Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
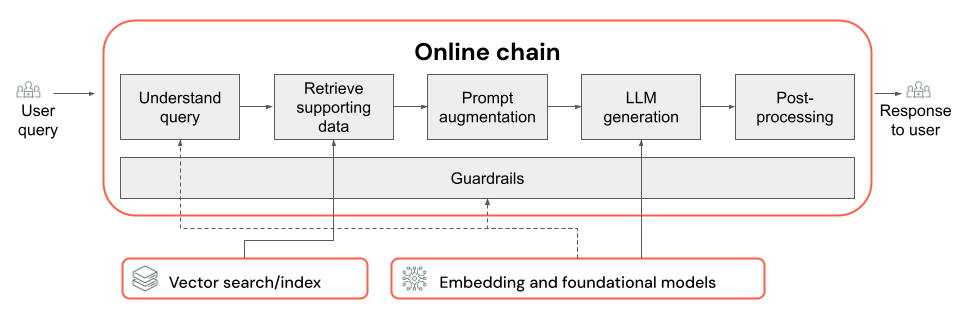
Bu makale, RAG zincirinin bileşenlerini kullanarak RAG uygulamasının kalitesini nasıl geliştirebileceğinizi kapsar.
RAG zinciri giriş olarak bir kullanıcı sorgusu alır, bu sorguyu verilen ilgili bilgileri alır ve alınan veriler üzerinde temellenmiş uygun bir yanıt oluşturur. RAG zincirindeki tam adımlar kullanım örneğine ve gereksinimlere bağlı olarak büyük ölçüde farklılık gösterse de, RAG zincirinizi oluştururken dikkate alınması gereken temel bileşenler şunlardır:
- Sorgu anlama: Alma işlemini geliştirmek için amacı daha iyi temsil etmek ve filtreler veya anahtar sözcükler gibi ilgili bilgileri ayıklamak için kullanıcı sorgularını analiz etme ve dönüştürme.
- Retrieval: Bir sorgulama sonucu en ilgili bilgi öbeklerini bulma. Yapılandırılmamış veri durumunda, bu genellikle bir veya bir semantik veya anahtar sözcük tabanlı arama birleşimini içerir.
- İstem zenginleştirme: Kullanıcı sorgusunu, alınan bilgi ve yönergelerle birleştirerek LLM'nin yüksek kaliteli yanıtlar üretmesini sağlamak.
- LLM : Performansı, gecikme süresini ve maliyeti iyileştirmek/dengelemek için uygulamanız için en uygun modeli (ve model parametrelerini) seçme.
- İşleme sonrası ve korumalar: LLM tarafından oluşturulan yanıtların konuyla ilgili, aslında tutarlı ve belirli yönergelere veya kısıtlamalara uyduğundan emin olmak için ek işleme adımları ve güvenlik önlemleri uygulama.
Yinelemeli olarak uygulama ve kalite düzeltmelerini değerlendirme, bir zincirin bileşenleri üzerinde nasıl yineleme yapılacağını gösterir.
Sorgu Anlayışı
Kullanıcı sorgusunu doğrudan alma sorgusu olarak kullanmak bazı sorgularda kullanılabilir. Ancak, alma adımından önce sorgunun yeniden düzenlenmesi genellikle yararlıdır. Sorgu anlama, zincirin başında, kullanıcı sorgularını analiz etmek ve dönüştürmek için bir adım (veya bir dizi adım) içerir. Bu adım, amacı daha iyi temsil etmek, ilgili bilgileri ayıklamak ve nihayetinde sonraki bilgilere erişim sürecine yardımcı olmak içindir. Alma işlemini geliştirmek için kullanıcı sorgusunu dönüştürme yaklaşımları şunlardır:
Sorgu yeniden yazma: Sorgu yeniden yazma, bir kullanıcı sorgusunu özgün amacı daha iyi temsil eden bir veya daha fazla sorguya çevirmeyi içerir. Amaç, sorguyu, alma adımının en uygun belgeleri bulma olasılığını artıracak şekilde yeniden oluşturmaktır. Bu, özellikle alma belgelerinde kullanılan terminolojiyle doğrudan eşleşmeyen karmaşık veya belirsiz sorgularla ilgilenirken yararlı olabilir.
Örnekler:
- Çok aşamalı sohbette konuşma geçmişini ifade etme
- Kullanıcının sorgusundaki yazım hatalarını düzeltme
- Daha geniş bir ilgili belge yelpazesini yakalamak için kullanıcı sorgusundaki sözcükleri veya tümcecikleri eş anlamlılarla değiştirme
Önemli
Sorgu yeniden yazma, alma bileşenindeki değişikliklerle birlikte yapılmalıdır
Filtre ayıklama: Bazı durumlarda, kullanıcı sorguları arama sonuçlarını daraltmak için kullanılabilecek belirli filtreler veya ölçütler içerebilir. Filtre ayıklama, bu filtreleri tanımlamayı ve sorgudan ayıklamayı ve bunları ek parametreler olarak alma adımına geçirmeyi içerir. Bu, kullanılabilir verilerin belirli alt kümelerine odaklanarak alınan belgelerin ilgi düzeyini artırmaya yardımcı olabilir.
Örnekler:
- Sorguda bahsedilen "son 6 ayın makaleleri" veya "2023 raporları" gibi belirli zaman aralıklarını ayıklama.
- Sorgudaki "Databricks Professional Services" veya "dizüstü bilgisayarlar" gibi belirli ürün, hizmet veya kategorilerden bahsedenleri tanımlama.
- Sorgudan şehir adları veya ülke kodları gibi coğrafi varlıkları ayıklama.
Not
Filtre ayıklama, hem meta veri ayıklama veri işlem hattındahem de retriever zinciri bileşenlerinde yapılan değişikliklerle birlikte yapılmalıdır. Meta veri ayıklama adımı, her belge/öbek için ilgili meta veri alanlarının kullanılabilir olmasını sağlamalı ve ayıklanan filtreleri kabul etmek ve uygulamak için alma adımı uygulanmalıdır.
Sorgu yeniden yazma ve filtre ayıklamaya ek olarak, sorgu anlamada dikkat edilmesi gereken bir diğer önemli nokta da tek bir LLM çağrısı mı yoksa birden çok çağrı mı kullanılacağıdır. Dikkatle hazırlanmış bir istemle tek bir çağrı kullanmak verimli olabilir ancak sorgu anlama işlemini birden çok LLM çağrısına bölmenin daha iyi sonuçlara yol açabileceği durumlar vardır. Bu arada, tek bir istemde bir dizi karmaşık mantık adımı uygulamaya çalışırken bu genel olarak geçerli bir kuraldır.
Örneğin, sorgu amacını sınıflandırmak için bir LLM çağrısı, ilgili varlıkları ayıklamak için başka bir LLM çağrısı ve ayıklanan bilgilere göre sorguyu yeniden yazmak için üçüncü bir çağrı kullanabilirsiniz. Bu yaklaşım genel işleme biraz gecikme katsa da, daha ayrıntılı denetime olanak tanıyabilir ve alınan belgelerin kalitesini artırma potansiyeline sahip olabilir.
Destek botu için çok adımlı sorgu anlama
Çok adımlı sorgu anlama bileşeni müşteri destek botu için şu şekilde görünebilir:
- Amaç sınıflandırması: Kullanıcının sorgusunu "ürün bilgileri", "sorun giderme" veya "hesap yönetimi" gibi önceden tanımlanmış kategoriler halinde sınıflandırmak için LLM kullanın.
- Varlık ayıklama: Tanımlanan amada bağlı olarak, sorgudan ürün adları, bildirilen hatalar veya hesap numaraları gibi ilgili varlıkları ayıklamak için başka bir LLM çağrısı kullanın.
- Sorgu yeniden yazma: Ayıklanan amacı ve varlıkları kullanarak özgün sorguyu daha belirgin ve hedefli bir biçimde yeniden yazın; örneğin, "RAG zincirim Model Sunma'da dağıtılamıyor, aşağıdaki hatayı görüyorum...".
Alma
RAG zincirinin alma bileşeni, alma sorgusu verilen en ilgili bilgi öbeklerini bulmaktan sorumludur. Yapılandırılmamış veriler bağlamında, alma işlemi genellikle anlamsal arama, anahtar sözcük tabanlı arama ve meta veri filtrelemenin bir veya bir birleşimini içerir. Alma stratejisinin seçimi uygulamanızın belirli gereksinimlerine, verilerin doğasına ve işlemeyi beklediğiniz sorgu türlerine bağlıdır. Şimdi şu seçenekleri karşılaştıralım:
- Anlamsal arama: Anlamsal arama, her metin öbeğinin anlamsal anlamını yakalayan bir vektör gösterimine dönüştürülmesi için bir ekleme modeli kullanır. Alma sorgusunun vektör gösterimini öbeklerin vektör gösterimleriyle karşılaştıran anlamsal arama, sorgudaki tam anahtar sözcükleri içermese bile kavramsal olarak benzer belgeleri alabilir.
- Anahtar sözcük tabanlı arama: Anahtar sözcük tabanlı arama, paylaşılan sözcüklerin alma sorgusuyla dizine alınan belgeler arasındaki sıklığını ve dağıtımını analiz ederek belgelerin ilgi düzeyini belirler. Hem sorguda hem de belgede aynı sözcükler ne kadar sık görünürse, o belgeye atanan ilgi puanı o kadar yüksek olur.
- Karma arama: Karma arama, iki aşamalı bir alma işlemi kullanarak hem anlamsal hem de anahtar sözcük tabanlı aramanın güçlü yönlerini birleştirir. İlk olarak, kavramsal olarak ilgili bir dizi belgeyi almak için anlamsal bir arama gerçekleştirir. Ardından, sonuçları tam anahtar sözcük eşleşmelerine göre daha da daraltmak için bu azaltılmış kümeye anahtar sözcük tabanlı arama uygular. Son olarak, belgeleri sıralamak için her iki adımdaki puanları birleştirir.
Alma stratejilerini karşılaştır
Aşağıdaki tabloda bu alma stratejilerinin her biri birbiriyle karşıttır:
| Anlamsal arama | Anahtar sözcük araması | Karma arama | |
|---|---|---|---|
| Basit açıklama | Sorguda ve olası bir belgede aynı kavramlar görünüyorsa, bunlar uygun olur. | Sorguda ve olası bir belgede aynı sözcükler görünüyorsa, bunlar uygun olur. Belgedeki sorgudan ne kadar çok sözcük olursa, o kadar ilgili olur. | HEM anlamsal arama hem de anahtar sözcük araması çalıştırır, ardından sonuçları birleştirir. |
| Örnek kullanım örneği | Kullanıcı sorgularının ürün kılavuzlarındaki sözcüklerden farklı olduğu müşteri desteği. Örnek: "Telefonumu nasıl açabilirim?" ve kılavuzun ilgili bölümü "güç değiştirme" olarak adlandırılır. | Sorguların belirli, açıklayıcı olmayan teknik terimler içerdiği müşteri desteği. Örnek: "HD7-8D modeli ne yapar?" | Hem anlamsal hem de teknik terimleri birleştiren müşteri desteği sorguları. Örnek: "HD7-8D'mi nasıl açabilirim?" |
| Teknik yaklaşımlar | Metni sürekli vektör alanında temsil etmek için eklemeleri kullanarak anlamsal aramayı etkinleştirir. | Anahtar sözcük eşleştirme için bag-of-words, TF-IDF, BM25 gibi ayrık belirteç tabanlı yöntemlere dayanır. | Sonuçları birleştirmek için karşılıklı derecelendirme füzyonu veya yeniden derecelendirme modeli gibi yeniden derecelendirme yaklaşımını kullanın. |
| Güçlü | Tam sözcükler kullanılmasa bile bağlamsal olarak bir sorguya benzer bilgiler alınıyor. | Kesin anahtar sözcük eşleşmeleri gerektiren senaryolar, ürün adları gibi belirli terim odaklı sorgular için idealdir. | Her iki yaklaşımın da en iyilerini birleştirir. |
Alma işlemini geliştirmenin yolları
Bu temel alma stratejilerine ek olarak, alma işlemini daha da geliştirmek için uygulayabileceğiniz birkaç teknik vardır:
- Sorgu genişletme: Sorgu genişletme, alma sorgusunun birden çok varyasyonunu kullanarak daha geniş bir ilgili belge aralığını yakalamaya yardımcı olabilir. Bu, genişletilmiş her sorgu için tek tek aramalar yaparak veya tek bir alma sorgusunda tüm genişletilmiş arama sorgularının birleştirilmesi kullanılarak elde edilebilir.
Not
Sorgu genişletme, sorgu anlama bileşeninde (RAG zinciri) yapılan değişikliklerle birlikte yapılmalıdır. Alma sorgusunun birden çok varyasyonu genellikle bu adımda oluşturulur.
- Yeniden derecelendirme: İlk öbek kümesini aldıktan sonra, sonuçları yeniden sıralamak için ek derecelendirme ölçütleri (örneğin, zamana göre sırala) veya yeniden sıralama modeli uygulayın. Yeniden derecelendirme, belirli bir alma sorgusuna göre en uygun öbeklerin önceliğini belirlemeye yardımcı olabilir. mxbai-rerank ve ColBERTv2 gibi çapraz kodlayıcı modellerle yeniden sıralama, alma performansında bir iyileştirme sağlayabilir.
- Meta veri filtreleme: Arama alanını belirli ölçütlere göre daraltmak için sorgu anlama adımından ayıklanan meta veri filtrelerini kullanın. Meta veri filtreleri belge türü, oluşturma tarihi, yazar veya etki alanına özgü etiketler gibi öznitelikleri içerebilir. Meta veri filtrelerini anlamsal veya anahtar sözcük tabanlı arama ile birleştirerek daha hedefli ve verimli alma oluşturabilirsiniz.
Not
Meta veri filtreleme, sorgu anlama (RAG zinciri) ve meta veri ayıklama (veri işlem hattı) bileşenlerindeki değişikliklerle birlikte yapılmalıdır.
Komut Genişletme
İstem artırma, kullanıcı sorgusunun bir istem şablonundaki alınan bilgiler ve yönergelerle birleştirilerek dil modelinin yüksek kaliteli yanıtlar üretmeye doğru yönlendirildiği adımdır. Modelin doğru, temellendirilmiş ve tutarlı yanıtlar üretmesini sağlamak amacıyla LLM'ye sağlanan komutu optimize etmek için bu şablonda yineleme yapmak gereklidir (AKA komut mühendisliği).
İstem mühendisliğine dair kılavuzlar vardır, ancak istem şablonunu tekrar ederken dikkate almanız gereken bazı hususlar şunlardır:
- Örnekler sağlayın
- İyi biçimlendirilmiş sorguların örneklerini ve bunlara karşılık gelen ideal yanıtları istem şablonunun kendisinde (birkaç denemeli öğrenme) ekleyin. Bu, modelin yanıtların istenen biçimini, stilini ve içeriğini anlamasına yardımcı olur.
- İyi örnekler oluşturmanın kullanışlı bir yöntemi, zincirinizin zorlandığı sorgu türlerini belirlemektir. Bu sorgular için altın standart yanıtlar oluşturun ve bunları istemde örnek olarak ekleyin.
- Sağladığınız örneklerin çıkarım zamanında tahmin ettiğiniz kullanıcı sorgularını temsil ettiğinden emin olun. Modelin daha iyi genelleştirilmesine yardımcı olmak için beklenen çeşitli sorguları kapsamayı hedefleyin.
- İstem şablonunuzu parametreleştirme
- alınan veriler ve kullanıcı sorgusunun ötesinde ek bilgiler içerecek şekilde parametreleştirerek istem şablonunuzu esnek olacak şekilde tasarlayın. Bu, geçerli tarih, kullanıcı bağlamı veya diğer ilgili meta veriler gibi değişkenler olabilir.
- Bu değişkenleri çıkarım zamanında istem içine eklemek daha kişiselleştirilmiş veya bağlama duyarlı yanıtlar sağlayabilir.
- Düşünce Zinciri istemini dikkate alın
- Doğrudan yanıtların kolayca görünür olmadığı karmaşık sorgular için Düşünce Zinciri (CoT) istemini göz önünde bulundurun. Bu istem mühendisliği stratejisi karmaşık soruları daha basit, sıralı adımlara bölerek LLM'ye mantıksal bir akıl yürütme süreci boyunca yol gösterir.
- Modelin "sorunu adım adım düşünmesini" sağlayarak, çok adımlı veya açık uçlu sorguları işlemek için özellikle etkili olabilecek daha ayrıntılı ve iyi gerekçeli yanıtlar sağlamasını öneririz.
- İstemler farklı modeller arasında aktarılamayabilir
- İstemlerin genellikle farklı dil modellerinde sorunsuz bir şekilde aktarılmadığını fark edin. Her modelin kendine özgü özellikleri vardır ve bir model için iyi çalışan bir istem diğer model için o kadar etkili olmayabilir.
- Farklı istem biçimleri ve uzunluklarıyla denemeler yapın, çevrimiçi kılavuzlara (OpenAI Yemek Kitabı veya Antropik yemek kitabı) bakın ve modeller arasında geçiş yaparken istemlerinizi uyarlamaya ve iyileştirmeye hazır olun.
Hukuk Yüksek Lisansı (LLM)
RAG zincirinin üretim bileşeni, önceki adımdan genişletilmiş istem şablonunu alır ve bunu bir LLM'ye iletir. BIR RAG zincirinin nesil bileşeni için bir LLM'yi seçip iyileştirirken, LLM çağrılarını içeren diğer adımlar için de aynı şekilde geçerli olan aşağıdaki faktörleri göz önünde bulundurun:
- Farklı kullanıma hazır modellerle denemeler yapın.
- Her modelin kendine özgü özellikleri, güçlü yanları ve zayıflıkları vardır. Bazı modeller belirli etki alanlarını daha iyi anlanabilir veya belirli görevlerde daha iyi performans gösterebilir.
- Daha önce belirtildiği gibi, farklı modeller aynı istemlere farklı yanıtlar verebileceği için model seçiminin istem mühendisliği sürecini de etkileyeebileceğini unutmayın.
- Zincirinizde LLM gerektiren, oluşturma adımına ek olarak sorgu anlama çağrıları gibi birden çok adım varsa, farklı adımlar için farklı modeller kullanmayı göz önünde bulundurun. Kullanıcı sorgusunun amacını belirlemek gibi görevler için daha pahalı, genel amaçlı modeller gereksiz olabilir.
- Küçük bir başlangıç yapın ve gerektiğinde ölçeği büyütün.
- Mevcut en güçlü ve yetenekli modellere (örneğin, GPT-4, Claude) hemen ulaşmak cazip olsa da, daha küçük ve daha hafif modellerle başlamak genellikle daha verimlidir.
- Çoğu durumda, Llama 3 veya DBRX gibi daha küçük açık kaynak alternatifler daha düşük maliyetle ve daha hızlı çıkarım süreleriyle tatmin edici sonuçlar sağlayabilir. Bu modeller, son derece karmaşık mantık yürütme veya kapsamlı dünya bilgisi gerektirmeyen görevler için özellikle etkili olabilir.
- RAG zincirinizi geliştirip geliştirdikçe, seçtiğiniz modelin performansını ve sınırlamalarını sürekli olarak değerlendirin. Modelin belirli sorgu türleriyle mücadele ettiğini veya yeterince ayrıntılı veya doğru yanıtlar sağlayamadığını fark ederseniz daha yetenekli bir modele ölçeklendirmeyi göz önünde bulundurun.
- Belirli bir kullanım örneğinizin gereksinimleri için doğru dengeyi sağladığınızdan emin olmak için modellerin yanıt kalitesi, gecikme süresi ve maliyet gibi önemli ölçümler üzerindeki etkisini izleyin.
- Model parametrelerini iyileştirme
- Yanıt kalitesi, çeşitlilik ve tutarlılık arasındaki en uygun dengeyi bulmak için farklı parametre ayarlarıyla denemeler yapın. Örneğin, sıcaklığı ayarlamak oluşturulan metnin rastgeleliğini denetlerken, max_tokens yanıt uzunluğunu sınırlayabilir.
- En uygun parametre ayarlarının belirli göreve, isteme ve istenen çıkış stiline bağlı olarak değişebileceğini unutmayın. Oluşturulan yanıtların değerlendirilmesi temelinde bu ayarları yinelemeli olarak test edin ve geliştirin.
- Göreve özgü ince ayarlama
- Performansı iyileştirdikçe, RAG zincirinizdeki sorgu anlama gibi belirli alt görevler için daha küçük modellerde ince ayarlamalar yapmayı göz önünde bulundurun.
- RAG zinciriyle tek tek görevler için özelleştirilmiş modeller eğiterek, tüm görevler için tek bir büyük model kullanmaya kıyasla genel performansı geliştirebilir, gecikme süresini azaltabilir ve çıkarım maliyetlerini düşürebilirsiniz.
- Devam eden ön eğitim
- RAG uygulamanız özelleştirilmiş bir etki alanıyla ilgileniyorsa veya önceden eğitilmiş LLM'de iyi temsil edilmeyen bir bilgiye ihtiyaç duyuyorsa, etki alanına özgü veriler üzerinde devam eden ön eğitim (CPT) gerçekleştirmeyi göz önünde bulundurun.
- Devam eden ön eğitim, modelin etki alanınıza özgü belirli terminolojiyi veya kavramları anlamayı geliştirebilir. Bu da kapsamlı istem mühendisliği veya birkaç deneme örneği gereksinimini azaltabilir.
Son işlem ve koruma önlemleri
LLM bir yanıt oluşturduktan sonra, çıkışın istenen biçim, stil ve içerik gereksinimlerini karşıladığından emin olmak için genellikle son işleme tekniklerinin veya koruyucuların uygulanması gerekir. Zincirdeki bu son adım (veya birden çok adım), oluşturulan yanıtlarda tutarlılık ve kalitenin korunmasına yardımcı olabilir. İşlem sonrası veri işleme ve koruma önlemleri uyguluyorsanız, aşağıdakilerden bazılarını göz önünde bulundurun:
- Çıkış biçimini zorunlu tutma
- Kullanım örneğinize bağlı olarak, oluşturulan yanıtların yapılandırılmış şablon veya belirli bir dosya türü (JSON, HTML, Markdown vb.) gibi belirli bir biçime uymasını isteyebilirsiniz.
- Yapılandırılmış çıkış gerekiyorsa, Eğitmen veya Anahatlar gibi kitaplıklar bu tür doğrulama adımlarını uygulamak için iyi başlangıç noktaları sağlar.
- Geliştirme sırasında, işlem sonrası adımın gerekli biçimi korurken oluşturulan yanıtlardaki varyasyonları işleyecek kadar esnek olduğundan emin olmak için zaman ayırın.
- Stil tutarlılığını koruma
- RAG uygulamanızın belirli stil yönergeleri veya ton gereksinimleri (ör. resmi ve gündelik, kısa ve ayrıntılı) varsa, işlem sonrası adım oluşturulan yanıtlarda bu stil özniteliklerini hem denetleyebilir hem de uygulayabilir.
- İçerik filtreleri ve güvenlik koruyucuları
- RAG uygulamanızın niteliğine ve oluşturulan içerikle ilişkili olası risklere bağlı olarak, uygunsuz, rahatsız edici veya zararlı bilgilerin çıkışını önlemek için içerik filtreleri veya güvenlik koruyucuları uygulamak önemli olabilir.
- Güvenlik korumaları uygulamak için Llama Guard gibi modelleri veya OpenAI'nin denetim API'si gibi içerik denetimi ve güvenlik için özel olarak tasarlanmış API'leri kullanmayı göz önünde bulundurun.
- Halüsinasyonları işleme
- Halüsinasyonlara karşı savunma, işlem sonrası bir adım olarak da uygulanabilir. Bu, alınan belgelerle oluşturulan çıktıya çapraz başvuruda bulunmak veya yanıtın gerçek doğruluğunu doğrulamak için ek LLM'ler kullanmayı içerebilir.
- Oluşturulan yanıtın alternatif yanıtlar oluşturma veya kullanıcıya yasal uyarı sağlama gibi olgusal doğruluk gereksinimlerini karşılayamaması durumlarını işlemek için geri dönüş mekanizmaları geliştirin.
- Hata işleme
- Tüm işlem sonrası adımlarda, adımın bir sorunla karşılaştığı veya tatmin edici bir yanıt üretemediği durumlarla düzgün bir şekilde başa çıkmak için mekanizmalar uygulayın. Bu, varsayılan bir yanıt oluşturmayı veya sorunu el ile gözden geçirme için bir insan operatöre iletmeyi içerebilir.