Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Akış tablosu, akış veya adımlı veri işleme desteğine sahip bir Delta tablosudur. ETL işlem hattındaki bir veya daha fazla akış, bir veri akışı tablosuna yönlendirilebilir.
Akış tabloları, aşağıdaki nedenlerle veri alımı için iyi bir seçimdir:
- Her giriş satırı yalnızca bir kez işlenir ve bu da veri alım iş yüklerinin büyük çoğunluğunu (bir tabloya satır ekleyerek veya güncelleyerek) modellemektedir.
- Büyük hacimlerde yalnızca ekleme amaçlı verileri işleyebilirler.
Akış tabloları, aşağıdaki nedenlerle düşük gecikme süreli akış dönüştürmeleri için de iyi bir seçimdir:
- Satırlar ve zaman pencereleri üzerinde değerlendirme yapın
- Yüksek hacimli verileri işleme
- Düşük gecikme süresi
Aşağıdaki diyagramda akış tablolarının nasıl çalıştığı gösterilmektedir.
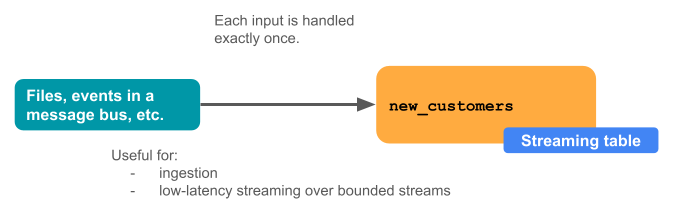
Her güncelleştirmede, akış tablosuyla ilişkili akışlar bir akış kaynağındaki değiştirilen bilgileri okur ve bu tabloya yeni bilgiler ekler.
Akış tabloları tek bir işlem hattı tarafından tanımlanır ve güncelleştirilir. akış tablolarını işlem hattının kaynak kodunda açıkça tanımlarsınız. İşlem hattı tarafından tanımlanan tablolar başka bir işlem hattı tarafından değiştirilemez veya güncelleştirilemez. Tek bir akış tablosuna eklenecek birden çok akış tanımlayabilirsiniz.
Databricks SQL'de işlem hattının dışında bir akış tablosu oluşturduğunuzda, Databricks bu tabloyu güncelleştirmek için kullanılan gizli bir işlem hattı oluşturur.
Akışlar hakkında daha fazla bilgi için bkz. Lakeflow Bildirimli İşlem Hatları akışlarıyla verileri artımlı olarak yükleme ve işleme.
Alım için akış tabloları
Akış tabloları yalnızca ekleme veri kaynakları için tasarlanmıştır ve girişleri yalnızca bir kez işler.
Aşağıdaki örnekte, bulut depolamadan yeni dosyaları almak için akış tablosunun nasıl kullanılacağı gösterilmektedir.
Piton
import dlt
# create a streaming table
@dlt.table
def customers_bronze():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.load("/Volumes/path/to/files")
)
bir veri kümesi tanımında işlevini kullandığınızda spark.readStream , Lakeflow Bildirimli İşlem Hatları'nın veri kümesini akış olarak işlemesine neden olur ve oluşturulan tablo bir akış tablosudur.
SQL
-- create a streaming table
CREATE OR REFRESH STREAMING TABLE customers_bronze
AS SELECT * FROM STREAM read_files(
"/volumes/path/to/files",
format => "json"
);
Akış tablosuna veri yükleme hakkında daha fazla bilgi için bkz. Lakeflow Bildirimli İşlem Hatları ile veri yükleme.
Aşağıdaki diyagramda yalnızca ekleme yapılan akış tablolarının nasıl çalıştığı gösterilmektedir.
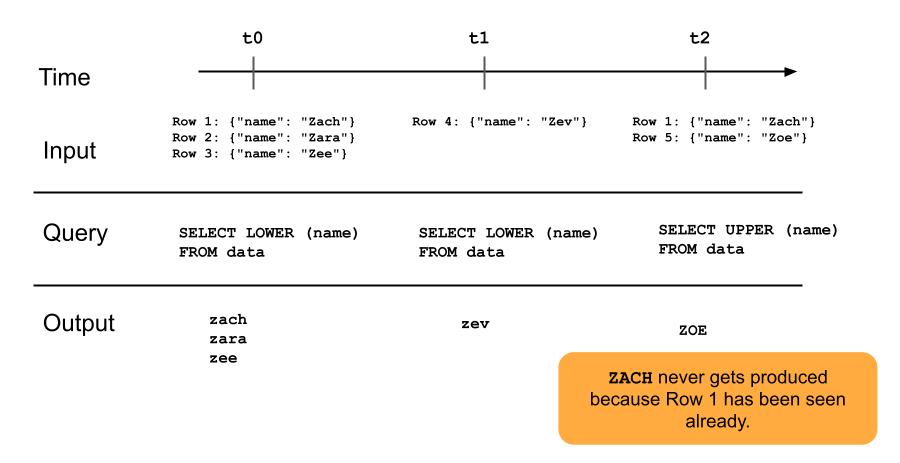
Akış tablosuna zaten eklenmiş olan bir satır, işlem hattındaki sonraki güncelleştirmelerle yeniden sorgulanmaz. Sorguyu değiştirirseniz (örneğin, SELECT LOWER (name)'dan SELECT UPPER (name)'e), var olan satırlar büyük harf olacak şekilde güncellenmeyecek, ancak yeni satırlar büyük harfle yazılacaktır. Akış tablosundaki tüm satırları güncelleştirmek üzere kaynak tablodan önceki tüm verileri yeniden sorgulamak için tam yenileme tetikleyebilirsiniz.
Akış tabloları ve düşük gecikmeli akış
Akış tabloları, sınırlanmış durum üzerinden düşük gecikme süreli akış için tasarlanmıştır. Akış tabloları denetim noktası yönetimini kullanır ve bu da düşük gecikmeli akış için uygun olmalarını sağlar. Ancak, doğal sınırları olan veya filigranla sınırlandırılmış akışları beklerler.
Doğal olarak sınırlanmış bir akış, iyi tanımlanmış bir başlangıç ve bitişe sahip bir akış veri kaynağı tarafından oluşturulur. Doğal olarak sınırlanmış bir akışa örnek olarak, ilk bir dosya toplu işlemi yerleştirildikten sonra yeni dosyaların eklenmediği bir dosya dizininden veri okuma işlemi gösterilmiştir. Dosya sayısı sınırlı olduğundan akış sınırlanmış olarak kabul edilir ve ardından tüm dosyalar işlendikten sonra akış sona erer.
Bir akışı sınırlamak için filigran da kullanabilirsiniz. Spark Structured Streaming'de filigran, sistemin zaman penceresini tamamlanmış saymadan önce gecikmiş olaylar için ne kadar beklemesi gerektiğini belirleyen ve bu şekilde geç verilerin işlenmesine yardımcı olan bir mekanizmadır. Filigranı olmayan bir ilişkisiz akış, bellek baskısı nedeniyle işlem hattının başarısız olmasına neden olabilir.
Durum bilgisine sahip akış işleme hakkında daha fazla bilgi için, Lakeflow Bildirimli İşlem Hatlarında filigranlarla durum bilgisini optimize etme başlığına bakın.
Akış-anlık görüntü birleşimleri
Akış-anlık görüntü birleşimleri, akışlar başlatıldığında anlık görüntüsü alınan bir boyut ile bir akış arasındaki birleşimlerdir. Boyut tablosu zaman içinde anlık görüntü olarak kabul edildiğinden ve boyut tablosunu yeniden yüklemediğiniz veya yenilemediğiniz sürece akış başladıktan sonra boyut tablosuna yapılan değişiklikler yansıtılmadığından, bu birleştirmeler akış başladıktan sonra boyut değişirse yeniden çözümlenmez. Küçük tutarsızlıkları bir birleşimde kabul edebiliyorsanız, bu makul bir davranıştır. Örneğin, işlem sayısı müşteri sayısından kat kat fazla olduğunda yaklaşık bir birleştirme kabul edilebilir.
Aşağıdaki kod örneğinde, iki satırlık bir müşteri boyut tablosunu sürekli artan bir veri kümesi olan işlemlerle birleştiriyoruz. adlı sales_reportbir tabloda bu iki veri kümesi arasında bir birleştirme gerçekleştiriyoruz. Dış işlem, müşteriler tablosuna yeni bir satır ekleyerek (customer_id=3, name=Zoya) güncelleme yaparsa, bu yeni satır, akışlar başlatıldığında statik boyut tablosu anlık görüntü alındığı için birleştirmede yer almayacaktır.
import dlt
@dlt.view
# assume this table contains an append-only stream of rows about transactions
# (customer_id=1, value=100)
# (customer_id=2, value=150)
# (customer_id=3, value=299)
# ... <and so on> ...
def v_transactions():
return spark.readStream.table("transactions")
# assume this table contains only these two rows about customers
# (customer_id=1, name=Bilal)
# (customer_id=2, name=Olga)
@dlt.view
def v_customers():
return spark.read.table("customers")
@dlt.table
def sales_report():
facts = spark.readStream.table("v_transactions")
dims = spark.read.table("v_customers")
return (
facts.join(dims, on="customer_id", how="inner"
)
Akış tablosu sınırlamaları
Akış tablolarının sınırlamaları şunlardır:
- Sınırlı geliştirme: Veri kümesinin tamamını yeniden derlemeden sorguyu değiştirebilirsiniz. Akış tablosu bir satırı yalnızca bir kez gördüğünden, farklı satırlarda çalışan farklı sorgularınız olabilir. Bu, veri kümenizde çalışan sorgunun önceki tüm sürümlerini bilmeniz gerektiği anlamına gelir. Akış tablosunun önceden işlenmiş verileri güncelleştirmesini sağlamak için tam yenileme gereklidir.
- Durum yönetimi: Akış tabloları düşük gecikme süresine sahip olduğundan, üzerinde çalıştıkları akışların doğal olarak sınırlandığından veya filigranla sınırlandığından emin olmanız gerekir. Daha fazla bilgi için bkz. Filigranlarla Lakeflow Deklaratif İşlem Hatlarında durum bilgisi olan işlemeyi optimize etme.
- Birleştirmeler yeniden derlenemez: Akış tablolarındaki birleştirmeler, boyutlar değiştiğinde yeniden derlenmez. Bu özellik "hızlı ama yanlış" senaryolar için iyi olabilir. Görünümünüzün her zaman doğru olmasını istiyorsanız, gerçekleştirilmiş bir görünüm kullanmak isteyebilirsiniz. Gerçekleştirilmiş görünümler her zaman doğrudur çünkü boyutlar değiştiğinde birleştirmeleri otomatik olarak yeniden derlerler. Daha fazla bilgi için bkz. Gerçekleştirilmiş görünümler.