Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Veri mühendisliğinde , geri doldurma , geçerli veya akış verilerini işlemek için tasarlanmış bir veri işlem hattı aracılığıyla geçmişe dönük verileri geriye dönük olarak işleme sürecini ifade eder.
Genellikle bu, mevcut tablolarınıza veri gönderen ayrı bir akıştır. Aşağıdaki çizimde, işlem hattınızdaki bronz tablolara geçmiş verileri gönderen bir geri doldurma akışı gösterilmektedir.
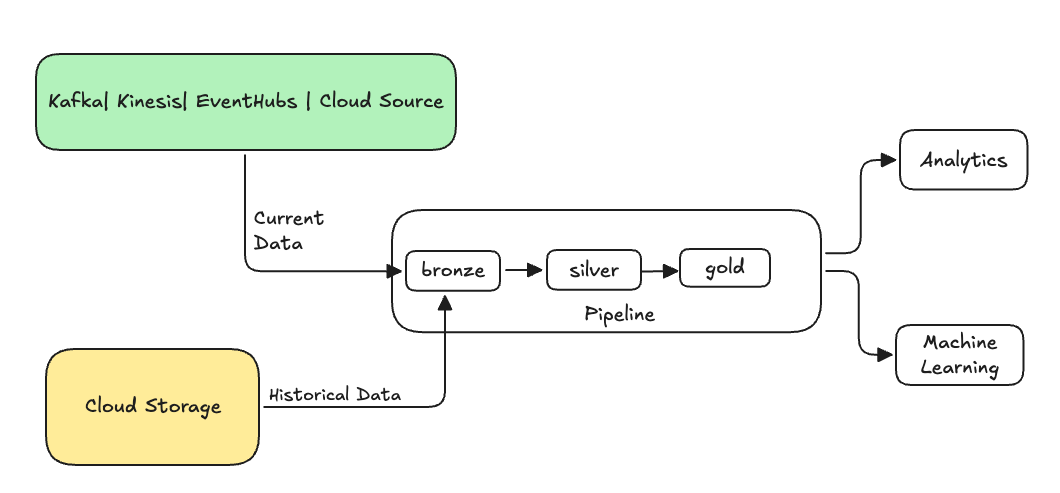
Geri doldurma gerektirebilecek bazı senaryolar:
- Makine öğrenmesi (ML) modelini eğitmek veya geçmiş eğilim analizi panosu oluşturmak için eski bir sistemden geçmiş verileri işleyin.
- Yukarı akış veri kaynaklarıyla ilgili bir veri kalitesi sorunu nedeniyle bir veri alt kümesini yeniden işleyin.
- İş gereksinimleriniz değişti ve ilk işlem hattının kapsamına alınmayan farklı bir zaman aralığı için verileri yedeklemeniz gerekiyor.
- İş mantığınız değişti ve hem geçmiş hem de geçerli verileri yeniden işlemeniz gerekiyor.
Lakeflow Spark Deklaratif İşlem Hatlarında, ONCE seçeneğini kullanan özel bir ekleme akışıyla bir geri doldurma işlemi desteklenir. Seçenek hakkında daha fazla bilgi için append_flow veya CREATE FLOW (işlem hatları) bölümüne bakın.
Geçmiş verileri akış tablosuna doldururken dikkat edilmesi gerekenler
- Genellikle, verileri bronz akış tablosuna ekler. İleriki gümüş ve altın katmanları, bronz katmandan yeni verileri alır.
- Aynı verilerin birden çok kez eklenmesi durumunda işlem hattınızın yinelenen verileri düzgün bir şekilde işleyebileceğinden emin olun.
- Geçmiş veri şemasının geçerli veri şemasıyla uyumlu olduğundan emin olun.
- Veri birimi boyutunu ve gerekli işleme süresi SLA'sını göz önünde bulundurun ve kümeyi ve toplu iş boyutlarını uygun şekilde yapılandırın.
Örnek: Mevcut işlem hattına geriye dönük doldurma ekleme
Bu örnekte, 01 Ocak 2025'ten başlayarak bir bulut depolama kaynağından ham olay kayıt verilerini alan bir işlem hattınız olduğunu varsayalım. Daha sonra aşağı akış raporlama ve analiz kullanım örnekleri için önceki üç yıllık geçmiş verilerini doldurmak istediğinizi fark edersiniz. Tüm veriler JSON biçiminde yıl, ay ve güne göre bölümlenmiş tek bir konumdadır.
İlk işlem hattı
Bulut depolama alanından ham etkinlik kayıt verilerini artımlı olarak alan başlangıç işlem hattı kodu aşağıdadır.
Piton
from pyspark import pipelines as dp
source_root_path = spark.conf.get("registration_events_source_root_path")
begin_year = spark.conf.get("begin_year")
incremental_load_path = f"{source_root_path}/*/*/*"
# create a streaming table and the default flow to ingest streaming events
@dp.table(name="registration_events_raw", comment="Raw registration events")
def ingest():
return (
spark
.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.maxFilesPerTrigger", 100)
.option("cloudFiles.schemaEvolutionMode", "addNewColumns")
.option("modifiedAfter", "2025-01-01T00:00:00.000+00:00")
.load(incremental_load_path)
.where(f"year(timestamp) >= {begin_year}") # safeguard to not process data before begin_year
)
SQL
-- create a streaming table and the default flow to ingest streaming events
CREATE OR REFRESH STREAMING LIVE TABLE registration_events_raw AS
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/*/*/*",
format => "json",
inferColumnTypes => true,
maxFilesPerTrigger => 100,
schemaEvolutionMode => "addNewColumns",
modifiedAfter => "2024-12-31T23:59:59.999+00:00"
)
WHERE year(timestamp) >= '2025'; -- safeguard to not process data before begin_year
Burada, bulut depolama yolundaki modifiedAfter tüm verileri işlemediğimizden emin olmak için Otomatik Yükleyici seçeneğini kullanırız. Artımlı işleme bu sınırda durdurulur.
İpucu
Kafka, Kinesis ve Azure Event Hubs gibi diğer veri kaynakları aynı davranışı elde etmek için eşdeğer okuyucu seçeneklerine sahiptir.
Önceki 3 yıla ait verileri doldurma
Şimdi önceki verileri doldurmak için bir veya daha fazla akış eklemek istiyorsunuz. Bu örnekte aşağıdaki adımları uygulayın:
-
append onceAkışı kullanın. Bu, ilk doldurmadan sonra çalışmaya devam etmeden tek seferlik bir geri doldurma gerçekleştirir. Kod, işlem hattınızda saklanır ve işlem hattı tamamen yenilenirse, yeniden doldurma yeniden başlatılır. - Her yıl için bir tane olan üç geri doldurma akışı oluşturun (bu örnekte veriler yolda yıla göre bölünür). Python için akışların oluşturulmasını parametrelendiririz, ancak SQL'de kodu her akış için bir kez olacak şekilde üç kez tekrarlarız.
Kendi projenizde çalışıyorsanız ve sunucusuz işlem kullanmıyorsanız, işlem hattı için en fazla çalışanı güncelleştirmek isteyebilirsiniz. En fazla çalışanı artırmak, beklenen SLA içinde geçerli akış verilerini işlemeye devam ederken geçmiş verileri işlemek için gerekli kaynaklara sahip olmanıza olanak sağlar.
İpucu
Gelişmiş otomatik ölçeklendirme (varsayılan) ile sunucusuz işlem kullanıyorsanız yükünüz arttığında kümenizin boyutu otomatik olarak artar.
Piton
from pyspark import pipelines as dp
source_root_path = spark.conf.get("registration_events_source_root_path")
begin_year = spark.conf.get("begin_year")
backfill_years = spark.conf.get("backfill_years") # e.g. "2024,2023,2022"
incremental_load_path = f"{source_root_path}/*/*/*"
# meta programming to create append once flow for a given year (called later)
def setup_backfill_flow(year):
backfill_path = f"{source_root_path}/year={year}/*/*"
@dp.append_flow(
target="registration_events_raw",
once=True,
name=f"flow_registration_events_raw_backfill_{year}",
comment=f"Backfill {year} Raw registration events")
def backfill():
return (
spark
.read
.format("json")
.option("inferSchema", "true")
.load(backfill_path)
)
# create the streaming table
dp.create_streaming_table(name="registration_events_raw", comment="Raw registration events")
# append the original incremental, streaming flow
@dp.append_flow(
target="registration_events_raw",
name="flow_registration_events_raw_incremental",
comment="Raw registration events")
def ingest():
return (
spark
.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.maxFilesPerTrigger", 100)
.option("cloudFiles.schemaEvolutionMode", "addNewColumns")
.option("modifiedAfter", "2024-12-31T23:59:59.999+00:00")
.load(incremental_load_path)
.where(f"year(timestamp) >= {begin_year}")
)
# parallelize one time multi years backfill for faster processing
# split backfill_years into array
for year in backfill_years.split(","):
setup_backfill_flow(year) # call the previously defined append_flow for each year
SQL
-- create the streaming table
CREATE OR REFRESH STREAMING TABLE registration_events_raw;
-- append the original incremental, streaming flow
CREATE FLOW
registration_events_raw_incremental
AS INSERT INTO
registration_events_raw BY NAME
SELECT * FROM STREAM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/*/*/*",
format => "json",
inferColumnTypes => true,
maxFilesPerTrigger => 100,
schemaEvolutionMode => "addNewColumns",
modifiedAfter => "2024-12-31T23:59:59.999+00:00"
)
WHERE year(timestamp) >= '2025';
-- one time backfill 2024
CREATE FLOW
registration_events_raw_backfill_2024
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2024/*/*",
format => "json",
inferColumnTypes => true
);
-- one time backfill 2023
CREATE FLOW
registration_events_raw_backfill_2023
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2023/*/*",
format => "json",
inferColumnTypes => true
);
-- one time backfill 2022
CREATE FLOW
registration_events_raw_backfill_2022
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2022/*/*",
format => "json",
inferColumnTypes => true
);
Bu uygulama birkaç önemli deseni vurgular.
Sorumlulukların ayrılması
- Artımlı işleme, geri doldurma işlemlerinden bağımsızdır.
- Her akışın kendi yapılandırma ve iyileştirme ayarları vardır.
- Artımlı ve geri doldurma işlemleri arasında net bir ayrım vardır.
Denetimli yürütme
-
ONCEseçeneğinin kullanılması, her bir doldurma işleminin tam olarak bir kez çalışmasını sağlar. - Geri dolgu akışı boru hattı grafiğinde kalır, ancak tamamlandığında boşta olur. Tam yenileme sonrasında otomatik olarak kullanıma hazırdır.
- İşlem hattı tanımında geri doldurma işlemlerinin net bir denetim izi vardır.
İşleme iyileştirmesi
- Daha hızlı işleme veya işlemenin denetimi için büyük doldurmayı birden çok daha küçük doldurmaya bölebilirsiniz.
- Gelişmiş otomatik ölçeklendirmenin kullanılması, küme boyutunu geçerli küme yüküne göre dinamik olarak ölçeklendirir.
Şema evrimi
-
schemaEvolutionMode="addNewColumns"kullanımı şema değişikliklerini düzgün işler. - Geçmiş ve geçerli veriler arasında tutarlı şema çıkarımına sahipsiniz.
- Yeni verilerde yeni sütunların güvenli bir şekilde işlenmesi sağlanır.