Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Uyarı
Bu makale, üçüncü taraf tarafından geliştirilen Jenkins'i kapsar. Sağlayıcıya başvurmak için Jenkins Yardımı'na bakın.
Bu makalede, Ci/CD geliştirme iş akışı uygulamak için Jenkins otomasyon sunucusunun Azure Databricks ile nasıl kullanılacağı açıklanmaktadır.
Azure Databricks ile CI/CD'ye genel bakış için bkz. Azure Databricks'te CI/CD. En iyi yöntemler için bkz. Databricks'te en iyi yöntemler ve önerilen CI/CD iş akışları.
Yerel geliştirme makinesi kurulumu
Bu makalenin örneği, Jenkins'i kullanarak Databricks CLI ve Bildirim temelli Otomasyon Paketleri'ne aşağıdakileri yapmalarını bildirir:
- Yerel geliştirme makinenizde bir Python tekerlek dosyası oluşturun.
- Yerel geliştirme makinenizden Azure Databricks çalışma alanına ek Python dosyaları ve Python not defterleriyle birlikte yerleşik Python tekerlek dosyasını dağıtın.
- Karşıya yüklenen Python wheel dosyasını ve not defterlerini bu çalışma alanında test edin ve çalıştırın.
Yerel geliştirme makinenizi Azure Databricks çalışma alanınıza bu örnekte derleme ve karşıya yükleme aşamalarını gerçekleştirme talimatı vermek üzere ayarlamak için yerel geliştirme makinenizde aşağıdakileri yapın:
1. Adım: Gerekli araçları yükleme
Bu adımda Databricks CLI, Jenkins jqve Python tekerlek derleme araçlarını yerel geliştirme makinenize yüklersiniz. Bu örneği çalıştırmak için bu araçlar gereklidir.
Henüz yapmadıysanız Databricks CLI sürüm 0.205 veya üzerini yükleyin. Jenkins, bu örneğin testini geçirmek ve çalışma alanınızda yönergeleri çalıştırmak için Databricks CLI'yi kullanır. Bkz. Databricks CLI'yı yükleme veya güncelleştirme.
Henüz yapmadıysanız Jenkins'i yükleyin ve başlatın. Bkz. Linux, macOS veya Windows için Jenkins'i yükleme.
jq'yi yükleyin. Bu örnek, JSON biçimli bazı komut çıkışlarını ayrıştırmak için kullanır
jq.Şu komutu kullanarak
pipPython tekerlek bina araçlarını yükleyin (bazı sistemlerdepip3yerinepipkullanmanız gerekebilir):pip install --upgrade wheel
2. Adım: Jenkins İşlem Hattı Oluşturma
Bu adımda, bu makalenin örneğine yönelik bir Jenkins İşlem Hattı oluşturmak için Jenkins'i kullanacaksınız. Jenkins, CI/CD işlem hatları oluşturmak için birkaç farklı proje türü sağlar. Jenkins Pipelines, Jenkins eklentilerini çağırmak ve yapılandırmak için Groovy kodunu kullanarak Jenkins İşlem Hattı'nda aşamaları tanımlamak için bir arabirim sağlar.
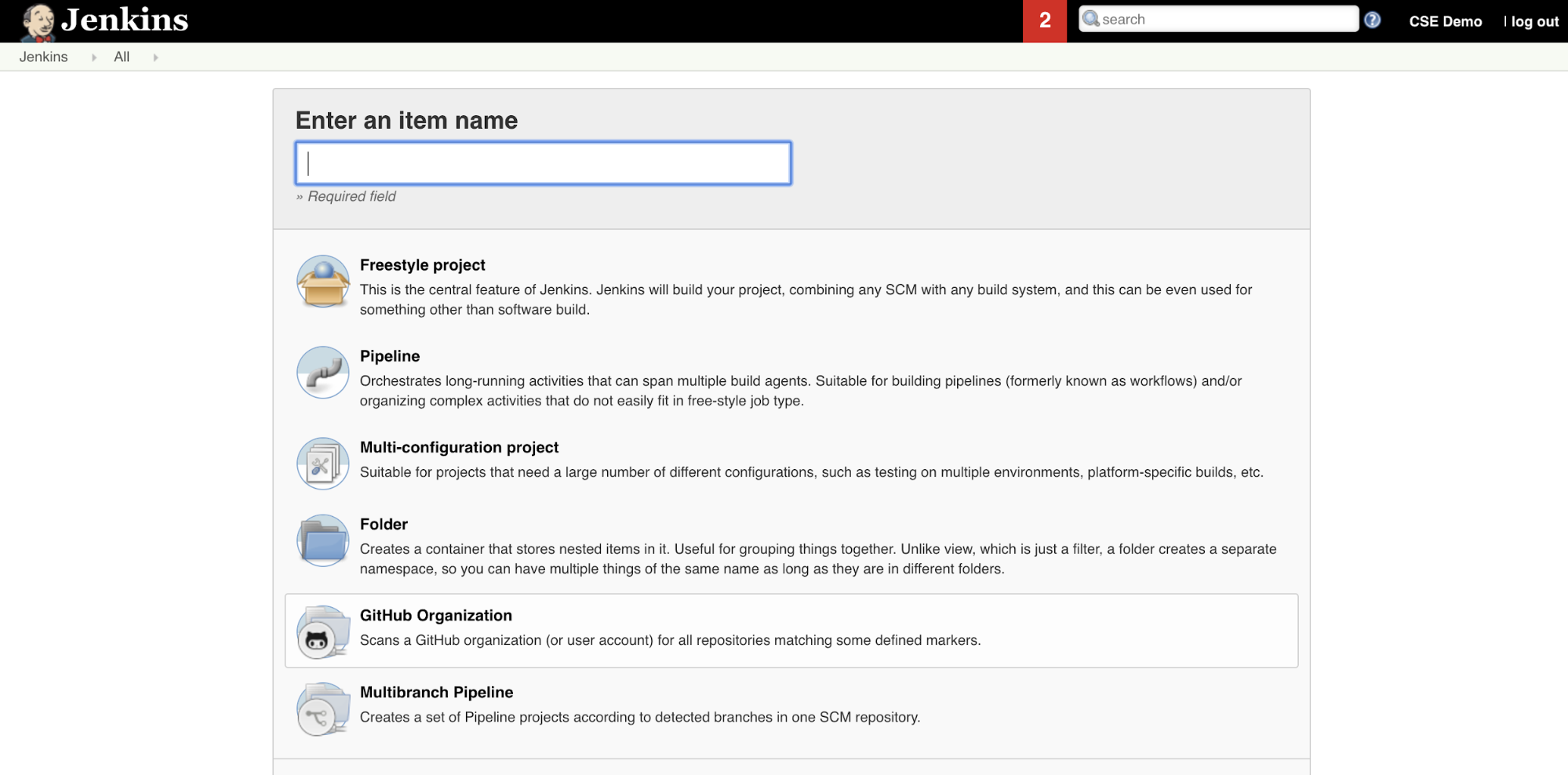
Jenkins'te Jenkins İşlem Hattı oluşturmak için:
- Jenkins'i başlattıktan sonra Jenkins Panonuzdan Yeni Öğe'ye tıklayın.
-
Öğe adı girin alanında Jenkins İşlem Hattı için bir ad yazın, örneğin
jenkins-demo. - İşlem hattı proje türü simgesine tıklayın.
- Tamam'a tıklayın. Jenkins Boru Hattının Yapılandır sayfası görüntülenir.
- İşlem Hattı alanındaki Tanımlama açılan listesinde, SCM'den İşlem Hattı betiği seçin.
- SCM açılan listesinden Gitseçin.
- Depo URL'si için, üçüncü bölüm Git sağlayıcınız tarafından barındırılan deponun URL'sini yazın.
-
Dal Tanımlayıcısıiçin
*/<branch-name>yazın; burada<branch-name>, deponuzda kullanmak istediğiniz dalın adıdır; örneğin*/main. - Henüz ayarlanmadıysa,
betik yolu için yazın. Bu makalede Jenkinsfileöğesini daha sonra oluşturursunuz. - Zaten işaretliyse Basit kullanıma alma başlıklı kutunun işaretini kaldırın.
- Kaydet'e tıklayın.
3. Adım: Jenkins'e genel ortam değişkenleri ekleme
Bu adımda Jenkins'e üç genel ortam değişkeni ekleyeceksiniz. Jenkins bu ortam değişkenlerini Databricks CLI'ya geçirir. Databricks CLI, Azure Databricks çalışma alanınızda kimlik doğrulaması yapmak için bu ortam değişkenleri için değerlere ihtiyaç duyar. Bu örnekte hizmet sorumlusu için OAuth makineden makineye (M2M) kimlik doğrulaması kullanılmaktadır (ancak diğer kimlik doğrulama türleri de kullanılabilir). Azure Databricks çalışma alanınız için OAuth M2M kimlik doğrulamasını ayarlamak için bkz. OAuth ile Azure Databricks'e hizmet sorumlusu erişimi yetkilendirme.
Bu örnek için üç genel ortam değişkeni şunlardır:
-
DATABRICKS_HOST,https://ile başlayan Azure Databricks çalışma alanı URL'niz olarak ayarlayın. Bkz: Çalışma alanı örneği adları, URL'ler ve kimlikler. -
DATABRICKS_CLIENT_ID, aynı zamanda uygulama kimliği olarak da bilinen hizmet sorumlusunun istemci kimliği olacak şekilde ayarlanır. -
DATABRICKS_CLIENT_SECRET, hizmet sorumlusunun Azure Databricks OAuth gizli anahtarına ayarlanır.
Jenkins'te genel ortam değişkenlerini ayarlamak için, Jenkins Panonuzdan:
- Kenar çubuğunda Jenkins'i Yönet'e tıklayın.
- Sistem Yapılandırması bölümünde Sistem'e tıklayın.
- Genel özellikler bölümünde Ortam değişkenleri başlıklı kutuyu işaretleyin.
- Ekle'ye tıklayın ve ortam değişkeninin Ad ve Değer değerlerini girin. Bunu her ek ortam değişkeni için yineleyin.
- Ortam değişkenlerini eklemeyi bitirdiğinizde, Jenkins Panonuza dönmek için Kaydet'e tıklayın.
Jenkins İşlem Hattını Tasarlama
Jenkins, CI/CD işlem hatları oluşturmak için birkaç farklı proje türü sağlar. Bu örnek bir Jenkins İşlem Hattı uygular. Jenkins Pipelines, Jenkins eklentilerini çağırmak ve yapılandırmak için Groovy kodunu kullanarak Jenkins İşlem Hattı'nda aşamaları tanımlamak için bir arabirim sağlar.
Jenkins pipeline tanımını Jenkinsfile adlı bir metin dosyasına yazarsınız ve bu da projenin kaynak denetim deposunda denetlenebilir. Daha fazla bilgi için bkz . Jenkins İşlem Hattı. Bu makalenin örneği için Jenkins İşlem Hattı aşağıda verilmiştir. Bu örnekte Jenkinsfile, aşağıdaki yer tutucuları değiştirin:
- Üçüncü taraf Git sağlayıcınız tarafından barındırılan kullanıcı adı ve depo adıyla
<user-name>ve<repo-name>değerlerini değiştirin. Bu makalede örnek olarak GitHub URL'si kullanılmaktadır. - Depo içindeki yayın dalının adıyla
<release-branch-name>değerini değiştirin. Örneğin, bu olabilirmain. -
<databricks-cli-installation-path>yerine Databricks CLI'nın yüklü olduğu yerel geliştirme makinenizdeki yolu girin. Örneğin, macOS'ta bu olabilir/usr/local/bin. -
<jq-installation-path>'ı yerel geliştirme makinenizdejq'in yüklü olduğu yol ile değiştirin. Örneğin, macOS'ta bu olabilir/usr/local/bin. - çalışma alanınızda bu örnek için oluşturulan işleri benzersiz olarak tanımlamaya yardımcı olacak bir dizeyle
<job-prefix-name>öğesini değiştirin. Örneğin, bu olabilirjenkins-demo. -
BUNDLETARGET'ın, bu makalenin devamında tanımlanan Bildirim Tabanlı Otomasyon Paketleri hedefinin adı olarakdevayarlandığına dikkat edin. Gerçek dünyadaki uygulamalarda bunu kendi paket hedefinizin adıyla değiştirin. Paket hedefleri hakkında daha fazla ayrıntı bu makalenin devamında verilmiştir.
Depo kökünüze eklemeniz gereken Jenkinsfile burada:
// Filename: Jenkinsfile
node {
def GITREPOREMOTE = "https://github.com/<user-name>/<repo-name>.git"
def GITBRANCH = "<release-branch-name>"
def DBCLIPATH = "<databricks-cli-installation-path>"
def JQPATH = "<jq-installation-path>"
def JOBPREFIX = "<job-prefix-name>"
def BUNDLETARGET = "dev"
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
-t ${BUNDLETARGET} \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
}
Bu makalenin geri kalanında, bu Jenkins İşlem Hattı'ndaki her aşama ve Jenkins'in bu aşamada çalışması için yapıtların ve komutların nasıl ayarlanacağı açıklanır.
Üçüncü taraf deposundan en son yapıtları çekme
Bu Jenkins İşlem Hattı'nın Checkout ilk aşaması olan aşama aşağıdaki gibi tanımlanır:
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
Bu aşama, Jenkins'in yerel geliştirme makinenizde kullandığı çalışma dizininin üçüncü taraf Git deponuzdan en son yapıtlara sahip olmasını sağlar. Jenkins genellikle bu çalışma dizinini olarak <your-user-home-directory>/.jenkins/workspace/<pipeline-name>ayarlar. Bu, aynı yerel geliştirme makinesinde kendi yapıt kopyanızı Jenkins'in üçüncü taraf Git deponuzda kullandığı yapıtlardan ayrı tutmanızı sağlar.
Databricks Varlık Paketini Doğrulama
Bu Jenkins İşlem Hattı'nın Validate Bundle ikinci aşaması olan aşama aşağıdaki gibi tanımlanır:
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
Bu aşama, yapıtlarınızı test edip çalıştırmak için iş akışlarını tanımlayan paketin söz dizimsel olarak doğru olmasını sağlar. Bildirim temelli Otomasyon Paketleri, tam veri, analiz ve ML projelerini kaynak dosya koleksiyonu olarak ifade etmeye olanak sağlar. Bkz. Bildirim temelli Otomasyon Paketleri nelerdir?.
Bu makalenin paketini tanımlamak için yerel makinenizde kopyalanan deponun kökünde adlı databricks.yml bir dosya oluşturun. Bu örnek databricks.yml dosyada aşağıdaki yer tutucuları değiştirin:
-
<bundle-name>değerini paket için benzersiz bir programatik adla değiştirin. Örneğin, bu olabilirjenkins-demo. - çalışma alanınızda bu örnek için oluşturulan işleri benzersiz olarak tanımlamaya yardımcı olacak bir dizeyle
<job-prefix-name>öğesini değiştirin. Örneğin, bu olabilirjenkins-demo. Jenkinsfile dosyanızdakiJOBPREFIXdeğeriyle eşleşmelidir. - değerini iş kümelerinizin Databricks Runtime sürüm kimliğiyle değiştirin
<spark-version-id>, örneğin13.3.x-scala2.12. -
<cluster-node-type-id>'yi, iş kümelerinizin düğüm türü kimliğiyle değiştirin. ÖrneğinStandard_DS3_v2. - Jenkinsfile içindeki
deviletargetseşlemedekiBUNDLETARGET'in aynı olduğuna dikkat edin. Paket hedefi, konağı ve ilgili dağıtım davranışlarını belirtir.
databricks.yml Bu örneğin doğru çalışması için deponuzun köküne eklenmesi gereken dosya aşağıda verilmiştir:
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
data_security_mode: SINGLE_USER
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: '/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl'
evaluate-notebook-runs:
name: ${var.job_prefix}-evaluate-notebook-runs
tasks:
- task_key: ${var.job_prefix}-evaluate-notebook-runs-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
spark_python_task:
python_file: ./evaluate_notebook_runs.py
source: WORKSPACE
libraries:
- pypi:
package: unittest-xml-reporting
targets:
dev:
mode: development
Dosya hakkında daha fazla bilgi için Otomasyon Paketleri'nin deklaratif yapılandırması bölümüne bakın databricks.yml.
Paketi çalışma alanınıza dağıtma
Jenkins İşlem Hattı'nın başlıklı Deploy Bundleüçüncü aşaması aşağıdaki gibi tanımlanır:
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
Bu aşama iki şey yapar:
-
artifactdosyasındakidatabricks.ymleşlemesiwhlolarak ayarlandığından, bu, Databricks CLI'ya belirtilen konumdakisetup.pydosyasını kullanarak Python tekerlek dosyasını oluşturmasını ister. - Python tekerlek dosyası yerel geliştirme makinenizde oluşturulduktan sonra Databricks CLI, yerleşik Python tekerlek dosyasını ve belirtilen Python dosyalarını ve not defterlerini Azure Databricks çalışma alanınıza dağıtır. Bildirim temelli Otomasyon Paketleri varsayılan olarak Python tekerlek dosyasını ve diğer dosyaları 'a
/Workspace/Users/<your-username>/.bundle/<bundle-name>/<target-name>dağıtır.
Python tekerlek dosyasının dosyada databricks.yml belirtildiği gibi derlenmesini sağlamak için, yerel makinenizde kopyalanmış deponuzun kökünde aşağıdaki klasörleri ve dosyaları oluşturun.
Not defterinin çalıştırılacağı Python tekerlek dosyasının mantığını ve birim testlerini tanımlamak için ve addcol.pyadlı test_addcol.py iki dosya oluşturun ve bunları deponuzun python/dabdemo/dabdemo klasörü içinde adlı Libraries bir klasör yapısına ekleyin:
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ └── dabdemo
│ ├── addcol.py
│ └── test_addcol.py
├── ...
Dosya, daha sonra bir Python Wheel dosyasına dönüştürülen ve ardından Azure Databricks kümesine kurulan bir kitaplık fonksiyonu içerir. Apache Spark DataFrame'e sabit bir değerle doldurulmuş yeni bir sütun ekleyen bu işlev:
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
Dosya test_addcol.py, with_status içinde tanımlanan addcol.py işlevine bir sahte DataFrame nesnesi geçirmeye ilişkin testler içerir. Sonuç daha sonra beklenen değerleri içeren bir DataFrame nesnesiyle karşılaştırılır. Değerler eşleşirse, ki bu örnekte eşleşiyorlar, test geçer.
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
Databricks CLI'nın bu kitaplık kodunu bir Python tekerlek dosyasına doğru şekilde paketlemesini sağlamak için, önceki iki dosyayla aynı klasörde ve __init__.py adlı __main__.py iki dosya oluşturun.
setup.py klasöründe python/dabdemo adlı bir dosya oluşturun.
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ ├── dabdemo
│ │ ├── __init__.py
│ │ ├── __main__.py
│ │ ├── addcol.py
│ │ └── test_addcol.py
│ └── setup.py
├── ...
Dosya kitaplığın __init__.py sürüm numarasını ve yazarını içerir. Adınızla <my-author-name> değiştirin.
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
Dosya kitaplığın __main__.py giriş noktasını içerir:
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
setup.py dosyası, kütüphaneyi bir Python wheel dosyasına oluşturmak için ek ayarlar içerir.
<my-url>, <my-author-name>@<my-organization>ve <my-package-description> anlamlı değerlerle değiştirin:
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
Python tekerleğinin bileşen mantığını test edin
Bu Run Unit Tests evre, Jenkins İşlem Hattı'nın dördüncü aşaması olarak, bir kitaplığın derlenmiş hâlde çalıştığından emin olmak için mantığını test etmek amacıyla pytest kullanır. Bu aşama aşağıdaki gibi tanımlanır:
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
Bu aşamada, bir not defteri işini çalıştırmak için Databricks CLI kullanılır. Bu iş Python not defterini dosya adıyla run-unit-test.py çalıştırır. Bu not defteri kitaplığın mantığına göre çalışır pytest .
Bu örnekte birim testlerini çalıştırmak için, yerel makinenizdeki kopyalanmış deponuzun köküne aşağıdaki içeriklerle adlı run_unit_tests.py bir Python not defteri dosyası ekleyin:
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
Yerleşik Python tekerleğini kullanma
Adlı Run Notebookbu Jenkins İşlem Hattının beşinci aşaması, yerleşik Python tekerlek dosyasındaki mantığı çağıran bir Python not defterini aşağıdaki gibi çalıştırır:
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
Bu aşama Databricks CLI'yı çalıştırır ve çalışma alanınıza bir not defteri işi çalıştırma talimatını da sağlar. Bu not defteri bir DataFrame nesnesi oluşturur, kitaplığın with_status işlevine geçirir, sonucu yazdırır ve işin çalıştırma sonuçlarını bildirir. Yerel geliştirme makinenizde kopyalanmış deponuzun kökünde aşağıdaki içeriklere sahip adlı dabdaddemo_notebook.py bir Python not defteri dosyası ekleyerek not defterini oluşturun:
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │first_name │last_name │email │status |
# +============+===========+=========================+=========+
# │paula │white │paula.white@example.com │checked |
# +------------+-----------+-------------------------+---------+
# │john │baer │john.baer@example.com │checked |
# +------------+-----------+-------------------------+---------+
Not defteri görev çalıştırma sonuçlarını değerlendirme
Bu Evaluate Notebook Runs Jenkins İşlem Hattının altıncı aşaması olan aşama, önceki not defteri işi çalıştırmasının sonuçlarını değerlendirir. Bu aşama aşağıdaki gibi tanımlanır:
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
Bu aşama Databricks CLI'yı çalıştırır ve bu da çalışma alanınıza bir Python dosya işi çalıştırmasını emreder. Bu Python dosyası, not defteri işi çalıştırması için hata ve başarı ölçütlerini belirler ve bu hata veya başarı sonucunu bildirir. Yerel geliştirme makinenizde kopyalanmış deponuzun kökünde aşağıdaki içeriklere sahip adlı evaluate_notebook_runs.py bir dosya oluşturun:
import unittest
import xmlrunner
import json
import glob
import os
class TestJobOutput(unittest.TestCase):
test_output_path = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output"
def test_performance(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
duration = data['tasks'][0]['execution_duration']
if duration > 100000:
status = 'FAILED'
else:
status = 'SUCCESS'
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
def test_job_run(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
status = data['state']['result_state']
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
if __name__ == '__main__':
unittest.main(
testRunner = xmlrunner.XMLTestRunner(
output = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output/test-results",
),
failfast = False,
buffer = False,
catchbreak = False,
exit = False
)
Test sonuçlarını içeri aktarma ve raporlama
Adlı Import Test Resultsbu Jenkins İşlem Hattı'nın yedinci aşaması, test sonuçlarını çalışma alanınızdan yerel geliştirme makinenize göndermek için Databricks CLI'sini kullanır. başlıklı Publish Test Resultssekizinci ve son aşama, Jenkins eklentisini kullanarak test sonuçlarını Jenkins'e junit yayımlar. Bu, test sonuçlarının durumuyla ilgili raporları ve panoları görselleştirmenizi sağlar. Bu aşamalar aşağıdaki gibi tanımlanır:
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
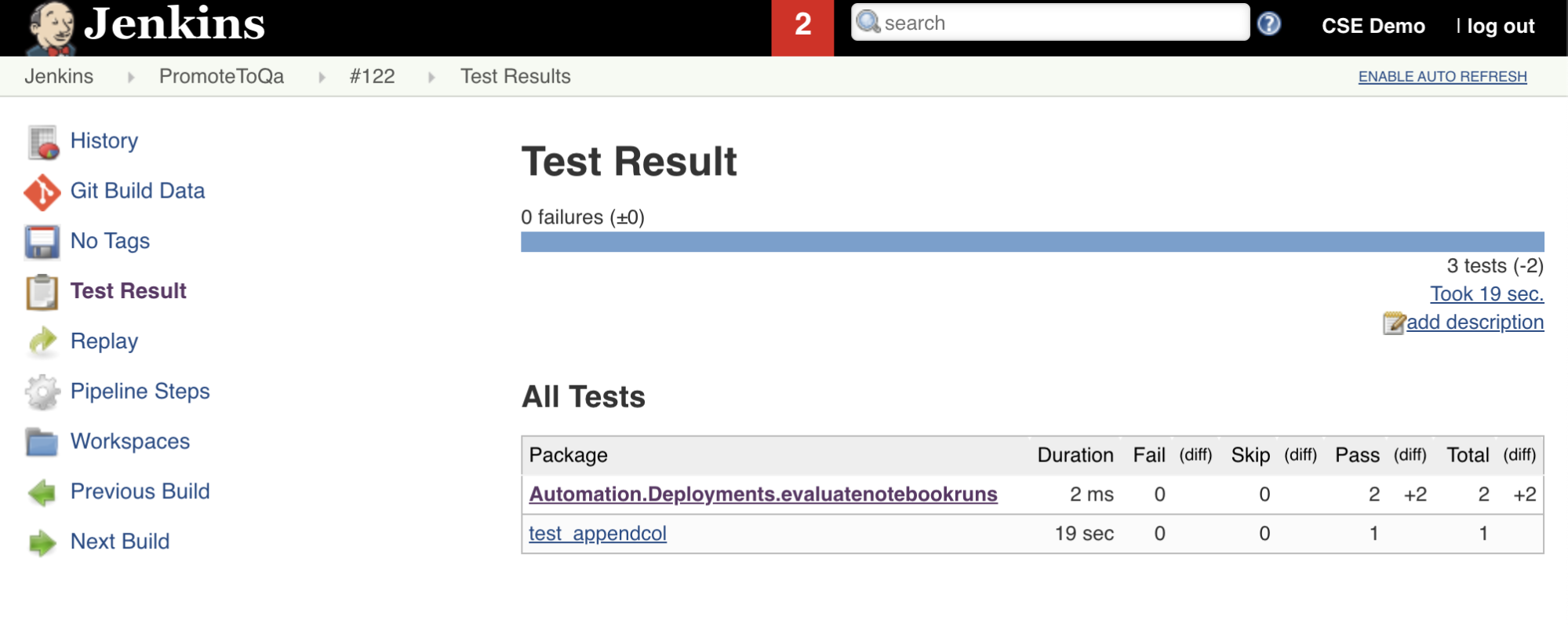
Tüm kod değişikliklerini üçüncü taraf deponuza gönderme
Şimdi yerel geliştirme makinenizdeki kopyalanmış deponuzun içeriğini üçüncü taraf deponuza göndermeniz gerekir. Göndermeden önce kopyalanmış deponuzdaki dosyaya .gitignore aşağıdaki girdileri eklemeniz gerekir çünkü büyük olasılıkla iç paket çalışma dosyalarını, doğrulama raporlarını, Python derleme dosyalarını ve Python önbelleklerini üçüncü taraf deponuza göndermemelisiniz. Genellikle, potansiyel olarak güncel olmayan doğrulama raporları ve Python tekerleği derlemelerini kullanmak yerine Azure Databricks çalışma alanınızda yeni doğrulama raporlarını ve en son Python derlemelerini yeniden oluşturmak istersiniz.
.databricks/
.vscode/
Libraries/python/dabdemo/build/
Libraries/python/dabdemo/__pycache__/
Libraries/python/dabdemo/dabdemo.egg-info/
Validation/
Jenkins İşlem Hattınızı çalıştırma
Artık Jenkins İşlem Hattınızı el ile çalıştırmaya hazırsınız. Bunu yapmak için Jenkins Panonuzdan:
- Jenkins İşlem Hattınızın adına tıklayın.
- Kenar çubuğunda Şimdi Oluştur'a tıklayın.
- Sonuçları görmek için en son Pipeline çalıştırmasına (örneğin,
#1) ve ardından Konsol Çıkışı'na tıklayın.
Bu noktada CI/CD işlem hattı bir tümleştirme ve dağıtım döngüsünü tamamlamıştır. Bu işlemi otomatikleştirerek kodunuzun verimli, tutarlı ve yinelenebilir bir işlem tarafından test edilmesini ve dağıtılmasını sağlayabilirsiniz. Üçüncü taraf Git sağlayıcınıza depo çekme isteği gibi belirli bir olay gerçekleştiğinde Jenkins'i çalıştırmasını bildirmek için üçüncü taraf Git sağlayıcınıza ait belgelere bakın.