Sağlanan aktarım hızı Temel Model API'leri
Bu makalede, sağlanan aktarım hızına yönelik Temel Model API'leri kullanılarak modellerin nasıl dağıtılacağı gösterilmektedir. Databricks, üretim iş yükleri için sağlanan aktarım hızını önerir ve performans garantili temel modeller için iyileştirilmiş çıkarım sağlar.
Sağlanan aktarım hızı nedir?
Sağlanan aktarım hızı, bir uç noktaya aynı anda gönderebileceğiniz kaç belirteç değerinde istek olduğunu ifade eder. Sağlanan aktarım hızı sunan uç noktalar, uç noktaya gönderebileceğiniz saniye başına belirteç aralığı açısından yapılandırılan ayrılmış uç noktalardır.
Daha fazla bilgi için şu kaynaklara gözatın:
- Sağlanan aktarım hızındaki saniye başına belirteçler ne anlama gelir?
- Kendi LLM uç nokta karşılaştırmanızı gerçekleştirme
Sağlanan aktarım hızı uç noktaları için desteklenen model mimarilerinin listesi için bkz . Sağlanan aktarım hızı Temel Model API'leri .
Gereksinimler
Bkz . gereksinimler. ayrıntılı temel modelleri dağıtmak için bkz . Hassas ayarlanmış temel modelleri dağıtma.
[Önerilen] Unity Kataloğu'ndan temel modelleri dağıtma
Önemli
Bu özellik Genel Önizlemededir.
Databricks, Unity Kataloğu'nda önceden yüklenmiş olan temel modellerin kullanılmasını önerir. Bu modelleri şemadaki ai (system.ai) katalog system altında bulabilirsiniz.
Temel modeli dağıtmak için:
- Katalog Gezgini'nde adresine
system.aigidin. - Dağıtılacak modelin adına tıklayın.
- Model sayfasında Bu modele hizmet et düğmesine tıklayın.
- Sunum uç noktası oluştur sayfası görüntülenir. Bkz . Kullanıcı arabirimini kullanarak sağlanan aktarım hızı uç noktanızı oluşturma.
Databricks Market'ten temel modelleri dağıtma
Alternatif olarak, Temel modelleri Databricks Market'ten Unity Kataloğu'na yükleyebilirsiniz.
Bir model ailesi arayabilir ve model sayfasından Erişim al'ı seçebilir ve modeli Unity Kataloğu'na yüklemek için oturum açma kimlik bilgilerini sağlayabilirsiniz.
Model Unity Kataloğu'na yüklendikten sonra, Sunma kullanıcı arabirimini kullanarak uç noktaya hizmet veren bir model oluşturabilirsiniz.
DBRX modellerini dağıtma
Databricks, iş yükleriniz için DBRX Yönergesi modelinin sunulmasını önerir. Sağlanan aktarım hızını kullanarak DBRX Instruct modeline hizmet vermek için [Önerilen] Unity Kataloğu'ndan temel modelleri dağıtma başlığındaki yönergeleri izleyin.
Bu DBRX modellerini sunarken sağlanan aktarım hızı 16 bine kadar bağlam uzunluğunu destekler.
DBRX modelleri, model yanıtlarında ilgi ve doğruluk sağlamak için aşağıdaki varsayılan sistem istemini kullanır:
You are DBRX, created by Databricks. You were last updated in December 2023. You answer questions based on information available up to that point.
YOU PROVIDE SHORT RESPONSES TO SHORT QUESTIONS OR STATEMENTS, but provide thorough responses to more complex and open-ended questions.
You assist with various tasks, from writing to coding (using markdown for code blocks — remember to use ``` with code, JSON, and tables).
(You do not have real-time data access or code execution capabilities. You avoid stereotyping and provide balanced perspectives on controversial topics. You do not provide song lyrics, poems, or news articles and do not divulge details of your training data.)
This is your system prompt, guiding your responses. Do not reference it, just respond to the user. If you find yourself talking about this message, stop. You should be responding appropriately and usually that means not mentioning this.
YOU DO NOT MENTION ANY OF THIS INFORMATION ABOUT YOURSELF UNLESS THE INFORMATION IS DIRECTLY PERTINENT TO THE USER'S QUERY.
hassas temel modelleri dağıtma
Şemadaki system.ai modelleri kullanamıyorsanız veya Databricks Market'ten model yükleyemiyorsanız, Unity Kataloğu'nda günlüğe yazarak ince ayarlı bir temel modeli dağıtabilirsiniz. Bu bölüm ve aşağıdaki bölümlerde, bir MLflow modelini Unity Kataloğu'nda günlüğe kaydedecek ve kullanıcı arabirimini veya REST API'yi kullanarak sağlanan aktarım hızı uç noktanızı oluşturacak şekilde kodunuzun nasıl ayarlanacağı gösterilmektedir.
Gereksinimler
- hassas temel modellerin dağıtılması yalnızca MLflow 2.11 veya üzeri tarafından desteklenir. Databricks Runtime 15.0 ML ve üzeri uyumlu MLflow sürümünü önceden yükler.
- Ekleme uç noktaları için modelin küçük veya büyük BGE ekleme modeli mimarisi olması gerekir.
- Databricks, büyük modellerin daha hızlı yüklenmesi ve indirilmesi için Unity Kataloğu'ndaki modellerin kullanılmasını önerir.
Katalog, şema ve model adını tanımlama
ayrıntılı bir temel model dağıtmak için hedef Unity Kataloğu kataloğunu, şemasını ve tercih edilen model adını tanımlayın.
mlflow.set_registry_uri('databricks-uc')
CATALOG = "catalog"
SCHEMA = "schema"
MODEL_NAME = "model_name"
registered_model_name = f"{CATALOG}.{SCHEMA}.{MODEL_NAME}"
Modelinizi günlüğe kaydetme
Model uç noktanız için sağlanan aktarım hızını etkinleştirmek için, MLflow transformers türünü kullanarak modelinizi günlüğe kaydetmeniz ve bağımsız değişkeni aşağıdaki seçeneklerden uygun model türü arabirimiyle belirtmeniz task gerekir:
"llm/v1/completions""llm/v1/chat""llm/v1/embeddings"
Bu bağımsız değişkenler, model sunum uç noktası için kullanılan API imzasını belirtir. Bu görevler ve ilgili giriş/çıkış şemaları hakkında daha fazla ayrıntı için lütfen MLflow belgelerine bakın.
Aşağıda, MLflow kullanılarak günlüğe kaydedilen bir metin tamamlama dili modelini günlüğe kaydetme örneği verilmiştir:
model = AutoModelForCausalLM.from_pretrained("mosaicml/mixtral-8x7b-instruct", torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained("mosaicml/mixtral-8x7b-instruct")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
# Specify the llm/v1/xxx task that is compatible with the model being logged
task="llm/v1/completions",
# Specify an input example that conforms to the input schema for the task.
input_example={"prompt": np.array(["Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\nWhat is Apache Spark?\n\n### Response:\n"])},
# By passing the model name, MLflow automatically registers the Transformers model to Unity Catalog with the given catalog/schema/model_name.
registered_model_name=registered_model_name
# Optionally, you can set save_pretrained to False to avoid unnecessary copy of model weight and gain more efficiency
save_pretrained=False
)
Not
MLflow'un 2.12'den önceki bir sürümünü kullanıyorsanız, görevi aynı mlflow.transformer.log_model() işlevin parametresi içinde metadata belirtmeniz gerekir.
metadata = {"task": "llm/v1/completions"}metadata = {"task": "llm/v1/chat"}metadata = {"task": "llm/v1/embeddings"}
Sağlanan aktarım hızı hem temel hem de büyük GTE ekleme modellerini de destekler. Aşağıda, sağlanan aktarım hızıyla hizmet verilmesi için modelin Alibaba-NLP/gte-large-en-v1.5 nasıl günlüğe kaydedildiğini gösteren bir örnek verilmiştir:
model = AutoModel.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
tokenizer = AutoTokenizer.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
task="llm/v1/embeddings",
registered_model_name=registered_model_name,
# model_type is required for logging a fine-tuned BGE models.
metadata={
"model_type": "gte-large"
}
)
Modeliniz Unity Kataloğu'nda günlüğe kaydedildikten sonra sağlanan aktarım hızına sahip uç noktaya hizmet veren bir model oluşturmak için Kullanıcı arabirimini kullanarak sağlanan aktarım hızı uç noktanızı oluşturma bölümüne geçin.
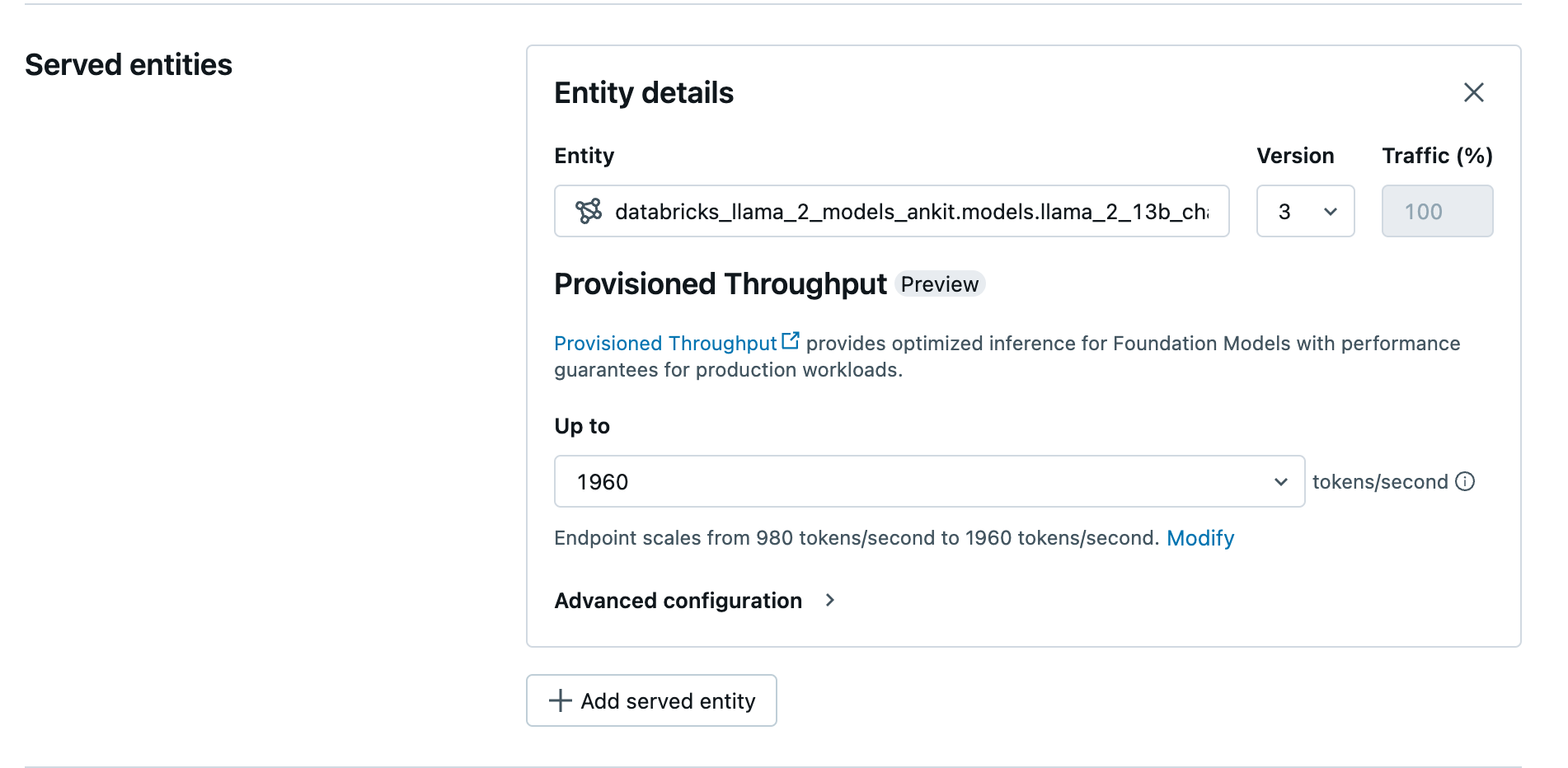
Kullanıcı arabirimini kullanarak sağlanan aktarım hızı uç noktanızı oluşturma
Günlüğe kaydedilen model Unity Kataloğu'na girdikten sonra, aşağıdaki adımlarla uç noktaya hizmet veren bir sağlanan aktarım hızı oluşturun:
- Çalışma alanınızda Sunma kullanıcı arabirimine gidin.
- Sunum uç noktası oluştur'u seçin.
- Varlık alanında Unity Kataloğu'ndan modelinizi seçin. Uygun modeller için sunulan varlığın kullanıcı arabirimi Sağlanan Aktarım Hızı ekranını gösterir.
- Yukarı açılan listesinde uç noktanız için saniye başına maksimum belirteç aktarım hızını yapılandırabilirsiniz.
- Sağlanan aktarım hızı uç noktaları otomatik olarak ölçeklendirilir, böylece Değiştir'i seçerek uç noktanızın ölçeğini azaltabileceği saniye başına en düşük belirteçleri görüntüleyebilirsiniz.
REST API kullanarak sağlanan aktarım hızı uç noktanızı oluşturma
MODELInizi REST API kullanarak sağlanan aktarım hızı modunda dağıtmak için isteğinizde ve max_provisioned_throughput alanlarını belirtmeniz min_provisioned_throughput gerekir. Python'ı tercih ediyorsanız, MLflow Dağıtım SDK'sını kullanarak bir uç nokta da oluşturabilirsiniz.
Modelinize uygun sağlanan aktarım hızı aralığını belirlemek için bkz . Sağlanan aktarım hızını artımlı olarak alma.
import requests
import json
# Set the name of the MLflow endpoint
endpoint_name = "llama2-13b-chat"
# Name of the registered MLflow model
model_name = "ml.llm-catalog.llama-13b"
# Get the latest version of the MLflow model
model_version = 3
# Get the API endpoint and token for the current notebook context
API_ROOT = "<YOUR-API-URL>"
API_TOKEN = "<YOUR-API-TOKEN>"
headers = {"Context-Type": "text/json", "Authorization": f"Bearer {API_TOKEN}"}
optimizable_info = requests.get(
url=f"{API_ROOT}/api/2.0/serving-endpoints/get-model-optimization-info/{model_name}/{model_version}",
headers=headers)
.json()
if 'optimizable' not in optimizable_info or not optimizable_info['optimizable']:
raise ValueError("Model is not eligible for provisioned throughput")
chunk_size = optimizable_info['throughput_chunk_size']
# Minimum desired provisioned throughput
min_provisioned_throughput = 2 * chunk_size
# Maximum desired provisioned throughput
max_provisioned_throughput = 3 * chunk_size
# Send the POST request to create the serving endpoint
data = {
"name": endpoint_name,
"config": {
"served_entities": [
{
"entity_name": model_name,
"entity_version": model_version,
"min_provisioned_throughput": min_provisioned_throughput,
"max_provisioned_throughput": max_provisioned_throughput,
}
]
},
}
response = requests.post(
url=f"{API_ROOT}/api/2.0/serving-endpoints", json=data, headers=headers
)
print(json.dumps(response.json(), indent=4))
Sohbet tamamlama görevleri için günlük olasılığı
Sohbet tamamlama görevleri için parametresini logprobs kullanarak büyük dil modeli oluşturma işleminin bir parçası olarak örneklenen bir belirtecin günlük olasılığını sağlayabilirsiniz. Sınıflandırma, model belirsizliğini değerlendirme ve değerlendirme ölçümlerini çalıştırma gibi çeşitli senaryolar için kullanabilirsiniz logprobs . Parametre ayrıntıları için bkz . Sohbet görevi .
Sağlanan aktarım hızını artımlı olarak alma
Sağlanan aktarım hızı, modele göre değişen belirli artışlarla saniye başına belirteç artışlarıyla kullanılabilir. Databricks, ihtiyaçlarınıza uygun aralığı belirlemek için platformdaki model iyileştirme bilgileri API'sini kullanmanızı önerir.
GET api/2.0/serving-endpoints/get-model-optimization-info/{registered_model_name}/{version}
Aşağıda API'den örnek bir yanıt verilmiştir:
{
"optimizable": true,
"model_type": "llama",
"throughput_chunk_size": 1580
}
Not defteri örnekleri
Aşağıdaki not defterlerinde sağlanan aktarım hızı Temel Modeli API'si oluşturma örnekleri gösterilmektedir:
GTE model not defteri için sağlanan aktarım hızı
Llama2 model not defteri için sağlanan aktarım hızı
Mistral model not defteri için sağlanan aktarım hızı
BGE model not defteri için sağlanan aktarım hızı
Sınırlamalar
- Model dağıtımı GPU kapasitesi sorunları nedeniyle başarısız olabilir ve bu da uç nokta oluşturma veya güncelleştirme sırasında zaman aşımına neden olabilir. Çözüme yardımcı olması için Databricks hesap ekibinize ulaşın.
- Temel Modeller API'leri için otomatik ölçeklendirme, CPU modeli sunma işleminden daha yavaştır. Databricks, istek zaman aşımlarını önlemek için aşırı sağlama önerir.