Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Veri düzenleme ve Otomatik Yükleyici için Lakeflow Spark Bildirimli İşlem Hatlarını (SDP) kullanarak yeni bir işlem hattı oluşturmayı öğrenin. Bu kılavuz, verileri temizleyip en iyi 100 kullanıcıyı bulmak için bir sorgu oluşturarak örnek işlem hattını genişletir.
Bu öğreticide, Lakeflow Pipelines Düzenleyicisi'ni kullanarak şunları yapmayı öğreneceksiniz:
- Varsayılan klasör yapısına sahip yeni bir işlem hattı oluşturun ve bir örnek dosya kümesiyle başlayın.
- Beklentileri kullanarak veri kalitesi kısıtlamalarını tanımlayın.
- Verileriniz üzerinde analiz gerçekleştirmek üzere işlem hattını yeni bir dönüşümle genişletmek için düzenleyici özelliklerini kullanın.
Gereksinimler
Bu öğreticiye başlamadan önce şunları yapmalısınız:
- Azure Databricks çalışma alanında oturum açabilirsiniz.
- Çalışma alanınız için Unity Kataloğu'nu etkinleştirin.
- Çalışma alanınız için Lakeflow işlem hatları düzenleyicisini etkinleştirin ve katılmanız gerekir. Bkz. Lakeflow Pipelines Düzenleyicisi'ni ve güncelleştirilmiş izlemeyi etkinleştirme.
- İşlem kaynağı oluşturma veya işlem kaynağına erişim iznine sahip olun.
- Katalogda yeni şema oluşturma izinlerine sahip olun. Gereken izinler
ALL PRIVILEGESveyaUSE CATALOGveCREATE SCHEMA.
1. Adım: İşlem hattı oluşturma
Bu adımda, varsayılan klasör yapısını ve kod örneklerini kullanarak bir işlem hattı oluşturursunuz. Kod örnekleri, örnek veri kaynağındaki users tablosuna referans verirwanderbricks.
Azure Databricks çalışma alanınızda
 Yeni ve ardından
Yeni ve ardından  ETL işlem hattı. İşlem hattı oluşturma sayfasında işlem hattı düzenleyicisi açılır.
ETL işlem hattı. İşlem hattı oluşturma sayfasında işlem hattı düzenleyicisi açılır.İşlem hattınıza bir ad vermek için başlığa tıklayın.
Adın hemen altında çıkış tablolarınızın varsayılan kataloğunu ve şemasını seçin. Bunlar, işlem hattı tanımlarınızda bir katalog ve şema belirtmediğinizde kullanılır.
İşlem hattınızın sonraki adımı altında
 SQL veya Şema simgesindeki örnek kodla başlayınDil tercihinize göre Python'da örnek kodla başlayın. Bu, örnek kodunuzun varsayılan dilini değiştirir, ancak daha sonra diğer dilde kod ekleyebilirsiniz. Bu, başlangıç yapmak için örnek kod içeren bir varsayılan klasör yapısı oluşturur.
SQL veya Şema simgesindeki örnek kodla başlayınDil tercihinize göre Python'da örnek kodla başlayın. Bu, örnek kodunuzun varsayılan dilini değiştirir, ancak daha sonra diğer dilde kod ekleyebilirsiniz. Bu, başlangıç yapmak için örnek kod içeren bir varsayılan klasör yapısı oluşturur.Örnek kodu çalışma alanının sol tarafındaki işlem hattı varlık tarayıcısında görüntüleyebilirsiniz.
transformationsaltında, birer işlem hattı veri kümesi oluşturan iki dosya vardır. altındaexplorations, işlem hattınızın çıkışını görüntülemenize yardımcı olacak kodun yer aldığı bir not defteridir. Bir dosyaya tıklanması, düzenleyicide kodu görüntülemenize ve düzenlemenize olanak tanır.Çıktı veri kümeleri henüz oluşturulmamıştır ve ekranın sağ tarafındaki İşlem Hattı grafiği boştur.
İşlem hattı kodunu (klasördeki
transformationskod) çalıştırmak için ekranın sağ üst kısmındaki İşlem hattını çalıştır'a tıklayın.Çalıştırma tamamlandıktan sonra, çalışma alanının alt kısmında oluşturulan iki yeni tablo
sample_users_<pipeline-name>vesample_aggregation_<pipeline-name>gösterilir. Çalışma alanının sağ tarafındaki İşlem Hattı grafiğinin artık kaynağı dasample_userssample_aggregationdahil olmak üzere iki tabloyu gösterdiğini de görebilirsiniz.
2. Adım: Veri kalitesi denetimleri uygulama
Bu adımda, tabloya sample_users bir veri kalitesi denetimi eklersiniz. Verileri kısıtlamak için işlem hattı beklentilerini kullanırsınız. Bu durumda, geçerli bir e-posta adresi olmayan tüm kullanıcı kayıtlarını siler ve temizlenen tablonun çıkışını olarak users_cleanedverirsiniz.
İşlem hattı varlık tarayıcısı içinde
tıklayın ve Dönüştürme seçeneğini seçin.Yeni dönüştürme dosyası oluştur iletişim kutusunda aşağıdaki seçimleri yapın:
- Dil için Python veya SQL'i seçin. Bunun önceki seçiminizle eşleşmesi gerekmez.
- Dosyaya bir ad verin. Bu durumda
users_cleanedseçin. - Hedef yolu için varsayılan değeri değiştirmeyin.
- Veri kümesi türü için hiçbiri seçili olarak bırakın veya Gerçekleştirilmiş görünümü seçin. Gerçekleştirilmiş görünüm'ü seçerseniz, sizin için örnek kod oluşturur.
Yeni kod dosyanızda, kodu aşağıdakilerle eşleşecek şekilde düzenleyin (önceki ekrandaki seçiminize bağlı olarak SQL veya Python kullanın).
<pipeline-name>değerinisample_userstablonuzun tam adıyla değiştirin.SQL
-- Drop all rows that do not have an email address CREATE MATERIALIZED VIEW users_cleaned ( CONSTRAINT non_null_email EXPECT (email IS NOT NULL) ON VIOLATION DROP ROW ) AS SELECT * FROM sample_users_<pipeline-name>;Piton
from pyspark import pipelines as dp # Drop all rows that do not have an email address @dp.table @dp.expect_or_drop("no null emails", "email IS NOT NULL") def users_cleaned(): return ( spark.read.table("sample_users_<pipeline_name>") )İşlem hattını güncelleştirmek için İşlem hattını çalıştır'a tıklayın. Artık üç tablosu olmalıdır.
3. Adım: En çok kullanılan kullanıcıları analiz etme
Ardından, thay'nin oluşturduğu rezervasyon sayısına göre ilk 100 kullanıcıyı alın.
wanderbricks.bookings tabloyu users_cleaned maddileştirilmiş görünüme birleştirin.
İşlem hattı varlık tarayıcısı içinde
tıklayın ve Dönüştürme seçeneğini seçin.Yeni dönüştürme dosyası oluştur iletişim kutusunda aşağıdaki seçimleri yapın:
- Dil için Python veya SQL'i seçin. Bunun önceki seçimlerinizle eşleşmesi gerekmez.
- Dosyaya bir ad verin. Bu durumda
users_and_bookingsseçin. - Hedef yolu için varsayılan değeri değiştirmeyin.
- Veri kümesi türü için Seçili değil olarak bırakın.
Yeni kod dosyanızda, kodu aşağıdakilerle eşleşecek şekilde düzenleyin (önceki ekrandaki seçiminize bağlı olarak SQL veya Python kullanın).
SQL
-- Get the top 100 users by number of bookings CREATE OR REFRESH MATERIALIZED VIEW users_and_bookings AS SELECT u.name AS name, COUNT(b.booking_id) AS booking_count FROM users_cleaned u JOIN samples.wanderbricks.bookings b ON u.user_id = b.user_id GROUP BY u.name ORDER BY booking_count DESC LIMIT 100;Piton
from pyspark import pipelines as dp from pyspark.sql.functions import col, count, desc # Get the top 100 users by number of bookings @dp.table def users_and_bookings(): return ( spark.read.table("users_cleaned") .join(spark.read.table("samples.wanderbricks.bookings"), "user_id") .groupBy(col("name")) .agg(count("booking_id").alias("booking_count")) .orderBy(desc("booking_count")) .limit(100) )Veri kümelerini güncelleştirmek için İşlem hattını çalıştır'a tıklayın. Çalıştırma tamamlandığında, yeni
users_and_bookingstablo da dahil olmak üzere dört tablo olduğunu Boru Hattı Grafiği'nde görebilirsiniz.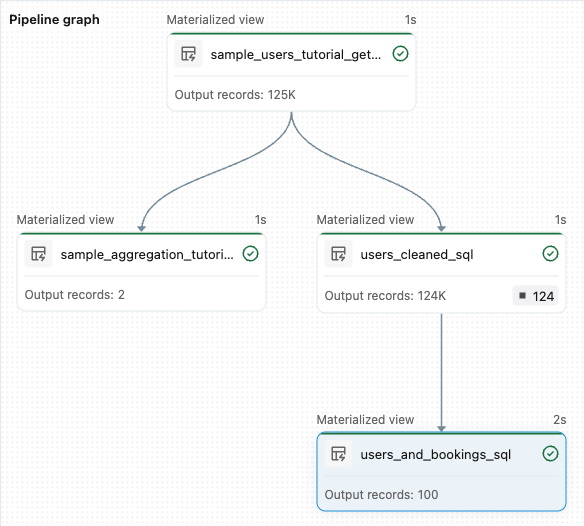
Sonraki Adımlar
Lakeflow işlem hatları düzenleyicisinin bazı özelliklerini kullanmayı öğrendiğinize ve bir işlem hattı oluşturduğunuza göre, hakkında daha fazla bilgi edinmek için diğer bazı özellikler şunlardır:
İşlem hatları oluştururken dönüştürmelerle çalışma ve hata ayıklama araçları:
- Seçmeli yürütme
- Veri önizlemeleri
- Etkileşimli DAG (işlem hattınızdaki veri kümelerinin grafiği)
Verimli işbirliği, sürüm kontrolü ve CI/CD entegrasyonu için doğrudan düzenleyiciden yerleşik Databricks Varlık Paketleri entegrasyonu: