Göl evi için yol gösterici ilkeler
Kılavuz ilkeler, mimarinizi tanımlayan ve etkileyen sıfır düzeyinde kurallardır. İşletmenizin hem şimdi hem de gelecekte başarılı olmasına yardımcı olan bir data lakehouse oluşturmak için, kuruluşunuzdaki paydaşlar arasında fikir birliği kritik öneme sahiptir.
Verileri seçme ve güvenilir ürünler olarak veri sunma
Verileri seçmek, BI ve ML/AI için yüksek değerli bir veri gölü oluşturmak için gereklidir. Verileri net bir tanım, şema ve yaşam döngüsüyle bir ürün gibi değerlendirin. İş kullanıcılarının verilere tam olarak güvenebilmesi için anlam tutarlılığını ve veri kalitesinin katmandan katmana artmasını sağlayın.

Veri ekiplerinin verileri kalite düzeylerine göre yapılandırmalarına ve katman başına rolleri ve sorumlulukları tanımlamalarına olanak tanıdığından, katmanlı (veya çok atlamalı) bir mimari oluşturarak verileri seçmek göl evi için kritik bir en iyi uygulamadır. Yaygın katmanlama yaklaşımı:
- Alma katmanı: Kaynak veriler lakehouse'a ilk katmana alınır ve orada kalıcı hale getirilmelidir. Alma Katmanından tüm aşağı akış verileri oluşturulduğunda, gerekirse bu katmandan sonraki katmanları yeniden oluşturmak mümkündür.
- Seçilmiş katman: İkinci katmanın amacı temizlenmiş, rafine edilmiş, filtrelenmiş ve toplanmış verileri tutmaktır. Bu katmanın amacı, tüm roller ve işlevler genelinde analizler ve raporlar için sağlam ve güvenilir bir temel sağlamaktır.
- Son katman: Üçüncü katman iş veya proje gereksinimleriyle oluşturulur; diğer iş birimlerine veya projelere veri ürünleri olarak farklı bir görünüm sağlar, güvenlik gereksinimleri (örneğin anonimleştirilmiş veriler) ile ilgili verileri hazırlar veya performansı en iyi duruma getirerek (önceden toplanmış görünümlerle). Bu katmandaki veri ürünleri işletme için gerçek olarak görülür.
Tüm katmanlardaki işlem hatlarının veri kalitesi kısıtlamalarının karşılandığından emin olması gerekir; bu da verilerin eşzamanlı okuma ve yazma işlemleri sırasında bile her zaman doğru, eksiksiz, erişilebilir ve tutarlı olduğu anlamına gelir. Yeni verilerin doğrulanması, seçilen katmana veri girişi sırasında gerçekleşir ve aşağıdaki ETL adımları bu verilerin kalitesini artırmak için çalışır. Veriler katmanlar arasında ilerledikçe ve bu nedenle verilere olan güven daha sonra iş açısından arttıkça veri kalitesi artmalıdır.
Veri silolarını ortadan kaldırma ve veri hareketini en aza indirme
Bu farklı kopyaları kullanan iş süreçleriyle bir veri kümesinin kopyalarını oluşturmayın. Kopyalar, veri gölünüzün kalitesinin düşmesine ve son olarak güncel olmayan veya yanlış içgörülere yol açan veri siloları haline gelebilir. Ayrıca, verileri dış iş ortaklarıyla paylaşmak için verilere güvenli bir şekilde doğrudan erişim sağlayan bir kurumsal paylaşım mekanizması kullanın.

Veri kopyalama ile veri silosu arasındaki ayrımı net bir şekilde ifade etmek için: Tek başına veya atıl durumdaki bir veri kopyası kendi başına zararlı değildir. Bazen çevikliği, denemeleri ve yenilikleri artırmak için gereklidir. Ancak bu kopyalar, bunlara bağımlı olan aşağı akış iş verileri ürünleriyle çalışır hale gelirse veri silolarına dönüşür.
Veri silolarını önlemek için, veri ekipleri genellikle tüm kopyaları özgün kopyalarla eşitlenmiş durumda tutmak için bir mekanizma veya veri işlem hattı oluşturmaya çalışır. Bunun tutarlı bir şekilde gerçekleşme olasılığı düşük olduğundan, veri kalitesi sonunda düşer. Bu, daha yüksek maliyetlere ve kullanıcılar tarafından önemli bir güven kaybına da yol açabilir. Öte yandan, çeşitli iş kullanım örnekleri iş ortaklarıyla veya tedarikçilerle veri paylaşımı gerektirir.
Önemli bir özellik, veri kümesinin en son sürümünü güvenli ve güvenilir bir şekilde paylaşmaktır. Veri kümesinin kopyaları genellikle yeterli değildir, çünkü bunlar hızla eşitlenmemiş olabilir. Bunun yerine, verilerin kurumsal veri paylaşım araçlarıyla paylaşılması gerekir.
Self servis aracılığıyla değer oluşturmayı demokratikleştirme
Kullanıcılar BI ve ML/AI görevleri için platforma veya verilere kolayca erişemediğinde en iyi veri gölü yeterli değer sağlayamaz. Tüm iş birimleri için verilere ve platformlara erişim engellerini azaltın. Yalın veri yönetimi süreçlerini göz önünde bulundurun ve platform ve temel alınan veriler için self servis erişim sağlayın.

Veri odaklı bir kültüre başarıyla taşınan işletmeler başarılı olur. Bu, her iş biriminin kararlarını analiz modellerinden veya kendi veya merkezi olarak sağlanan verileri analiz etmesinden aldığı anlamına gelir. Tüketiciler için verilerin kolayca bulunabilir ve güvenli bir şekilde erişilebilir olması gerekir.
Veri üreticileri için iyi bir kavram "ürün olarak veriler"dir: Veriler bir ürün gibi bir iş birimi veya iş ortağı tarafından sunulur ve korunur ve uygun izin denetimine sahip diğer taraflar tarafından kullanılır. Merkezi bir ekibe ve potansiyel olarak yavaş istek süreçlerine güvenmek yerine, bu veri ürünlerinin bir self servis deneyiminde oluşturulması, sunulması, bulunması ve tüketilmesi gerekir.
Ancak önemli olan yalnızca veriler değildir. Verilerin demokratikleştirilmesi, herkesin verileri üretmesine veya kullanmasına ve anlamasına olanak tanımak için doğru araçları gerektirir. Bunun için data lakehouse'un, başka bir araç yığını ayarlama çabasını yinelemeden veri ürünleri oluşturmaya yönelik altyapı ve araçlar sağlayan modern bir veri ve yapay zeka platformu olması gerekir.
Kuruluş genelinde veri idare stratejisini benimseme
Veriler, herhangi bir kuruluşun kritik bir varlığıdır, ancak herkese tüm verilere erişim veremezsiniz. Veri erişimi etkin bir şekilde yönetilmelidir. Erişim denetimi, denetim ve köken izleme, verilerin doğru ve güvenli kullanımı için önemlidir.

Veri idaresi geniş bir konu başlığıdır. Göl evi aşağıdaki boyutları kapsar:
Veri kalitesi
Doğru ve anlamlı raporlar, analiz sonuçları ve modeller için en önemli önkoşul yüksek kaliteli verilerdir. Kalite güvencesi (QA) tüm işlem hattı adımlarında mevcut olması gerekir. Veri sözleşmelerine sahip olmak, SLA'larla toplantı yapmak, şemaları kararlı tutmak ve bunları denetimli bir şekilde geliştirmek buna örnek olarak verilebilir.
Veri kataloğu
Veri bulmanın bir diğer önemli yönü de: Özellikle self servis modelinde tüm iş alanlarının kullanıcılarının ilgili verileri kolayca bulabilmesi gerekir. Bu nedenle, bir lakehouse,işle ilgili tüm verileri kapsayan bir veri kataloğuna ihtiyaç duyar. Veri kataloğunun birincil hedefleri şunlardır:
- Aynı iş kavramının tekdüzen olarak çağrıldığından ve işletme genelinde bildirildiğinden emin olun. Bunu, seçilmiş ve son katmanda semantik bir model olarak düşünebilirsiniz.
- Kullanıcıların bu verilerin geçerli şekil ve formlarına nasıl ulaştığını açıklayabilmesi için veri kökenini tam olarak izleyin.
- Verilerin düzgün kullanımı için verilerin kendisi kadar önemli olan yüksek kaliteli meta verileri koruyun.
Erişim denetimi
Göl evindeki verilerden değer oluşturma işlemi tüm iş alanlarında gerçekleştiğinden, göl evi birinci sınıf bir vatandaş olarak güvenlikle inşa edilmelidir. Şirketler daha açık bir veri erişim ilkesine sahip olabilir veya en az ayrıcalık ilkesine kesinlikle uyar. Bundan bağımsız olarak, veri erişim denetimleri her katmanda yer almalıdır. En başından itibaren (sütun ve satır düzeyi erişim denetimi, rol tabanlı veya öznitelik tabanlı erişim denetimi) ince sınıf izin düzenleri uygulamak önemlidir. Şirketler daha az katı kurallarla başlayabilir. Ancak göl evi platformu büyüdükçe, daha gelişmiş bir güvenlik rejimi için tüm mekanizmalar ve süreçler zaten mevcut olmalıdır. Ayrıca, göl evindeki verilere tüm erişim, get-go'dan denetim günlüklerine tabi olmalıdır.
Açık arabirimleri ve açık biçimleri teşvik edin
Açık arabirimler ve veri biçimleri, göl evi ve diğer araçlar arasında birlikte çalışabilirlik açısından çok önemlidir. Mevcut sistemlerle tümleştirmeyi basitleştirir ve ayrıca araçlarını platformla tümleştiren iş ortaklarından oluşan bir ekosistem açar.

Açık arabirimler, birlikte çalışabilirliği etkinleştirmek ve tek bir satıcıya bağımlılığı önlemek için kritik öneme sahiptir. Geleneksel olarak satıcılar, kuruluşların verileri depolama, işleme ve paylaşma yöntemleriyle sınırlı olduğu özel teknolojiler ve kapalı arabirimler oluşturur.
Açık arabirimler üzerine derlemek, gelecek için oluşturmanıza yardımcı olur:
- Daha fazla uygulamayla ve daha fazla kullanım örneğiyle kullanabilmeniz için verilerin uzun ömürlülüğünü ve taşınabilirliğini artırır.
- Araçlarını lakehouse platformuyla tümleştirmek için açık arabirimlerden hızlı bir şekilde yararlanabilen iş ortaklarının ekosistemini açar.
Son olarak, veriler için açık biçimleri standartlaştırarak toplam maliyetler önemli ölçüde daha düşük olacaktır; yüksek çıkış ve hesaplama maliyetlerine yol açabilecek özel bir platform aracılığıyla yönlendirmeye gerek kalmadan verilere doğrudan bulut depolamadan erişebilir.
Performans ve maliyet için ölçeklendirmeye ve iyileştirmeye yönelik derleme
Veriler kaçınılmaz olarak büyümeye devam eder ve daha karmaşık hale gelir. Kuruluşunuzu gelecekteki ihtiyaçlara göre donatmak için gölünüzün ölçeklenebilmesi gerekir. Örneğin, isteğe bağlı olarak kolayca yeni kaynaklar ekleyebilmeniz gerekir. Maliyetler gerçek tüketimle sınırlı olmalıdır.
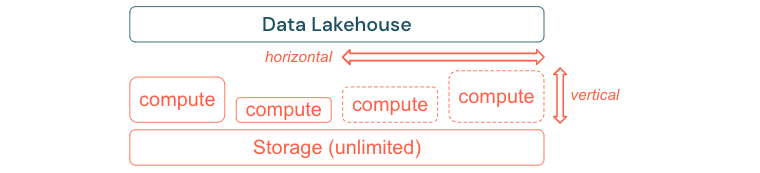
Standart ETL işlemleri, iş raporları ve panolar genellikle bellek ve hesaplama perspektifinden tahmin edilebilir bir kaynak gereksinimine sahiptir. Ancak yeni projeler, mevsimsel görevler veya model eğitimi (değişim sıklığı, tahmin, bakım) gibi modern yaklaşımlar, kaynak ihtiyacının en yoğun olduğu aşamaları oluşturur. Bir işletmenin tüm bu iş yüklerini gerçekleştirmesini sağlamak için bellek ve hesaplama için ölçeklenebilir bir platform gereklidir. Yeni kaynakların isteğe bağlı olarak kolayca eklenmesi ve yalnızca gerçek tüketimin maliyet oluşturması gerekir. Zirve sona erer bitmez kaynaklar yeniden boşaltılabilir ve maliyetler buna göre azaltılabilir. Bu genellikle yatay ölçeklendirme (daha az veya daha fazla düğüm) ve dikey ölçeklendirme (daha büyük veya daha küçük düğümler) olarak adlandırılır.
Ölçeklendirme, işletmelerin daha fazla kaynağa veya daha fazla düğüme sahip kümelere sahip düğümleri seçerek sorguların performansını geliştirmesine de olanak tanır. Ancak büyük makineleri ve kümeleri kalıcı olarak sağlamak yerine, yalnızca genel performans ile maliyet oranını iyileştirmek için gereken süre boyunca isteğe bağlı olarak sağlanabilirler. İyileştirmenin bir diğer yönü de depolama ve işlem kaynaklarıdır. Bu verileri kullanan veri hacmi ile iş yükleri arasında net bir ilişki olmadığından (örneğin, verilerin yalnızca parçalarını kullanmak veya küçük veriler üzerinde yoğun hesaplamalar yapmak), depolama ve işlem kaynaklarını ayıran bir altyapı platformuna yerleşmek iyi bir uygulamadır.