Azure Databricks’te Eski MLflow Model Sunma
Önemli
Bu özellik Genel Önizlemededir.
Önemli
- Bu belge kullanımdan kaldırılmıştır ve güncelleştirilmeyebilir. Bu içerikte belirtilen ürünler, hizmetler veya teknolojiler artık desteklenmemektedir.
- Bu makaledeki yönergeler Eski MLflow Modeli Sunma'ya yöneliktir. Databricks, gelişmiş model uç noktası dağıtımı ve ölçeklenebilirliği için model sunum iş akışlarınızı Model Sunma'ya geçirmenizi önerir. Daha fazla bilgi için bkz . Azure Databricks ile hizmet veren model.
Eski MLflow Model Sunma, Model Kayıt Defteri'nden makine öğrenmesi modellerini model sürümlerinin kullanılabilirliğine ve aşamalarına göre otomatik olarak güncelleştirilen REST uç noktaları olarak barındırmanıza olanak tanır. Artık klasik işlem düzlemi olarak adlandırılan hesapta kendi hesabınız altında çalışan tek düğümlü bir küme kullanır. Bu işlem düzlemi, sanal ağı ve not defterleri ve işler için kümeler, profesyonel ve klasik SQL ambarları ve Uç noktaları sunan Eski model gibi ilişkili işlem kaynaklarını içerir.
Belirli bir kayıtlı model için model sunumunu etkinleştirdiğinizde, Azure Databricks model için otomatik olarak benzersiz bir küme oluşturur ve modelin arşivlenmemiş tüm sürümlerini bu kümeye dağıtır. Azure Databricks, bir hata oluşursa kümeyi yeniden başlatır ve model için model sunumunu devre dışı bırakdığınızda kümeyi sonlandırır. Hizmet veren model, Model Kayıt Defteri ile otomatik olarak eşitlenir ve tüm yeni kayıtlı model sürümlerini dağıtır. Dağıtılan model sürümleri standart bir REST API isteğiyle sorgulanabilir. Azure Databricks, standart kimlik doğrulamasını kullanarak modele yönelik isteklerin kimliğini doğrular.
Bu hizmet önizleme aşamasındayken Databricks düşük aktarım hızı ve kritik olmayan uygulamalar için kullanılmasını önerir. Hedef aktarım hızı 200 q/sn ve hedef kullanılabilirlik %99,5'tir, ancak her ikisinde de garanti verilmez. Ayrıca, istek başına 16 MB yük boyutu sınırı vardır.
Her model sürümü MLflow modeli dağıtımı kullanılarak dağıtılır ve bağımlılıkları tarafından belirtilen bir Conda ortamında çalışır.
Not
- Etkin model sürümü olmasa bile hizmet etkin olduğu sürece küme korunur. Hizmet veren kümeyi sonlandırmak için kayıtlı model için model sunumunu devre dışı bırakın.
- Küme, tüm amaçlı iş yükü fiyatlandırmasına tabi olan, çok amaçlı bir küme olarak kabul edilir.
- Genel başlatma betikleri , kümelere hizmet veren modelde çalıştırılmaz.
Önemli
Anaconda Inc. anaconda.org kanalları için hizmet koşullarını güncelleştirdi. Yeni hizmet koşullarına bağlı olarak, Anaconda'nın paketleme ve dağıtımına güveniyorsanız ticari lisansa ihtiyacınız olabilir. Daha fazla bilgi için bkz . Anaconda Commercial Edition SSS . Herhangi bir Anaconda kanalını kullanımınız, hizmet koşullarına tabidir.
v1.18(Databricks Runtime 8.3 ML veya öncesi) öncesinde günlüğe kaydedilen MLflow modelleri varsayılan olarak conda defaults kanalıyla (https://repo.anaconda.com/pkgs/) bağımlılık olarak günlüğe kaydedilir. Bu lisans değişikliği nedeniyle Databricks, MLflow v1.18 ve üzeri kullanılarak günlüğe kaydedilen modeller için kanalın defaults kullanımını durdurdu. Günlüğe kaydedilen varsayılan kanal, conda-forgetopluluk tarafından yönetilen https://conda-forge.org/öğesine işaret eden şeklindedir.
MLflow v1.18'den önce kanalı modelin conda ortamından dışlamadan defaults bir modeli günlüğe kaydetmişseniz, bu modelin defaults kanala yönelik olarak amaçlamadığınız bir bağımlılığı olabilir.
Modelin bu bağımlılıkta olup olmadığını el ile onaylamak için, günlüğe kaydedilen modelle paketlenmiş dosyadaki conda.yaml değeri inceleyebilirsinizchannel. Örneğin, kanal bağımlılığı olan bir defaults model conda.yaml aşağıdaki gibi görünebilir:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Databricks, Anaconda ile olan ilişkiniz kapsamında Anaconda deposunu kullanarak modellerinizle etkileşim kurmanıza izin verilip verilmeyeceğini belirleyemediğinden, Databricks müşterilerini herhangi bir değişiklik yapmaya zorlamaz. Databricks'in kullanımı aracılığıyla Anaconda.com depoyu kullanımınıza Anaconda'nın koşulları altında izin verilirse herhangi bir işlem yapmanız gerekmez.
Modelin ortamında kullanılan kanalı değiştirmek isterseniz, modeli yeni conda.yamlbir ile model kayıt defterine yeniden kaydedebilirsiniz. Kanalı parametresinde conda_envlog_model()belirterek bunu yapabilirsiniz.
API hakkında log_model() daha fazla bilgi için, üzerinde çalıştığınız model çeşidine ilişkin MLflow belgelerine (örneğin, scikit-learn için log_model) bakın.
Dosyalar hakkında conda.yaml daha fazla bilgi için MLflow belgelerine bakın.
Gereksinimler
- Eski MLflow Model Sunma, Python MLflow modellerinde kullanılabilir. Conda ortamındaki tüm model bağımlılıklarını bildirmeniz gerekir. Bkz . Günlük modeli bağımlılıkları.
- Model Sunma'yı etkinleştirmek için küme oluşturma izniniz olmalıdır.
Model Kayıt Defteri'nden model sunma
Model sunma, Azure Databricks'te Model Kayıt Defteri'nden kullanılabilir.
Model sunumlarını etkinleştirme ve devre dışı bırakma
Bir modelin kayıtlı model sayfasından sunulmasını sağlarsınız.
Sunum sekmesine tıklayın. Model sunum için henüz etkinleştirilmemişse, Sunma özelliğini etkinleştir düğmesi görüntülenir.
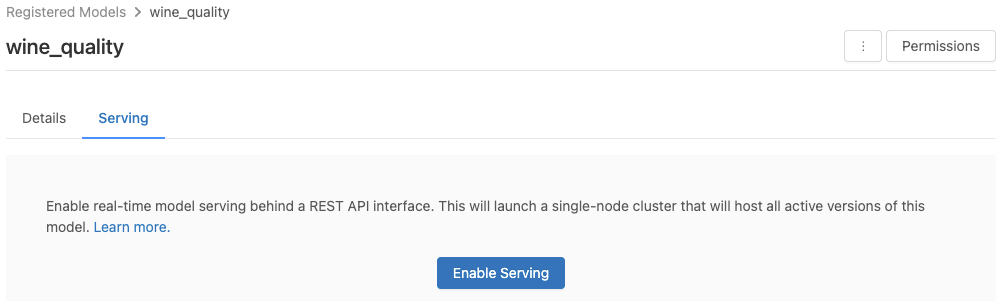
Sunulmasını Etkinleştir'e tıklayın. Sunum sekmesi , Durum Beklemede olarak gösterilir. Birkaç dakika sonra Durum, Hazır olarak değişir.
Bir modeli kullanıma sunma amacıyla devre dışı bırakmak için Durdur'a tıklayın.
Model sunumlarını doğrulama
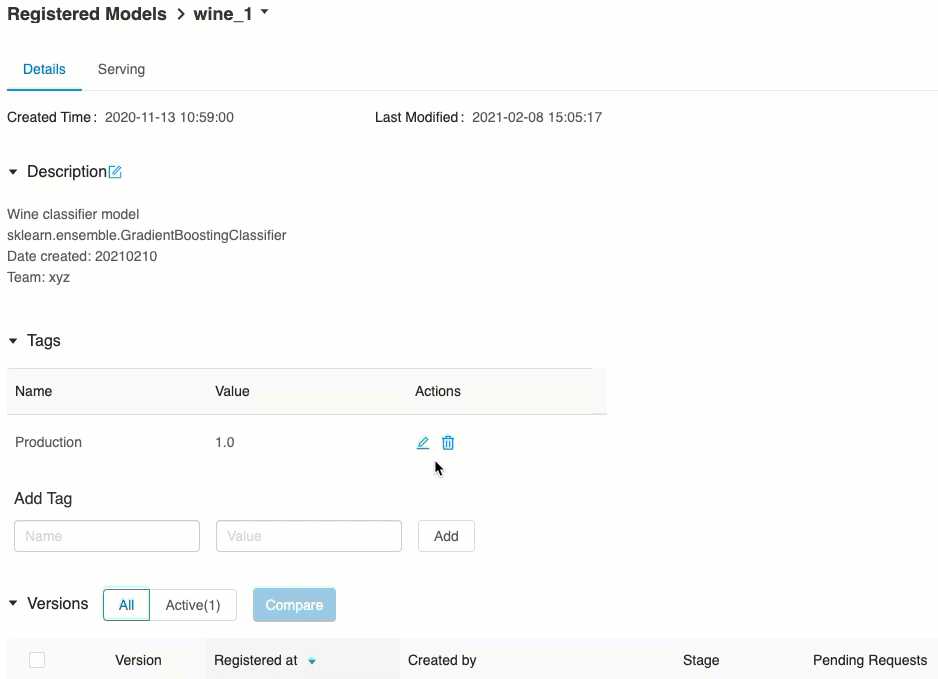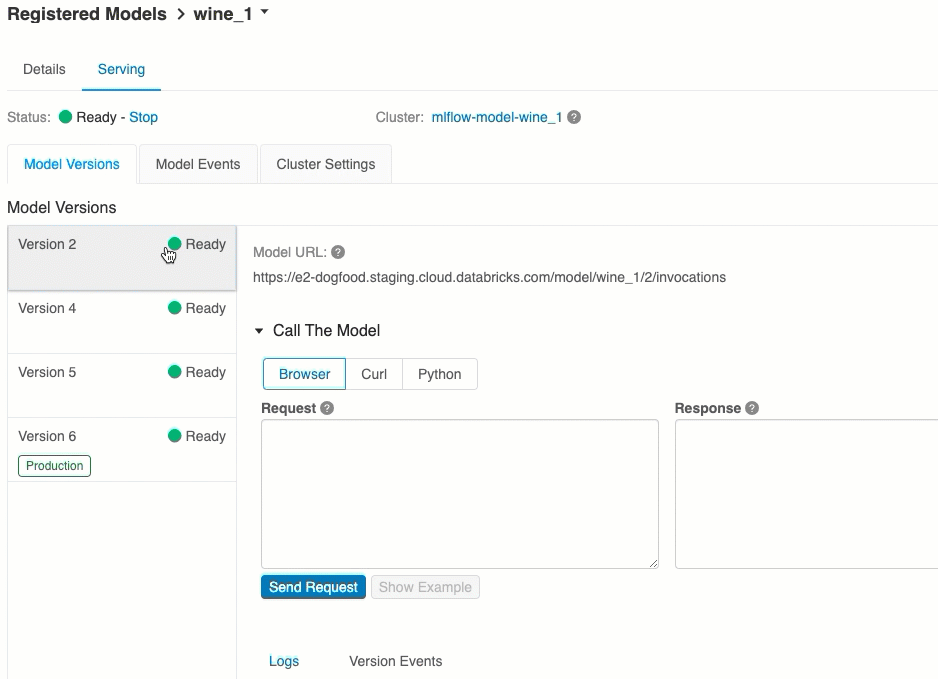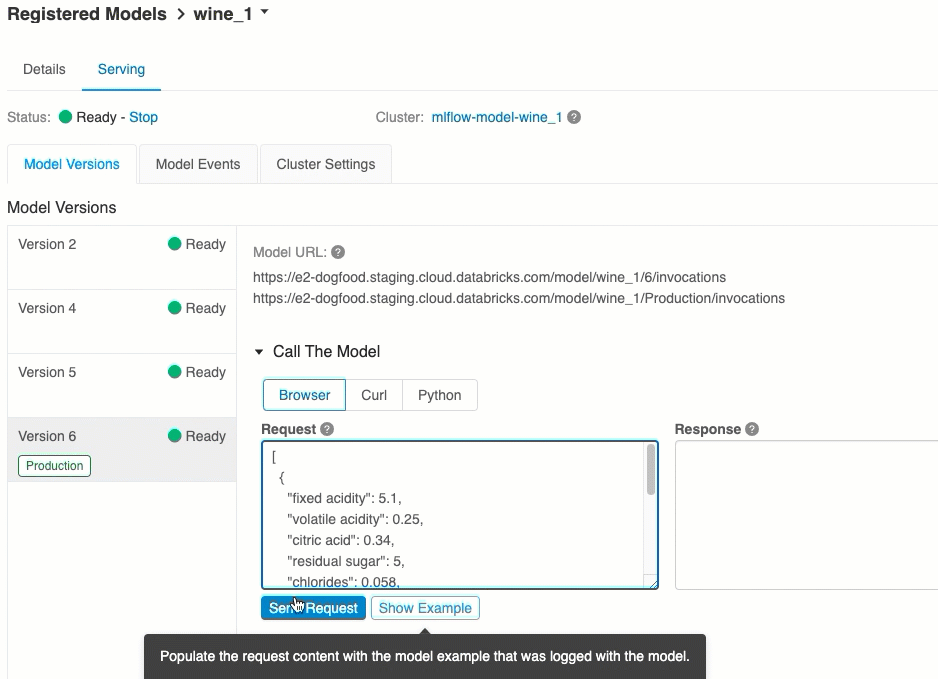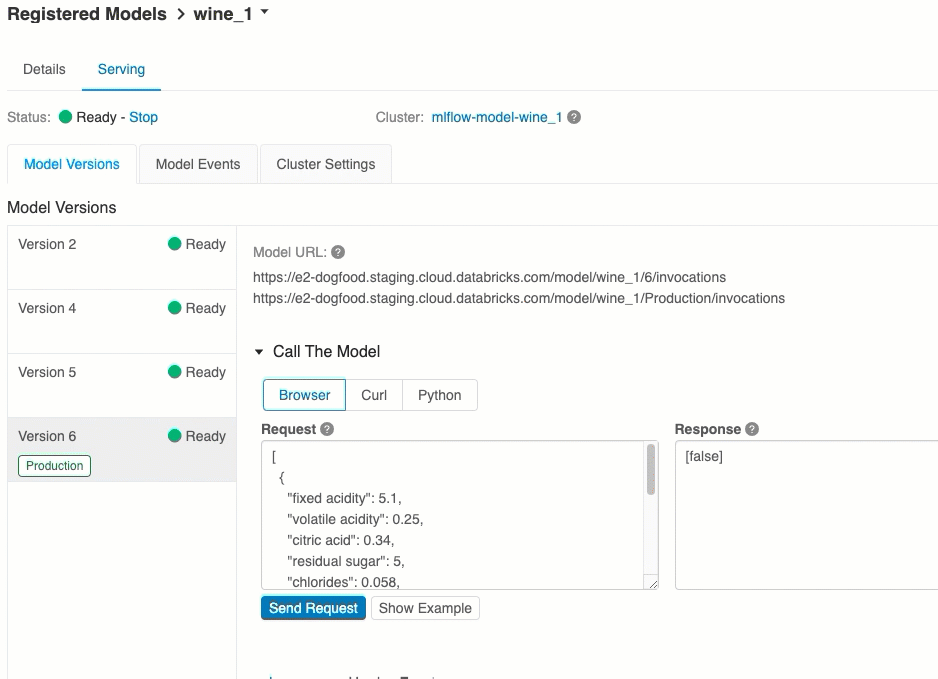
Sunum sekmesinden sunulan modele istek gönderebilir ve yanıtı görüntüleyebilirsiniz.
Model sürümü URI'leri
Dağıtılan her model sürümüne bir veya birkaç benzersiz URI atanır. En azından, her model sürümüne aşağıdaki gibi oluşturulmuş bir URI atanır:
<databricks-instance>/model/<registered-model-name>/<model-version>/invocations
Örneğin, olarak iris-classifierkaydedilen bir modelin 1. sürümünü çağırmak için şu URI'yi kullanın:
https://<databricks-instance>/model/iris-classifier/1/invocations
Ayrıca, bir model sürümünü aşamasına göre çağırabilirsiniz. Örneğin, sürüm 1 Üretim aşamasındaysa, bu URI kullanılarak da puanlanabilir:
https://<databricks-instance>/model/iris-classifier/Production/invocations
Kullanılabilir model URI'lerinin listesi, sunum sayfasındaki Model Sürümleri sekmesinin en üstünde görünür.
Sunulan sürümleri yönetme
Tüm etkin (arşivlenmemiş) model sürümleri dağıtılır ve bunları URI'leri kullanarak sorgulayabilirsiniz. Azure Databricks, yeni model sürümlerini kaydedildiğinde otomatik olarak dağıtır ve arşivlendiğinde eski sürümleri otomatik olarak kaldırır.
Not
Kayıtlı modelin dağıtılan tüm sürümleri aynı kümeyi paylaşır.
Model erişim haklarını yönetme
Model erişim hakları Model Kayıt Defteri'nden devralınır. Sunum özelliğinin etkinleştirilmesi veya devre dışı bırakılması için kayıtlı modelde 'yönetme' izni gerekir. Okuma hakları olan herkes dağıtılan sürümlerden herhangi birini puanlayabilir.
Dağıtılan model sürümlerini puanla
Dağıtılan modeli puanlamak için kullanıcı arabirimini kullanabilir veya model URI'sine rest API isteği gönderebilirsiniz.
Kullanıcı arabirimi aracılığıyla puanla
Bu, modeli test etmenin en kolay ve en hızlı yoludur. Model giriş verilerini JSON biçiminde ekleyebilir ve İstek Gönder'e tıklayabilirsiniz. Model bir giriş örneğiyle günlüğe kaydedildiyse (yukarıdaki grafikte gösterildiği gibi), giriş örneğini yüklemek için Örneği Yükle'ye tıklayın.
REST API isteğiyle puan
Standart Databricks kimlik doğrulamasını kullanarak REST API aracılığıyla puanlama isteği gönderebilirsiniz. Aşağıdaki örneklerde, MLflow 1.x ile kişisel erişim belirteci kullanılarak kimlik doğrulaması gösterilmektedir.
Not
En iyi güvenlik uygulaması olarak otomatik araçlar, sistemler, betikler ve uygulamalarla kimlik doğrulaması yaptığınızda Databricks, çalışma alanı kullanıcıları yerine hizmet sorumlularına ait kişisel erişim belirteçlerini kullanmanızı önerir. Hizmet sorumlularına yönelik belirteçler oluşturmak için bkz . Hizmet sorumlusu için belirteçleri yönetme.
Bir MODEL_VERSION_URI benzeri (Burada <databricks-instance> Databricks örneğinizin adıdır) ve adlı DATABRICKS_API_TOKENbir Databricks REST API belirteci verildiğinde, aşağıdaki örneklerde sunulan modelin nasıl sorgulandığı gösterilmektedir https://<databricks-instance>/model/iris-classifier/Production/invocations :
Aşağıdaki örnekler, MLflow 1.x ile oluşturulan modeller için puanlama biçimini yansıtır. MLflow 2.0 kullanmayı tercih ediyorsanız istek yükü biçiminizi güncelleştirmeniz gerekir.
Bash
Veri çerçevesi girişlerini kabul eden bir modeli sorgulamak için kod parçacığı.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '[
{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}
]'
Tensor girişlerini kabul eden bir modeli sorgulamak için kod parçacığı. Tensor girişleri, TensorFlow Hizmeti'nin API belgelerinde açıklandığı gibi biçimlendirilmelidir.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'
Python
import numpy as np
import pandas as pd
import requests
def create_tf_serving_json(data):
return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()}
def score_model(model_uri, databricks_token, data):
headers = {
"Authorization": f"Bearer {databricks_token}",
"Content-Type": "application/json",
}
data_json = data.to_dict(orient='records') if isinstance(data, pd.DataFrame) else create_tf_serving_json(data)
response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json)
if response.status_code != 200:
raise Exception(f"Request failed with status {response.status_code}, {response.text}")
return response.json()
# Scoring a model that accepts pandas DataFrames
data = pd.DataFrame([{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
# Scoring a model that accepts tensors
data = np.asarray([[5.1, 3.5, 1.4, 0.2]])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
Powerbi
Aşağıdaki adımları kullanarak Power BI Desktop'ta bir veri kümesini puanlayabilirsiniz:
Puanlamak istediğiniz veri kümesini açın.
Verileri Dönüştür'e gidin.
Sol panele sağ tıklayın ve Yeni Sorgu Oluştur'u seçin.
Gelişmiş Düzenleyici Görüntüle'ye >gidin.
Uygun
DATABRICKS_API_TOKENveMODEL_VERSION_URIdeğerini doldurduktan sonra sorgu gövdesini aşağıdaki kod parçacığıyla değiştirin.(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPredictionSorguyu istediğiniz model adıyla adlandırın.
Veri kümeniz için gelişmiş sorgu düzenleyicisini açın ve model işlevini uygulayın.
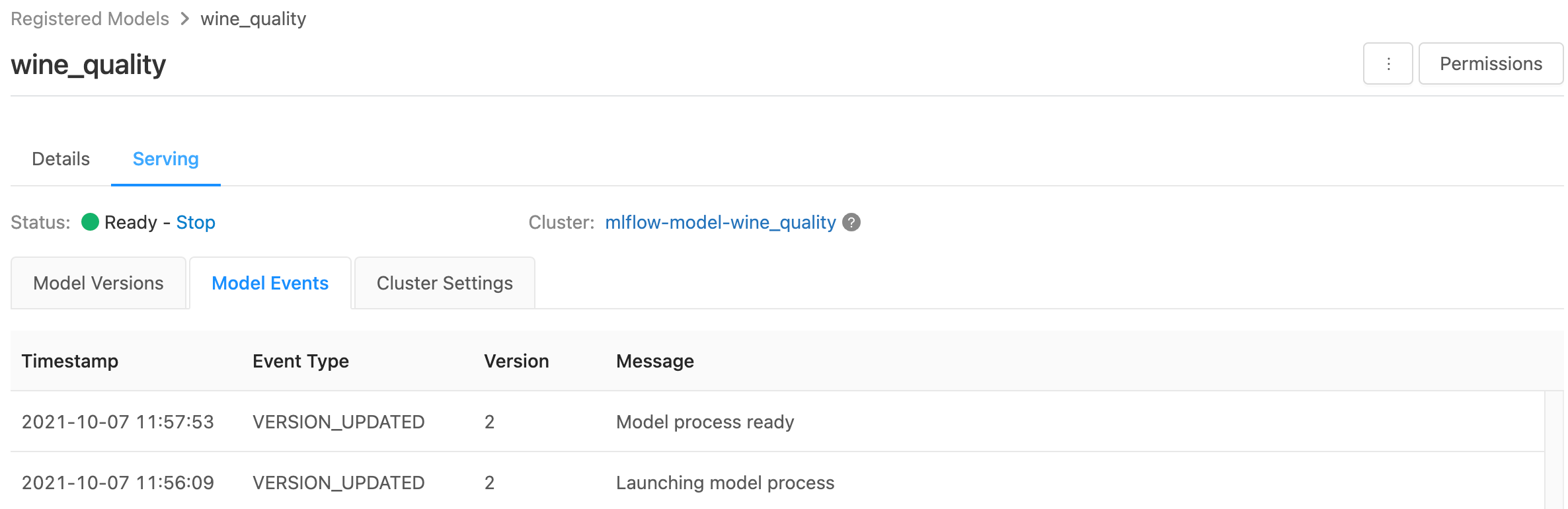
Sunulan modelleri izleme
Sunum sayfası, hizmet veren kümenin durum göstergelerini ve tek tek model sürümlerini görüntüler.
- Sunum kümesinin durumunu incelemek için, bu modele yönelik tüm sunum olaylarının listesini görüntüleyen Model Olayları sekmesini kullanın.
- Tek bir model sürümünün durumunu incelemek için Model Sürümleri sekmesine tıklayın ve Sayfayı kaydırarak Günlükler veya Sürüm Olayları sekmelerini görüntüleyin.
Hizmet veren kümeyi özelleştirme
Sunum kümesini özelleştirmek için, Sunum sekmesindeki Küme Ayarlar sekmesini kullanın.
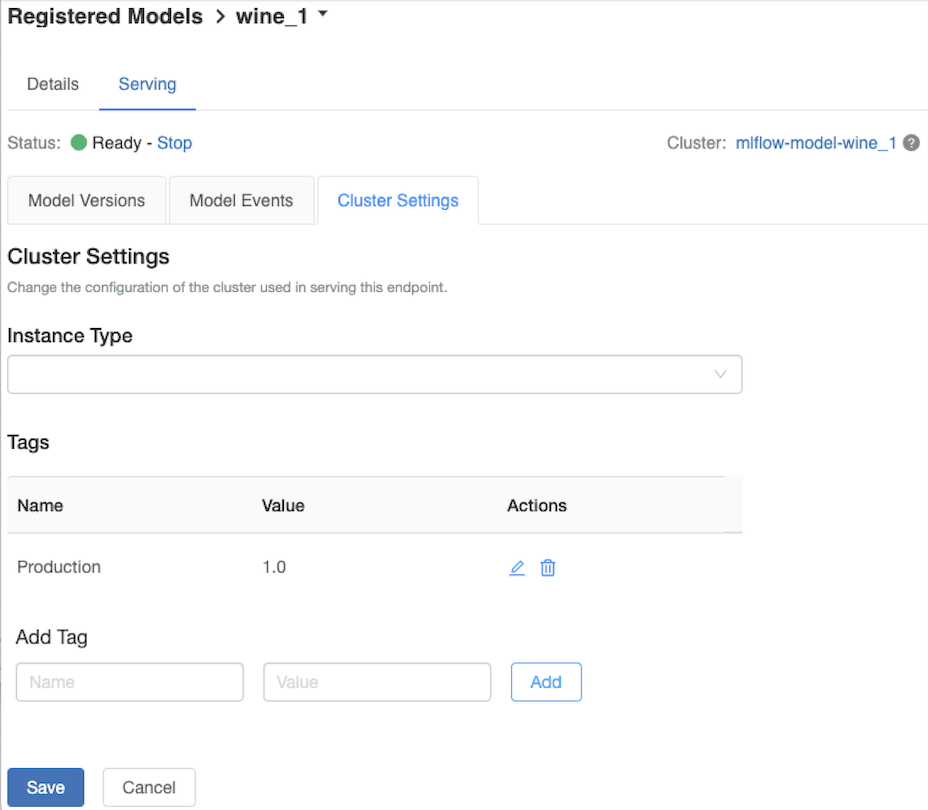
- Bir sunum kümesinin bellek boyutunu ve çekirdek sayısını değiştirmek için, istenen küme yapılandırmasını seçmek için Örnek Türü açılan menüsünü kullanın. Kaydet'e tıkladığınızda, mevcut küme sonlandırılır ve belirtilen ayarlarla yeni bir küme oluşturulur.
- Etiket eklemek için Etiket Ekle alanlarına adı ve değeri yazın ve Ekle'ye tıklayın.
- Mevcut bir etiketi düzenlemek veya silmek için Etiketler tablosunun Eylemler sütunundaki simgelerden birine tıklayın.
Özellik deposu tümleştirmesi
Eski model sunma özelliği, yayımlanan çevrimiçi mağazalardan özellik değerlerini otomatik olarak arayabilir.
.. Aws:
Databricks Legacy MLflow Model Serving supports automatic feature lookup from these online stores:
- Amazon DynamoDB (v0.3.8 and above)
- Amazon Aurora (MySQL-compatible)
- Amazon RDS MySQL
.. azure::
Databricks Legacy MLflow Model Serving supports automatic feature lookup from these online stores:
- Azure Cosmos DB (v0.5.0 and above)
- Azure Database for MySQL
Bilinen hatalar
ResolvePackageNotFound: pyspark=3.1.0
Model databricks pyspark Runtime 8.x kullanılarak bağımlıysa ve günlüğe kaydedildiyse bu hata oluşabilir.
Bu hatayı görürseniz, parametresini pysparkkullanarak conda_env modeli günlüğe eklerken sürümü açıkça belirtin.
Unrecognized content type parameters: format
Bu hata, yeni MLflow 2.0 puanlama protokolü biçiminin bir sonucu olarak oluşabilir. Bu hatayı görüyorsanız, büyük olasılıkla güncel olmayan bir puanlama isteği biçimi kullanıyorsunuz. Hatayı çözmek için şunları yapabilirsiniz:
Puanlama isteği biçiminizi en son protokole güncelleştirin.
Not
Aşağıdaki örnekler, MLflow 2.0'da sunulan puanlama biçimini yansıtır. MLflow 1.x kullanmayı tercih ediyorsanız, API çağrılarınızı
log_model()parametresine istenen MLflow sürümü bağımlılığınıextra_pip_requirementsiçerecek şekilde değiştirebilirsiniz. Bunun yapılması, uygun puanlama biçiminin kullanılmasını sağlar.mlflow.<flavor>.log_model(..., extra_pip_requirements=["mlflow==1.*"])Bash
Pandas veri çerçevesi girişlerini kabul eden bir modeli sorgulama.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{ "dataframe_records": [{"sepal_length (cm)": 5.1, "sepal_width (cm)": 3.5, "petal_length (cm)": 1.4, "petal_width": 0.2}, {"sepal_length (cm)": 4.2, "sepal_width (cm)": 5.0, "petal_length (cm)": 0.8, "petal_width": 0.5}] }'Tensor girişlerini kabul eden bir modeli sorgulama. Tensor girişleri, TensorFlow Hizmeti'nin API belgelerinde açıklandığı gibi biçimlendirilmelidir.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'Python
import numpy as np import pandas as pd import requests def create_tf_serving_json(data): return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()} def score_model(model_uri, databricks_token, data): headers = { "Authorization": f"Bearer {databricks_token}", "Content-Type": "application/json", } data_dict = {'dataframe_split': data.to_dict(orient='split')} if isinstance(data, pd.DataFrame) else create_tf_serving_json(data) data_json = json.dumps(data_dict) response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json) if response.status_code != 200: raise Exception(f"Request failed with status {response.status_code}, {response.text}") return response.json() # Scoring a model that accepts pandas DataFrames data = pd.DataFrame([{ "sepal_length": 5.1, "sepal_width": 3.5, "petal_length": 1.4, "petal_width": 0.2 }]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data) # Scoring a model that accepts tensors data = np.asarray([[5.1, 3.5, 1.4, 0.2]]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)Powerbi
Aşağıdaki adımları kullanarak Power BI Desktop'ta bir veri kümesini puanlayabilirsiniz:
Puanlamak istediğiniz veri kümesini açın.
Verileri Dönüştür'e gidin.
Sol panele sağ tıklayın ve Yeni Sorgu Oluştur'u seçin.
Gelişmiş Düzenleyici Görüntüle'ye >gidin.
Uygun
DATABRICKS_API_TOKENveMODEL_VERSION_URIdeğerini doldurduktan sonra sorgu gövdesini aşağıdaki kod parçacığıyla değiştirin.(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPredictionSorguyu istediğiniz model adıyla adlandırın.
Veri kümeniz için gelişmiş sorgu düzenleyicisini açın ve model işlevini uygulayın.
Puanlama isteğiniz gibi
mlflow.pyfunc.spark_udf()MLflow istemcisini kullanıyorsa, en son biçimi kullanmak için MLflow istemcinizi 2.0 veya sonraki bir sürüme yükseltin. MLflow 2.0'da güncelleştirilmiş MLflow Modeli puanlama protokolü hakkında daha fazla bilgi edinin.
Sunucu tarafından kabul edilen giriş veri biçimleri hakkında daha fazla bilgi için (örneğin, pandas bölünmüş yönlü biçim), MLflow belgelerine bakın.
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin