Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Lakeflow işlem hatları, işlem hatlarında gerçekleştirilmiş görünümleri ve akış tablolarını tanımlamak için birkaç yeni Python kod yapısı sunar. PySpark DataFrame ve Yapılandırılmış Akış API'lerinin temellerini temel alan işlem hatları geliştirmeye yönelik Python desteği.
Python ve DataFrame'leri tanımayan kullanıcılar için Databricks, SQL arabiriminin kullanılmasını önerir. Bkz . SQL ile Lakeflow işlem hattı kodu geliştirme. İki arabirim arasında karar verme konusunda yardım için bkz. SQL ile Python arasında seçim yapma.
Lakeflow işlem hatlarının Python söz diziminin tam başvurusu için bkz. Lakeflow işlem hatları için Python dil başvurusu.
İşlem hattı geliştirme için Python'ın temelleri
İşlem hattı veri kümeleri oluşturan Python kodun DataFrame'leri döndürmesi gerekir.
Tüm Lakeflow işlem hatları Python API'ler modülde pyspark.pipelines uygulanır. Python ile uygulanan işlem hattı kodunuzun, Python kaynağının pipelines en üstündeki modülü açıkça içeri aktarması gerekir. Örneklerimizde aşağıdaki içeri aktarma komutunu kullanırız ve dp öğesine atıfta bulunmak için pipelines kullanırız.
from pyspark import pipelines as dp
Uyarı
Apache Spark™, modül aracılığıyla kullanılabilen Spark 4.1'de başlayan bildirim temelli işlem hatlarınıpyspark.pipelines içerir. Databricks Runtime, bu açık kaynak özelliklerini yönetilen üretim kullanımı için ek API'ler ve tümleştirmelerle genişletir.
Açık kaynak pipelines modülüyle yazılan kod, Azure Databricks'te değişiklik yapılmadan çalıştırılır. Aşağıdaki özellikler Apache Spark'ın bir parçası değildir:
dp.create_auto_cdc_flowdp.create_auto_cdc_from_snapshot_flow@dp.expect(...)
İşlem hattı, işlem hattı yapılandırması sırasında belirtilen kataloğu ve şemayı varsayılan olarak okur ve yazar. Bkz. Hedef kataloğu ve şemayı ayarlama.
İşlem hattına özgü Python kodu, diğer Python kodu türlerinden kritik bir şekilde farklıdır: Python işlem hattı kodu, veri kümeleri oluşturmak için veri alımı ve dönüştürme gerçekleştiren işlevleri doğrudan çağırmaz. Bunun yerine Lakeflow işlem hatları, bir işlem hattında yapılandırılan tüm kaynak kodu dosyalarındaki modüldeki dp dekoratör işlevlerini yorumlar ve bir veri akışı grafiği oluşturur.
Önemli
İşlem hattınız çalışırken beklenmeyen davranışlardan kaçınmak için işlevlerinizde veri kümelerini tanımlayan yan etkileri olabilecek kodu eklemeyin. Daha fazla bilgi edinmek için bkz. Python referansı.
Python ile materyalize görünüm veya akış tablosu oluşturun.
@dp.table kullanarak akış okumasının sonuçlarından bir akış tablosu oluşturun. Toplu okumanın sonuçlarından bir maddi görünüm oluşturmak için @dp.materialized_view kullanın.
Varsayılan olarak, materialize edilmiş görünüm ve akış tablosu adları, işlev adlarından çıkarılır. Aşağıdaki kod örneği, gerçekleştirilmiş görünüm ve akış tablosu oluşturmaya yönelik temel söz dizimini gösterir:
Uyarı
her iki işlev de samples kataloğunda aynı tabloya başvurur ve aynı dekoratör işlevini kullanır. Bu örneklerde, gerçekleştirilmiş görünümler ve akış tabloları için temel söz dizimindeki tek farkın spark.read ve spark.readStreamkullanmak olduğu vurgulanır.
Tüm veri kaynakları akış okumalarını desteklemez. Bazı veri kaynakları her zaman akış semantiğiyle işlenmelidir.
from pyspark import pipelines as dp
@dp.materialized_view()
def basic_mv():
return spark.read.table("samples.nyctaxi.trips")
@dp.table()
def basic_st():
return spark.readStream.table("samples.nyctaxi.trips")
İsteğe bağlı olarak, name dekoratördeki @dp.table bağımsız değişkenini kullanarak tablo adını belirtebilirsiniz. Aşağıdaki örnek, materyalize edilmiş bir görünüm ve akış tablosu için bu modeli gösterir:
from pyspark import pipelines as dp
@dp.materialized_view(name = "trips_mv")
def basic_mv():
return spark.read.table("samples.nyctaxi.trips")
@dp.table(name = "trips_st")
def basic_st():
return spark.readStream.table("samples.nyctaxi.trips")
Nesne deposundan veri yükleme
İşlem hatları, Azure Databricks tarafından desteklenen tüm biçimlerden veri yüklemeyi destekler. bkz. Veri biçimi seçenekleri.
Uyarı
Bu örneklerde, çalışma alanınıza otomatik olarak bağlanan /databricks-datasets'da yer alan veriler kullanılır. Databricks, bulut nesne depolama alanında depolanan verilere başvurmak için birim yollarının veya bulut URI'lerinin kullanılmasını önerir. Bkz. Unity Catalog'un birimleri nelerdir?.
Databricks, artımlı alım iş yüklerini bulut nesne depolamasında depolanan verilere göre yapılandırırken Otomatik Yükleyici ve akış tablolarının kullanılmasını önerir. Bkz. Otomatik Yükleyici nedir?.
Aşağıdaki örnek, Otomatik Yükleyici kullanarak JSON dosyalarından bir akış tablosu oluşturur:
from pyspark import pipelines as dp
@dp.table()
def ingestion_st():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
Aşağıdaki örnek, JSON dizinini okumak ve gerçekleştirilmiş bir görünüm oluşturmak için toplu semantiği kullanır:
from pyspark import pipelines as dp
@dp.materialized_view()
def batch_mv():
return spark.read.format("json").load("/databricks-datasets/retail-org/sales_orders")
Verileri beklentilerle doğrulama
Veri kalitesi kısıtlamalarını ayarlamak ve uygulamak için beklentileri kullanabilirsiniz. bkz. İşlem hattı beklentileriyle veri kalitesini yönetme.
Aşağıdaki kod, veri alımı sırasında null olan kayıtları düşüren @dp.expect_or_drop adlı bir beklenti tanımlamak için valid_data kullanır:
from pyspark import pipelines as dp
@dp.table()
@dp.expect_or_drop("valid_date", "order_datetime IS NOT NULL AND length(order_datetime) > 0")
def orders_valid():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
İşlem hattınızda tanımlanan gerçekleştirilmiş görünümleri ve akış tablolarını sorgulayın
Aşağıdaki örnek dört veri kümesini tanımlar:
- JSON verilerini yükleyen
ordersadlı bir akış tablosu. -
customersadlı, CSV verilerini yükleyen maddi görünüm. -
customer_ordersveordersveri kümelerindeki kayıtları birleştiren, sipariş zaman damgasını bir tarih formatına dönüştüren vecustomers,customer_id,order_numbervestatealanlarını seçenorder_dateadlı oluşturulmuş bir görünüm. - Her eyalet için günlük sipariş sayısını toplayan
daily_orders_by_stateadlı bir materyalize görünüm.
Uyarı
İşlem hattınızdaki görünümleri veya tabloları sorgularken, kataloğu ve şemayı doğrudan belirtebilir veya işlem hattınızda yapılandırılan varsayılanları kullanabilirsiniz. Bu örnekte, orders, customersve customer_orders tabloları, işlem hattınız için yapılandırılan varsayılan katalogdan ve şemadan yazılır ve okunur.
Eski yayımlama modu, işlem hattınızda tanımlanan diğer gerçekleştirilmiş görünümleri ve akış tablolarını sorgulamak için LIVE şemasını kullanır. Yeni işlem hatlarında, LIVE şema söz dizimi sessiz bir şekilde göz ardı edilir.
LIVE şeması (eski) sayfasına bakın.
from pyspark import pipelines as dp
from pyspark.sql.functions import col
@dp.table()
@dp.expect_or_drop("valid_date", "order_datetime IS NOT NULL AND length(order_datetime) > 0")
def orders():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
@dp.materialized_view()
def customers():
return spark.read.format("csv").option("header", True).load("/databricks-datasets/retail-org/customers")
@dp.materialized_view()
def customer_orders():
return (spark.read.table("orders")
.join(spark.read.table("customers"), "customer_id")
.select("customer_id",
"order_number",
"state",
col("order_datetime").cast("int").cast("timestamp").cast("date").alias("order_date"),
)
)
@dp.materialized_view()
def daily_orders_by_state():
return (spark.read.table("customer_orders")
.groupBy("state", "order_date")
.count().withColumnRenamed("count", "order_count")
)
tabloları bir for döngüsünde oluşturma
Program aracılığıyla birden çok tablo oluşturmak için Python for döngülerini kullanabilirsiniz. Bu, yalnızca birkaç parametreye göre değişen çok sayıda veri kaynağınız veya hedef veri kümeniz olduğunda yararlı olabilir ve bu da toplam kodun korunmasına ve daha az kod yedekliliğine neden olur.
for döngüsü, mantığı seri sırada değerlendirir, ancak veri kümeleri için planlama tamamlandıktan sonra işlem hattı mantığı paralel olarak çalıştırır.
Önemli
Veri kümelerini tanımlamak için bu deseni kullanırken, for döngüsüne geçirilen değerlerin listesinin her zaman eklendiğinden emin olun. Daha önce işlem hattında tanımlanmış bir veri kümesi gelecekteki bir işlem hattı çalıştırmasından atlanırsa, bu veri kümesi hedef şemadan otomatik olarak bırakılır.
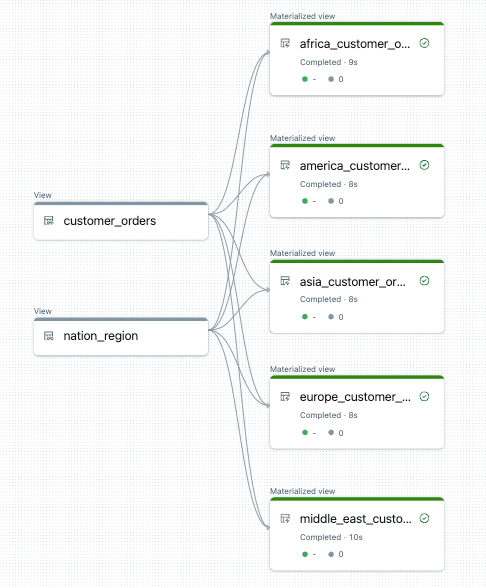
Aşağıdaki örnek, müşteri siparişlerini bölgeye göre filtreleyen beş tablo oluşturur. Burada, hedef gerçekleştirilmiş görünümlerin isimlerini belirlemek ve kaynak verileri filtrelemek için bölge adı kullanılır. Geçici görünümler, son gerçekleştirilmiş görünümleri oluştururken kullanılan kaynak tablolardan birleştirmeleri tanımlamak için kullanılır.
from pyspark import pipelines as dp
from pyspark.sql.functions import collect_list, col
@dp.temporary_view()
def customer_orders():
orders = spark.read.table("samples.tpch.orders")
customer = spark.read.table("samples.tpch.customer")
return (orders.join(customer, orders.o_custkey == customer.c_custkey)
.select(
col("c_custkey").alias("custkey"),
col("c_name").alias("name"),
col("c_nationkey").alias("nationkey"),
col("c_phone").alias("phone"),
col("o_orderkey").alias("orderkey"),
col("o_orderstatus").alias("orderstatus"),
col("o_totalprice").alias("totalprice"),
col("o_orderdate").alias("orderdate"))
)
@dp.temporary_view()
def nation_region():
nation = spark.read.table("samples.tpch.nation")
region = spark.read.table("samples.tpch.region")
return (nation.join(region, nation.n_regionkey == region.r_regionkey)
.select(
col("n_name").alias("nation"),
col("r_name").alias("region"),
col("n_nationkey").alias("nationkey")
)
)
# Extract region names from region table
region_list = spark.read.table("samples.tpch.region").select(collect_list("r_name")).collect()[0][0]
# Iterate through region names to create new region-specific materialized views
for region in region_list:
@dp.materialized_view(name=f"{region.lower().replace(' ', '_')}_customer_orders")
def regional_customer_orders(region_filter=region):
customer_orders = spark.read.table("customer_orders")
nation_region = spark.read.table("nation_region")
return (customer_orders.join(nation_region, customer_orders.nationkey == nation_region.nationkey)
.select(
col("custkey"),
col("name"),
col("phone"),
col("nation"),
col("region"),
col("orderkey"),
col("orderstatus"),
col("totalprice"),
col("orderdate")
).filter(f"region = '{region_filter}'")
)
Bu işlem hattı için veri akışı grafiği örneği aşağıda verilmiştir:
Sorun giderme: for döngüsü aynı değerlere sahip birçok tablo oluşturur
İşlem hatlarının Python kodunu değerlendirmek için kullandığı gecikmeli yürütme modeli, @dp.materialized_view() tarafından dekore edilen işlev çağrıldığında mantığınızın tek tek değerlere doğrudan başvurmasını gerektirir.
Aşağıdaki örnekte, for döngüsüyle tablo tanımlamaya yönelik iki doğru yaklaşım gösterilmektedir. Her iki örnekte de, tables listesindeki her tablo adına, @dp.materialized_view()tarafından süslenen fonksiyon içinde açıkça başvurulur.
from pyspark import pipelines as dp
# Create a parent function to set local variables
def create_table(table_name):
@dp.materialized_view(name=table_name)
def t():
return spark.read.table(table_name)
tables = ["t1", "t2", "t3"]
for t_name in tables:
create_table(t_name)
# Call `@dp.materialized_view()` within a for loop and pass values as variables
tables = ["t1", "t2", "t3"]
for t_name in tables:
@dp.materialized_view(name=t_name)
def create_table(table_name=t_name):
return spark.read.table(table_name)
Aşağıdaki örnek başvuru değerlerini doğru şekilde yapmamaktadır. Bu örnek farklı adlara sahip tablolar oluşturur, ancak tüm tablolar for döngüsündeki son değerden veri yükler:
from pyspark import pipelines as dp
# Don't do this!
tables = ["t1", "t2", "t3"]
for t_name in tables:
@dp.materialized(name=t_name)
def create_table():
return spark.read.table(t_name)
Gerçekleştirilmiş görünümden veya akış tablosundan kayıtları kalıcı olarak silme
GDPR uyumluluğu gibi, silme vektörleri etkinleştirilmiş bir malzemenin görünümünden veya akış tablosundan kayıtları kalıcı olarak silmek için, nesneyi temel alan Delta tablolarında ek işlemler gerçekleştirilmelidir. Gerçekleştirilmiş bir görünümden kayıtların silinmesini sağlamak için bkz. Gerçekleştirilmiş görünümden silme vektörleri etkinleştirilmiş olarak kayıtları kalıcı olarak silme. Akış tablosundan kayıtların silinmesini sağlamak için bkz. Akış tablosundan kayıtları kalıcı olarak silme.