyor?
- Bu verileri kim kullanıyor? Hangi işlemler onu aşağı akışta tüketir?
- Olağanüstü durum kurtarma değişiklikleriyle ilgili bilgi sahibi olması gereken üçüncü taraf entegrasyonlar var mı?
Olağanüstü durum kurtarma planınızı destekleyebilecek araçları veya iletişim stratejilerini belirleyin:
- Ağ yapılandırmalarını hızla değiştirmek için hangi araçları kullanacaksınız?
- Yapılandırmanızı önceden tanımlayabilir ve olağanüstü durum kurtarma çözümlerini doğal ve sürdürülebilir bir şekilde barındırmak için modüler hale getirir misiniz?
- Hangi iletişim araçları ve kanalları, olağanüstü durum kurtarma yük devretme ve yeniden çalışma değişikliklerini iç ekiplere ve üçüncü taraflara (tümleştirmeler, aşağı akış tüketicileri) bildirir? Onaylarını nasıl onaylayacaksınız?
- Hangi araçlara veya özel desteğe ihtiyaç duyulacak?
- Kurtarma tamamlanana kadar varsa hangi hizmetler kapatılır?
2. Adım: İş gereksinimlerinizi karşılayan bir süreç seçin
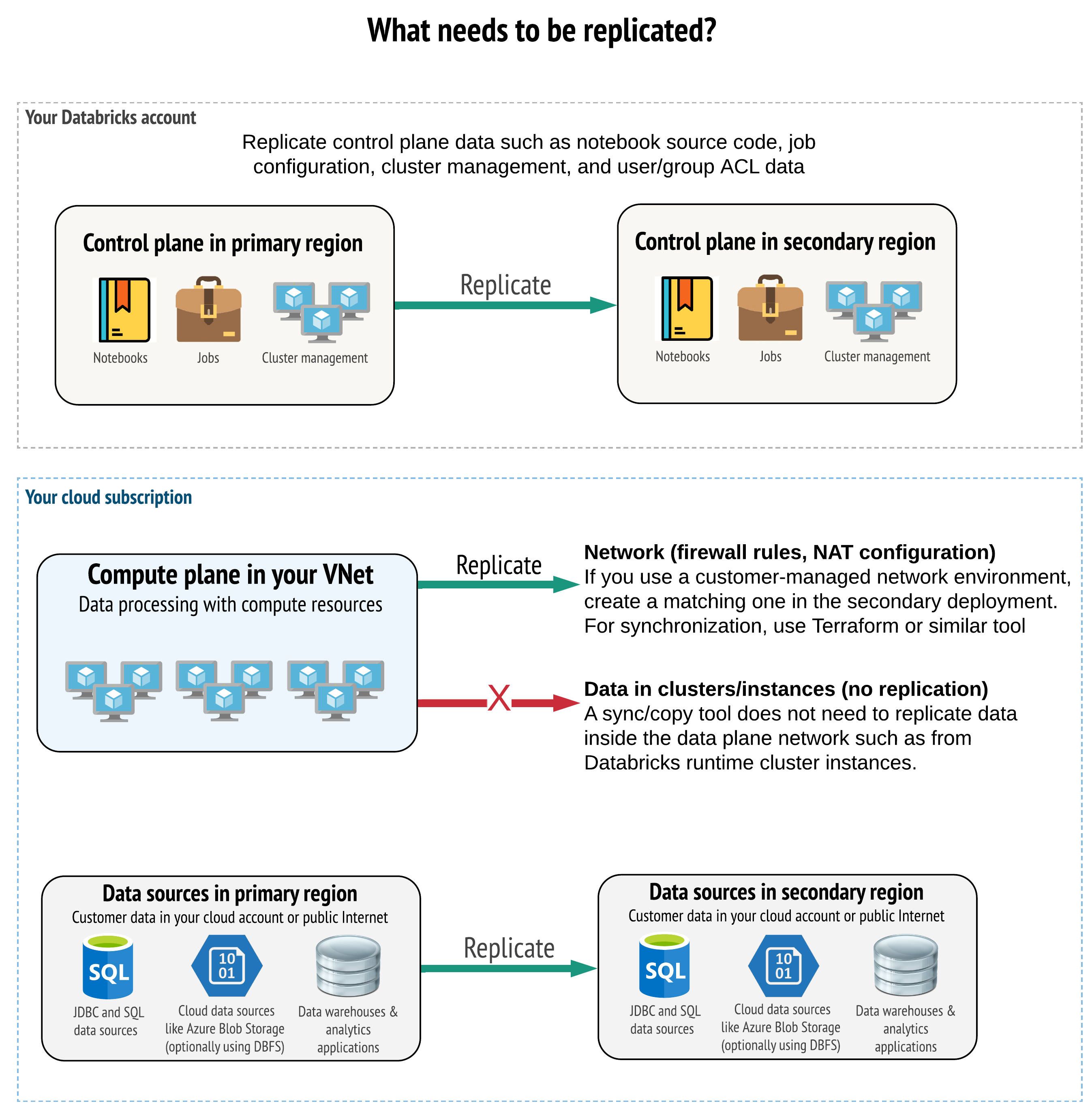
Çözümünüz kontrol düzlemi, işlem düzlemi ve veri kaynaklarında doğru verileri çoğaltmalıdır. Olağanüstü durum kurtarma için fazlalıklı çalışma alanları, farklı bölgelerdeki farklı denetim düzlemleriyle eşlenmelidir. Bir eşitleme aracı veya CI/CD iş akışı olmak üzere betik tabanlı bir çözüm kullanarak bu verileri düzenli aralıklarla eşitlenmiş durumda tutmanız gerekir. İşlem düzlemi ağının kendisinden (örneğin, Databricks Runtime çalışanlarından) veri eşitlemeye gerek yoktur.
Sanal ağ ekleme özelliğini kullanıyorsanız (tüm abonelik ve dağıtım türlerinde kullanılamaz), Terraform gibi şablon tabanlı araçları kullanarak bu ağları her iki bölgeye de tutarlı bir şekilde dağıtabilirsiniz.
Ayrıca, veri kaynaklarınızın bölgeler arasında gerektiğinde çoğaltıldığından emin olmanız gerekir.
Genel en iyi uygulamalar
Başarılı bir olağanüstü durum kurtarma planı için genel en iyi yöntemler şunlardır:
İşletme için kritik öneme sahip olan ve olağanüstü durum kurtarmada çalışması gereken işlemleri anlayın.
Hangi hizmetlerin dahil olduğunu, hangi verilerin işlendiğini, veri akışının ne olduğunu ve nerede depolandığını net bir şekilde belirleyin.
Hizmetleri ve verileri mümkün olduğunca yalıtın. Örneğin, olağanüstü durum kurtarma için veriler için özel bir bulut depolama kapsayıcısı oluşturun veya olağanüstü durum sırasında gereken Azure Databricks nesnelerini ayrı bir çalışma alanına taşıyın.
Databricks Denetim Düzleminde depolanmayan diğer nesneler için birincil ve ikincil dağıtımlar arasında bütünlüğü korumak sizin sorumluluğunuzdadır.
Uyarı
En iyi uygulama, 6 Mart 2023'ten önce oluşturulmuş çalışma alanları için DBFS kök erişimi amacıyla kullanılan kök ADLS'de (Azure Blob Depolama) veri depolamamanızdır. DBFS kök depolama alanı, üretim müşteri verileri için desteklenmiyor. Databricks ayrıca kitaplıkları, yapılandırma dosyalarını veya başlatma betiklerini bu konumda depolamamanızı önerir.
Mümkün olduğunca veri kaynakları için, verileri olağanüstü durum kurtarma bölgelerine çoğaltmak için çoğaltma ve yedeklilik için yerel Azure araçlarını kullanmanız önerilir.
Kurtarma çözümü stratejisi seçme
Tipik olağanüstü durum kurtarma çözümleri iki (veya muhtemelen daha fazla) çalışma alanı içerir. Çeşitli stratejiler arasından seçim yapabilirsiniz. Kesintinin olası uzunluğunu (saatler, hatta bir gün), çalışma alanının tamamen çalışır durumda olduğundan emin olma çabasını ve birincil bölgeye geri yükleme (yeniden çalışma) çabasını göz önünde bulundurun.
Aktif-pasif çözüm stratejisi
Etkin-pasif çözüm en yaygın ve en kolay çözümdür ve bu çözüm türü bu makalenin odağıdır. Etkin-pasif çözüm, etkin dağıtımınızdan pasif dağıtımınıza veri ve nesne değişikliklerini eşitler. İsterseniz, farklı bölgelerde birden çok pasif dağıtımınız olabilir, ancak bu makale tek pasif dağıtım yaklaşımına odaklanır. Olağanüstü durum kurtarma olayı sırasında ikincil bölgedeki pasif dağıtım, etkin dağıtımınız olur.
Bu stratejinin iki ana çeşidi vardır:
- Birleşik (kuruluş açısından) çözüm: Tam olarak kuruluşun tamamını destekleyen bir dizi etkin ve pasif dağıtım.
- Departmana veya projeye göre çözüm: Her departman veya proje etki alanı ayrı bir olağanüstü durum kurtarma çözümü tutar. Bazı kuruluşlar, departmanlar arasında olağanüstü durum kurtarma ayrıntılarını ayırmak ve her ekibin benzersiz ihtiyaçlarına göre her ekip için farklı birincil ve ikincil bölgeler kullanmak ister.
Salt okunur kullanım örnekleri için pasif dağıtım kullanma gibi başka çeşitlemeler de vardır. Örneğin, kullanıcı sorguları gibi salt okunur iş yükleriniz varsa, verileri veya not defterleri veya işler gibi Azure Databricks nesnelerini değiştirmemeleri durumunda herhangi bir zamanda pasif bir çözüm üzerinde çalışabilirler.
Etkin-etkin çözüm stratejisi
Etkin-etkin bir çözümde, her iki bölgede de tüm veri işlemlerini her zaman paralel olarak çalıştırırsınız. operasyon ekibiniz, iş gibi bir veri işleminin yalnızca her iki bölgede de başarıyla tamamlandığında tamamlandı olarak işaretlendiğinden emin olmalıdır. Nesneler üretimde değiştirilemez ve geliştirme/hazırlıktan üretime, sıkı bir CI/CD süreç takip edilmelidir.
Etkin-etkin bir çözüm en karmaşık stratejidir ve işler her iki bölgede de çalıştığından ek finansal maliyet vardır.
Aynı etkin-pasif stratejide olduğu gibi, bunu birleştirilmiş bir kuruluş çözümü olarak veya departmana göre uygulayabilirsiniz.
İş akışınıza bağlı olarak, ikincil sistemde tüm çalışma alanları için eşdeğer bir çalışma alanına ihtiyacınız olmayabilir. Örneğin, bir geliştirme ya da hazırlama çalışma alanının bir kopyasına ihtiyacı olmayabilir. İyi tasarlanmış bir geliştirme işlem hattıyla, gerekirse bu çalışma alanlarını kolayca yeniden yapılandırabilirsiniz.
Araçlarınızı seçin
Birincil ve ikincil bölgelerinizdeki çalışma alanları arasında verileri olabildiğince benzer tutmak için araçlara yönelik iki ana yaklaşım vardır:
- Birincil bölgeden ikincilye kopyalayan eşitleme istemcisi: Eşitleme istemcisi üretim verilerini ve varlıkları birincil bölgeden ikincil bölgeye yönlendirir. Bu, tipik olarak, zamanlanmış bir program dahilinde çalışır.
- Paralel dağıtım için CI/CD araçları: Üretim kodu ve varlıklar için, değişiklikleri üretim sistemlerine aynı anda her iki bölgeye de gönderen CI/CD araçlarını kullanın. Örneğin, kodu ve varlıkları hazırlama/geliştirme aşamasından üretime aktarırken, CI/CD sistemi bunu aynı anda her iki bölgede de kullanılabilir hale getirir. Temel fikir, Azure Databricks çalışma alanındaki tüm yapıtları kod olarak altyapı olarak ele almaktır. Çoğu yapıt hem birincil hem de ikincil çalışma alanlarına birlikte dağıtılabilirken, bazı yapıtların yalnızca olağanüstü durum kurtarma olayından sonra dağıtılması gerekebilir. Araçlar için bkz . Otomasyon betikleri, örnekler ve prototipler.
Aşağıdaki diyagramda bu iki yaklaşım karşıttır.
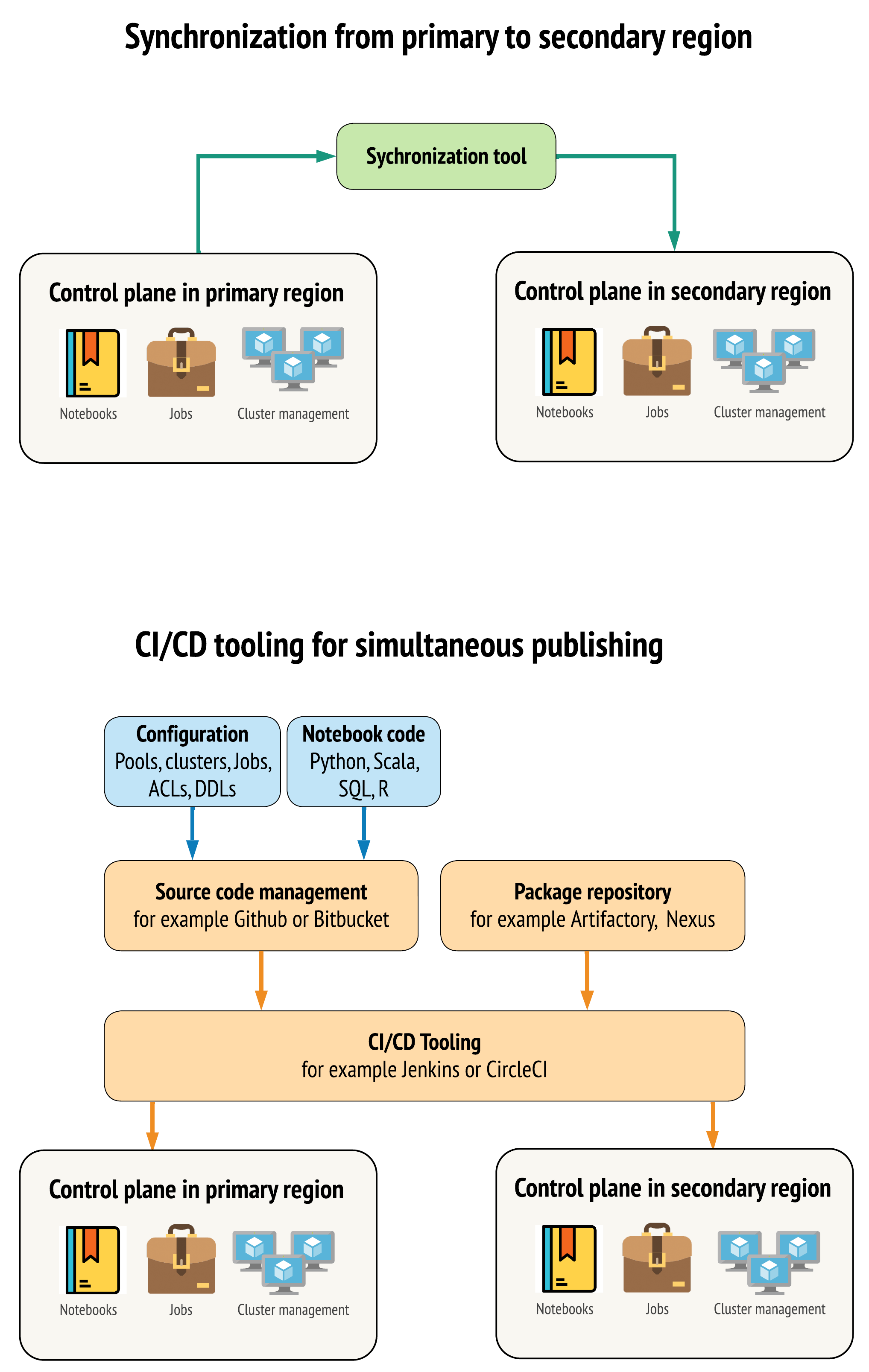
İhtiyaçlarınıza bağlı olarak yaklaşımları birleştirebilirsiniz. Örneğin, not defteri kaynak kodu için CI/CD kullanın, ancak havuzlar ve erişim denetimleri gibi yapılandırmalar için eşitleme kullanın.
Aşağıdaki tabloda, her araç seçeneğiyle farklı veri türlerinin nasıl işleneceğini açıklanmaktadır.
| Açıklama | CI/CD araçlarıyla işleme | Eşitleme aracıyla nasıl başa çıkılır |
|---|---|---|
| Kaynak kodu: paketlenmiş kitaplıklar için not defteri kaynak dışarı aktarmaları ve kaynak kodu | Hem birincil hem de ikincil olarak birlikte dağıtın. | Kaynak kodu birincilden ikincil koda eşitleyin. |
| Kullanıcılar ve gruplar | Git'te metadata'yı yapılandırma bilgisi olarak yönetin. Alternatif olarak, her iki çalışma alanı için de aynı kimlik sağlayıcısını (IdP) kullanın. Kullanıcı ve grup verilerini birincil ve ikincil dağıtımlara birlikte dağıtın. | Her iki bölge için SCIM veya başka bir otomasyon kullanın. El ile oluşturma önerilmez, ancak kullanılması gerekiyorsa her ikisi için de aynı anda yapılmalıdır. El ile kurulum kullanıyorsanız, iki dağıtım arasındaki kullanıcı ve grupların listesini karşılaştırmak için zamanlanmış bir otomatik işlem oluşturun. |
| Havuz yapılandırmaları | Git'teki şablonlar olabilir. Birincil ve ikincil yerlere eşzamanlı dağıtım yapın. Ancak, min_idle_instances olağanüstü durum kurtarma olayına kadar ikincil olarak sıfır olmalıdır. |
API veya CLI kullanılarak ikincil bir çalışma alanına senkronize edildiklerinde, herhangi bir min_idle_instances ile oluşturulan havuzlar. |
| İş yapılandırmaları | Git'teki şablonlar olabilir. Birincil dağıtım için iş tanımını olduğu gibi dağıtın. İkincil dağıtım için işi dağıtın ve eşzamanlılığı sıfır olarak ayarlayın. Bu, bu dağıtımdaki görevi devre dışı bırakır ve gereksiz çalıştırmaları önler. İkincil dağıtım etkin hale geldikten sonra eşzamanlılık değerini değiştirin. | İşler bir nedenden dolayı var olan <interactive> kümelerde çalıştırılırsa, eşitleme istemcisinin ikincil çalışma alanında karşılık gelen cluster_id ile eşleşmesi gerekir. |
| Erişim denetim listeleri (ACL’ler) | Git'teki şablonlar olabilir. Not defterleri, klasörler ve kümeler için birincil ve ikincil dağıtımlara birlikte dağıtın. Ancak, olağanüstü durum kurtarma olayına kadar işlerin verilerini tutun. | İzinler API'si kümeler, işler, havuzlar, not defterleri ve klasörler için erişim denetimleri ayarlayabilir. Eşitleme istemcisinin, ikincil çalışma alanındaki her nesneyi karşılık gelen nesne kimlikleriyle eşlemesi gerekir. Databricks, erişim denetimlerini çoğaltmadan önce bu nesneleri eşitlerken birincil çalışma alanından ikincil çalışma alanına nesne kimliklerinin eşlemini oluşturmanızı önerir. |
| Kitaplıklar | Kaynak koduna ve küme/iş şablonlarına ekleyin. | Merkezi depolardan, DBFS'den veya bulut depolamadan özel kitaplıkları eşitleyin (bağlanabilir). |
| Küme başlatma betikleri | İsterseniz kaynak koduna ekleyin. | Daha basit eşitleme için, başlangıç betiklerini birincil çalışma alanında ortak bir klasörde veya mümkünse küçük bir klasör kümesinde depolayın. |
| Bağlama noktaları | Yalnızca not defteri tabanlı işler veya Komut API'si aracılığıyla oluşturulduysa kaynak koduna ekleyin. | Azure Data Factory (ADF) etkinlikleri olarak çalıştırabileceğiniz işleri kullanın. Çalışma alanlarının farklı bölgelerde olması durumunda depolama uç noktalarının değişebileceğini unutmayın. Bu, veri olağanüstü durum kurtarma stratejinize de çok bağlıdır. |
| Tablo meta verileri | Yalnızca not defteri tabanlı işler veya Komut API'siyle oluşturulduysa kaynak koduna ekleyin. Bu, hem iç Azure Databricks meta veri deposu hem de dış yapılandırılmış meta veri deposu için geçerlidir. | Spark Katalog API'sini kullanarak meta veri depoları arasındaki meta veri tanımlarını karşılaştırın veya not defteri veya betikler aracılığıyla Tablo Oluştur'u gösterin. Depolamanın altında yatan tabloların bölge tabanlı olabileceğini ve metastore örnekleri arasında farklı olacağını unutmayın. |
| Sırlar | Yalnızca Komut API'si aracılığıyla oluşturulduysa kaynak koduna ekleyin. Bazı gizli içeriklerin birincil ve ikincil arasında değişmesi gerekebileceğini unutmayın. | Gizli bilgiler, API kullanılarak her iki çalışma alanında oluşturulur. Bazı gizli içeriklerin birincil ve ikincil arasında değişmesi gerekebileceğini unutmayın. |
| Küme yapılandırmaları | Git'teki şablonlar olabilir. Birincil ve ikincil dağıtımlara birlikte dağıtın, ancak ikincil dağıtımdakiler olağanüstü durum kurtarma olayına kadar durdurulmalıdır. | Kümeler, API veya CLI kullanılarak ikincil çalışma alanıyla eşitlendikten sonra oluşturulur. Otomatik sonlandırma ayarlarına bağlı olarak isterseniz bunlar açıkça sonlandırılabilir. |
| Not defteri, iş ve klasör izinleri | Git'teki şablonlar olabilir. Birincil ve ikincil dağıtımlara eş zamanlı dağıtım. | İzinler API'sini kullanarak çoğaltın. |
Bölgeleri ve birden çok ikincil çalışma alanını seçme
Olağanüstü durum kurtarma tetikleyicinizin tam denetimine sahip olmanız gerekir. Bunu istediğiniz zaman veya herhangi bir nedenle tetikleme kararı alabilirsiniz. yeniden çalışma (normal üretim) modunda işleminizi yeniden başlatabilmeniz için önce olağanüstü durum kurtarma sabitleme sorumluluğunu üstlenmeniz gerekir. Bu genellikle üretim ve olağanüstü durum kurtarma gereksinimlerinizi karşılamak için birden çok Azure Databricks çalışma alanı oluşturmanız ve ikincil yük devretme bölgenizi seçmeniz gerektiği anlamına gelir.
Azure'da veri çoğaltmanızın yanı sıra ürün ve VM türlerinin kullanılabilirliğini denetleyin.
3. Adım: Çalışma alanlarını hazırlama ve tek seferlik kopyalama yapma
Çalışma alanı zaten üretimdeyse pasif dağıtımınızı etkin dağıtımınızla eşitlemek için tek seferlik kopyalama işlemi çalıştırmak normaldir. Bu tek seferlik kopyalama aşağıdaki işlemleri yapar:
- Veri çoğaltma: Bulut çoğaltma çözümü veya Delta Derin Kopyalama işlemi kullanarak çoğaltma.
- Belirteç oluşturma: Çoğaltmayı ve gelecekteki iş yüklerini otomatikleştirmek için belirteç oluşturmayı kullanın.
- Çalışma alanı çoğaltması: 4. Adım: Veri kaynaklarınızı hazırlama başlığı altında açıklanan yöntemleri kullanarak çalışma alanı çoğaltmasını kullanın. Çalışma alanı yapılandırmasını, verilerini ve AI/ML varlıklarını dışarı aktarma hakkında kapsamlı yönergeler için bkz. Çalışma alanı verilerini dışarı aktarma.
- Çalışma alanı doğrulaması: - Çalışma alanının ve işlemin başarıyla yürütülediğinden ve beklenen sonuçları sağlayabildiğinden emin olmak için test edin.
sonraki kopyalama ve eşitleme eylemleri, ilk tek seferlik kopyalama işleminizden sonra daha hızlı olur. Araçlarınızın tüm günlükleri, neyin ne zaman değiştiğini de kaydeder.
4. Adım: Veri kaynaklarınızı hazırlama
Azure Databricks toplu işlem veya veri akışları kullanarak çok çeşitli veri kaynaklarını işleyebilir.
Veri kaynaklarından toplu işleme
Veriler toplu olarak işlendiğinde, genellikle kolayca çoğaltılabilen veya başka bir bölgeye teslim edilebilen bir veri kaynağında bulunur.
Örneğin, veriler düzenli olarak bir bulut depolama konumuna yüklenebilir. İkincil bölgeniz için olağanüstü durum kurtarma modunda, dosyaların ikincil bölge depolama alanınıza yüklendiğinden emin olmanız gerekir. İş yüklerinin ikincil bölge depolama alanından okuması ve ikincil bölge depolama alanına yazması gerekir.
Veri akışları
Veri akışını işlemek daha büyük bir zorluk. Akış verileri çeşitli kaynaklardan alınıp işlenebilir ve bir akış çözümüne gönderilebilir:
- Kafka gibi mesaj kuyruğu
- Veritabanı değişim verisi yakalama akışı
- Dosya tabanlı sürekli işleme
- Dosya tabanlı zamanlanmış işleme, tek seferlik tetikleyici olarak da bilinir.
Tüm bu durumlarda, veri kaynaklarınızı olağanüstü durum kurtarma modunu işleyecek ve ikincil dağıtımınızı ikincil bölgenizde kullanacak şekilde yapılandırmanız gerekir.
Akış yazıcısı, işlenen veriler hakkında bilgi içeren bir kontrol noktası depolar. Bu denetim noktası, akışın başarıyla yeniden başlatılmasını sağlamak için yeni bir konuma değiştirilmesi gereken bir veri konumu (genellikle bulut depolaması) içerebilir. Örneğin, denetim noktasının source altındaki alt klasör dosya tabanlı bulut klasörünü depolayabilir.
Bu denetim noktası zamanında çoğaltılmalıdır. Herhangi bir yeni bulut çoğaltma çözümüyle denetim noktası aralığını eşitlemeyi göz önünde bulundurun.
Kontrol noktası güncellemesi yazıcının bir işlevidir, dolayısıyla veri akışının alınması veya işlenmesi ve başka bir akış kaynağında depolanması için geçerlidir.
Akış iş yükleri için denetim noktalarının müşteri tarafından yönetilen depolama alanında yapılandırıldığından emin olun; böylece son hata noktasından iş yükü yeniden başlatma için ikincil bölgeye çoğaltılabilir. İkincil akış işlemini birincil işleme paralel olarak çalıştırmayı da seçebilirsiniz.
5. Adım: Çözümünüzü uygulama ve test edin
Düzgün çalıştığından emin olmak için olağanüstü durum kurtarma kurulumunuzu düzenli aralıklarla test edin. İhtiyacınız olduğunda kullanamıyorsanız olağanüstü durum kurtarma çözümünü korumanın bir değeri yoktur. Bazı şirketler birkaç ayda bir bölgeler arasında geçiş yapabilir. Düzenli bir zamanlamaya göre bölgeler arasında geçiş yapmak varsayımlarınızı ve süreçlerinizi test eder ve kurtarma gereksinimlerinizi karşıladığından emin olur. Bu, kuruluşunuzun acil durumlarla ilgili politikalar ve yordamlar hakkında bilgi sahibi olmasını da sağlar.
Önemli
Olağanüstü durum kurtarma çözümünüzü gerçek dünya koşullarında düzenli olarak test edin.
Bir nesnenin veya şablonun eksik olduğunu fark ederseniz ve yine de birincil çalışma alanınızda depolanan bilgilere güvenmeniz gerekiyorsa, planınızı değiştirerek bu engelleri kaldırın, bu bilgileri ikincil sistemde çoğaltın veya başka bir şekilde kullanılabilir hale getirin.
İşlemlerinizde ve genel olarak yapılandırmada gerekli kuruluş değişikliklerini test edin. Olağanüstü durum kurtarma planınız dağıtım işlem hattınızı etkiler ve ekibinizin nelerin eşitlenmiş tutulması gerektiğini bilmesi önemlidir. Olağanüstü durum kurtarma çalışma alanlarınızı ayarladıktan sonra altyapınızın (el ile veya kod), işlerinizin, not defterinizin, kitaplıklarınızın ve diğer çalışma alanı nesnelerinin ikincil bölgenizde kullanılabilir olduğundan emin olmanız gerekir.
Değişiklikleri tüm çalışma alanlarına dağıtmak için standart iş süreçlerini ve yapılandırma işlem hatlarını genişletme hakkında ekibinizle görüşün. Tüm çalışma alanlarında kullanıcı kimliklerini yönetin. yeni çalışma alanları için iş otomasyonu ve izleme gibi araçları yapılandırmayı unutmayın.
Yapılandırma araçlarındaki değişiklikleri planlayın ve test edin:
- Veri alımı: Veri kaynaklarınızın nerede olduğunu ve bu kaynakların verilerini nereden edindiği hakkında bilgi edinin. Mümkün olduğunda kaynağı parametreleştirin ve ikincil dağıtımlarınız ve ikincil bölgelerinizle çalışmak için ayrı bir yapılandırma şablonunuz olduğundan emin olun. Kesinti durumunda hizmet devamlılığı için bir plan hazırlayın ve tüm varsayımları test edin.
- Yürütme değişiklikleri: İşleri veya diğer eylemleri tetikleyen bir zamanlayıcınız varsa, ikincil dağıtım veya veri kaynaklarıyla çalışan ayrı bir zamanlayıcı yapılandırmanız gerekebilir. Kesinti durumunda hizmet devamlılığı için bir plan hazırlayın ve tüm varsayımları test edin.
- Etkileşimli bağlantı: REST API'lerinin, CLI araçlarının veya JDBC/ODBC gibi diğer hizmetlerin kullanımı için yapılandırma, kimlik doğrulaması ve ağ bağlantılarının bölgesel kesintilerden nasıl etkilenebileceğini göz önünde bulundurun. Kesinti durumunda hizmet devamlılığı için bir plan hazırlayın ve tüm varsayımları test edin.
- Otomasyon değişiklikleri: Tüm otomasyon araçları için yük devretme için bir plan hazırlayın ve tüm varsayımları test edin.
- Çıkışlar: Çıkış verileri veya günlükleri oluşturan araçlar için yük devretme için bir plan hazırlayın ve tüm varsayımları test edin.
Yük devretme testi
Olağanüstü durum kurtarma birçok farklı senaryo tarafından tetiklenebilir. Beklenmeyen bir kesmeyle tetiklenebilir. Bulut ağı, bulut depolama alanı veya başka bir çekirdek hizmet gibi bazı temel işlevler devre dışı olabilir. Sistemi düzgün bir şekilde kapatmaya erişiminiz yok ve sistemi kurtarmaya çalışmalısınız. Ancak işlem, kapatma veya planlı kesinti veya hatta iki bölge arasındaki etkin dağıtımlarınızın düzenli olarak değiştirilmesiyle tetiklenebilir.
Yedekleme modunu test ettiğinizde sisteme bağlanın ve sistemi kapatmaya yönelik bir işlem başlatın. Tüm işlerin tamamlandığından ve kümelerin sonlandırıldığından emin olun.
Eşitleme istemcisi (veya CI/CD araçları), ilgili Azure Databricks nesnelerini ve kaynaklarını ikincil çalışma alanına çoğaltabilir. İkincil çalışma alanınızı etkinleştirmek için, işleminiz aşağıdakilerden bazılarını veya tümünü içerebilir:
- Platformun güncel olduğunu doğrulamak için testler çalıştırın.
- Birincil bölgedeki havuzları ve kümeleri devre dışı bırakın, böylece başarısız olan hizmet çevrimiçi olduğunda birincil bölge yeni verileri işlemeye başlamaz.
- Kurtarma işlemi:
- En son eşitlenen verilerin tarihini denetleyin. Bkz . Olağanüstü durum kurtarma sektörü terminolojisi. Bu adımın ayrıntıları, verileri nasıl eşitlediğinize ve benzersiz iş gereksinimlerinize bağlı olarak değişir.
- Veri kaynaklarınızı kararlı hale getirerek bunların tümünün kullanılabilir olduğundan emin olun. Azure Cloud SQL gibi tüm dış veri kaynaklarını ve Delta Lake, Parquet veya diğer dosyaları dahil edin.
- Akış geri yükleme noktanızı bulun. İşlemi oradan yeniden başlatacak şekilde ayarlayın ve olası yinelemeleri tanımlayıp ortadan kaldırmaya hazır bir işlem oluşturun (Delta Lake bunu kolaylaştırır).
- Veri akışı işlemini tamamlayın ve kullanıcıları bilgilendirin.
- İlgili havuzları başlatın (veya ilgili bir sayıya yükseltin
min_idle_instances). - İlgili kümeleri başlatın (sonlandırılmamışsa).
- İşlerin eşzamanlı yürütme ayarını değiştirin ve ilgili işleri başlatın. Bunlar tek seferlik çalıştırmalar veya düzenli çalıştırmalar olabilir.
- Azure Databricks çalışma alanınız için URL veya etki alanı adı kullanan herhangi bir dış araç için yapılandırmaları yeni denetim düzlemini hesaba katma amacıyla güncelleştirin. Örneğin REST API'leri ve JDBC/ODBC bağlantıları için URL'leri güncelleştirin. Denetim düzlemi değiştiğinde Azure Databricks web uygulamasının müşteriye yönelik URL'si değiştiğinden kuruluşunuzun kullanıcılarına yeni URL'yi bildirin.
Geri yüklemeyi test edin (geriye dönüş)
Geri dönüş sürecinin kontrolü daha kolaydır ve bakım penceresinde yapılabilir. Bu plan aşağıdakilerden bazılarını veya tümünü içerebilir:
- Ana bölgenin geri yüklendiğine dair onayı alın.
- Yeni verileri işlemeye başlamaması için ikincil bölgede havuzları ve kümeleri devre dışı bırakın.
- İkincil çalışma alanında bulunan yeni veya değiştirilmiş varlıkları birincil dağıtıma geri eşitleyin. Yedekleme betiklerinizin tasarımına bağlı olarak, ikincil (olağanüstü durum kurtarma) bölgesinden birincil (üretim) bölgeye nesneleri senkronize etmek için aynı betikleri çalıştırabilirsiniz.
- Yeni veri güncelleştirmelerini birincil dağıtıma geri eşitleyin. Veri kaybını önlemek için günlüklerin ve Delta tablolarının denetim izlerini kullanabilirsiniz.
- Olağanüstü durum kurtarma bölgesindeki tüm iş yüklerini kapatın.
- İşleri ve kullanıcıların URL'sini birincil bölgeye değiştirin.
- Platformun güncel olduğunu doğrulamak için testler çalıştırın.
- İlgili havuzları başlatın (veya ilgili bir sayıya yükseltin
min_idle_instances). - İlgili kümeleri başlatın (sonlandırılmamışsa).
- İşler için eşzamanlı yürütmeyi değiştirin ve ilgili işleri başlatın. Bunlar tek seferlik çalıştırmalar veya düzenli çalıştırmalar olabilir.
- Gerektiğinde, gelecekteki olağanüstü durum kurtarma için ikincil bölgenizi yeniden ayarlayın.
Otomasyon betikleri, örnekler ve prototipler
Olağanüstü durum kurtarma projeleriniz için göz önünde bulundurmanız gereken otomasyon betikleri:
- Databricks, kendi eşitleme işleminizi geliştirmenize yardımcı olması için Databricks Terraform Sağlayıcısı'nı kullanmanızı önerir.
- Ayrıca örnek ve prototip betikler için Databricks Çalışma Alanı Geçiş Araçları'na bakınız. Azure Databricks nesnelerine ek olarak, tüm ilgili Azure Data Factory işlem hatlarını çoğaltarak ikincil çalışma alanına eşlenen bağlı bir hizmete başvurmalarını sağlayın.
- Databricks Sync (DBSync) projesi, Databricks çalışma alanlarını yedekleyen, geri yükleyen ve eşitleyen bir nesne eşitleme aracıdır.